
水库移民生产生活水平综合评价方法研究
2021-08-25 06:14许桂生苑鹏飞冯湘萍郑凯鑫董鹤亭
人民长江 2021年6期
许桂生 苑鹏飞 冯湘萍 郑凯鑫 董鹤亭


摘要:移民生产生活水平的综合评价是水库移民安置及后期扶持效果评价的核心内容。基于广东省大中型水库移民后期扶持政策实施情况的监测评估调查数据,从指标遴选、分级标准、评价方法3个方面(全过程)对此进行了研究。首先,利用复相关-信息灵敏度方法从海选指标中遴选出信息重叠度低的关键指标,构建移民生产生活水平的评价指标体系;其次,由指标的数据场势值计算初始聚类中心,再根据K均值聚类法确定各指标的分级标准;最后,采用基于熵权法的综合评分法对移民的生产生活水平进行评价。根据评价结果分析比较了不同地区的后期扶持工作,结果表明,该方法与现有的移民生产生活水平评价方法相比,更加客观、合理,可为后续工作的开展提供参考意见。
关 键 词:
水库移民; 生产生活水平; 综合评价; 复相关-灵敏度法; K均值聚类法; 综合评分法
中图法分类号: D632.4
文献标志码: A
DOI:10.16232/j.cnki.1001-4179.2021.06.035
0 引 言
自20世纪50年代以来,中国兴建了大量的水利水电工程,发挥了显著的社会经济效益,但同时也造成了大量的水库移民。据统计,截止2014年底,中国已建、在建水库移民总数已达2 200万人[1],随着172项重大水利工程的陆续开建,目前移民总数已增至2 500万人左右。有研究表明,中国早期的水库移民的确在很大程度上转移或制造了贫困[2-3],加大了移民与非移民的收入差距,也引发了许多社会问题[3-4]。为此,国务院明确要求移民安置应使移民生活达到或超过原有水平,对移民生产生活水平恢
复情况应进行监督评估,对水库移民后期扶持政策实施情况应进行监测评估[5]。移民生产生活水平评价是水库移民安置及后期扶持工作评估的核心内容,其本质是一个综合评价问题。该问题的关键在于构建科学的移民生产生活水平评价指标体系、确定合理的指标分级标准和指标权重、选择合适的综合评价方法。
科学的评价指标体系是合理评价的基础,应当全面、科学地考虑各个影响因素,指标过少则可能会遗漏重要信息,指标太多则会增加问题的复杂性,不可避免地造成信息重叠,这种信息的重叠有时甚至会抹杀事物的真正特征和内在规律[6]。但现有研究主要依赖主观分析确定评价指标[7-10],鲜见对评价指标的客观遴选。李娜等[11]采用主成分分析法评价移民生产生活水平,但主成分分析法对重叠信息的剔除无能为力,因而并未真正实现指标遴选。本文首先从移民的收入水平、消费水平、生产条件、生活条件、基础设施、发展保障等6个方面海选出51个指标作为备选指标集,再通过复相关-信息灵敏度法[12]剔除其中信息含量低和信息重叠度高的指标,实现了对指标的客观遴选。
在对水库移民工作进行评估时,我们常常将移民的生产生活水平分为“很差、较差、一般、较好、很好”5个等级,但在确定分级标准时,主要依赖主观分析[13]。聚类分析可以通过对样本数据的聚类从而实现等级划分和确定分级标准[14],而K均值聚类法就是其中常用的一种方法,具有计算方便、准确度高等优点。但该方法需要人为指定初始聚类中心,且聚类结果依赖指定的初始聚类中心,有时只能获得局部最优解[15]。本文采用基于数据场的K均值聚类法[16],通过计算指标数据的势值,确定初始聚类中心,克服了传统K均值聚类法存在的主观性,使得指标分级标准的确定更为客观。
确定指标权重的方法主要有层次分析法,熵权法,灰色关联度法等。本文采用熵权法确定移民生产生活水平评价指标的权重。
在确定了评价指标、分级标准和指标权重后,即可直接对样本的单指标得分加权求和计算综合评分,根据样本的综合评分即可直接定级或排序,无需且不适合再使用相对复杂的模糊综合评判技术。这是因为在分级标准明确后,各等级也就不再属于“模糊集”,对确定的指标数据而言,其所属等级也是确定的;其次,模糊综合评判常采用的最大隶属度原则并不合理,陈守煜提出应采用级别特征值原则进行判别[17]。为验证综合评分法的有效性,本次研究前用该方法对文献[18]的围岩稳定性进行了判别,得出了与陈守煜[19]相似的结论。
本文在广东省大中型水库移民2019年度后期扶持监测评估工作的基础上,利用10个县100个移民村2 000户移民家庭的抽样调查数据,从评价指标遴选、分级标准、评价方法3个方面对移民生产生活水平的综合评价问题进行了研究。
1 数据来源与指标遴选
1.1 数据来源
广东省有搬迁农业人口后期扶持任务的水库共329座,全省共有大中型水库移民154.19萬人。为了对2019年度大中型水库移民后期扶持政策实施情况进行监测评估,本文基于广东省10个样本县的抽样调查工作,选取了46个乡镇100个移民村2 000户移民家庭较为全面的调查数据。
1.2 确定备选指标集
结合已有研究成果、理论分析及实践经验,根据评价对象及评价目标设置准则层,再根据“全面性、可观测性”原则进行指标海选,从收入水平等6个方面确定了51个指标,去除“建房支出比例、住房质量、耕作半径、有线电视覆盖率、适龄儿童入学率、医疗报销比例、发病死亡率、劳动技术培训比例、平均寿命、正规教育规模、成人教育规模、绿化率、垃圾集中处理比例”等13个缺乏监测数据的指标后,得到了含38个指标的备选指标集(见表1)。
1.3 指标遴选
1.3.1 指标数据标准化
在对指标进行遴选前,首先按min-max原则对原始数据进行标准化处理,以消除各指标量级和量纲不同的影响,公式为
xij=Xij-min1≤j≤nXijmax1≤j≤nXij-min1≤j≤nXij
(1)
式中:i=1,…,m,j=1,…,n,m为指标总数,n为样本总数;Xij,xij分别为第i个指标第j个样本的原始数据、标准化数据值,minXij,maxXij分别为第i个指标样本数据的最大、最小值。
1.3.2 指标相关性分析
对同一类别的指标计算复相关系数,对复相关系数最大的指标,若该指标的复相关系数大于设定的临界值VR,则剔除该指标。循环处理,直至各类别所有保留指标的复相关系数均小于VR。一般VR可取0.80~0.95,本文取0.90。
1.3.3 指标灵敏度分析
对所有保留指标按公式(2)计算其信息含量,按照信息含量的大小对指标进行降序排列,按设定的累计信息灵敏度值VI截取保留指标。一般VI可取0.70~0.95,本文取0.85。
Ii=1n-1nj=1(xij-1nnj=1xij)21nnj=1xij(2)
式中:Ii為第i个指标信息含量。
取VR=0.90,VI=0.85时,指标遴选的结果如表2所列。通过计算复相关系数和指标累计信息灵敏度,剔除了9个对评价结果影响较小的指标,最终确定了人均可支配收入、人均消费支出、水浇地比例、人均住房面积、亮化照明比例、贫困人口比例等29个指标的评价指标体系。
2 指标分级与赋权
2.1 指标分级
为客观地确定各指标的分级标准,采用了K均值聚类法。同时为克服传统的K均值聚类法人为指定初始聚类中心的不足,本文基于数据场势函数理论确定了初始聚类中心,然后再使用K均值聚类法得到指标分级结果。
2.1.1 数据场理论
数据场势函数反映了一个数据对象受到其他所有数据对象的影响程度,克服了传统聚类算法仅考虑2个对象之间影响关系的局限性,认为空间中任一点的状态是其他所有的对象共同作用的结果,能够获得更加科学合理的聚类分级结果[20]。指标数据的势函数φ(x)定义如下[21]:
φ(x)=1nnj=1e-(‖x-xj‖σ)2(3)
式中:‖x-xj‖表示对象x到xj的距离;σ一般可取为1。
2.1.2 基于数据场的K均值聚类指标分级
K均值聚类算法是一种迭代求解的聚类分析算法。首先指定要形成的聚类数k,再随机选取k个对象作为初始的聚类中心[6]。在引入数据场概念后,将不需要人为指定聚类中心,而是从各个指标样本数据间的相互作用力出发,由势函数计算公式(3)得到每个样本的势值,所得势值越大说明该样本点与其他样本数据的相互作用越大,该点就可以作为聚类中心的备选值。根据大量实例计算经验可知,基于数据场的K均值聚类法比传统算法聚类正确率更高[16]。水库移民生产生活水平评价指标分级具体算法步骤如下:
(1) 对表2筛选保留的29个评价指标样本数据进行标准化,根据公式(3)按等级计算各个评价指标下样本数据xi的势值;
(2) 分析每个评价指标样本数据势值的极大值点,确定各个评价指标的初始聚类中心;
(3) 利用K均值聚类算法对各个指标数据进行分级聚类,得到最终聚类结果。
下面以“人均可支配收入”为例,对基于数据场的K均值聚类算法计算过程进行说明。根据公式(3)计算数据场势值,可得到2 000户样本家庭的人均可支配收入势值分布情况(见图1)。本文将人均可支配收入分为5个等级,按等级找到5个势值极大值点,其对应的人均可支配收入分别为9 260,13 000,16 137,19 872,29 377,以此作为初始聚类中心。将人均可支配收入样本数据以及5个初始聚类中心数值代入SPSS软件中的K-均值聚类算法进行聚类分析,求得最终聚类结果作为人均可支配收入的分级标准(见表3)。
对各个指标数据重复以上步骤共得到29个评价指标的分级区间(见表4)。
2.2 指标赋权
熵权法是一种以评价对象中各项评价指标所提供的信息含量为依据,确定权重值的客观赋权法。熵权法确定权重的计算步骤[20]如下:
(1) 为了消除指标计量单位的影响,要对评价指标进行归一化处理。设Xijn×m为同趋势化后的指标矩阵,Zijn×m为归一化后的指标矩阵,则:
Zij=Xijni=1X2ij(4)
(2) 计算第i个样本第j项指标值的比重:
Pij=Zijni=1Zij(5)
(3) 计算指标信息熵:
Ej=-Kni=1(pijlnpij)(6)
式中:常数K=1/lnn。
(4) 计算权重:
Wj=1-Ejnj=1(1-Ej)(7)
将广东省10个样本县的监测评估数据,代入公式(4)~(7)得到各指标权重(见表5)。
3 综合评价与分析
3.1 综合评分法
在传统的综合评价分析中,不少学者采用了基于最大隶属度原则的模糊综合评判法。但该方法容易导致信息丢失而引起判别结果出现偏差。比如10个评委对某评价对象的较差、中等、优秀进行打分,其结果为4个评委打分较差、3个评委打分中等、3个评委打分优秀,按照最大隶属度原则,其综合评价为较差,但实际情况应该属于中等。
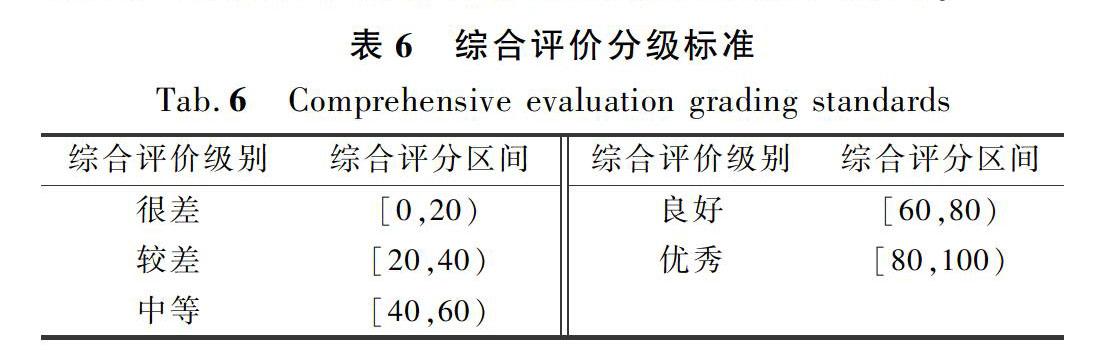
本文基于“加权平均”的思想,提出了综合评分法,可得到更为合理的评价结果。假定指标A划分5个区间等级分别为[A0,A1),[A1,A2),[A2,A3),[A3,A4),[A4,A5),并规定A0为0分,A1为20分,A2为40分,A3为60分,A4为80分,A5为100分。中间3个等级为有限区间,两端的可能为无限区间,也可能为有限。当各等级区间为有限区间时,直接线性插值计算得分。若落在无限区间,即:若最高等级区间为[A4,+∞),则f(x)=100-20ex-A4(x>A4);若最低等级区间为[-∞,A1),则f(x)=20eA1-x(x
结合熵权法计算所得的权重,可得广东省水库移民生产生活水平综合评价分级标准如表6所列。
3.2 评价结果及分析
对广东省10个样本县数据进行计算,由综合评分结果可得,10个样本县综合评级均为中等,其中花都区综合评分最高,为52.66;郁南县综合评分最低,为41.62。可见通过后期扶持,广东省水库移民生产生活水平恢复效果较为显著,虽然不同地区水库移民生产生活水平有差异,但其差距也在逐渐缩小(见表7)。具体分析如下:
(1) 通过对比各样本县反映移民收入水平的多个指标发现,家庭经营性收入和二、三产业收入为移民家庭总收入的重要组成部分,各样本县的家庭经营性收入比例评分均在中等偏上水平,二、三产业收入比例评分接近中等水平,后续仍需加强对二、三产业的扶持。建议各县在后续扶持中结合当地实际适当增加生产开发项目的比重,收入结构多元化发展,引进龙头企业,充分利用当地资源,一、二、三产业融合发展,促进移民增收致富。
(2) 通过对比各样本县反映移民消费水平、生活水平和发展保障的多个指标发现,部分样本县教育支出比例较低,高中阶段入学率不高,后期仍需要加大对移民后代教育问题的关注力度,子女的教育问题所受影响因素较多,如家庭经济水平、当地居民思想观念、当地政策支持力度。建议移民部门在提高当地移民收入的同时,一方面可适当拨付部分资金对贫困移民子女教育进行资助;另一方面也要加大宣传子女受教育的重要性,提高当地移民对教育的重视程度。
(3) 通过对比各样本县反映基础设施的多个指标发现,部分样本县村均卫生室个数和亮化照明比例评分均不高,需要继续完善基础设施建设。当地移民的参与度和意愿对移民村基础设施的建设起着决定性的作用,建议移民部门一方面要结合当地移民村的实际出发,统筹规划,合理配置资源;另一方面也要充分调动当地移民对家园建设的积极性,要培养其“大局意识”,通过加大移民群众的参与度,推动当地基础设施的建设进程。
4 结 论
(1) 本文利用复相关-信息灵敏度方法从海选指标中遴选出信息重叠度低的关键指标,构建移民生产生活水平的评价指标体系。相比于传统上仅仅依靠主观经验对水库移民后期扶持效果评价指标进行筛选,复相关-信息灵敏度方法从备选指标中剔除了信息含量低和信息重叠度高的指标,实现了对指标的客观遴选,并克服了主成分分析法无法实现对重复信息筛选的缺点。
(2) 本文采用基于数据场的K均值聚类法,通过计算指标数据的势值,确定初始聚类中心,克服了传统K均值聚类法存在的主观性问题;建立了针对水库移民后期扶持评价指标的分级标准,克服了传统上依靠专家经验或参考统计公报数据确定评价指标分级标准的缺点,使得指标分级标准的确定更为客观。
(3) 本文提出综合评分法,直接对样本的单指标得分加权求和计算综合评分,根据样本的综合评分即可直接定级或排序,无需再使用相对复杂的模糊综合评判技术,简化了综合评价过程。
參考文献:
[1] 邱元锋,孟戈,WEI Y,等.水库移民满意度影响因素实证分析[J].水利学报,2016,47(5):663-673.
[2] 张绍山.水库移民“次生贫困”及其对策初探[J].水利经济,1992(4):25-28.
[3] 檀学文.中国移民扶贫70年变迁研究[J].中国农村经济,2019(8):2-19.
[4] 姚凯文.水库移民安置研究[M].北京:中国水利水电出版社,2008.
[5] 国务院.大中型水利水电工程建设征地补偿和移民安置条例[M].北京:中国法制出版社,2017.
[6] 何晓群.多元统计分析[M].3版.北京:中国人民大学出版社,2012.
[7] 施国庆,陈绍军,袁汝华,等.水库移民生产生活水平分析与评价方法[J].水利学报,1996(2):51-55,62.
[8] 胡宝柱,赵静,何小龙,等.水库移民经济评价方法研究[J].华北水利水电学院学报,2005,36(2):5-8.
[9] 单颖,左绪海.水库移民安置后评价指标体系探讨[J].人民长江,2010,41(23):26-30.
[10] 牟立.水库移民后期扶持效果评价[D].北京:清华大学,2014.
[11] 李娜,王火根.基于主成分分析的水库移民生活水平综合评价[J].人民长江,2016,47(23):120-125.
[12] 张壮,李琳琳,路云飞.基于复相关-信息灵敏度的C4ISR评估指标体系构建[J].火力与指挥控制,2018,43(10):68-73.
[13] 郑从奇,许彦刚,赵胜,等.水库移民生产生活水平可变模糊评价方法与应用[J].山东大学学报(工学版),2013,43(3):75-81.
[14] 刘玉邦,梁川.基于天气成因和主成分分析的暴雨洪水分级研究[J].水利学报,2011,42(1):98-104.
[15] 蔡蓉蓉,张红武,卜海磊,等.基于水沙组合分类的黄河中下游水沙变化特点研究[J].水利学报,2019,50(6):732-742.
[16] 龚艳冰,杨舒馨,戴靓靓,等.基于数据场K-means聚类的洪涝灾害突发事件分级方法[J].统计与决策,2018,34(20):47-49.
[17] 陈守煜.可变模糊集理论与模型及其应用[M].大连:大连理工大学出版社,2009.
[18] 王广月,刘健.围岩稳定性的模糊物元评价方法[J].水利学报,2004(5):20-24.
[19] 陈守煜,胡吉敏,李敏.水电站导流洞围岩稳定性的可变模糊评价方法[J].北京工业大学学报,2009,35(4):464-469.
[20] 林建潮.熵权法确定评价指标权重在Excel中的实现[J].中国医院统计,2020,27(4):362-364.
[21] 淦文燕,李德毅,王建民.一種基于数据场的层次聚类方法[J].电子学报,2006(2):258-262.
(编辑:谢玲娴)
Study on comprehensive evaluation method of production and living
standard of reservoir immigrants
XU Guisheng1,YUAN Pengfei1,FENG Xiangping2,ZHENG Kaixin1,DONG Heting1
(1.School of Water Resources and Hydropower Engineering,North China Electric Power University,Beijing 102206,China; 2.Guangxi Water Resources and Electric Power Survey and Design Institute,Nanning 530023,China)
Abstract:
The comprehensive evaluation of production and living standards of immigrants is the core content in reservoir resettlement and subsequent support effect evaluation.Based on the monitoring and implementation evaluation data of the later support policies for large and medium-sized reservoirs in Guangdong Province,we study from three aspects(the whole process) of indicator selection,classification standards and evaluation methods.Firstly,the multiple correlation-information sensitivity method is used to select key indicators with low information overlap from all indicators to construct an evaluation indicator system for the production and living standards of immigrants.Secondly,the initial clustering centre is calculated from the data field potential values of the indicators and then the classification standard of each indicator is determined according to the K-means clustering method.Finally,the comprehensive scoring method based on entropy weight method is used to evaluate the production and living standards of immigrants.According to the evaluation results,this paper compares and analyzes the subsequent support work in different regions.The results show that this method is more objective and reasonable than the existing evaluation methods,and can provide reference for the follow-up work.
Key words:
reservoir immigrant;production and living standard;comprehensive evaluation;multiple correlation-sensitivity method;K-means clustering method;comprehensive scoring method
猜你喜欢
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
软件(2017年6期)2017-09-23
发明与创新·中学生(2017年5期)2017-05-12
投资者报(2017年9期)2017-03-14
电子技术与软件工程(2016年23期)2017-03-06
中学生英语·阅读与写作(2014年11期)2015-03-11
中学生英语·阅读与写作(2014年3期)2014-07-29
中学生数理化·高考版(2008年2期)2008-11-01
