
基于在线问卷调查的卷烟竞品评价文本挖掘分析
2021-09-14 15:17汪显国李思源李思典林鸿佳杨晶津刘丹许磊
中国市场 2021年25期
关键词:文本挖掘
汪显国 李思源 李思典 林鸿佳 杨晶津 刘丹 许磊
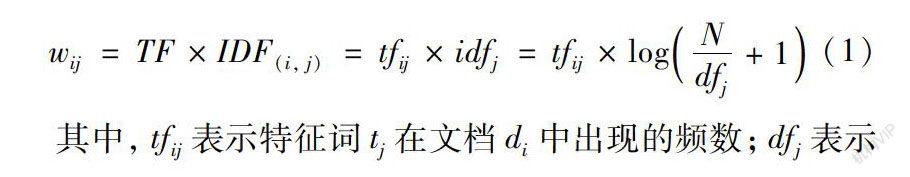


[摘 要]为了维护卷烟产品质量和把握消费者关注热点,通过在线问卷调查获取消费者抽吸感知评价数据,并从消费者满意度、评论热度和文本特征提取等方面开展竞品对比分析,实现了新的竞品筛选及其特征提取方式。研究表明:①通过客观评分得出卷烟A在外观整体、吸味整体和产品综合上的满意度远高于其他竞品;②文本挖掘得出消费者关注的竞品与专家筛选的竞品存在差异,且其产品优势集中表现为“口感”“价格”“吸味”等。该分析方法可有效动态监测消费者偏好和市场消费趋势,为卷烟工业企业改进产品质量提供支持。
[关键词]在线问卷调查;竞品评价;文本挖掘;TF-IDF算法;词云图
[DOI]10.13939/j.cnki.zgsc.2021.25.133
1 前言
卷烟产品质量与卷烟企业的信誉、消费者的体验、企业的生存发展息息相关。当前,以市场为导向,在满足不同消费者需求的前提下培育高质量的卷烟品牌已经成为行业企业发展的共识。因此,获取消费者的消费评价和需求信息对卷烟工业企业维护产品质量而言显得尤为重要。随着互联网的迅速发展,各种网络平台为企业提供与消费者沟通的便利渠道。利用网络平台形成的在线问卷调查成了获取卷烟消费评价的有效途径,同时弥补了由评吸员评价的传统方式中存在的样本少、成本高、主观性不强等不足。在所收集的问卷数据中,通常会存在消费者对产品的主观评价,以文本数据的形式呈现,反映了消费者的真实体验和使用心得,蕴含了极其丰富的信息。采用文本分析方法挖掘文本数据的隐含信息,可以帮助企业了解消费者的真实需求,具有重要的现实意义[1]。
文本挖掘分析,又称为意见挖掘,是利用自然语言处理技术、数据挖掘算法等对带有情感色彩的主观性文本进行预处理、归纳和推理的过程[2]。近些年来,运用文本挖掘技术将难以量化的文本数据进行清洗、整合、转换为结构化数据,并提取有价值的信息已广泛应用于商业[3]、旅游[4]和金融[5]等领域。然而,对于问卷调查中消费者主观评价文本的研究却鲜见报道。因此,文章基于在线问卷调查采集而来的竞品评价文本,利用文本挖掘技术探索消费者对卷烟产品的关注热点,剖析国内市场卷烟的热销品及其产品优势,捕捉消费者对产品质量的需求,为卷烟工业企业改进卷烟产品质量提供参考。
2 研究方法
2.1 在线问卷调查
为了深入了解消费者评价卷烟抽吸感知的关键要素,通过营销渠道邀请全国31个省市消费者参与卷烟A及竞品的评吸、评价活动,并进行在线问卷调查。问卷由结构化客观题和非结构化主观题组成,分为人口学特征、抽吸评价和竞品对比及质量改进三部分。人口学特征包括性别、年龄、烟龄、消费水平4个问题,抽吸评价包括香气浓度、香气类型、一致性、抽吸感受等8个问题,竞品对比及质量改进的指标评价、主观评价等3个问题。其中,第三部分除了客观评分以外,还设置主观评价的问题。例如“您认为在15~20元/包的常规支产品中,还有哪款产品抽吸体验更好或在当地更畅销,该产品主要好在哪些方面?”该部分构成了问卷调查中竞品评价的文本数据。
2.2 文本挖掘方法
2.2.1 中文分词
在进行文本数据分析前,需要对文本进行分词处理。中文分词就是将一段话切割成有字和词或短语的小片段,是文本挖掘、特征提取的基础[6]。在自然语言分类中,中文原本起步就比国外晚了很多年,在分词的技术上更是借鉴国外的方法。目前,常用的中文分词算法有:基于词典的分词方法、基于语义的分词方法及基于统计的分词方法等。其中,基于词典的分词方法是选定的字或词构成字符串,与字典里的字符串进行匹配[6]。假设需识别文本中的字符串Z,若词典中存在字符串Z,则可匹配成功。该方法效率高但是对新词的识别能力不足,需经常更新词典[7];基于语义的分词方法是根据中文的句法以及语义来划分句子,从而达到分词的目的。这种方法需要前期做大量的准备工作,需要对几乎所有的语料、语义、语法进行标注,甚至还需要考虑中文语义里的反讽、反语以及正词反义等一系列的特殊语义;基于统计的分词方法是根据同时出现的相邻两个字的频率来进行分词,可以不受待处理文本领域的限制自动排除歧义并识别相应的词语[7]。
以上3种中文分词方法各有优缺点,文章采用基于词典的分词方法对文本进行分词,并调用R软件的jiebaR安装包来实现。jiebaR包拥有自己的系统词典,且词汇量相当丰富,结合自建的烟草专有名词词典,共同形成本文文本分析的分词词典。
2.2.2 文本数据清洗
首先,原始文本数据会包含大量重复性、无语义的评论,例如数字、字母以及特殊字符,或者包含例如“没有”“好”字符很小的极短评论,此类评论内容蕴含的信息量很少,会增加文本分析的复杂度,需将其清除过滤。
其次,对文本分词处理后会出大量的停用词。停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据之后会自动过滤掉某些字或词,这些字或词即被称为Stop-Words。对于停用词的去除,即可采用现有的停用词词典,也可以根据需要自建停用词典。
最后,文本中使用频率不高的非停用词往往对文本特征的提取也没有价值,故对这类词也需要进行清除,即可根据词语的长度或出现的频数进行过滤处理。
2.2.3 文本特征提取
特征提取本质上是一种降维的技术,目的是从样本所有的特征中筛选出具有区分性和代表性的特征,从而提高模型或方法的分类性能[8]。特征提取一般先构建特征选取函数,计算所有特征的权重,然后筛选出权重大的特征作为关键特征。文本特征提取时常用的方法有文档频数[9](Document Frequency,DF)、信息增益[10-11](Information Gain,IG)、互信息[10,12-13](Mutual Information,MI)、x2统计法[10,12](CHI)等。通过比较,文章采用的方法是TF-IDF算法[14],TF-IDF實际上是TF与IDF的乘积。TF代表词频(Term Frequency),指词或短语在一篇文档中出现的频数;IDF代表逆向文件频率(Inverse Document Frequency),指含有词或短语的文档数在总文档中所占比例取逆后的对数值,表征该词项区分文档的能力。当某个词或短语在一篇文档中出现的频率越高并且在其他文档中出现的次数越少,说明该词或短语的区分能力越强,其TF-IDF值越大。计算公式如下:
猜你喜欢
科技资讯(2017年5期)2017-04-12
电脑知识与技术(2016年33期)2017-03-21
商情(2016年32期)2017-03-04
软件导刊(2016年12期)2017-01-21
电子技术与软件工程(2016年22期)2016-12-26
商(2016年34期)2016-11-24
中国中医药图书情报(2016年4期)2016-10-20
湖南师范大学学报·自然科学版(2016年3期)2016-06-25
语文教学之友(2016年5期)2016-06-15
电脑知识与技术(2016年5期)2016-04-14
