
基于肯德尔系数的改进ID3算法
2021-08-16 11:16侯勋方刚
科学技术创新 2021年22期
侯勋 方刚
(重庆三峡学院,重庆 404020)
1 概述
随着科技的飞速发展,人类积累的数据也越来越多,以数字化储存的数据信息量达到了一个十分庞大的地步,这些数据中也存在着大量有用的信息和知识。同时为了获得这些信息和知识,数据挖掘技术被人们发现并应用,在短时间内就应用于各行各业[1]。
决策树算法是应用最为广泛的数据挖掘算法之一[2],它易于理解和解释。而在决策树算法中,ID3[3]算法是最具影响力和独特地位的算法,之后的许多决策树算法都是由之延伸而来。但是作为基础的决策树算法,ID3算法也存在许多不足之处。ID3算法在分类过程中存在多值倾向问题,且它是贪心算法,存在着局部最优问题。因此本文提出一种ID3的改进,在计算信息增益时引入修正函数以达到属性的信息增益修正的目的,解决多值偏向问题[4]。并利用遗传算法对决策树算法进行优化[5],能有效的解决ID3算法面对的问题。
2 ID3 算法概念及改进原理
2.1 ID3算法概念
ID3算法的核心思想是以信息增益值作为属性选择度量,将具有最大增益值的属性作为最优分裂属性,对属性进行分类[6]。
信息增益指的是划分前后熵的变化,可以用下面的公式表示:

其中,A表示样本的属性,Value(A)是属性A所有的取值集合。V是A的其中一个属性值,SV是S中A的值为V的样例集合。
熵的公式可以表示为:

2.2 肯德尔等级相关系数
肯德尔等级相关系数的定义为:设X、Y两个集合的元素个数均为N,两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,其包含的元素为(Xi,Yi)(1<=i<=N)。当集合XY中任意两个元素(Xi,Yi)与(Xj,Yj)满足Xi>Xj且Yi>Yj或Xi
其计算方式如下所示:
(1)当集合中不存在Xi=Xj或Yi=Yj的情况时;

其中C表示XY中拥有的同序对元素对数;D表示XY中拥有的逆序对元素对数。
(2)当集合中存在Xi=Xj或Yi=Yj的情况时;

将X,Y中的相同元素分别组合成小集合,ti(或ui)表示X(或Y)中第i个小集合所包含的元素数。
τ的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的[8]。
2.3 基于肯德尔等级相关系数的ID3算法实现
若训练集A是由n个条件属性X和一个决策属性Y构成,我们可以把n个条件属性看成是随机变量,表示为Xp(p=1,2,…,n),决策属性可以看成是随机变量Y[5]。
令x,y是抽自两个不同总体X,Y的样本,其观察值表示为x1,x2,x3,…,xn和y1,y2,…,yn,将它们配对成顺序(x1,y1),(x2,y2),…,(xn,yn)。其中Xi,Yi的大小依据是用户预先设定Y的排序以及X的排序。
例如Y内包含数据有两个值,则设定其为1和2,y1值为1,y2值为2则y1 ID3的改进算法在ID3算法公式(2)的基础上引入系数θ。公式定义如下: 运用公式(6)计算每个属性的Gain(S,A),把Gain(S,A)最大的属性设为决策树的划分节点,然后不断重复以上的过程得到最终的决策树。 根据一个实例对上述的优化算法进行比较分析。在这里我们选择西瓜数据集进行分析。其中训练样本实例如表1所示。 表1 训练集样本实例 通过计算我们可知,西瓜数据集信息熵为: 同理可计算得:Gain(根蒂)=0.143 ;Gain敲声)=0.141 ;Gain纹理)=0.381 ;Gain脐部)=0.289 ;Gain触感)=0.006 。 对训练集进行等级数字化之后,由肯德尔相关系数计算公式可得:τ(色泽)=0.20 ,τ根蒂)=0.34 ,τ敲声)=0.34 ,τ纹理)=0.63 ,τ脐部)=0.50 ,τ触感)=0.09 。将求得的系数带入ID3算法中可得到改进后的信息增益为:Gain色泽)=0.109 ×1-|τ(色泽)|)=0.0872 ;Gain根蒂)=0.143 ×1-|τ(根蒂)|)=0.0944 ;Gain敲声)=0.141 ×1-|τ(敲声)|)=0.0931 ;Gain纹理)=0.381 ×1-|τ(纹理)|)=0.1410 ;Gain脐部)=0.289 ×1-|τ(脐部)|)=0.1445 ;Gain触感)=0.006 ×1-|τ(触感)|)=0.0055 。由于Gain脐部)>Gain(纹理)>Gain(根蒂)>Gain(敲声)>Gain(色泽)>Gain(触感)。脐部属性的值最大,所以我们选择脐部属性作为划分该决策树的根节点,然后不断重复以上的过程得到最终的决策树。通过与ID3得出的信息增益进行比较,乘以相关系数使得结果得到了一定的修正,避免了偏向属性个数过多的情况。 为了验证改进算法的有效性,引入UCI数据集中的若干数据在weka平台上进行仿真验证。实验结果如图1所示。 图1 准确率对比 通过实验结果的对比,可以看出改进后的算法的准确率要明显优于原算法。能够帮助我们更好的对数据进行决策树分类。 本文通过利用肯德尔等级相关系数的知识对传统的ID3算法进行了优化改进,并且通过实验证明了改进的算法在一定程度上提升了算法的准确率。
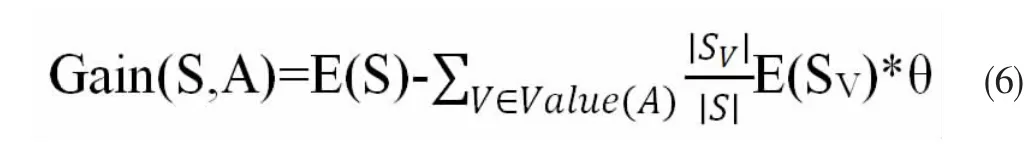
3 实验和分析
3.1 实例分析


3.2 实验结果验证

结束语
猜你喜欢
小资CHIC!ELEGANCE(2021年40期)2021-11-08
发明与创新(2021年17期)2021-07-05
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
伴侣(2018年6期)2018-06-27
国外畜牧学·猪与禽(2018年4期)2018-05-14
科学与财富(2016年32期)2017-03-04
Coco薇(2015年12期)2015-12-10
秀·媛尚(2013年8期)2013-10-12
决策与信息·下旬刊(2013年1期)2013-03-11
