
一种应用于语义分割的新型亲和力监督方法
2021-07-24 09:30曹露濛杨周旺
网络安全与数据管理 2021年7期
曹露濛,杨周旺
(中国科学技术大学 大数据学院,安徽 合肥230026)
0 引言
语义分割是计算机视觉中一项具有挑战性的任务,在自动驾驶、机器人、卫星、农业、医疗诊断等领域有着广泛的应用。它是一项稠密分类任务,旨在对图像进行像素点级别的分类。由于卷积神经网络技术的迅速发展,许多语义分割神经网络应运而生。例如,FCN[1]使用卷积层来代替完全连接层,使得神经网络能够适应任何输入大小。Deeplab[2],PSPNet[3]采用空间金字塔池化来提取不同尺度的特征,然后合并特征来获取不同尺度的上下文信息。长期以来,研究者们致力于特征复用方法和注意机制来设计分割网络[4-6]。使用残差和密集的跳跃连接来聚合和复用不同层的特征,使得语义分割更加准确,并使梯度更容易反向传播。注意力模型[7-9]和非局部模型[10-11]弥补了卷积核的局部局限性,可以捕获长程依赖。最近的研究显示了像素分组的重要性[12-15]。Zhong Zilong等人[12]提出语义分割可以分为两个子任务:显式像素预测和隐式像素分组。Yu Changqian等人[13]使用标签对类别内和类别间的先验知识进行建模,以指导网络的学习。KE T W等人[14]提出了一种自适应亲和场(Adaptive Affinity Field,AAF)来捕获和匹配标签空间中相邻像素之间的语义关系。Jiang Peng等人[15]提出了一种扩散分支,它由一个用于得分图的种子子分支和一个用于像素级相似性的子分支组成。条件随机场(Conditional Random Fields,CRFs)[16-18,2]方法用于语义分割,利用上下文信息优化网络输出,这是一种统计方法,用于对相似像素进行分组,并通过能量函数优化得分图(score map)。以前的许多CRFs都是对网络输出的后处理。VEMULAPALLI R等人[17]和CHANDRA S等人[18]在CNN中引入了高斯条件随机场,并取得了很好的效果。
语义分割网络中的先进模块,如注意机制、非局部模型、亲和力传播机制等,需要很高的计算开销[7,11,19]。这主要是因为亲和矩阵太大了。在许多实际应用中,本文需要一个轻快的网络来处理GPU限制和实时性要求等需求。除了设计轻巧高效的网络[20-22],探索在不增加额外计算负担的情况下改进原始语义分割网络的方法也是非常有意义的。本文注意到,在像素分组方法中,建立成对关系模型非常重要。受先前利用位置和特征向量进行二元计算工作[11,15-16]的启发,本文设计了新的标签亲和力矩阵[13-14],并将其与分数图(Softmax之前的特征图)连接起来,作为相似性的惩罚。与以往的工作[13-14]不同,本文以回归的方式建立了一个非局部亲和性监督模型。本文还设计了一个平方根核用于亲和性计算,使得回归惩罚具有良好的数学解释性。此外,本文采用空间金字塔池模块来聚合不同尺度的信息,同时减少计算负担。本文的主要贡献可以概括为三个方面:
(1)本文提出了一种新的辅助损失函数,它提供了语义分割任务中交叉熵损失无法提供的二元形式监督。
(2)本文以回归的方式建立二元成对损失函数,帮助解决基于分类的问题,并且这在数学上可解释。
(3)本文的模型没有增加网络模型的推断计算开销,只增加了少量的训练计算开销,并且对GPU内存需求不高。
1 相关工作
1.1 交叉熵(Cross-Entropy,CE)
交叉熵损失是分类任务中广泛使用的一元损失函数。语义分割任务主要使用的损失函数是基本的CE损失,此外还有一些补充。OHEM算法增加了错误分类样本的权重。Focal loss[23]降低了易于分类的样本的权重,使模型更加关注难以分类的样本。IOU损失和Teversky损失提供了粗粒度上的监督。Dice loss的作用是对背景和前景信息进行区别。
语义分割中的一个像素点位置的交叉熵损失为:

其中yi∈{0,1},且yi只在一个维度上等于1,其他维度均为0,构成一元形式的监督。
1.2 成对建模(pair-wise modeling)
条件随机场(CRFs)在一元形式的监督基础上加入了二元形式的监督信息。通过引入能量函数(energy function)将i,j位置的成对关系引入惩罚函数,典型的CRFs惩罚可以写作:

其中θi是一元势函数,输入是神经网络的得分图Score Map,θi,j是二元势函数,计算的是i,j位置像素点的相似性。目标是使得整体能量函数下降,迫使像素点相似的位置预测结果相同。
非局部(Non-local)模型[10-11]和许多注意力(attention)模型[7-9]也集中于利用(xi,xj)的二元计算,其中(xi,xj)是特征层的矢量。在这些模块中,经常使用对亲和矩阵的行向量进行SoftMax变换归一化,产生特征融合权值,以便在空间和通道方面捕获长程关系。因此,亲和矩阵在成对建模中占有核心地位。要建立成对关系的模型,假定xi,xj是i,j位置的特征向量,定义相似性核函数s(xi,xj),可以有点积的形式L1距离的形式|xi-xj|,指数函数的形式等。本 文 采 用 平 方 根 点 积 形 式是经过Softmax归一化之后的特征向量,既可以保留概率信息,还可以保证亲和力矩阵的计算有界,从而保证整个模块是李普希兹(Lipschitz)连续的。
1.3 空间金字塔池化
He Kaiming等人[25]将空间金字塔池化成功地应用到目标检测任务中,CHEN L C等人[2]使用不同采样权重的扩张卷积作为池化层的替代,并设计了一个空洞空间金字塔池层(Atrous Spatial Pyramid Pooling layer,ASPP)来处理多个尺度。PSPNet[3]在特定层之后进行空间金字塔池化,将不同尺度的上下文特征嵌入到网络中。Xu Mengde等人[11]修改了空间金字塔池化模型以适应非局部模型,用于减少计算负担。本文遵循多尺度池化策略来构建非局部的关联模式。
2 方法
2.1 标签亲和力矩阵
语义分割的标签是一个具有离散值的单通道图像,每个值表示一个类。生成标签亲和力矩阵的操作类似于许多视觉任务中的自注意操作:给定尺寸为1×W×H的标签图片,将标签平展到一维,得到1×WH向量L,然后得到尺寸为WH×WH的亲和力矩阵M,满足以下要求:

M矩阵非常大,例如,如果标签图片的大小是100×100,那么L的长度是1×10 000,M的大小是10 000×10 000。此外,M在具有许多独特标签的场景中是稀疏的。很难对一个大的稀疏矩阵进行建模。本文采用PSP模块,使用对称PSP模块使计算可行。本文使用最近邻插值将标签向下采样为12×12、6×6的大小,然后将标签展平并将它们连接在一起,得到一个1×180大小的L。图1可视化展示了该矩阵。

图1 标签亲和力矩阵(黑色表示0白色表示1)
2.2 亲和力回归损失(Affinity Regression loss)
一个典型的全局亲和力矩阵是这样计算的:给定一个输入特征:X满足X∈RC×H×W。其中C、W、H分别表示特征通道数量,特征长度和特征宽度。然后经过三个不同的1×1大小的卷积层,WφWθWγ三个卷积将X映射为三个不同的嵌入特征:φ∈θ=Wθ(X),γ=Wγ(X),表示新的输出特征 通道 数。将输出得到的三个不同特征进行降维展平,得到维度为的特征,其中L=H×W。可以计算得到亲和力矩阵A:

接下来就是一些常规的归一化运算,例如Softmax运算,在行向量方向进行归一化,得到了调整之后的亲和力矩阵。通常self-attention中的attention运算为:
在语义分割任务的最终输出层中,利用非局部亲和矩阵进行了研究。为了有相同的映射,本文修改了经典的亲和力矩阵,将ϕ、θ、γ设为恒等映射,本文就可以保留类别的通道信息,用以代表预测的概率。首先,进行Softmax变换,使信道信息成为概率。然后本文在嵌入特征上进行平方根运算。最后,本文计算了亲和矩阵A,用以表示每个空间坐标点之间的相似性。
为了降低非局部亲和力模型的计算复杂度,之前的许多工作[8,11]采取的技巧是减少亲和矩阵A的维数,实验结果证明,这样做不仅能减少计算量,降低内存需求,还能显著提高性能。本文遵循了前面的工作[11],并采用了两种尺寸的下采样操作。假设得分图的大小为(C,W,H)。本文将分数映射的样本降到(C,12,12)和(C,6,6),然后将它们平展到(C,144)、(C,36),并将两个嵌入特征拼接起来,以获得(C,180)嵌入特征。标签操作与特征向下采样位置对齐。然后本文计算亲和力矩阵,得到(180,180)大小的亲和力矩阵:

本文通过均方误差损失将亲和力矩阵与标签亲和矩阵进行关联。亲和力回归损失为(Affinity Regression loss,AR loss):

整体下降函数由分类下降损失函数Cross-Entropy和亲和力回归损失函数Affinity Regression组成:

参数λ设置为0.1。
2.3 亲和力回归的数学含义
在经典的注意力模块中,亲和力矩阵通常是这样计算的:

而在本文的实验设置中,ϕ=X,θ=X,而X是神经网络的得分图(Score Map),并且经过了下采样拼接和通道维度的Softmax归一化。
假定pi表示XT的第i行向量,pj表示XT的第j行向量,那么:

由柯西不等式(Cauchy inequality)可以推出:
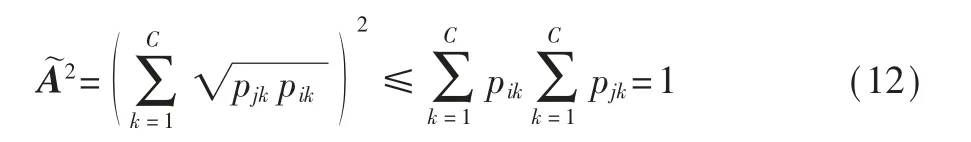
柯西不等式成立的条件是:

其中λ为实数。这要求pi、pj是一样的,即λ=1,并且pi、pj分布越相同,A˜越趋近于1。 反之pi、pj分布越不相同,越远离1,趋近于0。
另一方面,从排序不等式来看:
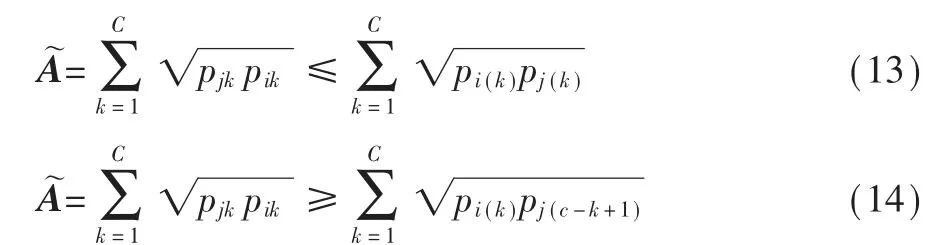
其中pi(k)、pj(k)是将非负实数序列按照从小到大顺序排序后得到的第k项。
由排序不等式性质可以得知:当pik、pjk顺序一致的时候即pik=pi(k),pjk=pj(k)时最大,当pik、pjk顺序相反的时候最小,即:pik=pi(k),pjk=pj(c-k+1)。
在语义分割网络的输出中,每个空间点的通道向量中数值最大的(argmax)通道作为预测类别输出。那么回归1意味着的大小顺序要尽可能一致,特别地,pi、pj数值最大的维度要一致,即位置i、j预测的是同一种类别。反之,回归0,这会增大数值较大的维度乘在一起的惩罚,导致中数值大的维度尽可能与数值小的维度乘在一起,也就是说,i、j预测的是不同类别。不等式的等号是可以取到的。
由上述分析可以知道,建立的回归下降损失函数可以起到一种全局性的结构监督作用,它是基于成对建模的函数,提供二元形式的监督信息,弥补了单一的交叉熵损失Cross-Entropy无法进行成对运算的缺陷。
本文的模型结合了二元惩罚的优点,可以看作是一个辅助损失函数,可以与分割网络同时训练。没有额外的参数被添加到网络中,意味着在网络推断过程中没有增加新的计算开销。而且训练时额外引入的计算量特别小,计算复杂度为O(C×L2),C为通道数量或者标签种类,L是亲和力矩阵边长,本文中L具体数值为180。
3 实验
3.1 数据集
NYU Depth Dataset V2[26].NYUv2数据集是一个室内场景数据集,包含1 449对对齐的RGB和深度图像,包括795个训练图像和654个验证图像。该数据集提供了40个类别的分类和13个类别的分类。本文在设置中使用40个类,并且本文没有以任何方式直接或者间接使用深度信息。
3.2 评价指标
语义分割的最主要评价指标就是mIOU,即计算真实值和预测值两个集合的交集和并集之比。本文采用mIOU作为评价指标。
3.3 实验与分析
本文主要采用RefineNet[5]的轻量化版本Refine-NetLW[20]作为骨干网络,该网络在NYUv2数据集上表现良好,且能计算开销小,运行速度快。本文采用了文献[20]的实验设置要求,只使用一块GTX-1080Ti训练,并且没有在验证集上做任何增强处理。
本文对亲和力回归损失AR loss的用法是:先预训练网络至一定的精度,再加入AR loss与CE loss一起进行训练直到收敛。
图2展示了验证集的mIOU随着训练变化的曲线,可以看出加入AR loss之后,网络的性能有了明显的提升。
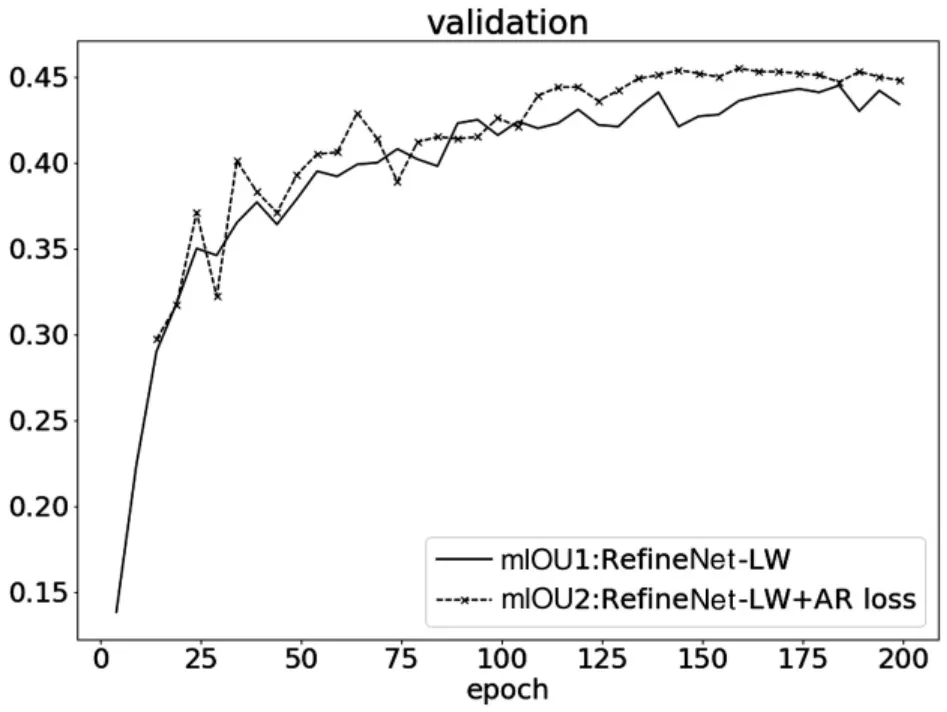
图2 NYUv2训练曲线
之后本文对比AR loss和传统的Dice loss的效果,如表1所示,Dice loss对网络性能的改进不大,只有0.1%,而加入AR loss以后,网络在验证集上提升了接近0.9%,效果非常显著。

表1 Dice loss vs AR loss(NYUv2验证集)/%
而进一步进行实验,采用不同的ResNet骨干网络进行实验,可以发现,基于ResNet152的提升效果比基于ResNet50的效果明显。

表2 替换不同残差网络的影响(NYUv2验证集)/%
本文是基于成对建模的方法,计算了二元形式的惩罚函数,对比之前的二元惩罚函数模型,有非常明显的优势。如表3所示,本文的方法训练开销更小,计算复杂度更低,且不增加推断时的计算开销。

表3 计算复杂性比较
N的大小为500左右,因此系数80,1/10差距显著。CRFs方法是后处理方法,在神经网络运算之后还要再进行统计处理,训练和推断都比较耗时。AAF[14]对每一个点计算3个核的亲和力(3×3+5×5+7×7≈80)。本文与AAF[14]都只需参与训练,不参与推断。
4 结论
本文提出了一种新的使用标签亲和力矩阵作为二元形式监督的范式,在处理语义分割这样的分类问题上,引入回归形式的监督。能够在提高语义分割网络性能的同时,又不引入额外的参数,可以有效地提高语义分割网络的计算效率。在NYUv2数据集上的实验验证了该模型的有效性和高效性。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
新闻传播(2018年11期)2018-08-29
新闻传播(2018年13期)2018-08-29
海峡姐妹(2018年3期)2018-05-09
新闻传播(2016年9期)2016-09-26
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
Coco薇(2015年11期)2015-11-09
