
融合多模态影像的阿尔茨海默病多分类诊断模型
2021-08-31 06:09张荣张烁余红梅刘龙
山西大学学报(自然科学版) 2021年4期
张荣,张烁,余红梅,刘龙
(1. 山西医科大学 计算机教学部,山西 太原 030001;2. 山西青年职业学院 计算机与信息工程系,山西 太原 030032;3. 山西医科大学 公共卫生学院,山西 太原 030001)
0 引言
阿尔茨海默症AD 是一种常见的老年神经退行性疾病,临床表现为记忆力减退、失忆、语言能力退化并且难以逆转和控制。文献表明,预计到2050年,全世界AD 症患者将达到1.07 亿人[1]。轻度认知障碍MCI 是AD 和正常衰老NC 的中间状态。研究 表 明,MCI 患 者 比NC 更 容 易 发 展 为AD[2]。所以,更多关注MCI 和AD 的差异研究对AD 的早期诊断有很大帮助。由于MCI 病人在日常生活中并不会有太大影响,表现为记忆力轻度衰退,并且在发病前期不被人重视,这就是MCI 患者延误病情最终发展为AD 病的重要原因。
随着医学影像技术的快速发展,产生了异构的医学图像,如电子计算机断层影像(Computed Tomography,CT)、磁共振影像(Magnetic Resonance Imaging,MRI)和正电子发射断层影像(Positron Emission Tomography,PET)等,这些医学影像对AD 的早期诊断起到了至关重要的作用。为了给医生提供有效、准确、快速的辅助诊断信息,机器学习技术处理多模态影像逐步成为医学研究的热点领域[3]。这种技术通过对不同模态的医学影像的感兴趣区域进行特征提取,并分别对提取的特征进行选择和融合,最后根据选择和融合的特征进行图像的分类和识别。
卷积神经网络(Convolutional Neural Network,CNN)是近些年来发展起来的高效识别模型,广泛应用于图像识别领域,主要的特点是CNN 可以通过卷积和池化操作自动对感兴趣区域进行高效的特征提取,避免传统机器学习方法需要人工提取特征时出现不必要的人为错误。CNN 通过类脑学习的方式,将图像数据从底层到高层逐层进行特征提取,直到提取到适合模型分类的特征,最后通过分类器对目标图像进行分类,以提高识别的准确率。
目前,对单模态医学影像的识别研究已经取得了一些成果,如Sarraf 等[4]用MRI 图像使用CNN 模型对AD 和NC 进行分类,分类准确率达94.3%,但此方法只对AD 和NC 进行分类,没有考虑MCI 的情况。Wang 等[5]设计了一种8 层的CNN 网络模型来辅助诊断AD,准确率提高到97.65%,但同样未考虑MCI 的情况。因此,对于复杂的多模态医学影像数据,如何使用深度学习模型对NC、MCI 和AD进行多分类成为一大挑战。
本文提出了一种基于多模态影像数据,利用深度迁移学习方法对NC、MCI 和AD 进行多分类识别的诊断模型。首先利用迁移学习的方法对VGG 网络进行参数初始化,并用MRI 脑图像和PET 脑图像对网络模型进行训练实现网络参数的微调,构成两个独立的单模态CNN 网络(MRI-CNN,PETCNN),然后分别提取MRI-CNN 和PET-CNN 网络的特征向量并对其进行融合,最后对MRI-CNN和PET-CNN 网络构建全连接层,并利用Adaboost算法对特征进行选择和融合,构建分类器进行分类识别。
1 基础理论
1.1 卷积神经网络(CNN)
CNN 是一种具有深层结构的前馈神经网络,是由输入层、卷积层、池化层、全连接层和分类输出层构成,网络中间多个卷积层和池化层的组合可以看做一个复杂的函数f(·)。原始图像数据首先通过卷积层进行卷积操作后输出特征图(Feature Map),每次卷积操作都可以对输入图像进行一次特征提取,假如有n次卷积操作就可以得到输入图像的n个特征。设Yi为经过第i个卷积操作后输出的特征图,X为原始图像的输入矩阵,则在经过第一次卷积操作 前Y0=X,Yi可 以 表 示 为Yi=f(Yi-1⊗Wi+bi),其中f为激活函数(Activation Function),常用的激活函数有ReLU、sigmoid 等,Wi为第i个卷积层中卷积核的权值,bi为第i个卷积层的偏置值,⊗为卷积操作。
池化层主要是为了减少上一层特征向量的数据维度,还能保留原有重要信息的一种操作。设yi为经过第i个池化操作的结果,有yi=down(xi),其中xi为上一层的特征图,down(·)为池化函数,常用的池化函数[6]有平均池化(Average-Pooling)、最大池化(Max-Pooling)等。
全连接层将经过多次卷积和池化操作的特征图进行全连接,并将特征图展开为一个向量,最后通过激活函数输出结果,实现图像的分类,可表示为:xl=f(wl xl-1+bl),其中f为激活函数,wl为全连接层的权值,xl-1为上一层的特征图,bi为全连接层的偏置值。CNN 原理图如图1 所示。
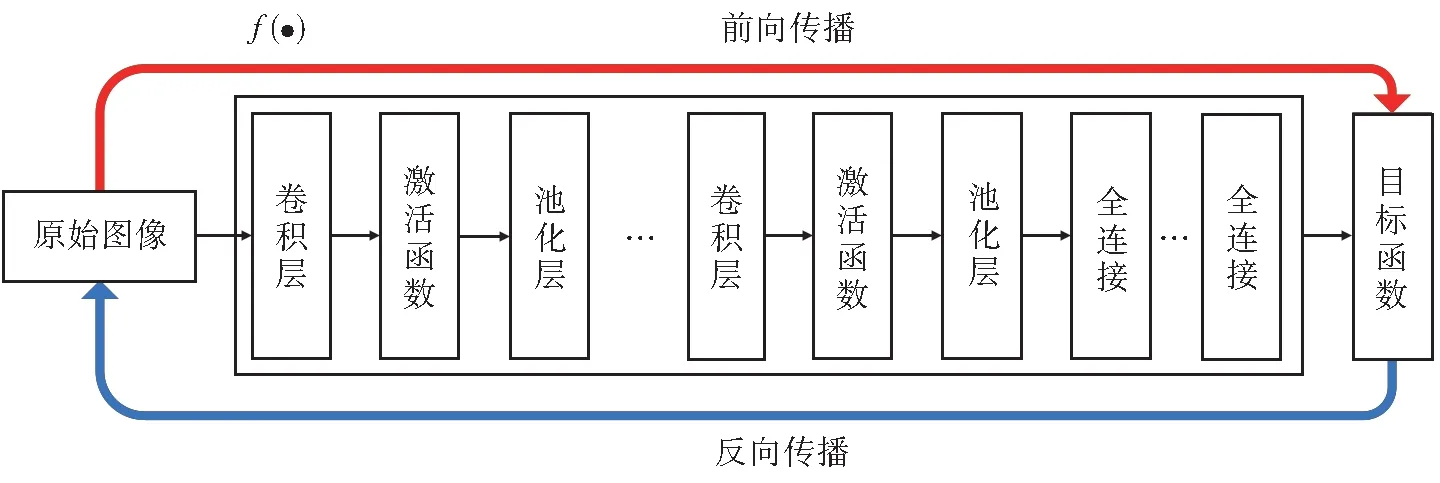
图1 CNN 原理图Fig. 1 CNN schematic diagram
1.2 VGG网络结构
VGG 网络是在2014 年牛津大学VGG 项目组为参加ImageNet 大赛提出的一种CNN 模型,该网络具有非常好的泛化能力,卷积层的通道数随着网络深度的增加而增加,通过该网络可以得到丰富的特征向量。VGGNet 网络具体分为VGG-13、VGG-16、VGG-19 三种类型。本文使用VGG-16进行MRI 脑图像和PET 脑图像的特征提取,网络结构如图2 所示。

图2 VGG-16 网络结构图Fig. 2 VGG-16 network structure diagram
VGG-16 网络输入为224×224×3 的RGB 图像,由1 个输出层、13 个卷积层、5 个池化层、3 个全连接层和1 个输出层构成。表1 列出了VGG-16 网络的具体参数,其中,f为卷积核或池化核的大小,s为步长,d为该层卷积核的通道数(个数),p为填充参数,a为激活函数,C为类别个数。
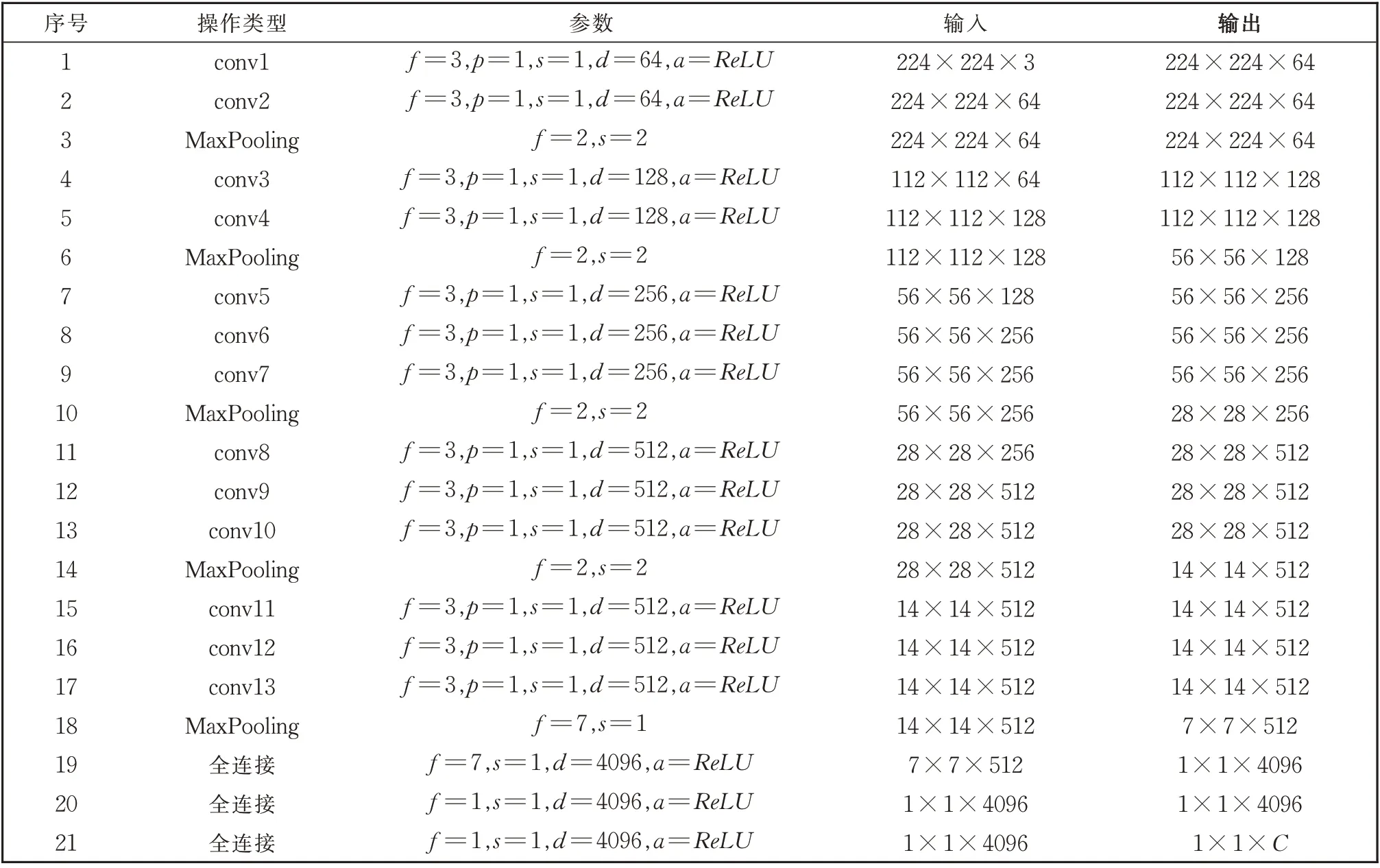
表1 VGG-16网络参数Table 1 VGG-16 network parameters
2 对象与方法
本文设计的基于深度迁移学习的AD 诊断模型的建立主要分为三个阶段:(1)对ADNI 数据集进行图像预处理;(2)利用VGG 网络模型,通过迁移学习的方法对各模态脑图像(MRI 图像和PET 图像)进行特征提取;(3)利用Adaboost 算法对多模态图像提取的特征进行选择和融合,构建同一维度的特征向量,并得到最后的AD、MCI 和NC 的分类结果。总体框架图如图3 所示。

图3 总体框架图Fig. 3 General frame diagram
具体步骤如下:
(1)数据预处理:通过ADNI 公开数据库下载分别带有AD,MCI,NC 标记的MRI 和PET 两个模态影像数据,将每个模态的图像分成训练集和测试集,最后对图像(图像大小为224×224)进行预处理。
(2)对各模态图像进行特征提取:构建2 个VGG 网络,使用迁移学习,优化MRI-CNN 和PET-CNN 两个网络的参数(MRI-CNN 主要用来提取MRI 图像特征,MRI-CNN 主要用作提取PET图像特征),然后将预处理好的各模态的图像通过构建好VGG 网络进行特征提取,为特征选择和融合做准备。
(3)特征选择与融合:使用Adaboost 算法对各模态提取的特征向量进行选择,在训练过程中不断优化各特征的权重,最后将不同权重的特征向量进行叠加融合,再通过激活函数进行分类,得出分类的结果。
2.1 数据来源和预处理
本文图像数据来源为ADNI 公开数据库,ADNI 数据库是由美国多个机构[7]于2003 年创立,该数据库不仅包括多模态的医学影像数据,还包括了具有生物标志物信息和医学评定量表信息的数据,方便研究者对AD 病进行研究。
图像数据全部来源于Philips 系统,其中MRI 图像使用1.5 T 扫描仪以上数据,全部受试者具有18F-FDG 的PET 图 像 和MRI 图 像,实 验 数 据 集 为AD、MCI、NC 三类,共818 名受试者图像信息,其中AD 为167 名,MCI 为301 名,NC 为350 名,每 名 受试者都有一个MRI 图像和一个PET 图像,每位受试者图像都有横断面60 层的图像信息,受试者信息如表2 所示。

表2 受试者信息统计表Table 2 Statistical table of subject information
研究表明图像中大脑组织(灰质、白质等)是否萎缩是早期AD 和NC 区分的重要标志[8]。本文通过对大脑灰质密度图进行分析处理,大脑灰质密度图可以通过Matlab 提供的SPM-12(Statistical Parametric Mapping)工具包完成[9]。处理流程为:对于MRI 图像,由于MRI 的原始图像中都包含头骨等结构,为了降低运算量和提高实验结果,采用SPM-12中的CAT12 工具完成取头骨操作,再对MRI 图像进行图像分割,提取脑灰质、白质等信息。然后将预处理的MRI 脑图像匹配到标准脑空间MNI(Montreal Neurological Institute)模板上。接着将预处理的MRI 图像通过剪切或填充的方式统一图像大小为224×224,为了符合VGG 网络的输入要求,需通过MicroDicom 工具将DICOM 格式转化为png格式的图像。最后为了保证图像的统一性,将MRI的图像体素值归一化为0~255 之间。
对于PET 图像,首先将同一受试者的多个DICOM 格式的图片数据融合为一种PET 图像,其脑部空间和组织结构信息被保留。然后将每位受试者的PET 图像与对应同一样本的MRI 图像进行配准,防止因设备而产生的差异。接着将预处理的PET 图像匹配到标准脑空间MNI 模板上并将PET图像调整为224×224,通过MicroDicom 工具将DICOM 格式转化为png 格式的图像。最后为了保证图像的统一性,将MRI 的图像体素值归一化为0~255 之间。
2.2 基于VGG迁移学习的特征提取
本文基于VGG 网络对每位受试者MRI 和PET的两种模态影像分别进行特征提取,根据CNN 网络学习原理,随着卷积层和池化层的交替对图像的学习和降维,图像特征的抽象程度越来越高,表达能力越来越强,同时维度也越来越低。在VGG 网络结构中,靠近输入层的卷积层通常反映出图像的纹理、边缘信息,靠近输出层的卷积层通常反映图像的细节信息[10]。
由于训练VGG 网络需要大量的训练集数据,如果直接使用818 位受试者的图像数据重新训练VGG 网络的参数,很容易发生过拟合的现象,最后导致分类准确率的下降,所以本文使用了迁移学习技术,在已训练好的VGG 网络中,微调网络参数,进行图像的特征提取。在特征提取时,首先将预处理好的MRI 图像和PET 图像分别输入预先训练好的VGG 模型中(MRI-CNN,PET-CNN),网络模型会“自动”地进行图像特征提取,每张图像提取第11 卷积层(conv11)、第13 卷积层(conv13)的特征,conv11 和conv13 的特征向量维度都为14×14×512,分别提取每位受试者60 个横断面的特征信息。以MRI 图像为例,选择一位受试者的脑横切面在conv6、conv11、conv13 图像特征提取的可视化如图4 所示。
从 图4 中 可 以 看 出,conv11 和conv13 的 特 征 图比conv6 的特征图更加抽象,每个单模态的图像经过特征的提取后,在conv11、conv13 的特征总和为14×14×512×2×60(每个横断面图像都提取conv11 和conv13 的特征,一共60 个横断面),维度总和达到了1 200 万维,但是每组的受试者样本不超过300 例,这样可以看到提取特征的维度远大于样本的数量,存在过多的冗余信息,这样极容易发生过拟合现象,因此要进一步对特征进行选择和融合使特征向量降维。本文设计的特征提取网络结构如图5 所示。

图4 MRI 图像conv6、conv11、conv13 特征提取可视化Fig. 4 Feature extraction image of conv6,conv11,conv13 by MRI
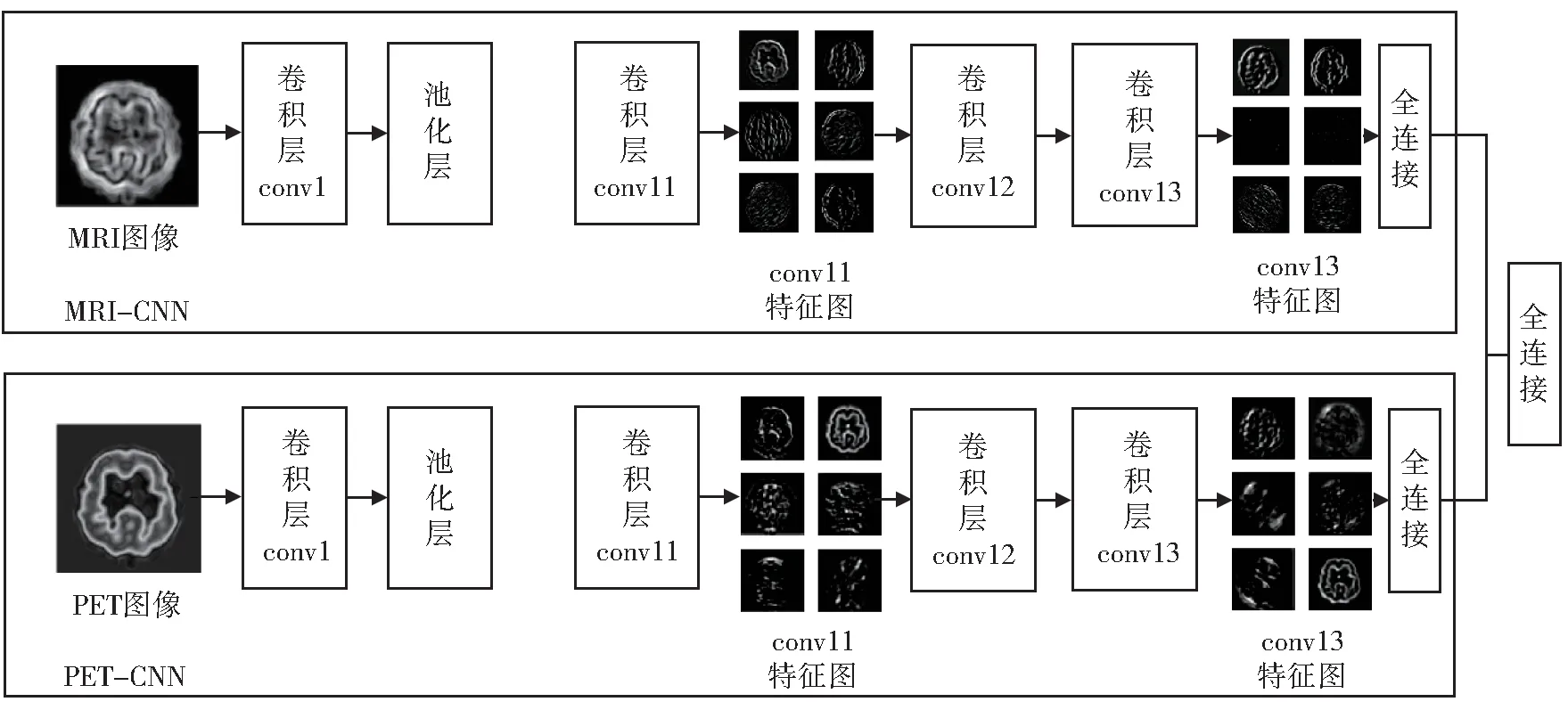
图5 特征提取网络结构Fig. 5 Network structure of feature extraction
2.3 特征选择与融合
本文对NC、MCI 和AD 的三分类问题转化为AD:NC,AD:MCI,NC:MCI,NC:MCI:AD,三个二分类和一个三分类问题。根据MRI-CNN 和PET-CNN 各 模 态 提 取 的conv11 和conv13 的 特 征为14×14 的矩阵,每个模态都有61 440 个(512×2×60)特征矩阵,特征选择的目的就是除去冗余的特征信息,保留对分类算法贡献度高的信息的过程。本文使用Adaboost 算法对特征进行选择与融合,其基本思想为分别将各模态的特征向量按顺序进行串联组合,该组合包含了不同模态的全部特征信息。根据Adaboost 算法逐步选择某一特征向量作为弱分类器,然后循环以上选取弱分类器的过程,逐步组合成一个强分类器对各类问题进行分类。设A为MRI 图 像 的 特 征 矩 阵,B为PET 图 像 的特征矩阵,ai为A矩阵某行的特征向量,bi为B矩阵某行的特征向量,特征选择与融合过程原理如图6所示。
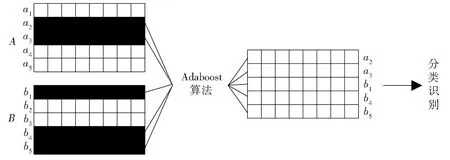
图6 特征融合原理Fig. 6 Schematic diagram of feature fusion
设每组二分类问题的数据集为T={(x1,y1),(x2,y2),…,(xN,yN)},其 中yi={+1,-1}表示正负两类,算法流程如算法1 所示。

算法1输入:T={(x1,y1),(x2,y2),…,(xN,yN)}输出:特征融合后的分类器G(x),其中G(x)={+1,-1}(1)初始化各模态特征向量权值:D1=(w11,w12,…,w1i),其中w1i=1 N (i=1,2,…,N);(2)设m=1,2,…,M,其中M 为弱分类器的个数。用DM 采样N 个样本,在训练样本上获得分类器Gm(x),使Gm(x)=±1;(3)计算加权错误率:em=P(Gm(xi)≠yi)=∑i=1 NwmiI(Gm(xi)≠yi),并计算分类器Gm(x)的权重αm=1 2 log 1-em em;(4)更新特征向量的权值:DM+1=(wm+1,1,wm+1,2,…,wm+1,N),其中:wm+1,i=wmi N wmie-αm yiGm(xi);zme-αm yiGm(xi),zm=∑i=1(5)回到第(2)步迭代执行;(6)最终分类器G(x)=sign( ∑m=1 MαmGm(x))
2.4 诊断模型评价
针对818 名受试者图像信息分为4 组数据进行实验,分别为AD:NC,AD:MCI,NC:MCI,NC:MCI:AD,其中研究AD:MCI 和NC:MCI,可以对AD 早期诊断提供帮助。每类数据都分为训练集和测试集,为了测试算法性能,采用十折交叉验证方法来验证算法性能,也就是将样本平均分成10 份,逐一选择其中的一份为测试集,其余的9 份为训练集。
评价指标包括准确率(Accuracy)、灵敏度(Sensitivity)、特 异 度(Specificity)、受 试 者 工 作 特 征(ROC)曲线下的面积(Area under curve,AUC)。
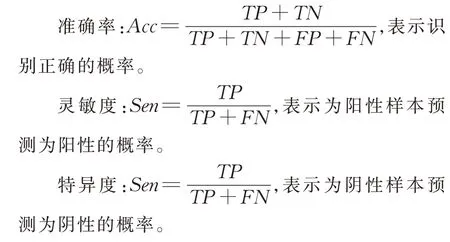
其中,TP表示真阳性(True Positive)、FP表示假阳性(False Positive)、TN表示真阴性(True Negative)、FN表示假阳性(False Negative)。
本文实验软件环境为:Windows10 操作系统,Python3.6,TensorFlow1.4 开 源 框 架 和sklearn 包。硬 件 环 境 为i7 处 理 器3.60 GHz,32 G 内 存,Ge-Force 1 080Ti 独立显卡。VGG16 配置参数为:参数优化算法为Adam,dropout 丢掉率为0.5,学习率为1×10-8,训练的批次大小(batch size)为20。
3 结果与讨论
本文将各模态数据在VGG 网络进行特征提取,并使用Adaboost 算法对各模态特征进行融合,消除单模态信息不全的缺点,达到最后分类识别的目的。实验分别从以下两个方面进行分析:1)使用VGG 网络conv6、conv11 和conv12 特征信息对 图像进行分类比较;2)多模态特征融合和单模态图像分类比较。
3.1 基于VGG 网络conv6、conv11 和conv13 特征信息对图像进行分类比较
利用VGG 网络分别训练预处理后的MRI 图像和PET 图 像,并 将 卷 积 层conv6、conv11 和conv13的特征进行提取,并只用已提取的单层特征信息基于Adaboost 算法进行特征融合和分类,在测试集上分类准确率结果如图7 和表3 所示。

表3 各卷积层特征分类准确率(%)Table 3 The accuracy of the feature classification in each convolution(%)

图7 各卷积层特征分类结果Fig. 7 Results of feature classification in each convolution
通过图7 可以看出,对于AD:NC,AD:MCI,NC:MCI 分类问题,单独使用conv11 和conv13 两个层的特征进行分类,结果明显好于仅使用conv6 特征的分类结果,说明conv11 和conv12 中有更多可用的特征信息;又由于conv11 和conv13 提取特征的大小都为14×14×512,而conv6 提取特征的大小为56×56×256,conv6、conv11 和conv13 特征向量维度不同,为了方便,后续实验只需选择和融合conv11 和conv13 的特征即可。对于MRI 图像和PET 图像,使用单模态MRI 图像进行特征提取和融合的分类正确率高于单模态PET 图像的正确率,说明VGG 网络对于MRI 图像可以获得更多有用的特征信息。
3.2 基于Adaboost特征融合与单模态图像分类比较
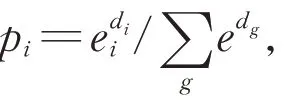

表4 多模态特征融合和单模态识别准确率(%)Table 4 Recognizable accuracy of muti-modal feature fusion and single modal(%)
通过表4 可以看出,多模态特征融合的分类方法在准确率方面比任意单模态特征分类方法都有显著提高,其中AD:NC 组分类效果最佳;AD:MCI组分类效果最差;AD:MCI:NC 组分类效果相对较低,但准确率在92.8%。在对AD 和MCI 分类时,准确率最低,可能是由于判断MCI 较为复杂,因为MCI 最终可以表现为两种类型:其一MCI 发展为AD,其二终身保持MCI,所以在分辨AD 和MCI 时有一定的难度。
图8 展示了多模态特征融合对AD:NC 数据训练的迭代过程。这里只选取分类结果最好的AD:NC 组进行展示,从图中可以看出使用曲线符合深度学习网络学习规律,当迭代到35 次时,曲线收敛。

图8 多模态特征融合AD:NC 组数据训练的迭代过程Fig. 8 Iterative process of data training for AD:NC in multi-modal feature fusion
多模态特征融合模型在区分AD、MCI 和NC 问题上有比较理想的分类结果,为了更好地用于医学诊断,分别计算AD:NC、AD:MCI、NC:MCI 二分类问题的灵敏度和特异度。对于临床诊断,正确诊断出病人是最为重要的,所以灵敏度(真阳性率TPR)越高越理想;如果将没病的错误诊断为患者也会出现不良的后果,所以假阳性率FPR(100%-特异度)越低越理想,因此灵敏性和特异性是相互制约的两个因素。理想化的情况为TPR=1,FPR=0,即为将所有病人都诊断出来,并且没有误诊任何一个没有病的病人。表5 列出了多模态特征融合模型分类的统计数据,图9 绘制了表5 中AD:NC、AD:MCI 和NC:MCI 组对应的ROC 曲线。
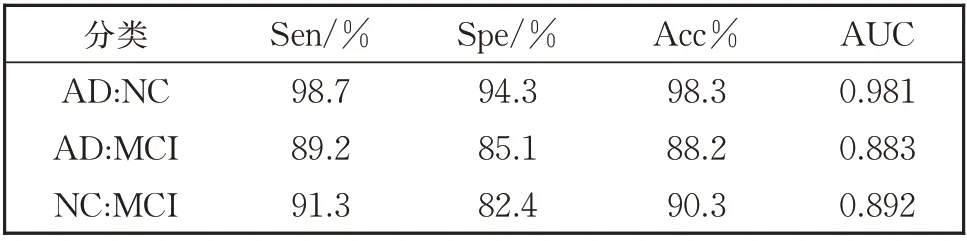
表5 AD:NC、AD:MCI、NC:MCI分类评价指标Table 5 Evalutaion index of AD:NC,AD:MCI,NC:MCI classification
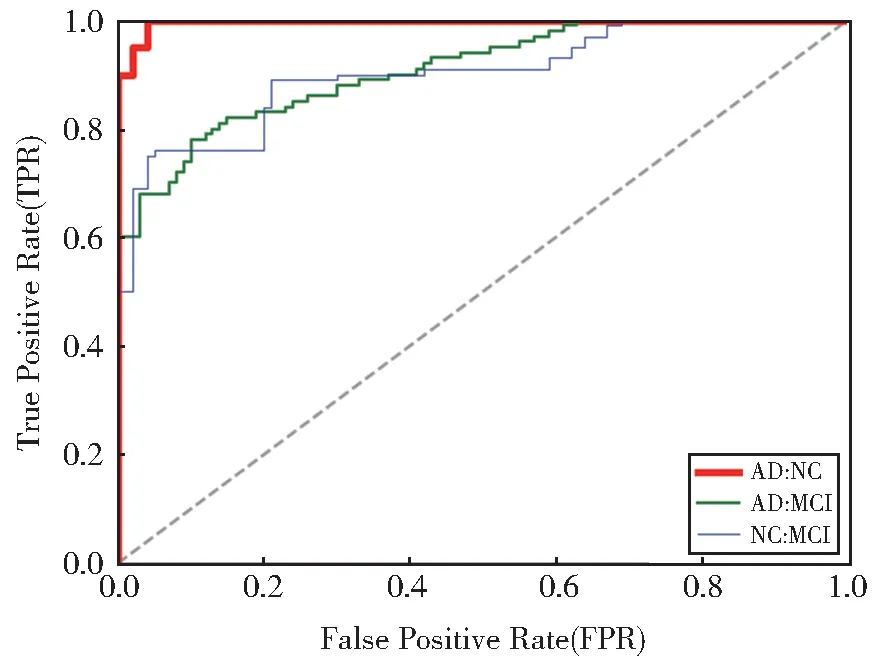
图9 多模态特征融合模型上AD:NC、AD:MCI、NC:MCI的ROC 曲线Fig. 9 ROC curves of AD:NC,AD:MCI,NC:MC on multimodal feature fusion model
通过表5 和图8 可以看出,多模态特征融合模型在AD:NC 组的真阳性率为98.76%,AUC 值为0.988,说明多模态特征融合模型对诊断AD 更具有优势。在AD:MCI 组的假阳性率为85.13%,说明对AD 的误诊率相对较高,也恰好验证了AD:MCI组用来判断MCI 准确率较低。
由表6 可以看出,不论在AD:NC 组还是NC:MCI 组分类实验中,本文的方法都优于文献中的其他方法,而且本文方法只用了两种模态的特征,文献[11]、文献[12]、文献[13]使用了三种模态的特征,除了MRI 图像和PET 图像外,还加入了CSF 生物标志物特征进行融合,这也为今后研究提供了方向,加入CSF 生物标志物特征会对AD 病的早期诊断有多大影响,也是后续需要研究的一个内容。总之,本文算法和分类诊断模型在AD:NC,AD:MCI,NC:MCI,AD:MCI:NC 组上取得了更好的效果,也验证了算法的可行性和优越性。
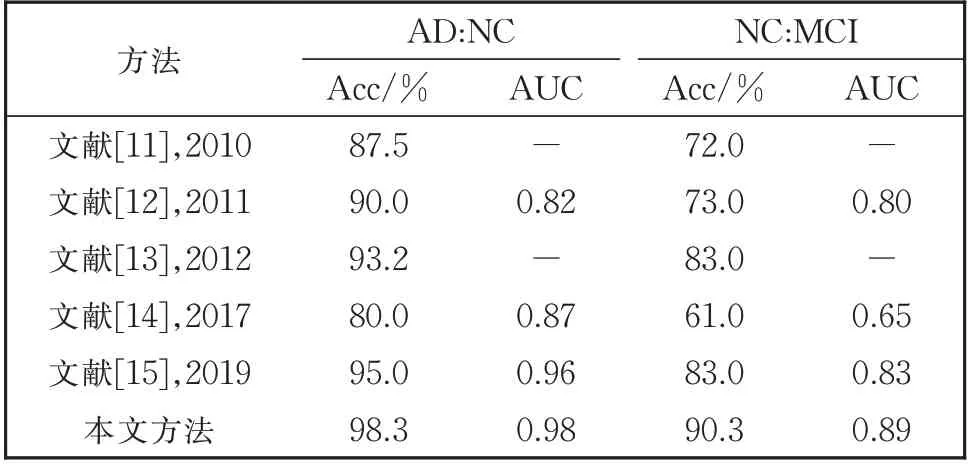
表6 多模态分类方法在AD:NC和NC:MCI组的分类实验结果对比Table 6 Comparison of the experimental results using mutimodal classification method in AD:NC and NC:MCI
4 结论
本文提出了一种融合多模态影像的AD 多分类诊断模型。该诊断模型基于深度学习,可以对各单模态特征信息进行有效地融合和图像识别。通过对同一模型不同卷积层特征融合实验和多模态特征融合与单模态图像分类对比,结果表明本文提出的方法对AD 病的诊断具有一定的医学意义。在未来的研究中,可以进一步完善脑图像数据集,对AD和MCI 分类结果进行提升。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
保定学院学报(2022年2期)2022-04-07
中国心血管杂志(2021年6期)2021-01-02
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
中国心血管杂志(2019年3期)2019-01-04
电子制作(2018年19期)2018-11-14
