
基于Spark的大数据清洗框架设计与实现
2021-08-16 11:17张菁楠
科学技术创新 2021年22期
张菁楠
(天津轻工职业技术学院,天津 300000)
大数据是目前学术和企业重点关注的问题,是指利用收集到的复杂数据信息从而创造出较为显著的商业价值,充分的挖掘信息的潜在价值。一般来说,在大数据处理的过程中主要包含四个环节,数据采集--数据清洗--数据储存--数据分析。数据清洗在大数据处理中起着非常关键的作用,随着信息时代的到来,大量信息和海量数据引起了人们广泛的关注,也由此加强了对数据清洗的深度研究和分析。传统的数据清洗方法已经难以适应现代数据技术的发展,由此文章提出基于Spark的大数据清洗框架,通过组合和串联的方式来完成数据清洗的过程,并实现数据清洗的优化。
1 Spark——ETL大数据清洗框架
1.1 框架介绍
Spark——ETL技术框架的核心是为了解决大数据清洗问题。即大数据清洗系统内包含多个大数据清洗操作单元,在数据清洗的过程中通过不同清洗单元的组合形成一套完成的清洗流水线,从而开展清洗工作。在Spark--ETL系统中清洗单元具有一定的独立性,通过RDD的作用促进单元之间的联系,实现数据信息的共享和传递,而单元的主要作用体现在原始数据从获取到清洁直至存入大数据库的过程。在大数据清洗流水线运行的过程中也包含多个步骤,如提取、转化等等,在这些步骤当中包含以上或以上的大数据清晰操作单元。
Spark-ETL技术框架具有以下几个方面的特征:
第一,高性能处理。Spark-ETL技术框架是以RDD为数据封装对象,利用Spark的分布式计算能力实现数据清晰的系统,其性能较为高效。
第二,面对不同数据源和数据格式能够做到兼容处理,有效的解决了数据的多样性问题。
第三,具有较高的易用性和可扩展性,实现了不同数据单元的数据分享和传递,便于完成较为复杂的清洗任务。
1.2 框架原理
Spark-ETL框架的主要思路是利用清洗任务单元的组合形成较为完整的流水线进而完成数据的清洗工作。在Spark-ETL系统中具备Driver Program和Executor分离设计特性,相对于传统的方式来说,Spark-ETL在保持原有构架的基础上促进了Spark接口的扩展,从而更加的适合大数据的清晰。此外与原生框架进行对比,Spark-ETL实现了工作方式的转变,在大数据清洗的过程中改变了传统的清洗方式,通过串联和组合的方式完成了大数据的清洗,在实际操作的过程中并不需要较为复杂的代码编程,对相关技术人员的Spark编程能力也没有较高的要求,就能够完成大数据的清洗工作。除此之外是清洗流水线的设计,和普通的单线流水线进行对比,增加了多叉树数据结构定义计算流,不仅能够满足Spark的内部计算模式要求,并且通过对计算过程中分支节点数据的缓存,还能够有效的提升计算效率,为大数据清洗的优化打下了坚实的基础。
2 相关技术分析
2.1 Spark Application提交逻辑分析
在Spark集群上Spark Application属于独立运行,每个Application都是相对独立的,有属于自己的Spark Context,彼此之间相互不影响,此外拥有Spark Context对象的程序也可以被称之为Driver。
Spark集群有两个部分组成,分别是Cluster Manager与Worker。在实际运行的过程中也有两种模式,分别是Client与Cluster。Client模式是指在集群外部进行运行的Driver程序;Cluster模式与Client模式刚好相反,在其运行的过程中是在集群内部,由某个Worker启动的Driver程序,在运行的过程中可以将结果在Web UI上进行显示,或者是向某个接受者进行发送。在大数据清洗的过程中,更加侧重于将Driver程序运行在集群外部自行管理,即Client模式,实际整个集群的模块架构如图1所示。
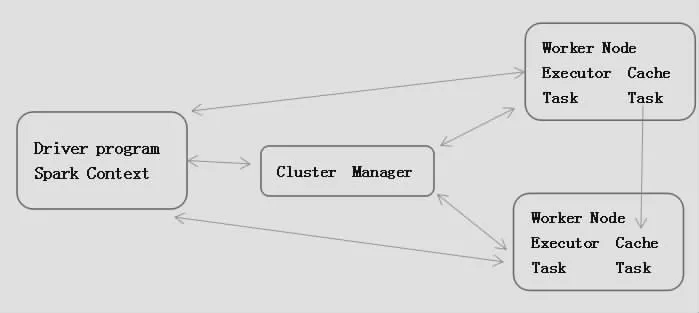
图1 Spark集群架构图
2.2 Spark实现ETL功能分析
目前,在大数据清洗的过程中多数的Hadoop-ETL都逐渐转向Spark-ETL,其根本原因在于基于Spark的大数据清洗其效率更高,可扩展性更强,并且在实际操作的过程中较为简捷。Spark SQL在Spark属于独立的一个模块,其作用是处理结构化数据,为Spark-ETL系统提供了分布式查询引擎和较为抽象的数据结构。除此之外在Spark SQL模块中其数据接口也较为丰富,针对不同的数据来源和数据格式都能够做好兼容和有效处理。另外基于Spark的大数据清洗还包含Spark Streaming,其为实时流数据处理接口提供了较高的可靠性设计。
3 清洗框架设计
3.1 框架架构设计
在Spark-ETL框架中其核心目标是提供大数据ETL系统充分的满足大规模数据处理的需求。因此在Spark-ETL进行框架设计的时候其设计底层是以Spark为基础,其设计思路为用户通过实际操作的过程配合平台在Spark集群内完成数据的清洗工作。Spark-ETL后台服务系统是以Jar、Context、Job为核心,将Spark Context与实际的Job内容分离,由Server直接管理Spark Context,将提高Jar包,设计成Algorithms的程序,动态扩展到整体平台的大数据处理功能[1]。Spark-ETL框架如图2所示,共分为五部分,分别是Spark-ETL Web Client、Spark-ETL Job Server、Algorithms、Spark SQL、Spark ETL SDK。其中Spark-ETL Web Client与Spark-ETL Job Server属于Web Service平台,Algorithms代表了扩展的大数据清洗任务单元库,通过Web Service平台添加需要的清洗单元,并执行算法任务。Spark SQL则代表了Spark集群,此处用Spark SQL进行标识其目的是为了大数据在清洗处理的过程中主要是依赖于Spark SQL进行完成,进行Spark SQL的标识能够更加的明确,但是在实际过程中Spark SQL所代表的是整个后台计算服务的集群。Spark SQL、Spark-ETL Web Client、Spark-ETL Job Server所代表的是Spark-ETL中最为基础的部分-清洗平台Server系统。Spark ETL SDK模块在实际运行中需要借助Algorithms模块通过SDK接口在Job Server模块完成提交。最后流水线配置设计涵盖在Algorithms单元内[2]。

图2 Spark ETL模块架构图
3.2 Spark-ETL Server设计
Spark-ETL Server可以将其分为三部分。Web Client为前端界面,一方面根据后台的服务来满足设计的需求,另一方面通过运行完善后台服务。在Job Server设计的过程其结构模式参考了Spark-ETL Server的结构设计理念,以Jar、Context、Job为核心完成架构的设计。与此同时Spark SQL模块在Context中实现与Job Server的连接,Spark SQL模块属于Spark集群,Spark是由Spark Context将Job分布到各个计算节点完成运算处理[3]。
3.3 Spark-ETL SDK设计
Spark-ETL SDK连 接 了Spark-ETL Job Server与Algorithms两个模块,将Spark Context由Job Server传入到Algorithm程序内,使其完成Spark Application。在实际操作的过程中无需对原有的平台架构进行改变,并在此基础上提高了便捷性,增强了拓展性[4]。
在Spark-ETL SDK设计的过程中可以将其分为两部分组成。一是Spark Job的接口定义,将清洗单元与Job Server有效的连接在一起;二是连通Spark Job,利用RDD实现了不同清洗单元的连接,促进了数据的分享[5]。
3.3.1 Spark-ETL Spark Job接口
图3为SDK Spark Job接口设计图,SDK Spark Job运行的主要目的是能够支持不同类型的Context,以Spark JobBase特质为基类,其他的特质定义继承Spark JobBase并且定义其中的类型C,一般为Spark Context或者是SQL Context。
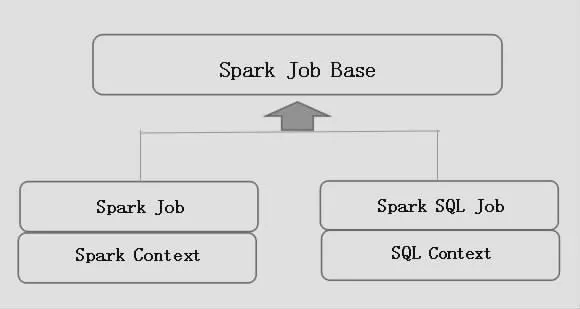
图3 SDK接口关系图
3.3.2 Spark-ETL Share RDD接口
RDD数据共享是指在不同的Spark Job之间可以共享RDD数据,上一个运行的Job结果可以作为下一个Job继续使用,使得数据处理工具之间能够协作完成任务[6]。在之前的设计当中,Spark Job继承了Spark Job的特质,而在本文中提出了一种个更为简单的共享RDD的设计方法-依赖Context管理的方法,整体的结构设计方式如下:

图4 RDD数据共享设计类图
结束语
总的来说,在信息技术快速发展的背景下,Spark的产品也会越来越高,Spark-ETL系统框架的设计通过清洗单元的组合形成大数据流水线从而完成数据的清洗,促使数据清洗工作变得更加高效,在未来的发展中将不断完善Spark-ETL系统框架,为大数据技术的发展做出了卓越贡献。
猜你喜欢
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
纺织科学研究(2021年6期)2021-07-15
电子制作(2019年19期)2019-11-23
军事运筹与系统工程(2019年4期)2019-09-11
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
信息化建设(2019年2期)2019-03-27
永善文学(2017年1期)2017-07-18
