
基于深度卷积神经网络的水下偏色图像增强方法
2021-07-15 01:24王瑞子王丽妍张湘怡
吉林大学学报(理学版) 2021年4期
傅 博, 王瑞子, 王丽妍, 张湘怡
(辽宁师范大学 计算机与信息技术学院, 辽宁 大连 116081)
0 引 言
水下图像是海洋生物多样性观测和海洋环境监测的重要信息载体. 但由于水下成像环境较复杂, 水下成像系统潜入到海底深处后会因光照、 介质、 波长、 震荡等原因导致图像退化, 产生诸如水下图像颜色偏蓝、 偏绿、 清晰度下降、 细节信息丢失等问题, 如图1所示. 由图1可见, 这种退化不仅影响观测的视觉感受, 且严重影响识别、 跟踪、 颜色分析等高层计算机视觉任务. 因此, 通过水下图像处理算法, 能较好地改善水下图像质量, 对海洋生物的分类识别乃至海洋生物多样性观测具有重要价值.

图1 干净水下图像(A)与真实水下退化图像(B)Fig.1 Clean underwater images (A) and real underwater degraded images (B)
水下图像处理技术分为传统的图像优化算法和基于卷积神经网络的图像优化算法两类. 传统的图像优化算法又可分为水下图像复原和水下图像增强两部分, 其中水下图像复原算法主要侧重于水下图像的细节修复, 而水下图像增强更侧重于水下图像整体色彩的调整. Schechner等[1]基于消除水下图像的偏振干扰, 通过在相机摄像头上安装可调试的偏振器, 获得了同一场景下不同偏角的多角度水下图像, 结合多张图像以及计算出的偏振度, 便可估计场景深度, 从而达到图片复原效果. Li等[2]提出了除雾和颜色校正水下图像复原的方法, 先用一种简单算法对图像进行预处理, 再通过调整饱和度强度、 拉伸直方图等方式增强水下图像, 提高图像对比度. He等[3]提出了一种暗通道先验(DCP)去雾图像增强方法, 可用于水下图像修复. 张凯等[4]提出了一种基于多尺度Retinex的算法, 以此提升图片的全局效果, 并使图像色彩展现更丰富. Zhang等[5]提出了一种扩展Retinex框架, 利用双边和三边滤波器对水下图像不同颜色的通道进行处理, 并达到图像复原效果. 冯辉等[6]提出了一种基于直方图均衡化的水下图像增强算法, 通过较窄的单峰式直方图变为均衡分布的直方图, 使图像对比度增强, 从而达到图像优化的效果. Ancuti等[7]提出了一种基于融合原理的水下图像增强算法, 利用多尺度融合技术, 避免了图像在输出时产生的光影, 并且解决了水下图像不清晰、 对比度较差、 色彩差异等问题. Garcia等[8]提出了一种用同态滤波解决水下雾化、 颜色偏蓝绿等问题, 将像素灰度变换与频率过滤相结合, 改善图像动态范围, 提高图像对比度, 增强图像质量. Chiang等[9]提出了利用补偿光在水中的衰退系数达到水下图像增强的效果, 通过对人工照明与非人工照明区域进行补偿, 以该方式对图像进行优化. Galdran等[10]提出了一种利用红通道方式恢复水下图像的算法, 利用该算法可恢复与短波相关的颜色, 从而恢复丢失的信息, 提升图像对比度. 尽管传统算法在一定程度上可减少图像模糊程度、 增强边缘、 去除蓝绿, 但传统算法普遍存在颜色主体信息不突出、 清晰度较差、 色彩模糊等问题, 因此还需进一步完善.
近年来, 随着人工智能技术的发展, 深度学习在计算机视觉、 图像处理与分析等相关领域取得了很多成果. 基于深度学习图像修复与增强的研究早期侧重于自然图像. 例如, Dong等[11]提出了一种图像超分辨率重建(SRCNN)算法, 该算法使用卷积神经网络拟合低分辨率图像和高分辨率图像的映射, 是一种端到端的方法, 保证了图像重建达到较好的效果, 目前该算法在医学成像领域具有重要价值. Zhang等[12]提出了一种深度残差网络(RCAN)算法, 通过跳跃链接的残差块构造高频信息的学习网络, 该网络在图像增强领域取得了很好的精度和效果. Zhang等[13]提出了一种简捷快速的神经网络去噪器, 该模型利用变量分裂技术, 去噪先验可作为基于模型优化方法的一个模块解决其他模糊或噪声等问题, 该算法可在低视觉应用中提供良好的性能. 之后, Zhang等[14]又进一步提出了一个深度残差网络的高斯去噪算法, 能对未知的高斯噪声去噪, 可解决高斯、 超分、 JPEG图像的块效应问题. Liu等[15]提出了一种非局部递归网络的图像恢复算法, 通过在神经网络中引入非局部方法, 进行端到端的训练去捕捉一个特征与其邻近的特征相关性, 在一定程度上扩展了网络的宽度, 进而改善了效果. 徐岩等[16]提出了一种基于传统神经网络的水下图像优化算法, 首先根据水下成像模型生成模拟水下图像, 其次建立生成的水下图像与真实水下图像之间的映射关系, 最后神经网络通过这种映射关系提取图像特征, 以减少噪声、 增强清晰度, 从而对水下图像进行恢复, 但由于该网络较小且只有单一的映射学习方式, 所以该算法增强能力较弱. Li等[17]提出了一种端到端的学习方式, 通过大量的训练图像数据集与一些水下的深度数据作为一种端到端的输入, 可粗略学习到水下场景深度估计, 以此恢复图像特征, 增强视觉效果. Liu等[18]提出了一种基于深度残差网络框架的水下图像增强算法, 通过引入超分辨率重建模型的方式提高水下图像质量, 但该方法提取特征能力较差, 导致上采样时信息不能准确还原, 所以图像增强能力有限. Li等[19]提出了WaterNet, 使用大规模真实的水下图像与其相对应的真实图像构建水下增强基准建立水下图像增强网络, 该算法有较好的水下图像增强效果. Islam等[20]提出了FUnIE-GAN网络, 通过对目标函数多方式的调整, 基于图像内容、 颜色、 纹理细节等方面恢复水下图像的真实颜色, 但由于该模型网络较浅, 使网络不能完全学习到图像全部特征而导致泛化能力较弱, 所以该算法具有局限性.
尽管基于深度学习图像修复与增强在自然图像领域已取得显著效果, 但由于水下环境的特殊性, 自然图像的增强算法并不完全适用于水下图像. 基于此, 本文提出一种基于深度卷积神经网络的水下偏色图像增强方法.
1 传统神经网络水下图像优化算法
水下图像增强算法的核心任务是对水下图像去模糊、 去蓝绿偏色, 并实现输出图与清晰图之间端到端的映射, 使两张图像之间差异达到最小化, 用公式表示为
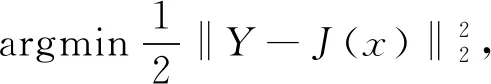
(1)
其中J(x)表示清晰图像,Y表示网络输出图像.算法的目标是寻找一种使函数最小化的映射.
1.1 水下图像成像模型
光在深海环境中传播时, 会受水体的吸收和散射作用. 水下成像主要由相机接收到光线衰减后的直接分量、 前向散射分量、 后向散射分量三部分组成, 如图2所示. 水下相机接收到的衰减后直接分量是指场景反射光在传播过程中经过衰减后到达相机的部分; 前向散射分量是指光经场景表面反射后在传播过程中发生小角度散射的部分; 后向散射分量是指背景光经悬浮粒子散射后到达相机的部分. 考虑到上述成像因素, 水下图像成像模型可表示为
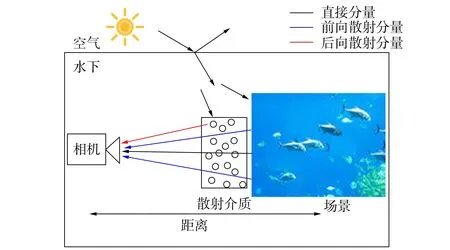
图2 水下成像模型Fig.2 Underwater image formation model
I(x)=J(x)t(x)+A(1-t(x)),
(2)
其中x表示水下图像中第x个像素,J(x)表示水下的清晰图像,A表示大气光散射函数,I(x)表示真实被退化后的水下图像,t(x)表示透射率.透射率与场景深度之间有固定的函数关系, 其相关性可定义为
t(x)=e-βd(x),
(3)
其中d(x)表示场景深度,β表示衰减系数.
1.2 基于深度学习的水下图像增强算法
随着基于深度学习图像处理技术的不断发展, 传统端到端的任务已不能进一步挖掘各领域任务中数据的独特性, 因此如何利用具体的领域知识与模型构建深度学习任务变得更重要.
图3为基于卷积神经网络的经典水下图像增强模型结构.由图3可见, 传统卷积神经网络水下增强网络模型主要由特征提取模块、 特征映射模块和图像重建模块组成.
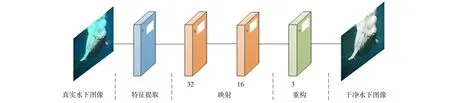
图3 神经网络算法模型Fig.3 Neural network algorithm model
特征提取模块包含一个卷积核为7×7的卷积层, 共64个卷积核.网络通过卷积操作提取特征, 公式为
Y=W*I(x),
(4)
其中Y表示生成的水下图像,W表示卷积核(由n×f×f个参数组成),n表示卷积核数量,f表示卷积核大小,I(x)表示输入的水下图像.
特征映射模块包含两个卷积层.每个卷积层由5×5大小的卷积核组成, 特征提取卷积层经过映射后到达特征映射模块第一个卷积层, 实现了从高维度到低维度的映射, 再经过一个卷积层增加模型的非线性.
图像重建模块主要通过重建后得到的结果图与清晰图像之间的迭代, 不断调整参数.网络采用均方误差(mean squared error, MSE)作为损失函数, 表示为
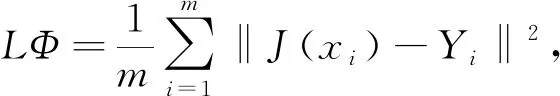
(5)
其中J(xi)为第i组的清晰图像值,Yi为网络中第i组的输出值,m为训练的数据集大小.
上述传统基于卷积神经网络的方法虽然在一定程度上解决了传统水下图像算法的偏色、 清晰度低、 模糊、 色彩单一等问题, 但由于网络较浅、 提取特征不全面, 导致网络泛化性较差, 且网络只有一种端到端的映射学习方式, 使网络不能深度提取特征信息, 导致图像增强效果不显著.
2 本文算法
一般水下图像学习通常采用三通道方法.该方法虽然可在一定程度上学习到水下图像特征, 但由于水下环境复杂, 生成的水下图像严重偏色, 使一般的学习方法学到图像特征的难度较大, 导致学习效果较差.因此, 本文提出一种基于深度卷积神经网络的水下偏色图像增强算法的模型结构, 用于挖掘更多的特征信息及网络输出与标准图像的关系.该算法首先在U-net模型的基础上进一步加深网络, 从而提取到更深层次的特征信息, 用跳跃连接方式进行图像优化; 其次, 网络采用学习输入图像I(x)与输出图像Y之间残余偏色图的方法增强图像, 该方法可提高网络的泛化性.将这种学习策略应用到网络中, 不仅可更深入、 更全面地提取信息, 还可减少过拟合问题, 使网络训练更简捷有效.图4为干净水下图像与偏色水下图像的细节对比.由图4可见, 整体的水下图像偏色严重, 清晰度退化.

图4 干净水下图像(A)与偏色水下图像(B)细节对比Fig.4 Detail contrast between clean underwater images (A) and color cast underwater images (B)
2.1 网络结构
传统的U-net模型由下采样、 上采样和跳跃连接三部分组成. 首先, 输入一张图片, 通过卷积和下采样降低图片尺寸, 提取浅层特征; 其次, 通过卷积和上采样获得深层次特征; 最后, 将编码器和解码器获得的图像特征相结合后输入优化图像. 本文在U-net模型基础上提出一个准确性更高的模型, 由5对编码器和解码器组成, 模型结构如图5所示.
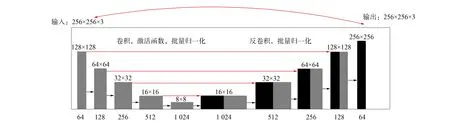
图5 基于深度卷积神经网络的水下偏色图像增强方法模型结构Fig.5 Model structure of enhancement method of underwater color cast image based on deep convolutional neural network
假设给定一个256×256×3大小的水下图像I(x), 输出图像Y, 首先将图像输入到网络中, 该网络由5个编码器和5个解码器组成, 即(e1,d5),(e2,d4),(e3,d3),(e4,d2),(e5,d1), 每个编码器的输出会跳跃连接到对应的解码器, 每个卷积层都有一个3×3的2D卷积, 该网络是一个未使用全连接层的全卷积网络. 此外, 本文算法不直接从输入I(x)到输出Y中学习映射, 而是通过输入图像I(x)与输出图像Y之间学习残余偏色图的能力增强图像, 用公式表示为
d=Y-I(x),
(6)
其中d表示残余偏色图像,Y表示输出图像,I(x)表示输入的水下图像.由于残余偏色图像更稀疏地表达了退化图像与原图的差异, 因此网络可更好地学习偏色残余图像与标准图像的相关性.将这种学习策略应用到卷积层中, 会使训练更有效.
网络中还用到了Leak-ReLU激活函数、 BN层, 同时用反卷积代替传统的上采样方法, 可实现还原图片大小的同时还原信息.
2.2 损失函数
本文的目标是训练模型学习输入和输出的残余能力增强图像.为进一步提高图像中主要成分和边缘细节的清晰度, 本文使用均方误差计算损失函数, 将水下图像输入到已训练好的网络中, 其损失函数为
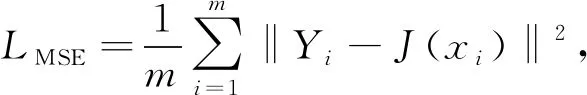
(7)
其中m表示样本的数量,Yi表示模型中生成的第i组值,J(xi)表示第i组清晰图像的值.
此外, 本文还将结构相似性(structural similarity, SSIM)加入损失函数中, 其计算表达式为

(8)
其中:Y表示生成的水下图像;J(x)表示干净的水下图像;μY和μJ(x)分别表示水下生成图像的平均值和干净水下图像的平均值;σ2Y和σ2J(x)分别表示生成图像和干净图像的方差;σYJ(x)表示协方差;C1,C2表示用于维持稳定的常数,
C1=(K1L)2,C2=(K2L)2,
(9)
式中L为像素的范围,K1=0.01,K2=0.03.当生成水下图像与干净水下图像非常相似时, SSIM的值趋近于1. 所以SSIM的损失函数LSSIM可表示为
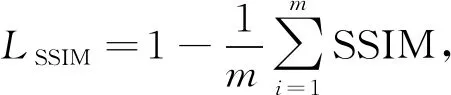
(10)
整体的损失函数可表示为
L=LMSE+LSSIM,
(11)
其中m表示样本数量,LMSE表示MSE的损失函数,LSSIM表示SSIM的损失函数,L表示MSE与SSIM损失函数之和.通过上述定义的网络结构与损失函数, 对整个网络进行迭代训练, 直到达到损失函数值小于阈值或者达到最大迭代阈值为止.获得的网络模型描述了偏色图像与标准图像的映射关系.
3 实 验
实验运行于Linux操作系统, 基于Tensorflow深度学习框架[21]实现, 在配置环境为 1个NVIDIA Tesla K80的条件下训练5 224张成对数据集, 并测试528张验证集. 该网络采用Adam优化器, 参数β1=0.9,β2=0.999, 模型的学习率为0.001, 步数为300×50, 批处理器大小为16, 训练过程中只保留最优模型.
为验证本文算法的有效性, 分别与UGAN[22],UWCNN[23],FastGan[24]算法进行性能对比, 其中UGAN算法包括Pix2Pix算法和Resnt算法. 为保证实验的公平性, 所有算法均用原网络结构和参数, 并使用与本文相同的训练集与测试集.
3.1 实验结果分析
表1为不同算法的峰值信噪比(peak signal to noise ratio, PSNR)和SSIM值对比.

表1 不同算法的PSNR和SSIM值对比
由表1可见, 本文模型的PSNR评价指标高于其他模型, SSIM评价指标也具有很大优势, 生成的图像与原图差距最小. 该结果表明, 本文算法在处理颜色校正、 增强对比度、 优化图像细节、 提高图像质量等方面均优于其他4种对比算法.
在相同数据集下, 本文算法与其他算法处理图像细节的比较结果如图6所示. 由图6可见, Pix2Pix和Resnet算法处进图像细节较清晰, 但没有针对主体信息进行增强; UWCNN算法对图像颜色修正效果不明显; FastGan算法未对生成图像进行约束, 使增强的图像细节信息丢失并有噪声. 本文算法引入了结构相似性损失, 对输入图像和增强图像之间的特征结构信息进行约束, 使生成的图像保持主体信息完整性, 并且可有效去除偏色, 提高对比度. 因此, 本文模型生成的图像最接近真实图像的视觉效果.

图6 各类算法处理图像的细节对比Fig.6 Detail contrast of image processing of various algorithms
图7(A),(B)分别为不同算法的PSNR值和SSIM值对比. 由图7可见, 本文算法与其他算法相比有明显优势, 对去除海洋生物图像的蓝绿色, 增强图像的对比度效果更好.
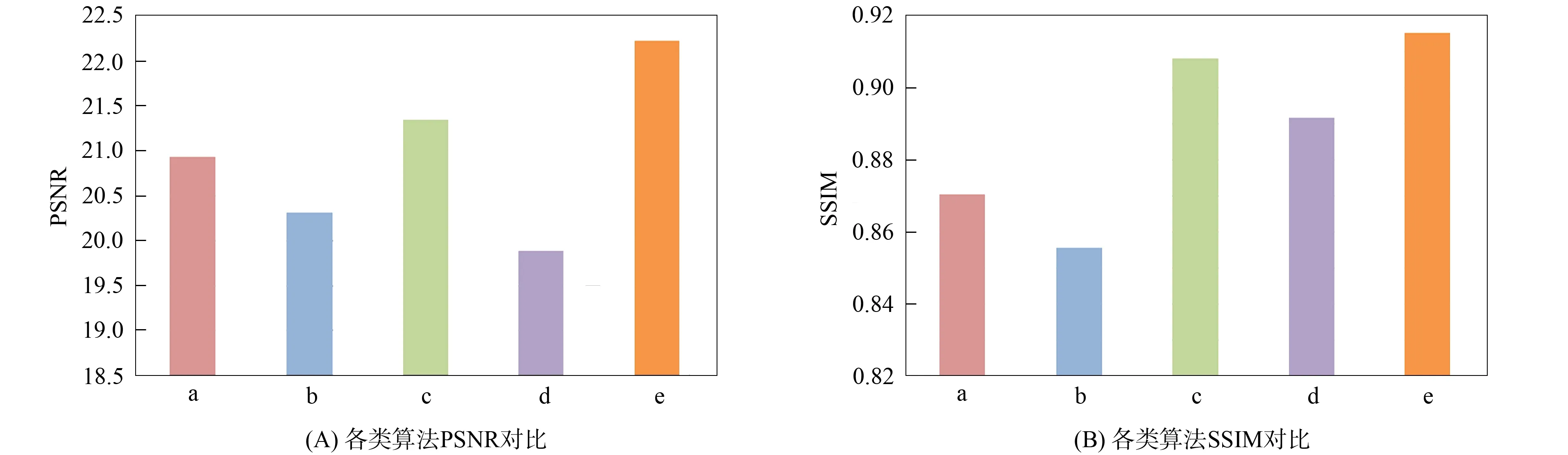
a. Pix2Pix算法; b. Resent算法; c. UWCNN算法; d. FastGan算法; e. 本文算法.图7 不同算法的评价指标对比结果Fig.7 Contrast results of evaluation indicators of different algorithms
3.2 算法的收敛性分析
下面对本文算法的收敛性用数据结果的数据指标曲线图进行测量与分析. 图8(A)为本文算法的损失函数下降曲线, 其中蓝色线表示本文算法在训练过程中的趋势, 红色线表示在验证过程中的趋势. 由图8(A)可见, 当网络训练超过100轮时, 本文网络输出已接近目标精度. 图8(B)为本文算法输出结果的峰值信噪比变化曲线. 由图8(B)可见, 随着算法损失函数的不断下降, 输出结果的效果不断改善, 峰值信噪比不断增加, 在第100轮时达到最高并趋于平稳. 通过算法的收敛性和有效性指标分析可见, 本文算法可在有限时间内收敛, 且收敛后可得到较高的修复结果.
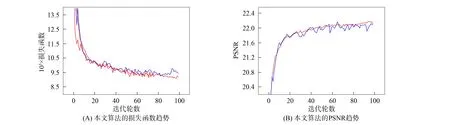
图8 本文算法的收敛性分析Fig.8 Convergence analysis of proposed algorithm
综上所述, 本文针对水下图像偏色失真的问题, 提出了一种基于深度卷积神经网络的水下偏色图像增强算法, 有效解决了水下图像的偏色、 模糊等问题. 该算法首先在U-Net模型的基础上构建一种卷积神经网络, 训练网络学习图像输入与图像输出的色彩差异; 其次, 用损失函数提高输入与输出图像的相似度, 在视觉上提高了水下图像质量. 对比实验结果表明, 对解决水下图像偏色失真等问题, 本文算法优于其他算法.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
电子制作(2019年19期)2019-11-23
中国生物医学工程学报(2019年5期)2019-07-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年3期)2017-11-23
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
