
基于图卷积神经网络的函数自动命名①
2021-09-10 07:32王堃,李征,刘勇
计算机系统应用 2021年8期
王 堃,李 征,刘 勇
(北京化工大学 信息科学与技术学院,北京 100029)
1 引言
函数自动命名是根据现有源代码自动生成可读性强的自然语言来描述函数的功能.在软件维护过程中,开发者往往需要花费大量的时间去理解一段代码所对应的功能.其中,一种重要的方式便是通过阅读函数名来快速的了解代码的功能,从而节约开发者的时间.尽管开发者可以通过函数名理解函数的功能,但是在实际开发过程中往往这些函数名并不是完整的或具有时效性的.这类问题可能会误导开发者,导致开发者花费大量的时间来理解程序,影响开发效率.现有工作表明:“函数名大多是常规编程语言中聚集函数行为的最小命名单位,因此函数名是函数抽象的基石.”[1].因此,在软件开发过程中,给定一段代码,如何自动生成一个正确并且相关联的函数名变得尤为重要.
随着深度学习技术的快速发展,许多研究人员尝试使用深度学习模型来解决这个问题,例如sequenceto-sequence 模型[2-5].Allamanis 等[6]将代码解析成token 序列,然后利用卷积神经网络(CNN)对token 序列进行建模,通过卷积操作提取代码特征,并引入注意力机制学习代码序列与函数名之间的关键信息.但是,使用token 序列仅仅是代码的展开,模型很难去学习到代码中的结构信息,同时token 序列过长导致模型很难学习到其中的语义信息.为了解决这个问题,Alon 等[7,8]通过将代码转化为抽象语法树(AST),并根据每一个叶节点(变量名、方法名等) 从AST中提取相关路径(AST Path)来作为代码的特征表示,该特征向量包含了一定的结构信息以及语义信息.之后Alon 等[9]提出了code2seq 模型,对先前模型进行了再一次改进,利用BiLSTM 网络对AST 路径进行模型构建,然后通过引入注意力机制来学习所生成的单词与各条AST 路径的相关性.该方法在函数名预测任务中达到了目前最好效果.然而,该方法依旧存在弱化了AST 树形结构信息的缺陷,从而导致其很难学习到AST 路径之间节点的信息.Fernandes 等[10]提出一种结合sequenceto-sequence 模型和图神经网络(GNN)模型的方法来表示代码,Sequence-GNNs.该方法使用BiLSTM对代码序列进行编码,然后引入图神经网络对编码后的代码序列进行建模,最后得到的向量便是代码的特征表示.但是BiLSTM 等循环神经网络模型存在长程依赖问题,该模型很难捕捉到长距离文本之间的关系,会导致一些关键信息丢失.
可以看出,目前在函数命名任务中面临两大挑战:(1)代码的表示方法.对代码进行特征提取时,不仅要提取其语义信息,而且更要提取其结构信息.在目前code2seq 模型中,该方法将代码表示为AST 路径的集合,引入注意力机制来提取代码的结构以及语义信息.但是该方法对路径建模的同时一定程度上破坏了AST的结构,而且只能提取路径内部节点之间的信息,并不能有效提取路径间节点之间的信息,尤其是数据流和控制流信息.(2)长程依赖问题[11].当前的代码片段可能依赖于离它很远的代码段.例如,一个程序中第90 行的语句“a=a+2;”依赖于第10 行语句“int a=10;”的变量定义.随着代码长度的增加,BiLSTM 等循环神经网络很难捕捉到长距离文本之间的信息.
本文提出一种新颖的神经网络模型TrGCN,采用了近期提出的Transformer[12]模型,该模型可以有效缓解长程依赖问题.然而原生的的Transformer 模型主要用于自然语言翻译中,并不能应用在结构性很强的代码中.所以我们在每个Transformer encoder block中添加了两层图卷积层[13],将节点以及其相关节点进行卷积操作,从而丰富代码的结构信息.在函数命名任务中,我们使用了Java-small、Java-med和Java-large[6,9]数据集,在7 个基准模型来评估TrGCN.实验结果表明我们的模型明显优于其他基准模型,相比于模型code2seq[9]和Sequence-GNNs[10],TrGCN 在F1 指标上分别提高了平均5.2%、2.1%;在ROUGE-2和ROUGE-L 指标上,比Sequence-GNNs 分别提高了0.7%、3.6%.
2 相关背景
随着开源代码库的不断增加,数据规模的不断增大,越来越多的研究者开始使用机器学习对程序源代码进行建模,学习其中的信息,帮助开发者更好的理解程序.起初研究人员把源代码作为一种符号序列,将源代码转化为token 序列,并通过RNN 或LSTM 等序列模型(Seq2Seq)对其进行建模和学习序列中的信息.Allamanis 等[14]利用Logbilinear 模型,通过对变量、函数名以及类名的上下文信息进行预测.之后Allamanis等[6]提出了ConvAttention 模型,将源代码看做一组token 序列,并使用神经网络对其建模,通过CNN 以及注意力机制来学习代码和函数名之间的关键信息.Lyer等[15]和Hu 等[16]在代码注释生成任务中利用RNN对源代码建模,然后根据其建模结果使用RNN 进行解码,同时引入了注意力机制来学习注释文本中各个单词与函数体之间的关系.程序语言与自然语言最大不同之处在于程序语言是一种高度结构化的语言,而基于token的程序表示方法仅仅将代码线性展开,丢失了程序语言的结构信息,导致代码特征向量信息的不完整.
为了对程序的结构信息进行建模,研究人员使用AST 来对源代码进行建模.Li 等[17]和Liu 等[18]在代码补全任务中,将程序源代码解析为AST,然后遍历AST 得到一组节点序列,通过对其建模,实现代码补全.Sun 等[19,20]在代码生成任务中利用树卷积的方式,将AST中的节点、双亲节点和祖先节点结合起来,通过预测语法规则实现代码生成.Alon 等[8,9]通过从AST中提取AST 路径来表示程序的结构信息以及语法信息,然后对AST 路径建模,并且引入注意力机制,通过学习函数名和AST 路径之间的关系来进行函数名预测.虽然基于AST的程序表示方法有效的提取了程序的结构信息,但是并不完整,缺少对数据流以及控制流信息的提取.
随着图神经网络(GNN)的兴起,研究人员尝试将程序源代码转化为图的形式并对其进行建模.其转化方式为通过给AST 增加更多的边,使得模型可以更好的理解节点之间的关系.Allamanis 等[21]提出了一种基于门控图神经网络(GGNN)[22]模型,利用图的形式来表示程序源代码.该方法通过将源代码的AST 扩展为图的形式,其中图中的节点表示AST 序列中的token,图中的边表示节点与节点之间的相互关系.Fernandes 等[10]在代码注释任务中提出一种将GNN与Seq2Seq 结合的模型,首先使用BiLSTM对程序进行编码,得到其特征向量表示,然后利用GNN对其进行建模,最后得到特征向量作为程序的特征表示.但是先前的研究所使用的模型都是RNN、LSTM 等循环神经网络模型,存在长程依赖问题,导致对代码特征信息的提取不够完整.本文利用了Transformer中多头自注意力机制的特性来缓解这个问题.
为了将结构信息的提取与缓解长程依赖问题相结合,本文提出了一种基于Transformer 模型的图卷积神经网络(GCN)模型TrGCN,使用图卷积提取代码的结构信息,并且利用Transformer 模型来缓解长程依赖问题.
3 模型结构
图1显示了TrGCN 模型的结构图,主要包括两个部分:AST 编码器和解码器.

图1 TrGCN 模型结构
3.1 Encoder-Decoder 结构
TrGCN 使用了Transformer 模型,是一种标准的Encoder-Decoder 结构,其中Encoder 编码器将输入的token 序列 (x1,···,xn)转化为一组连续的特征向量z=(z1,···,zn).得到特征向量z后,Decoder 解码器根据z输出一组token 序列(y1,···,ym),因此模型化之后的条件概率为:p(y1,···,ym|x1,···,xn).在解码阶段,预测出的token 取决于先前token的信息,该概率模型为:

3.2 AST 编码器
一段代码可以解析为一颗抽象语法树,其叶节点被称为终结符,一般是用户所定义的变量以及方法名等;非叶节点被称为非终结符,代表代码中的一些结构,例如循环、表达式以及变量声明.图2表示AST的一部分,其中变量名(如num)代表终结符,而条件语句(IfStmt)和表达式语句(ExpressionStmt)这些语法结构代表非终结符.由于非终结符拥有丰富的结构信息,终结符拥有丰富的语义信息,所以AST 编码器的目标就是尽可能的提取AST的结构信息和语义信息来帮助模型更好的理解代码.首先将代码解析成一棵AST,利用前序遍历的方式将AST 展开成一组token 序列.假设AST为T,则token 序列为T={n1,···,nL},其中L为序列的长度.每个token 可以被分割为一组字符序列其中m表示单词最大长度,如果长度小于m,则会被填充字符填充至m.所有的token 序列以及字符序列通过table-look-up embedding的方式来表示成具有真值的初始特征向量

图2 抽象语法树(部分)
3.3 输入序列的特征表示方法
Character Embedding.无论是在自然语言中还是在代码中,都会出现一些相似的单词并且拥有相近的语义,例如name,names.为了利用这个特性,本文使用character embedding的方式来表示每个token,公式如下:
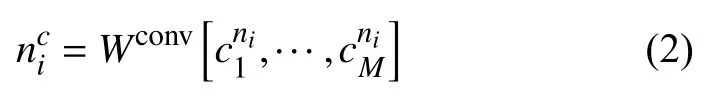
其中,Wconv表示一层卷积权重,通过卷积操作来提取字符之间的特征;M为字符序列的最大长度,如果长度小于M,则会被填充字符填充至M.在卷积层之后会附加一层归一化层(layer normalization[23])来对特征向量进行归一化.最终使用加和的方式来结合word和character的特征向量:

其中,character的特征向量nci会保留到下文的characterword 注意力层,利用注意力机制来更好的融合character和word 特征向量.
3.4 AST 编码器结构
AST 编码器是由一组encoder 组成(总共有N个encoder).其中每个encoder中都包含3 个不同的子层,分别为多头自注意力层,character-word 注意力层以及图卷积层,通过这3 个子层来提取输入代码中的特征信息.本文将会在下面的小结中详细介绍这些子层.其中每个子层之间添加了残差连接(residual connection[24])以及归一化层,其中残差连接可以有效缓解网络退化问题和梯度弥散问题.
多头自注意力层:AST 编码器中的self-attention子层与原生Transformer 相同,使用了多头自注意力机制来捕捉长程依赖信息.
假设有一组输入的token 序列n1,···,nL,从上文可知,通过look-up table embedding 方式可以得到一组初始化的特征向量{n1,···,nL}.由于输入序列是有序的,为了让模型学习到序列中的位置关系,需要在特征向量中加入位置信息,并使用position embedding 来对位置信息进行编码:

其中,PE是二维矩阵,行表示节点,列表示节点的词向量;pos表示节点在输入序列中的位置,dmodel表示词向量的维度,i表示词向量的位置.
每个Transformer中的encoder和decoder 都会通过多头自注意力机制来学习数据中的非线性特征,它的主要思想是将一个序列文本的上下文词汇通过矩阵乘法的方式,使每个词汇都拥有其上下文词汇的特征信息.而传统的注意力机制只是关注了源文本和目标文本之间关系.多头自注意力机制是将多个拥有不同参数的自注意力机制进行融合,使模型增强了关注序列文本不同位置的能力;同时丰富了序列文本词汇的特征信息.多头自注意力机制拥有更多线性变换,变换之后会通过激活函数进行非线性转换,从而提高了模型非线性的学习能力.其公式如下:

其中,H表示头的数量,Wh表示权重.同时在每个头中都会添加一层self-attention 层,如下:

其中,dk=d/H表示每个特征向量的长度.Q,K,V的计算如下:

其中,WQ,WK,WV是模型的参数,xi是AST encoder的输入.对于第一个encoder的输入来说,它是将word、character以及position的特征向量进行加和,例如ni+nci+PEi.而其他encoder的输入来自上一个encoder的输出.
Character-word 注意力层[19]:经过self-attention层计算得到的特征向量,本层将会把该向量与保留下来的character embedding 向量进行结合.对于每一个单词,将对进行两个不同线性转化,得到控制向量qi和权重向量,对进行一个线性转化得到权重向量,最后经过Softmax 计算得到:

得到的两个注意力分数是用来衡量Transformer中self-attention 层的输出和character embeddingnci,然后分别进行线性转化得到vyi和vci:

最后character-word 注意力层的输出为Ycwa=[h1,···,hL].
图卷积层:考虑到模型很难学习节点的双亲节点、祖先节点等相关节点之间的关系,例如:节点a和节点b在文本中距离很远,但是在AST 结构中距离却很近,因此,对于传统的Transformer 模型来说很难提取这样的结构信息.
为了更好的提取程序的结构信息,将AST 通过增加边的方式扩展为图的形式,其中使用了7 种边的类型[21]:
(1)Child edge:当前节点与孩子之间的边.
(2)Parent edge:当前节点与双亲节点之间的边.
(3)Grandparent edge:当前节点与祖先节点之间的边.
(4)Next edge:当前节点与其先驱节点(语义)之间的边.
(5)LastUse edge:当前节点与在词法上最近节点之间的边.
(6)Next sibling edge:当前节点与兄弟节点之间的边.
(7)Subtoken edge:subtokens 之间的边.
TrGCN 将AST 视为图的形式,同时使用邻接矩阵来表示AST 扩展之后的图.根据上文信息,可以得到邻接矩阵M1,···,M7.给定一个邻接矩阵M1,如果节点αi是节点 αj的双亲节点,则M1,ij=1.假设节点的特征向量被表示为fi,则通过邻接矩阵M1可以得到节点i双亲节点的特征向量,计算如下:

同理可以得到节点i的其他相关节点的特征表示,计算如下:

其中,fik表示节点i的第k种类型相关节点的特征向量.对根节点来说,其双亲节点就是其本身,对于其他非AST节点(填充节点)来说,其任何相关节点的特征向量都是它本身.
为了将节点与其相关节点的特征向量结合起来,本文使用了图卷积神经网络,公式如下:

其中,Wgconv,l是图卷积层的权重参数,卷积核大小k=3,l表示图卷积层的层数.特别的是,表示当前节点的特征向量,表示character-word 注意力机制的输出,f是激活函数ReLU,被应用于这些图卷积层中.
综上所述,AST 编码器有N个encoder,其中每个encoder 包含3 个子层,最后AST 编码器的输出为
3.5 解码器
模型最后的模块是解码器,其作用是通过对AST解码器的结果进行解码,从而来预测函数名.解码器与AST 编码器的结构很类似,由一组N个decoder 组成,其中包含多头自注意力层,encoder-decoder 注意力层以及全连接层3 个子层.在每个子层都会增加残差连接和归一化层,帮助模型训练.其中在训练阶段,decoder的输入为函数名,在预测阶段,输入为空序列(仅由填充字符组成).
TrGCN 利用上文提到的两个注意力子层将AST编码器的输出与decoder的输入进行结合.首先利用多头自注意力机制来提取目标语句的特征向量,···,,其中d-self 表示解码器中的多头自注意力子层,P表示目标语句的最大长度.然后利用Encoder-Decoder注意力机制来学习目标语句和源语句之间的关系.其中Encoder-Decoder 注意力层与多头自注意力层结构相同,输入不同,只要将,···,当做Q向量,将当做K,V向量即可.
最后使用两层全连接层,其中第一层全连接层使用激活函数ReLU,第二层全连接层用来提取特征,帮助模型预测结果.
3.6 模型训练
预测函数名的下一个单词是通过使用激活函数Softmax对解码器最后一层的输出进行计算,从而得到所有候选单词的概率,选择概率最大的单词作为结果.
为了提高语义提取效果,TrGCN 使用了指针网络[25],该网络可以直接从函数体中复制单词来作为预测函数名时的候选单词.如图3所示,指针网络可以在预测函数名getName 时,从语句return name 或者形参String name中复制单词name,进行预测.

图3 函数样例
指针网络通过学习一个概率来指导模型对函数体中的单词进行复制或者是生成新的单词.公式如下:

其中,w表示单词,P(w)表示预测单词w的概率,Pvocab(w)表示在词表中单词w的概率,pgen表示生成新的单词的概率,它是根据解码器最后一层的特征向量进行线性转化,然后通过Sigmoid 函数计算得出;Pc表示单词w对源语句单词的注意力分布.从公式中可以看出,当词表中没有单词w时,即Pvocab(w)=0,该网络可以从函数体中进行单词的复制,这样可以有效缓解Out of Vocabulary[25]问题,避免未知单词的出现.
在指针网络进行单词复制时,因为在AST中终结符包含程序的语义信息,非终结符包含程序的结构信息,根据非终结符不会在函数体中出现,仅需要从AST中的终结符复制的特点,TrGCN 使用了Children 注意力机制来计算Pc,公式如下:

其中,hdec表示decoder 最后一层的特征向量,yast是AST 编码器最后一层的特征向量,Mask是掩码矩阵,将 βt中的非终结符置为-INF,仅计算终结符与目标语句之间的注意力分数.最后利用Softmax 来计算每个目标语句中单词的概率.
4 实验评估
本文在Java 函数命名任务中评估TrGCN,通过给定Java 方法的函数体,来预测函数名.先前的研究表明,这是一个很好的基准任务.因为其数据集选自Github开源的Java 项目,其中的函数可以被认为是准确的、相关的,函数体总体上都是完整的逻辑单元.同时我们会对函数名进行处理,将其转化为一组子token 序列,例如getMaxNumber 可以被预测为序列get max number.其中目标序列的平均长度为3.
4.1 数据集
如表1所示,本文使用3 个不同规模的Java 数据集来评估模型,Java-small,Java-med,Java-large[6,9].

表1 数据集统计
Java-small 包含12 个大型的Java 项目,其中9 个项目作为训练集,1 个项目作为验证集,1 个项目作为测试集.该数据集包含约770 k 条样例.
Java-med 包含1000 个来自Github的星标Java 项目.其中799 个项目作为训练集,100 个项目作为验证集,96 个项目作为测试集.该数据集大约有4 M 条样例.
Java-large 包含9555 个来自Github的星标Java项目.其中8998 个项目作为训练集,250 个项目作为验证集,307 个项目作为测试集.该数据集大约有14 M条样例.
4.2 评估标准
本文采取的评估标准是Allamanis[6]以及Alon[9]等先前工作使用的评估标准,对预测结果产生的subtokens 计算Precision、Recall和F1 值,其中目标语句大小写不敏感.这个指标的主要思想是一个预测出的函数名的质量依赖于其组成的子单词.例如,对于一个函数名countNumbers,如果预测出的结果为numbersCount,也认为它是精确的匹配;如果预测结果为count,那么它的Precision为100%,但是Recall值却很低;如果预测结果为countRandomNumbers,那么它的Recall值为100%,但是Precision值很低.本文希望使Precision和Recall都尽可能的大,但是这显然有些困难,所以使用F1 值来衡量这两个标准.公式如下:

其中,TP为预测正确单词的数量,FP为预测错误单词的数量,FN为没有预测出正确单词的数量.
本文还使用了ROUGE[26]评估标准.该标准主要用于摘要的自动评价,通过比较机器自动生成的摘要与人工生成的摘要中重叠单元的数量,来评价机器自动生成摘要的效果.本文主要使用了ROUGE-2,ROUGEL.公式如下:

其中,分母统计目标语句中N-gram的个数,而分子统计目标语句与预测出的语句共有N-gram的个数,本文将N设置为2 或L,其中L代表预测出的语句和目标语句的最长公共子序列.
4.3 实验设置和环境配置
在TrGCN 模型中,AST 编码器中encoder的数量为N=6,解码器中decoder的数量为N=6.词向量的维度和模型维度dvector=dmodel=128.隐藏层的维度dhid=512.在模型输入中,本文尝试使用参数学习的加权方式来融合character和word特征向量,其公式为其中vT为权值参数,b为偏差值.其中实验得到的F1 值分别为53.46%、53.34%,没有显著差异(差异可能由于实验的随机性导致).推测原因为TrGCN 所使用的character-word 注意力机制的本质也是将word和character 特征向量通过加权的方式融合,而且在AST 编码器中N(N=6) 个encoder 都会使用character-word 注意力机制,所以多一次加权融合对模型学习能力没有明显的影响.为了减少参数量,加快实验运行速度,所以本文在模型输入阶段选择了直接加和的方式对character和word 特征向量进行融合.在多头自注意力机制中,原文将头的数量设置为H=8,为了探究头的数量对模型的影响,分别设置H=2,4,8进 行实验.当H=2时,F1 值为51.25%;当H=4 时,F1 值为53.46%;当H=8时,F1为52.45%.可以看出F1 值随着H的增大而提高.但是当H=8时,F1 值有一定幅度的下降,此时模型出现了过拟合现象.随着H数量的增加模型的非线性学习能力逐渐变强,但是数量增加到一定值后非线性学习能力太强导致出现过拟合的现象,所以本文将头的数量设置为4.
TrGCN 在每一层后使用了dropout,来防止过拟合现象(其中包括注意力层,卷积层以及全连接层),其中dropout=0.3.实验中每次选取的样本数量为batch_size=256,迭代次数epoch=100,为了防止过拟合,使用了早停法,只要连续10 次迭代后F1 值没有比当前最大F1值高,就停止训练,early_stopping=10.为了防止模型出现梯度爆炸,TrGCN 把最终所有候选词的概率截断在[1e-10,1.0]之间.对于模型优化,使用了Adam 优化器[27],参数为默认值.
所有实验都运行在Linux(系统版本3.10.0-957.c17.x86-64,CPU Inter(R) Gold 6240@260 GHz 18 cores,两块显存为12 GB的(NVIDIA)TITAN Xp 显卡)系统下.
4.4 实验结果和分析
在实验中本文使用了6 个基准模型:
(1)Allamanis 等提出ConvAttention 模型[6],该模型使用了带有注意力机制的卷积神经网络来预测函数名;(2) Alon 等提出Path+CRFs[7]模型,将句法路径与条件随机场相结合;(3) Alon 等提出的code2vec[8]模型;(4) Alon 等提出的code2seq[9]模型;(5) Tai 等提出的TreeLSTM 模型;(6) Vaswani 提出的Transformer[12]模型.
表2显示了函数命名任务在Java 数据集中的结果.从表中可以看出,TrGCN 在评估标准Precision、Recall和F1 以及3 个数据集中,几乎都优于所有基准模型.与ConvAttention对比,TrGCN 在F1 值提升约20.41%至21.8%,其原因可能为TrGCN 有效的提取了程序的结构信息.同样在和TreeLSTM对比中发现,TrGCN在F1 提升约6.12%至23.49%.虽然TreeLSTM[28]也提取了程序的结构信息,但是我们认为基于图的神经网络模型可以丰富结构信息,具有更强的建模能力.在与当前使用广泛模型code2seq[9]比较中发现,我们的模型在F1 值有着明显提高,在数据集Java-small 提升了10.44%,在数据集Java-med 提升了4.7%.

表2 在Precision,Recall,F1 以及Java-small,Java-med,Java-large 三个数据集与基准模型比较结果
其原因可能不仅是图卷积神经网络提取到更加丰富的结构信息,而且character-word 注意力机制以及指针网络可以有效的提升语义提取的效果.但是我们发现随着数据规模的增大,我们模型提升效果逐渐减小;尤其在数据集Java-large中,Precision略低于code2seq模型,F1 仅提高了0.56%.可能的原因有:(1)随着数据规模的增大,但是模型复杂度不变,模型很难进一步从庞大的数据中学习;(2)基于图的神经网络模型虽然有很强的建模能力,但是也具有模型复杂、较难训练的特点,其中在3 个数据集训练过程中,迭代一次分别需要40 分钟、2 小时和4 小时;(3)实验资源短缺,实验室仅有两块12 G 显存的(NVIDIA)TITAN Xp 显卡,随着数据量的增大,内存以及显存无法满足训练要求,所以只能通过减小batch_size 来克服资源问题,但是batch_size的大小一定程度会影响实验结果.
同时,我们选择了一个基于图神经网络的基准模型,Fernandes 等[10]提出的Sequence-GNNs 模型,该模型使用图神经网络来对程序进行编码.表3说明我们的模型在评估标准F1,ROUGE-2 以及ROUGE-L 都优于模型Sequence-GNNs.在code2seq 文章中提到,Sequence-GNNs 在数据集Java-large 上的F1 值低于code2seq,所以我们只使用了数据集Java-small 进行比较.

表3 与Sequence-GNNs 在数据集Java-small的比较
从表3中可以看出TrGCN 在F1 值比Sequence-GNNs 提升了2.1%,说明TrGCN 在不考虑预测结果单词顺序的情况下有较强的预测能力;在ROUGE-2和ROUGE-L 分别提高了0.7%、3.6%,可以看出TrGCN在考虑预测结果单词顺序的情况下同样优于Sequence-GNNs.所以TrGCN 模型在融合Transformer、图卷积以及character-word 注意力机制后的预测能力的提高是有效的.
5 结论与展望
本文提出了一个TrGCN 模型来解决函数自动化命名任务.TrGCN 利用Transformer中的注意力机制来缓解模型训练时遇到的长程依赖问题;利用图卷积神经网络提取更为丰富的结构信息,使得程序的特征向量信息更加完整;利用character-word 注意力机制以及指针网络来丰富程序的语义信息.实验结果表明,TrGCN的函数命名效果优于其他基准模型.在后续的研究中,作者将使用不同的编程语言数据集,以及不同的代码摘要任务来验证方法的有效性.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
中学生理科应试(2021年11期)2021-12-09
上海师范大学学报·自然科学版(2019年5期)2019-12-13
数学学习与研究(2018年15期)2018-11-12
新高考·高二数学(2016年7期)2017-01-23
电脑知识与技术(2016年22期)2016-10-31
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
