
面向文本特征选择的去冗余相对判别准则
2021-08-31 06:09王家琪张莉
山西大学学报(自然科学版) 2021年4期
王家琪,张莉,2*
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 苏州大学 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
0 引言
文本作为当今互联网时代信息的主要载体,可以承载各类领域的信息,如新闻报道、商品评论、博客文章等,对文本信息的处理在大数据分析中占据重要地位。作为文本处理的一种技术,文本分类在情感分析、舆情分类、垃圾邮件检测以及各种现实领域都有着很重要的作用。基于机器学习方法的文本分类通常使用词袋模型(bag-of-words)来将文本数据转换为特征矩阵的形式[1],这样表示的文本数据具有很高的维度。为了避免维数灾难问题并获得好的分类性能,对之进行特征选择是非常必要的。
特征选择的主要任务是从原有特征集中选取在后续分类任务中表现最好的特征子集,一般分为封装法(wrapper method)、筛选法(filter method)以及嵌入法(embedded method)三类[2]。最早的封装法于1997 年由Kohavi 等人[3]提出,是一种与分类器相结合的特征选择方法,以分类器的性能作为选择标准。由于封装法直接依赖于分类算法来选择特征,因此在分类任务中可以有一个较好的性能。但是,此类算法的复杂度较高,计算代价较大。筛选法是目前最为常用的特征选择方法。筛选法独立于分类器算法,通过某种特征评价准则,选择最佳特征组合。目前常用的筛选法有互信息[4-5]、信息增益[6]、CHI[7]等。嵌入法结合了封装法和筛选法的特点,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。以上筛选法只考虑了特征与决策的相关性,Peng 等人[8]通过理论分析证明了一种同时以相关性与冗余性为准则的特征选择思路的可行性及优越性,并提出了一种最小冗余-最大相关(Minimal Redundancy Maximal Relevancy,mRMR)框架以最小化冗余。
文本数据有别于普通的数值数据,有着高维度和高稀疏性的特点,并且每一维特征都有着较直观的含义。基于特征词频的特征选择方法是文本特征选择所特有的,Uysal 等人[9]提出了对于词语特征的四种评分标准,并基于这些标准提出了基于词频的DFS(Distinguishing Feature Selector)算 法。Rehman 等人[10]提出了相对判别准则(Relative Discrimination Criterion,RDC),考虑了每个特征在正类与负类的出现频率,并将其根据正类以及负类的样本数进行归一化,体现了特征与类别的相关性。但是RDC 未考虑特征子集的冗余。Labani 等人[11]将RDC 结合Pearson 相关系数,提出了多变量相对判别准则(Multivariate Relative Discrimination Criterion,MRDC),同时考虑特征子集的冗余性以及特征与类别之间的相关性。但是,MRDC 是建立在文档频率基础上的准则,没有考虑文本特征的语义信息。
为了在选择相关特征的同时有效地去除冗余特征,我们提出了去冗余相对判别准则(De-redundantly Relative Discrimination Criterion,DRDC)。该准则的目的是从候选特征子集中选择一个特征,该特征和已有特征子集冗余度最小且与类别相关性最大。为了考虑文本特征的语义信息,DRDC 引入了特征的向量表示,保留了单词的语义和语法信息。基于特征的向量表示,DRDC 计算候选特征与所选择特征子集之间的距离,以此来量化候选特征与特征子集的冗余度。此外,DRDC 还使用RDC 来评价单个候选特征与类别之间的相关性。本文在Reuters21589 数据集对所提方法进行了实验,并验证了算法的优越性。
本文的行文结构如下:第1 部分,介绍了相关的工作;第2 部分,描述了所提出的去冗余相对判别准则的结构;第3 部分,详细介绍了数据集和实验设置以及结果。第4 部分,阐明了我们的结论和未来的研究方向。
1 相关工作
1.1 常用文本特征选择方法

1.1.1 信息增益
在ID3 决策树中,信息增益(Information Gain,IG)[6]被用作为特征评价准则。在文本特征选择中,通过文档中特征t的存在与否来度量为类别预测而获得的信息量,特征t的信息增益定义为:
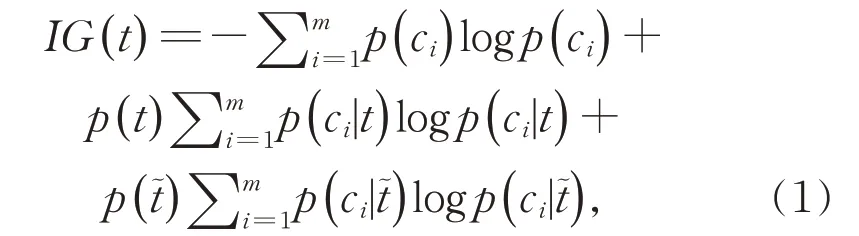
1.1.2 DFS
Uysal 等人[9]根据对显著特征赋高分和不相关特征赋低分的原则,提出了筛选文本特征选择的四种评分标准:
(1)如果一个特征频繁出现在某一个类别,并且不出现在其他类别,则该特征与该类别相关度高,需对其赋较高分数;
(2)如果一个特征很少出现在单个类别,同时也不常出现其他类别,则该特征与类别不相关,需对其赋较低分数;
(3)如果一个特征在所有类别都经常出现,则该特征与类别不相关,应对其赋较低分数;
(4)如果一个特征只出现在某一些类别,则该特征与类别相关,需对其赋较高分数。
基于这些标准,提出了依赖词频的DFS 特征选择准则:
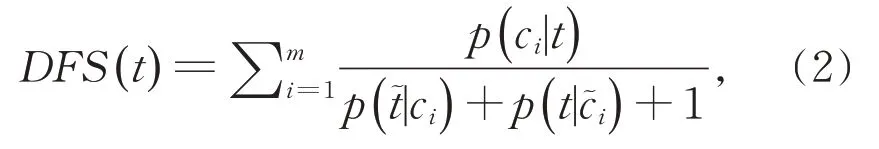
可以证明DFS 满足以上四种标准。
1.1.3 相对判别准则
Rehman 等 人[10]基 于Uysal 等 人 制 定 的 四 条 评分标准,提出了一种同时考虑特征计数和文档频率的相对判别准则:
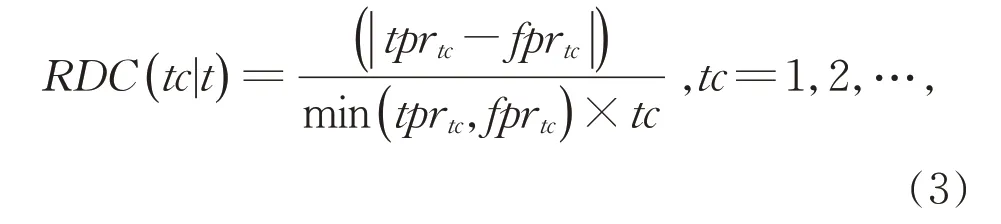
其中,tc表示特征t在一个样本中出现的次数,tprtc是特征t在正类中出现tc次的文档频率,以及fprtc是特征t在负类中出现tc次的文档频率。对特征t的所有可能的tc取值计算其相应的RDC(tc|t)值,并对其求曲线下面积(Area Under the Curve,AUC)作为特征t最终的得分:

1.2 词语的向量表示
在特征工程中,文本一般表示为one-hot 编码与词袋模型。One-hot 编码是将文本表示为二进制编码的形式。随着语言模型的广泛使用,文本表示由one-hot 编码方式逐渐发展为文本的分布式表示。Word2vec 是 由Google 的Mikolov 等人[12]提出的一种词嵌入(Word Embedding)的方式,能够将词语转换成可计算的向量。Word2vec 使用神经网络训练语言模型,得到词语特征的向量表示。相较于one-hot 编码,Word2vec 极大地减少了向量的维度,同时也赋予了向量更多词语上的含义。
GloVe(Global Vectors for Word Representation)是一种基于全局词频统计的词表征算法[13]。该算法综合了全局矩阵分解和局部上下文窗口两种方法,同时考虑词的局部信息与全局语料的关联,保留了语义和语法信息。ELMO(Embedding from Language Models)在训练过程中根据上下文对Word Embedding 进行动态调整,调整后的向量更能表达出上下文的具体含义,解决了静态词向量未解决的多义词问题[14]。BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,使用双向Transformer[15]对大量未标注文本进行训练,训练后需要对根据下游具体任务进行微调[16]。根据词语的向量表示来判断两个词语间的距离,在机器翻译[17]、情感分析[18-20]和问答系统[21]等领域都有着广泛应用。
2 去冗余相对判别准则
本节详细介绍所提出的去冗余相对判别准则DRDC。

2.1 优化问题
在文本特征选择中,考虑需要满足最大相关最小冗余原则,本文提出的DRDC 可以满足这样的原则。在利用DRDC 方法进行特征选择时,除了考虑特征子集与类别的相关性之外,还考虑了特征子集的冗余性。在相对判别准则的基础上,DRDC 利用下式来选择特征:
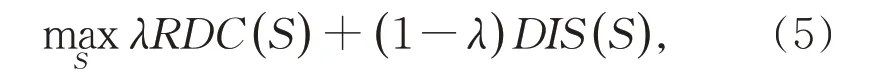
其中,S⊆F是特征子集,λ为组合参数,决定第一项RDC(S) 和第二项在特征选择中所占比重。RDC(S)代表特征子集与类别的相关性,DIS(S)表示特征子集的冗余性。下面分别讨论(5)式中RDC(S)和DIS(S)的计算,并用S表示目前所选择的特征子集。
关于特征子集与类别相关性的衡量,DRDC 推广了RDC 的衡量方式。RDC 通过单个特征的文档频率以及其词频来计算单个特征与类别的相关性。DRDC 采用简单的累加平均方式来计算特征子集与类别的相关性。即,对于特征子集S⊆F,其与类别的相关性定义为:

其中,RDC(ti)由公式(4)计算得到。
关于特征的冗余性,我们认为特征与特征越相似,则特征之间的冗余性越高。在衡量特征的相似性时,不能只依靠特征的频率。因而,本文引入特征的向量表示,保留了特征的语义和语法信息。DRDC 计算向量表示之间的相似性,以此来衡量冗余性。令特征ti的向量表示为vi且tj的向量表示为vj,则特征ti与tj之间的相似性为:
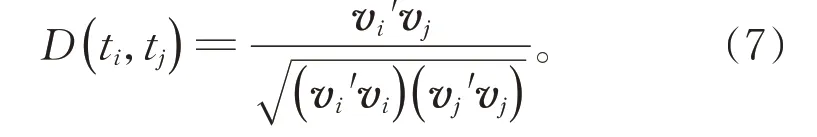
对于特征子集S⊆F,其冗余性被定义为:
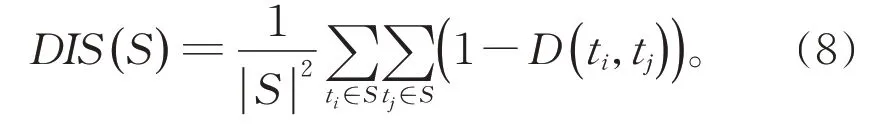
利用(6)式和(8)式,DRDC 就可以通过最大化(5)式去寻找具有最大相关和最小冗余的特征子集。
2.2 优化过程
优化问题(5)是一个组合优化问题,其最优解需要遍历所有可能的组合才能获得。因此,为节省计算资源,可以使用贪心算法来逐个选择特征。假设在当前迭代中,我们已经得到了当前的最佳子集S。下一步,我们要从候选特征子集F-S中,选择一个候选特征加入S,这时需要考虑候选特征与类别的相关性以及候选特征与特征子集的冗余性。
利用贪心算法,把优化问题(5)简化为

其中,第一项RDC(ti)表示候选特征与类别的相关性,第二项DIS(ti|S)表示候选特征与特征子集的冗余性:

优化问题(9)中的第一项与优化问题(5)中的第一项表示方式不完全一致,但是实际效果是等价的。 这是因为每一次迭代都是寻找最大的RDC(ti),因而能保证到目前为止的RDC(S)为最大。对第二项,也有同样的结论。算法1 描述了DRDC 的特征选择过程。算法的输入参数分别为数据集、特征的向量表示,选择特征数以及组合参数,算法的返回值是选择的特征子集。在选择第一个特征时,由于已选择特征子集为空集,所以不需要判断冗余,只需要根据RDC 来选择得分最高的特征。

算法1 去冗余相对判别准则的特征选择过程
3 实验设置与结果分析
3.1 数据集与预处理
本文选取了Reuters21578 的单标签数据子集进行实验,并与RDC 以及一些常用文本特征选择方法进行实验对比。
Reuters 数据集是路透社收集的文本语料,同时是目前应用最广泛的文本分类数据集。原始数据集类别较多,文档的类别分布较为不平衡,并且有部分多标签数据,因此本文使用Cardoso-Cachopo①https://ana.cachopo.org/datasets-for-single-label-text-categorization筛选处理的数据集[22]。该数据集使用了Mod Apté划分[1],划分出了训练集与测试集,并筛选出单标签的数据,生成了R10 子集。在R10 数据子集中删除了训练样本或者测试样本个数为0 的类别,最终得到了数据子集R8。表1 为R8 数据集中样本的分布。
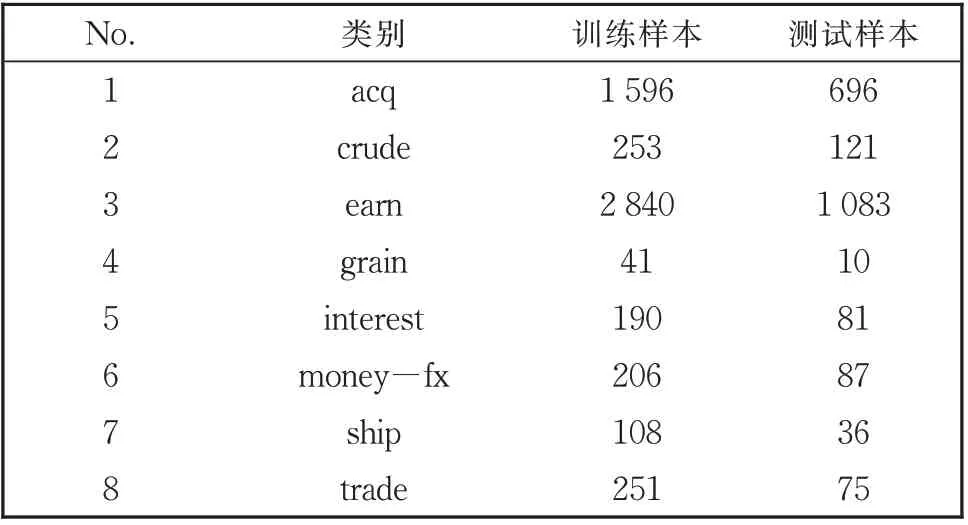
表1 R8样本分布Table 1 Distribution of R8 samples
由于文本数据中特征维度过大,需要对文本数据进行预处理。首先删除字符长度小于3 的单词以及停用词,同时考虑频率过高以及过低的词语对分类的贡献都很小,需要选取合适频率区域的特征[23]。在本文实验中选择保留文档频率大于3 的特征,最终保留6 827 个特征。本文使用词袋模型将文本数据表示为特征矩阵的形式,同时使用通用的GloVe①http://nlp.stanford.edu/data/glove.840B.300d.zip文件用于表示文本特征,将预处理后的特征转换为向量表示。
3.2 分类器及评估指标
本文对特征选择后的数据分别使用支持向量机与K 近邻算法(KNN)进行分类,均由Python 中的sklearn 库实现。利用分类数据准确度(Accuracy)对分类结果进行评估[24],准确度的计算方法如下:

其中,TP为预测正确的正类样本数,TN为预测正确的负类样本数,n为样本总数。表2 给出的分类混淆矩阵描述了以上数据含义。
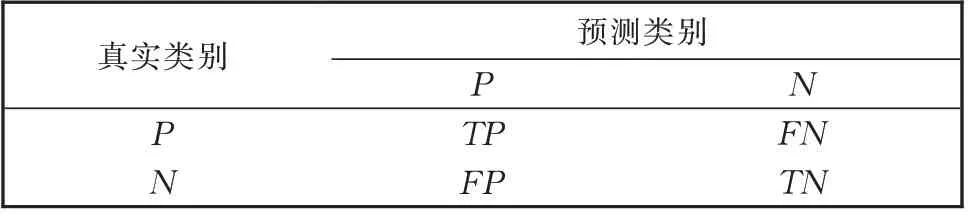
表2 分类混淆矩阵Table 2 Confusion matrix for classification
在多类别分类过程中,分别对每一种类别进行预测结果的统计,类别ci的准确度记为acci。本文所用的多分类的度量指标为:
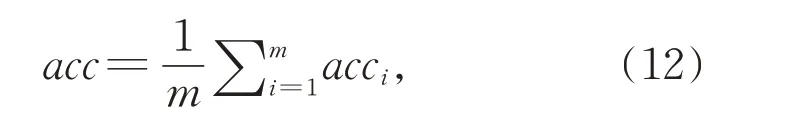
其中,m为类别总数。
3.3 实验结果及分析
为证明本文所提出的去冗余相对判别准则的有效性,将本文所提方法与IG、DFS、RDC 以及MRDC 进行对比实验。实验对R8 进行特征选择,选 择 的 特 征 数 分 别 为10,20,50,100,200,500,1 000,1 500,得到特征选择后的数据,使用支持向量机和K 近邻算法进行分类,并使用准确度对分类结果进行评估。表3 和表4 分别为使用支持向量机和K 近邻算法作为分类器的实验结果对比。

表3 支持向量机的分类准确度Table 3 Accuracy using SVM

表4 K近邻算法的分类准确度Table 4 Accuracy using KNN
通过对比表3 和表4 的数据可以看出,DRDC特征选择方法相较于RDC、MRDC、DFS 和IG 在准确度上有一定提升。为观察DRDC 的去冗余作用,提取出了在特征数为100 的情况下,被RDC 选择而未被DRDC 选择的特征。其中,RDC 选择了特征词money 与cash,二者在含义上较为接近,而DRDC 只选择了特征money,在一定程度上避免了一些冗余。不过由于在特征选择过程中相关性与冗余性均占一定比重,因此在特征选择初期更倾向于选择更为相关的特征。
为了进一步对比RDC 和DRDC 的特征选择效果,选取特征数为1 500 到3 000 之间的特征选择数据。两种特征选择方法在不同分类器下的分类准确度对比结果分别如图1 和图2 所示。由图1 和图2可以看出,在特征维度较高的情况下,DRDC 的特征选择效果远好于RDC。在特征维度较大的情况下,以相关性为选择标准的RDC 方法仅仅倾向于频次分布不均的特征,未考虑与已选择特征子集之间的关系,容易忽略特征子集间的冗余性。而在特征维度增加的情况下无可避免地会出现冗余,本文提出的DRDC 方法有效地解决了这一问题。DRDC在使用相对判别准则的同时,引入特征的词嵌入表示,并根据词向量之间的距离来去除冗余。DRDC在特征选择过程中,采用特征携带的文本信息来判断冗余,尽量避免选择与已选特征子集距离过小的特征,从而达到去冗余的目的。

图1 两种特征选择方法在支持向量机下的准确度对比Fig. 1 Comparison of accuracy of two feature selection methods under SVM

图2 两种特征选择方法在K 近邻分类器下的准确度对比Fig. 2 Comparison of accuracy of two feature selection methods under KNN
4 结论
本文在相对判别准则的方法上引入文本分布式表示,将文本特征表征为可计算向量来去除冗余。在文本多分类数据集进行了实验,并与一些常用文本特征选择算法比较,在分类准确度上有一定提高。通过对比未去冗余的相对判别准则,本文所提方法在选择特征数目较大的情况下优势更为明显,表明本文方法在选择特定特征数的情况下,可以选择更多相关的特征,达到了去冗余的目的。
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
陶瓷学报(2021年4期)2021-10-14
少儿画王(3-6岁)(2020年4期)2020-09-13
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
小型微型计算机系统(2018年5期)2018-07-04
计算机应用(2017年3期)2017-05-24
电子制作(2017年23期)2017-02-02
都市丽人(2015年4期)2015-03-20
