
基于多重示范的智能车辆运动基元表征与序列生成
2021-06-19 05:19陆瑶敏龚建伟王博洋关海杰
兵工学报 2021年4期
陆瑶敏,龚建伟,王博洋,2,关海杰
(1.北京理工大学 机械与车辆学院,北京 100081;2.北京大学 信息科学技术学院,北京 100871)
0 引言
通过学习人类驾驶员的知识与经验能够有效提升无人或辅助驾驶系统的适用性与接受度[1-2]。轨迹规划系统作为无人驾驶系统中的重要组成部分,为无人车规划出了最优的可通行路径[3],这其中将复杂的驾驶任务分解成简单的基元组合,不仅能够有效提升轨迹生成的效率[4-5],也能提升驾驶行为学习的效率与准确度[6-7]。
目前较为实用的运动基元表征生成方法主要有基于运动学模型[5]和曲线模型[8-9]两种方法,但上述两种方法主要是从车辆模型约束与轨迹平滑度的角度研究基元的生成问题,而未能将驾驶行为数据作为生成参考融入到运动基元的生成过程中。此外,上述基元生成方法也不具备对纵向与横向耦合关系的表征能力,无法实现轨迹与其相匹配速度的协同生成;而原有各独立基元之间的拼接则主要通过增添加减速或曲率过渡基元实现平滑过渡[10-11],但所选用的基元过渡模式较为单一,并且不具备在过渡过程中轨迹与速度的协同关联能力。
在基于驾驶数据的类人轨迹生成方面,Xu等[12]对候选换道基元和驾驶员行车轨迹进行偏差建模,并在实时路径生成时进行误差补偿;He等[13]将候选轨迹与驾驶员换道轨迹的相似性参量引入到运动基元选择的成本函数中,以实现类人轨迹生成;胡文等[14]借鉴熟练驾驶员的泊车经验提出了相应的类人自动泊车算法。Li等[15]利用深度学习算法表征类人驾驶轨迹与道路中线的偏差,实现不同道路曲率下的类人驾驶。上述方法都借助于驾驶数据实现了类人轨迹规划,但并未对不同驾驶风格进行区分,因此未能在规划轨迹中体现出驾驶风格参量的影响作用。
类人运动基元的泛化生成需要具备两方面的调整能力,其一是对目标点和中间点的适应跟随能力,其二是对不同驾驶风格的表征调整能力。Duggal等[16]基于5次多项式构建类人换道运动基元,并通过控制基元的中间点位置来调整换道过程中的横向和纵向间距;Schnelle等[17]针对换道场景将不同驾驶员的驾驶风格以参量的形式融入到个性化轨迹的生成模型中。但这两种方法都只针对特定的换道场景,并且模型中的参量也与场景相关,因此虽然能够分别实现对目标点和驾驶风格的泛化调整,但不具备对多类典型场景的适用性,未能摆脱对特定场景模型的依赖。
本文针对多类典型场景下类人轨迹的生成需求,利用动态运动基元(DMP)与奇异值分解(SVD)相结合的方法对同类型多重示范轨迹进行表征,并根据运动规划系统设定的初始条件,在单一运动基元泛化生成的基础上,扩展实现序列中各独立运动基元的关联,最终通过准均匀B样条曲线拟合生成类人运动基元序列。
1 基元表征与序列生成
在给定运动基元类别集合MP={MP1,…,MPM}(M为总的运动基元类别数)的前提下,针对给定同类型运动基元中不同驾驶风格的运动基元集合M={m1,…,mQ}(Q为同一运动基元类型下所有示范轨迹的总个数),本文的目的为利用SVD实现对基元表征方法中主要形状变化表征参量ωm(m为运动基元类别)与驾驶风格微调参量集sm的分离,并和原有的轨迹基元调整参量一起构成新的调整参量集γm,进一步提升单一运动基元的泛化调整能力;此外,本文还将在给定初始条件I={I1,…,IK}(K为给定的基元序列目标点总数)的基础上,构建基元序列中各独立运动基元的关联关系,并选取合适的控制点集合P以准均匀B样条曲线为依托对序列进行重拟合,最终得到符合车辆运动连续性约束的运动基元序列S={s1,…,sL},L为最终生成的运动基元序列点总数。
本文中主要参量的定义与解释说明如下:
1)mi(t)是t时刻运动基元点的定义,mi(t)=[xm(t),ym(t)]T∈R2×1,其中xm和ym分别是在坐标系Oxmym中的横、纵坐标值。运动基元的初始坐标点为坐标系Oxmym的原点,轨迹基元初始点的航向与xm轴的正方向一致。
2)ωm是同类型下运动基元的主要形状变化表征参量,该参量集在运动基元的泛化调整过程中始终保持不变,ωm=[ωx,ωy],其中ωx和ωy分别是所选定运动基元的纵向和横向形状变化表征参量。
3)γm是同类型运动基元的泛化调整参量集,能够依据不同的目标需求实现对运动基元的调整,γm=[bm,gm,Tm,sm]。其中bm是运动基元的起始位置,gm是运动基元的终点位置,Tm是运动基元的时间尺度,sm是运动基元驾驶风格微调参量,该参量允许在同类型运动基元主要形状的基础上,对轨迹及相应速度的变化做进一步的微调。
4)Ik是运动基元序列所设定的初始条件,Ik=[id,Tk,bk,gk,θk]T∈R7×1,其中id是运动基元序列中第k个运动基元的类别信息,Tk是期望时间尺度信息,bk是期望起始位置,gk是期望目标位置,θk是期望目标航向。

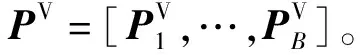
7)sl是重拟合之后最终生成的运动基元序列点,sl=[x(l),y(l),v(l)]T∈R3×1。其中x(l)和y(l)是生成的基元序列位置点在Oxy坐标系下的坐标位置值,v(l)是相应的速度值。Oxy坐标系与基元序列中第1个独立基元的坐标系Oxmym相一致。
本文所提出的方法致力于解决如下的两个关键问题:其一,如何从相互关联但又不完全一致的同类型多重驾驶风格的示范轨迹中,实现表征运动基元主要形状变化参量与驾驶风格调整参量的分离;其二,在给定基元序列初始条件的前提下,完成基元序列中各独立运动基元轨迹与速度的协同关联,并在保证连接点处平滑过渡的基础上,实现对目标点位置和航向的钳位。整体的处理流程图如图1所示。

图1 运动基元表征与序列生成流程
2 单一运动基元的表征
原有的DMP表征方法虽然具备表征单一运动基元的能力,但其无法实现对多重同类型示范运动基元的表征,也不具备关联基元序列中各独立运动基元的能力。正是基于上述两方面的考量,本文对原有DMP表征方法进行了改进,即改进DMP(MDMP)表征方法,改进主要涉及3方面的内容:衰减函数zm、目标函数rm以及非线性形状表征函数f(t,zm)。同类型下多重驾驶风格单一运动基元的表征及参量学习的总体流程如图2所示。在单一基元表征方法中,非线性函数用以表征驾驶行车时序轨迹点的纵向与横向协同配合规律;类临界阻尼系统则实现了基元应对目标状态变化的泛化调整。为了实现对不同驾驶风格参量的表征,非线性函数又被进一步分解成描述纵向与横向耦合的基本形状变化参量集ωm与驾驶风格微调参量集sm. 图2中,Fd为非线性函数参量集,Db为表征同类型下运动基元主要形状的数据。
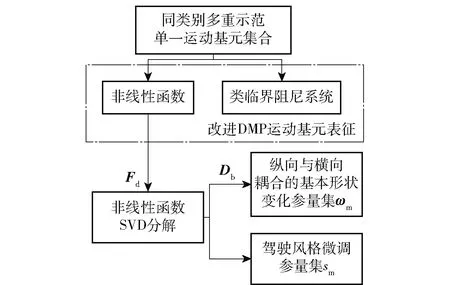
图2 基于多重示范的单一运动基元表征流程
2.1 MDMP表征方法
首先,MDMP表征方法利用Sigmoidal衰减函数替代了原有的Exponential衰减函数,Sigmoidal衰减函数和Exponential衰减函数分别为
(1)
(2)
式中:αz为设定的衰减系数;τ为时间缩放系数;Tm为多重示范基元的时间尺度;Δt为运动基元点采样的时间间隔,由于同类型中Tm并不完全一致,因此对每个运动基元进行数据重采样以保证其具备同样数目的采样点个数,相邻采样点之间的间隔与采样总时间T的关系为Δt=T/100.
虽然改进前后的衰减函数都会在单一运动基元的终止时刻衰减到0,但二者整体上的衰减过程却有显著的差别。原有的衰减函数在初始阶段便会向零点衰减,但改进后的衰减函数只有到了最后阶段才会开始迅速衰减。因为衰减函数控制的是表征轨迹形状变化的非线性函数衰减规律,因此非线性函数的延迟衰减使得基元在整个时间尺度内具有较高的表征精度,尤其有利于提升运动基元后半段特别是末尾处的表征精度。
其次,MDMP表征方法将原有固定目标点位置数值gm替换为目标函数rm,MDMP表征方法如(3)式~(5)式所示,原DMP表征方法加速度表达式如(6)式所示:
(3)
式中:
(4)
(5)
(6)
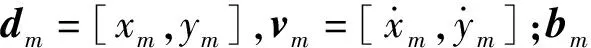
最后,非线性函数是DMP方法中表征轨迹形状变化的核心要素。改进后的非线性函数将原有单一的非线性函数表征方式转换成J个基底函数的组合,如(7)式所示,原DMP方法的非线性函数如(8)式所示:
(7)
(8)
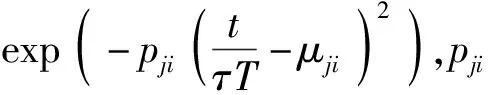
2.2 基于多重示范的形状表征参量学习方法
整体的形状表征参量学习过程分为两个步骤展开:其一,利用SVD方法从多重示范轨迹中提取出同类型运动基元主要形状的基底函数Db,并实现驾驶风格微调参量集sm的分离;其二,利用回归算法得到表征运动基元轨迹主要形状变化的参量集ωm,以使得表征数据与示范数据之间的偏差最小。由于组成运动基元横、纵向参量的训练方法完全一致,因此只在此处介绍纵向参量的训练过程。
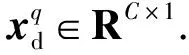
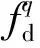
(9)
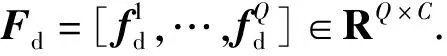
Fd=UΣVT≈smDb,
(10)

同类型多重示范运动基元的固有形状参量集ωm=[ω1,…,ωJ]T∈RJ×N可以通过求解如(11)式所示的优化问题得到:
(11)
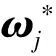
3 运动基元序列的生成
基元序列生成方法的核心是序列中各独立运动基元的关联与拼接问题。虽然简单的运动基元首尾相接算法(即上一个运动基元的终点位置坐标作为下一个运动基元的起点位置坐标)能够实现位置参量层面的关联能力,但不具备关联速度层面信息的基本能力。
区别于简单的基元拼接算法,本文所提出的运动基元序列生成方法将序列看作是一个完整的整体而非各个独立的基本单元。通过MDMP方法完成各独立运动基元衰减函数、目标函数和非线性函数的关联,并利用准均匀B样条曲线对生成的运动基元序列进行重拟合,进一步提升运动基元序列的平滑度以及对目标点位置和航向的钳位能力。运动基元序列的生成方法流程如图3所示,其中,μk、pk、ωk分别是运动基元序列中第k个运动基元高斯内核函数的均值、带宽和权重,μ′和p′分别是MDMP基元序列非线性表征函数中单一基底函数的高斯内核中心参量和带宽参量,Fx和Fy是指坐标分别向x轴和y轴转换时,考量坐标系转换关系生成的非线性函数。其中在各独立基元关联的过程中,其核心是通过高斯内核组合与坐标系转换,构建了表征纵横向耦合关系的基元序列非线性函数,将各独立基元的关联问题转换成了基元序列的重表征问题,使得基元序列具备了与单一独立基元完全相同的泛化调整能力。
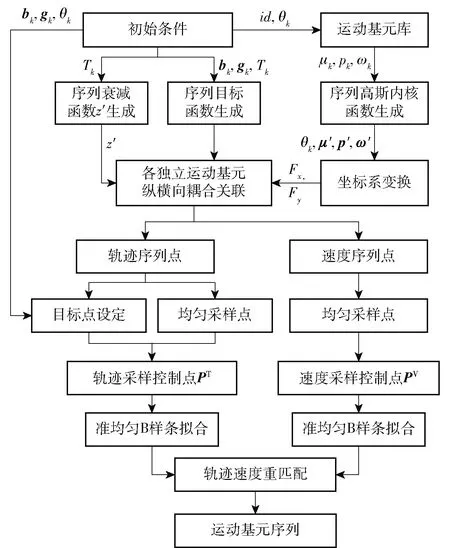
图3 运动基元序列生成流程图
3.1 基于MDMP方法的基元序列表征
表征运动基元序列的MDMP方法中衰减函数z′的定义为
(12)
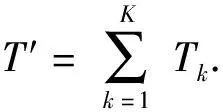
根据给定的运动基元序列生成的初始条件,最终生成的运动基元序列的目标位置函数为
(13)
从(13)式中能够观察到,运动基元序列的目标位置函数以各独立基元所处的时间段为依据,对目标位置函数进行分段化表征,实现了各独立基元目标位置函数的关联。
MDMP序列非线性表征函数中单一基底函数的高斯内核中心参量μ′j和带宽参量p′j,也根据基元序列中各独立运动基元的参量进行组合重生成,如(14)式~(17)式所示:
(14)
(15)
(16)
(17)
由于整个非线性内核函数是基于时间定义的,因此在生成整个运动基元序列的非线性内核函数时,也需要根据整体的时间尺度T′完成各独立运动基元中非线性内核参量的关联。其中,高斯内核中心参量μ′j是在单一独立基元按时间尺度缩放的基础上再进行的简单叠加,带宽参量p′j则是在时间尺度上的缩放。
基元序列非线性函数中各高斯内核的权重系数仅仅是各独立运动基元参量的简单拼接,如(18)式所示:
(18)
此外,由于基元序列中每一个独立的运动基元都定义在Oxmym坐标系中,但运动基元序列生成时所选用的坐标系为Oxy.两个坐标系之间的转换关系如(19)式~(22)式所示:
(19)
(20)
(21)
(22)
式中:x′,y′和v′x,v′y分别为基元序列在Oxy坐标系下的位置坐标值和速度值。坐标分别向x轴和y轴转换时,考量坐标系转换关系生成的非线性函数Fx和Fy如(23)式~(26)式所示:
(23)
(24)
(25)
(26)
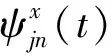
3.2 基于准均匀B样条曲线的序列重拟合
本文采用准均匀B样条曲线对实现轨迹与速度层面协同关联的运动基元序列进行重拟合,q次B样条曲线C(u)的定义如(27)式~(29)式所示:
(27)
(28)
(29)
式中:[P0,…,Pnc]=P,P为给定的nc+1个控制点;[u0,…,umk]=U,U为mk+1个节点;q为曲线的次数,q∈N+,mk、nc、q三者之间需要满足的基本关系式为mk=nc+p+1;Ni,q(u)是第i个q次B样条基函数。
准均匀B样条曲线就是在B样条曲线的基础上增加了部分控制点,使得拟合之后的曲线能够满足对目标点位置和航向的钳位需求。考虑到无人车行驶的期望轨迹和速度参考量需要满足加速度连续性的基本需求[19],因此选取q=5,采用5次准均匀B样条曲线进行拟合。轨迹采样控制点PT与速度采样控制点PV的选取依据如图4所示。

图4 准均匀B样条曲线控制点选取
4 基元表征与序列生成结果与分析
4.1 数据采集平台及所建立的驾驶员数据库
通过图5所示的无人车辆平台,在人工驾驶条件下,采集了驾驶员在典型交通场景下的驾驶行为数据。其中,典型场景包括换道、直角弯、U形弯、纵向跟驰等。驾驶行为数据中的车辆行驶速度信息由底层控制器局域网络(CAN)提供,航向信息由惯性组合导航系统(英国OxTs公司生产的 Inertial + GNSS/INS系统)提供。各独立运动基元中的相对位置参量mi(t)由速度和航向偏差根据采样时间积分产生。本文以前期既有的运动基元类别辨识方法作为同类型的判别依据[18],并构建同类别多重示范的运动基元数据集合,但需要指出的是本文方法并不仅限于上述聚类方法。
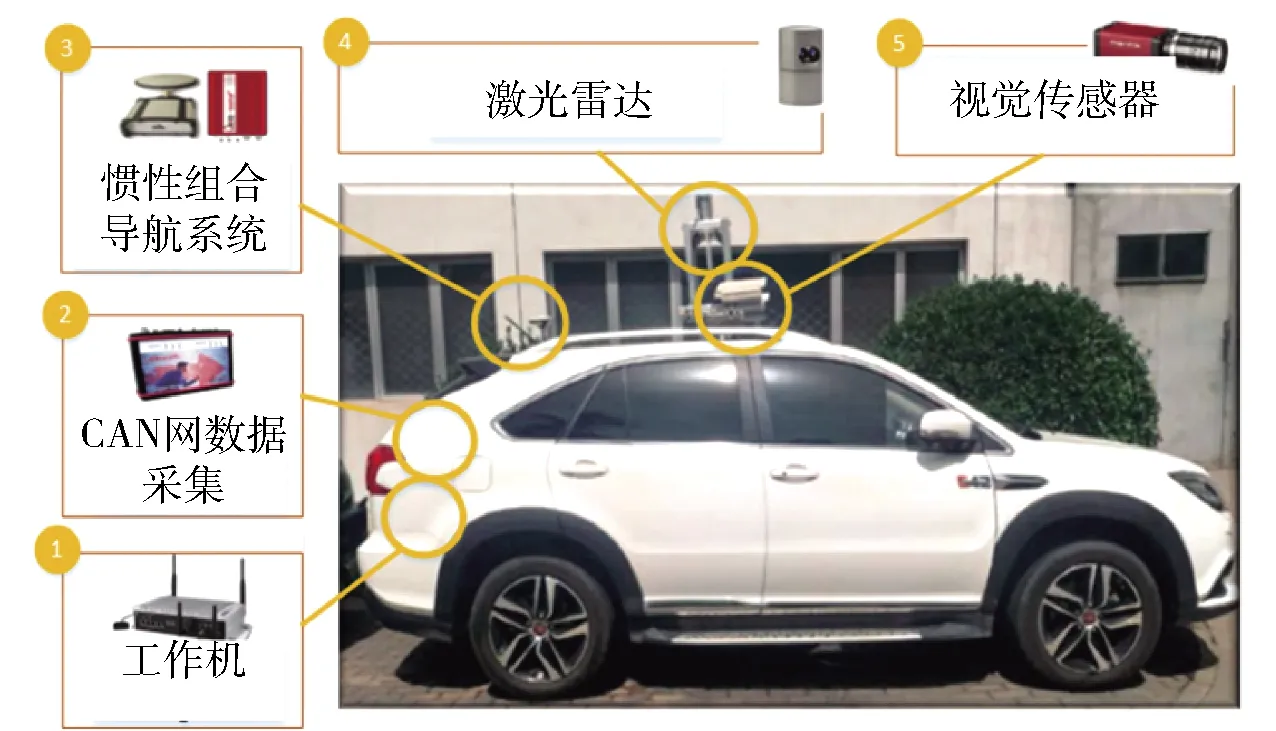
图5 驾驶行为数据采集平台
4.2 单一运动基元表征与再生成结果分析
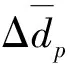
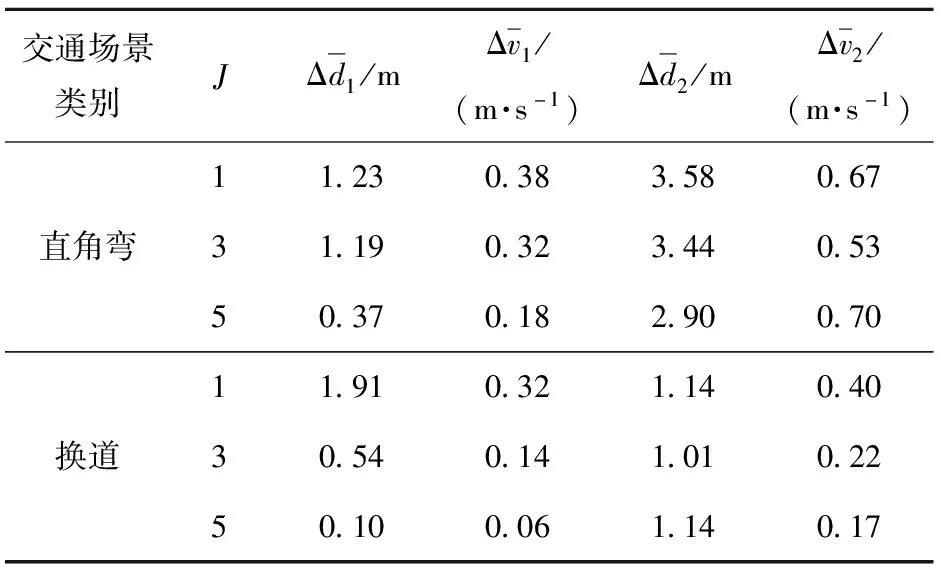
表1 多重示范轨迹平均表征偏差
从图6和表1中可以观察得到,在所选定两个类型下的运动基元中,所有示范轨迹的位置表征偏差或速度表征偏差都随着J值的增大而减小。但是,表征精度的提升对于同类型下的多重示范轨迹并不完全一致,也就是说,J值的提升引入了越来越多同类型下的主要轨迹形状特征,有效提升了同类型单一运动基元的表征能力。虽然通过SVD算法只提取出了同类别下的主要形状变化参量,在一定程度上牺牲了表征的精度,但精度上的牺牲有效限制了分离出的驾驶风格微调参量集维度数。图7展示了选定两种交通场景类别下的运动基元,基于驾驶风格微调参量调整变化而产生的在轨迹层面和相应速度层面上的联动调定结果,在调整过程中起始位置、目标位置和时间尺度泛化调整参量维持不变。
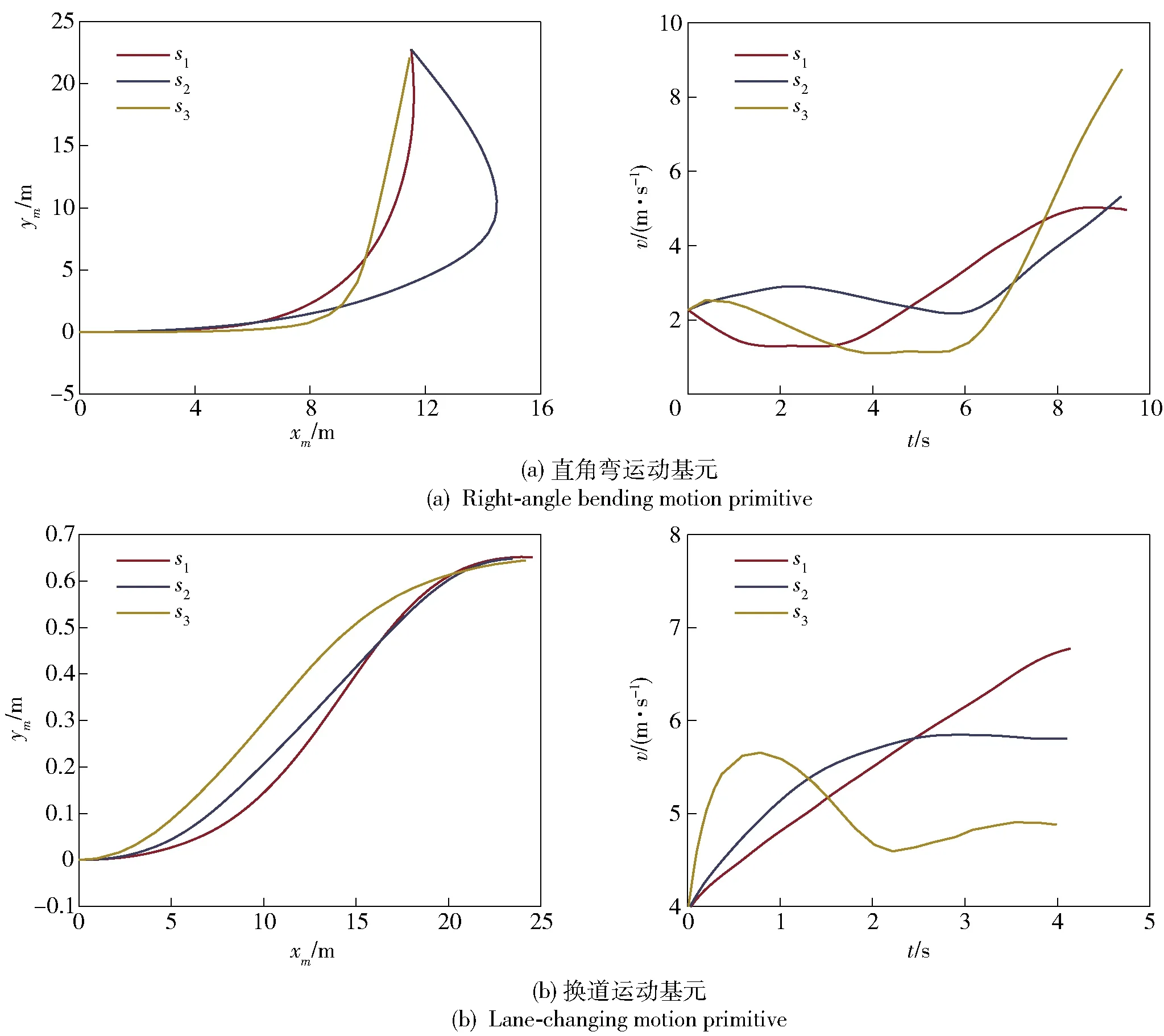
图7 不同驾驶风格微调参量sm泛化调整结果
4.3 运动基元序列的生成结果分析
选取直角弯场景实现对运动基元序列重拟合效果的评估,直角弯场景中包含两个直驶运动基元与一个直角弯基元。以关联过程中产生的最大加速度amax(m/s2)与位置偏差Δdi(m)作为速度平滑与对目标点跟踪精度的基本评价指标,amax为在各独立运动基元关联过程中所产生的最大加速度,Δdi为生成轨迹与初始设定编号为i目标点之间的最小距离。
在两个场景下,独立基元首尾相接的简单拼接(SJ)方法、利用MDMP方法关联得到的运动基元序列生成结果,以及利用重拟合(B-MDMP)方法得到的运动基元序列如图8所示。相应的每一个连接点处的评价指标如表2所示,其中amax1为第1个过渡点最大加速度,amax2为第2个过渡点最大加速度,过渡点为不同基元序列之间的连接点。在直角弯场景中,3个目标点的航向信息为0°、90°、90°.
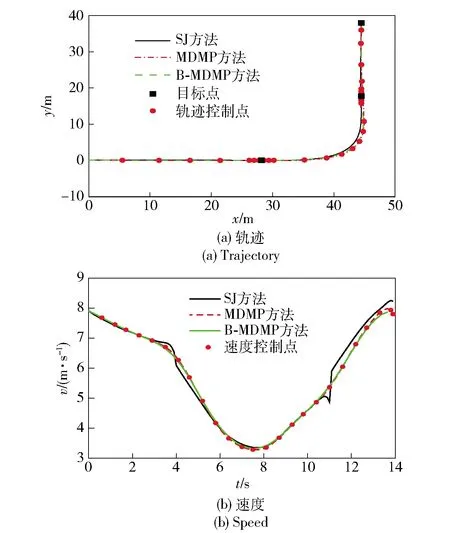
图8 直角弯场景运动基元序列生成结果
当准均匀B样条曲线的节点个数mk+1取值为21时,基元序列生成过程的平均耗时为10 ms,满足规划实时性需求。
从图8和表2中可得:SJ方法仅仅实现了轨迹层面的关联而忽略了轨迹和速度的协同关联关系,因此虽然位置偏差较小,但却有较大的速度跳变;MDMP方法实现了序列中各独立运动基元轨迹和速度层面的协同关联,避免了连接点处的速度跳变,并且最终生成的运动基元序列作为一个整体依然具备
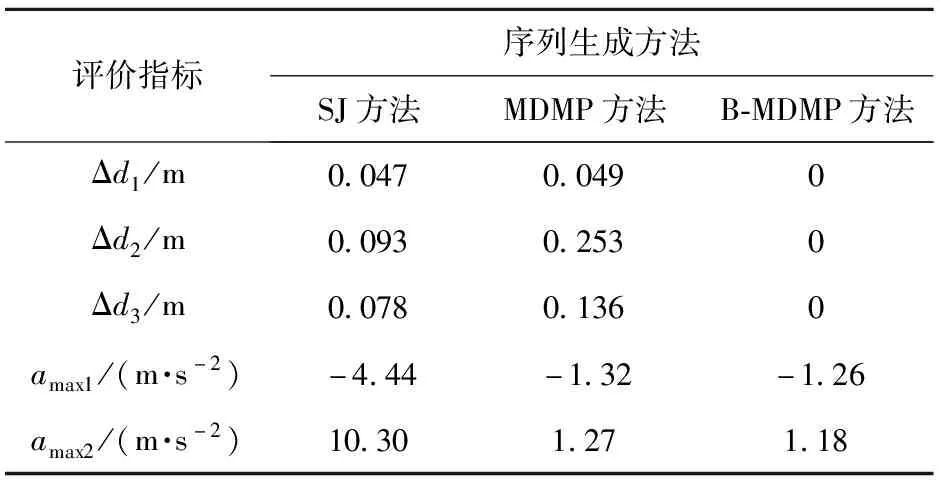
表2 运动基元序列生成评价指标
对目标点位置gi和时间尺度Ti的泛化调整能力(见图9);B-MDMP方法在进一步提升轨迹平滑度的同时,实现了对目标点位置的零偏差拟合,并且增加了对目标点航向的钳位能力。
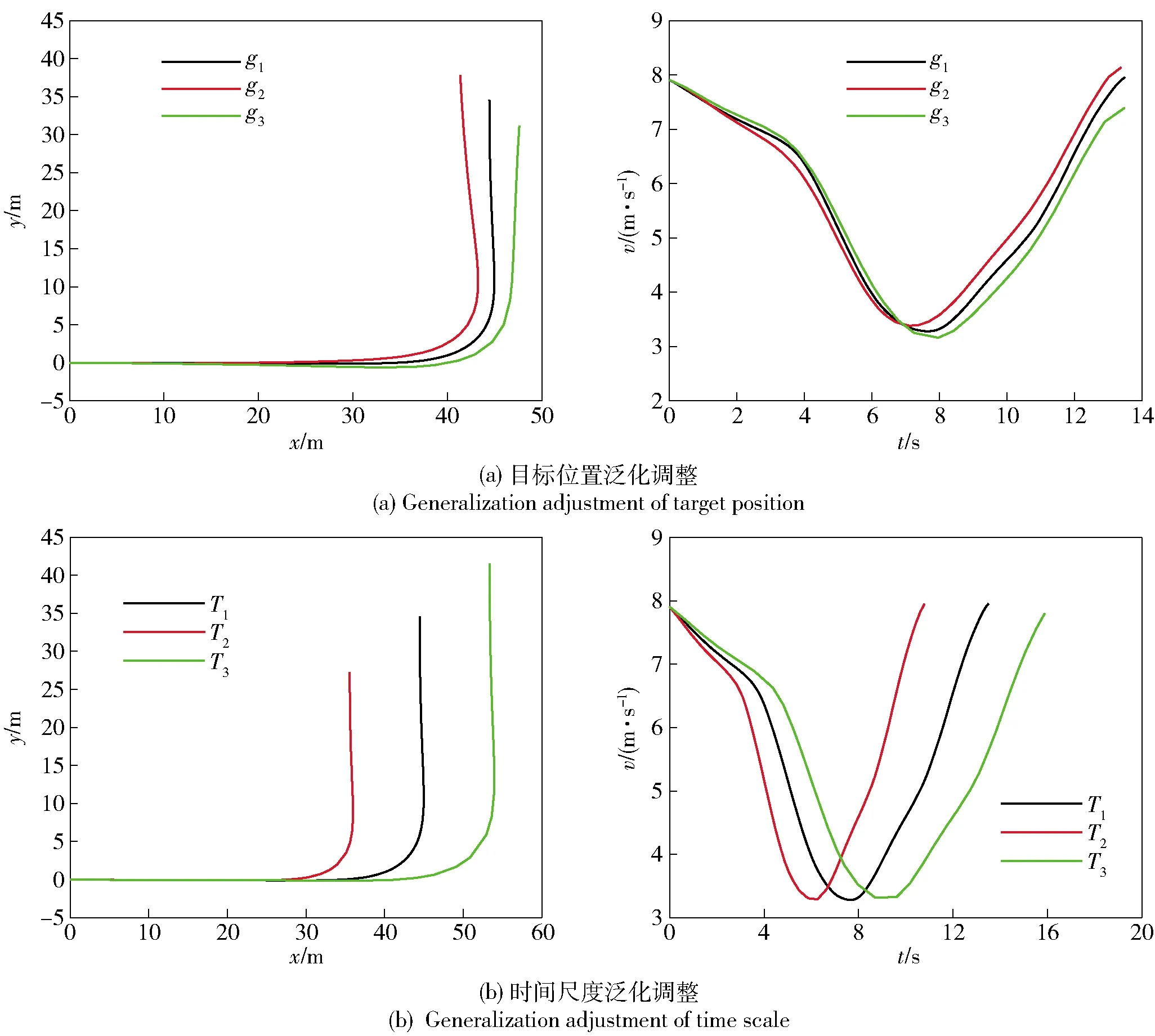
图9 直角弯场景运动基元序列整体泛化调整结果
5 结论
本文在对运动基元进行分类提取的基础上,提出一种MDMP表征方法,以满足类人参考轨迹生成对于独立基元生成和关联的基本需求。得出以下主要结论:
1)本文利用MDMP方法对单一运动基元进行表征以及泛化,并使用SVD实现对表征轨迹形状非线性函数的分解,提取出同类型多重示范轨迹集中的主要形状变化参量ωm与驾驶风格微调参量集sm,并且对比了sm的不同维度数J对多重示范表征精度的影响。
2)运动基元序列生成方法在关联各独立运动基元衰减函数、目标函数与非线性函数的基础上,将基元的拼接问题转换成基元序列的重表征问题,实现了轨迹和速度层面的协同关联表征与整体泛化生成。
3)利用准均匀B样条曲线在进一步平抑拼接时速度跳变的基础上,实现了对目标点位置和航向的零偏差钳位。
猜你喜欢
安徽师范大学学报(自然科学版)(2022年2期)2022-05-30
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
现代职业教育·高职高专(2020年10期)2020-01-05
软件(2017年6期)2017-09-23
商情(2017年12期)2017-05-19
科学中国人(2017年14期)2017-05-19
计算机应用(2016年10期)2017-05-12
国外科技新书评介(2014年11期)2014-12-08
