
基于自适应邻域和自表示正则的无监督特征选择算法
2021-09-15 08:02张继炎王慧玲黄宏昆刘艳芳
南京理工大学学报 2021年4期
彭 明,张继炎,王慧玲,黄宏昆,刘艳芳
(1.龙岩学院 数学与信息工程学院,福建 龙岩 364012;2.伊犁师范大学 电子与信息工程分院,新疆 伊宁 835000)
随着技术的发展,大量高维数据已成为许多应用领域的问题,例如计算机视觉[1,2],数据挖掘[3-5]和模式识别[6]。高维数据不仅增加了运算的时间复杂度和空间复杂度,也会导致学习模型的过拟合现象。同时,高维数据通常包含很多与学习任务无关的噪声和冗余信息。特征选择是从原始数据中选择最具代表性和区分性的特征子集,是处理高维数据的最重要方法之一。
根据数据中是否有标签信息,特征选择分为监督特征选择、半监督特征选择和无监督特征选择。在许多场合下获取标签很费力,因此在实际应用中,无监督特征选择更为实用,它通过聚类[7,8]将无标签的数据根据某种评估标准划分成有意义或有用的簇,但不可避免会遇到很多挑战。在过去的几十年中,国内外许多研究人员在无监督特征选择方面做出了巨大的努力。流形学习[9]验证了高维空间的数据可以在低维空间表示,且被成功应用于无监督特征选择算法中,构造出了一系列性能良好的基于图正则的无监督特征选择算法。主要算法有:基于拉普拉斯打分的特征选择(Laplacian score,LS)[10]根据同类数据较紧凑的特性,利用K近邻得到数据的局部几何结构图,然后计算每个特征的得分选择特征;基于非负谱分析的无监督特征选择算法[11]通过K近邻的相似矩阵得到谱聚类以学习数据集的伪标签,进而和2,1正则结合起来,获得了具有判别性的特征子集;鲁棒的无监督特征选择算法[12]利用了鲁棒非负矩阵分解、局部学习和鲁棒特征学习的优势,并用2,1正则来约束标签和特征之间的关系,删除冗余和噪声特征;嵌入无监督特征选择(Embedded unsupervised feature setection,EUFS)[13]算法通过稀疏学习将特征选择直接嵌入到聚类算法中,而无需进行变换,并用交替方向乘子法(Alternating direction method of multipliers,ADMM)来优化目标函数;随着无监督特征选择数据重构误差[14]的出现,大多数相关算法往往假设线性重构,但重构函数依赖于数据,而高维数据不总是线性的,因此,基于重构的无监督特征选择(Reconstruction-based unsupervised feature selection,REFS)[15]算法研究了如何从数据中自动学习用于无监督特征选择的重构函数,并将重构函数的学习嵌入到特征选择的过程中;大多数的无监督特征选择算法首先根据计算出的特征降序选择最前面的特征子集,然后执行K-means聚类,而这样得到的是一组次优特征,因此依赖指导的无监督特征选择算法[16]以联合的方式选择特征和划分数据集,同时增强了原始数据集、聚类标签和所选特征之间的关系,并提出了基于2,0等式约束的无投影特征选择模型;基于邻域保持学习的无监督特征选择算法[17]利用K近邻重构权重系数,引入中间矩阵构造低维空间,并在低维空间内运用拉普拉斯乘子法优化目标函数进而选择特征子集;根据高维数据的稀疏性,鲁棒邻域嵌入的无监督特征选择算法[18]通过K近邻构造权重系数矩阵,并利用1正则约束删除数据中的噪声和异常点,运用ADMM优化方法得到具有代表性和判别性的特征子集。
上述基于图正则的无监督特征选择算法构造的相似矩阵都是来自原始数据集,没有嵌入到学习过程,且在后续过程中保持不变。为了解决这个问题,自适应结构学习的无监督特征选择算法[19]为结构学习和特征选择提供了一个统一的框架,从特征选择的结果中自适应地学习结构,并重新选择重要特征以保留数据的精确结构;结构图优化的无监督特征选择算法[20]融合了特征选择和局部结构学习,可以自适应地更新相似矩阵,通过约束相似矩阵使其包含更准确的数据结构信息,从而选择更有代表性的特征;基于自适应图和约束的无监督特征选择算法(Unsupervised feature selection via adaptive graph learning and constraint,EGCFS)[21]将相似矩阵的结构纳入优化过程以自适应地学习图结构,同时,将最大化类间散布矩阵和自适应图结构的思想集成到一个统一的框架中,不仅可以获得出色的结构性能,也可以选择不相关但有区别的特征。
然而,无论来自原始数据集的相似矩阵是否嵌入到模型的学习中,相似矩阵都是由相同且固定的近邻数构造或更新的。在现实世界中,高维数据往往是分布不均匀的,为每个样本选取相同而固定的近邻数是不能很好地适应每个样本的局部几何结构的[22],这使得由相同且固定近邻数来构造的相似矩阵是不可靠的。为了解决这个问题,本文基于文献[22]中提出的自适应邻域思想,提出了一种基于自适应邻域和自表示正则的无监督特征选择算法(Adaptive neighborhood regularized self-representation,ANRSR)。首先,根据数据集自身的稀疏稠密情况,为每个样本自适应的选择近邻数,进而构建拉普拉斯矩阵。其次,将拉普拉斯图嵌入到目标函数中,以保持原始数据的局部结构。然后,用迭代算法优化目标函数。最后,在公开的UCI数据集上进行实验,验证所提算法ANRSR的有效性。
1 问题形式化
1.1 符号说明
首先介绍本文中使用的一些符号,其中,大写粗体表示矩阵,小写粗体表示向量。对于任列向量v=[v1,v2,…,vn]T,它的2范数为对于任意矩阵M=[mij]n×d∈Rn×d,M的2,1范数定义为对于任意方阵A=[aij]n×n∈Rn×n,它的迹为可逆矩阵表示为A-1,In∈Rn×n是单位矩阵。
数据集X=[x1;x2;…;xn]=[f1,f2,…,fd]∈Rn×d,表示有n个样本和d个特征,其中xi是一个d维的样本向量,fj是一个n维的特征向量。令样本集S={x1,x2,…,xn},特征集F={f1,f2,…,fd}。
1.2 所提算法ANRSR
特征自表示[23]指每个特征可以由其他的特征线性表示,即,对于数据集X的每一个特征fi,有
(1)
则对于所有的特征向量有
X=XW+E
(2)
式中:W=[wij]d×d∈Rd×d是特征自表示系数矩阵。显然,系数矩阵W反映了不同特征的重要性,令W=[w1;w2;…;wd],其中wi是W的第i行。‖wi‖2表示第i个特征的重要度,则‖wi‖2的值越大,表示第i个特征越重要。通过数据集的特征自表示,无监督特征选择问题转化为如下形式
minW‖X-XW‖2,1+α‖W‖2,1
(3)
式中:α>0是平衡损失项和2,1正则项的参数。
谱图理论和流形学习的研究表明,可以通过数据样本的最近邻图有效地建模局部几何结构[10,24]。因此,将拉普拉斯图嵌入到式(3)中进行优化,如下所示
minW‖X-XW‖2,1+α‖W‖2,1+βtr(WTXTLXW)
(4)
式中:参数β>0,L是拉普拉斯图。
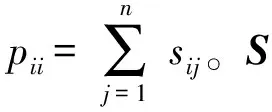
(5)
由于所有样本采用相同且固定的近邻数不能很好地适应每个样本的局部流形结构。文献[22]根据数据自身的稀疏稠密情况自适应选择近邻数。首先,为数据集中的每个样本引入一个有序序列。
定义1有序序列[22]数据集X=[x1;x2;…;xn]∈Rn×d,样本集S={x1,x2,…,xn},令i∈{1,2,…,n},对于样本xi的有序序列定义为
list(xi)=(x(i,1),x(i,2),…,x(i,n-1))
(6)
式中:Δ(xi,x(i,1))≤Δ(xi,x(i,2))≤…≤Δ(xi,x(i,n-1)),S={xi,x(i,1),x(i,2),…,x(i,n-1)},Δ(xi,xj)是样本xi和样本xj之间的欧式距离。简单起见,将Δ(xi,x(i,j))记为Δi(x(i,j))。


(7)
式(4)中的拉普拉斯图是根据数据自身的稀疏稠密情况自适应选择近邻数来构建的,则这个模型就被称为基于自适应邻域和自表示正则的无监督特征选择算法ANRSR。
不同于K近邻法,在定义2中,数据集中每个样本点获得的最近邻个数是不同的,能够反映出数据集的样本稀疏稠密情况。算法1[22]给出了自适应邻域集的求解过程。

算法1自适应邻域集
输入:数据集X∈Rn×d(d个特征,n个样本)中的样本xi(i=1,2,…,n);
输出:自适应邻域集AN(xi);
1: 运用欧式距离,分别计算样本xi与样本x1,…,xi-1,xi+1,…,xn的距离,得到距离向量disi;
2: 升序排列更新disi,根据定义1得到xi的有序序列list(xi);
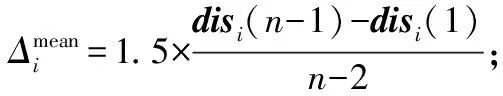
4: 根据list(xi),采用式(7)计算xi的自适应邻域集AN(xi)。
2 算法模型优化
ANRSR模型实际上是凸的,但是损失函数和正则项都不平滑。因此在本节中,使用迭代方法解决ANRSR的优化问题。
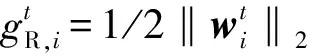
(8)
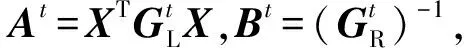
(9)
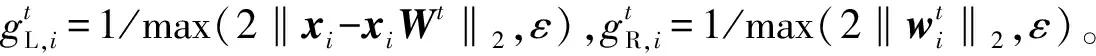
算法2基于自适应邻域和自表示正则的无监督特征选择算法ANRSR
输入:数据集X∈Rn×d(n个样本,d个特征),参数α,β,选择的特征个数m;
输出:所选的特征子集I;
2: fori=1∶n
3: 调用算法1,获得样本xi的自适应邻域集AN(xi);
4: 根据式(5),计算样本xi与AN(xi)中样本的相似权重系数si;
5: end if
6: 样本相似矩阵S=[s1;…;sn];
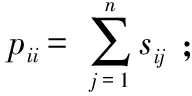
8: repeat
9: 用式(9)更新Wt+1;
11:t=t+1;
12:until收敛;
13:W=[w1;w2;…;wd],降序排列‖wi‖2,i=1,2,…,d,则I是前m个向量的下标集所对应的特征子集。
在ANRSR算法中,首先需要根据自适应邻域计算拉普拉斯矩阵,其计算复杂度为O(n2d);其次是迭代更新W,每次迭代的时间复杂度为O(n2d+d3)。则ANRSR的总时间复杂度为O(n2d+T(n2d+d3)),其中T是迭代的次数。又迭代次数T通常是大于1的,因此,ANRSR的时间复杂度为O(T(n2d+d3))。
3 实验与结果分析
实验选用了4个公开的人脸数据集对算法进行测试研究,包括JAFFE、IMM40、ATT40、warpAR10P,其中,JAFFE、IMM40、ATT40是来自于文献[21]的数据集,可从https://github.com/LilyLSL/EGCFS中获取,warpAR10P可从FEATURE SELECTION DATASETS(http://featureselection.asu.edu/datasets.php)中获取。数据集的详细信息如表1所示。

表1 实验数据集描述
3.1 实验参数设计
为了验证本文提出的基于自适应邻域和自表示正则的无监督特征选择算法ANRSR的优势,将其和选择所有特征(Baseline)以及4种经典的无监督特征选择算法进行了比较,包括基于拉普拉斯打分的特征选择LS[10]、嵌入无监督特征选择EUFS[13]算法、基于重构的无监督特征选择REFS[15]算法、基于自适应图和约束的无监督特征选择EGCFS[21]算法。对比算法LS、EUFS、REFS和本文所提算法ANRSR采用热核相似性度量和带宽参数t=1得到拉普拉斯图,EGCFS在学习过程中自动更新拉普拉斯图。同时,ANRSR的近邻数是根据数据集本身的分布自适应得到的,其他对比算法LS、EUFS、REFS、EGCFS的近邻数k均设置为5。为了公平比较,通过网格搜索范围{10-4,10-3,10-2,10-1,1,101,102,103,104}为所有对比算法调整其正则化参数,并记录其最佳性能。对所有的数据集,特征选择的个数设置为{20,30,…,100}。实验选用K-means算法进行聚类,由于K-means算法对初始选取的聚类中心点是敏感的,因此,K-means算法对选取的特征子集运行30次实验记录平均值。
3.2 度量标准
为了验证算法的有效性,文中采用两种判断标准:聚类精度(Clustering accuracy,ACC)和归一化互信息(Normalized mutual information,NMI)来衡量不同算法选择不同特征子集时的效果,其中,ACC和NMI的值越大表示算法效果越好。
3.3 实验结果分析
本节比较了所提算法ANRSR算法与LS、EUFS、REFS、EGCFS和Baseline在表1数据集上的性能,并对性能指标进行了分析。
为了说明参数α,β对所提算法ANRSR的敏感程度,图1展示了参数对IMM40数据集的影响。从图1中可以看出,算法ANRSR对β不敏感,而对α敏感。当α较大时,获取W的更多行稀疏,从而在某种程度上获取更精确的特征重要度排序。但是对于如何自适应获得较好的参数值依旧是一个开放式的问题。
图1 在数据集IMM40上所提算法ANRSR关于参数的影响
表2和表3分别记录了不同算法在表1的4个数据集上最高的聚类精度和归一化互信息结果,其中最好的结果用粗体标注,次优用下划线标注。与保留全部特征(Baseline)的聚类精度相比,ANRSR不仅大幅度地降低了特征维数,而且提高了聚类性能,这表明ANRSR选择的特征子集相对具有代表性和判别性。同时,ANRSR的聚类精度在3个数据集上优于其他对比算法,而在归一化互信息上均优于其他对比的无监督特征选择算法。
从表2和表3的信息可知,所提算法ANRSR在总体性能上高于其他对比算法。尽管所有对比的无监督特征选择算法LS、EUFS、REFS和EGCFS在模型学习过程中均保持了原有数据集的局部几何结构,但本文所提算法得到的聚类性能更好,原因可以归结为以下两点:(1)ANRSR采用的是能捕捉原数据集稀疏稠密的局部几何结构,而LS、EUFS、REFS均采用的是忽略数据集分布结构的相同且固定的邻域数;(2)EGCFS在IMM40数据集上的聚类精度高于ANRSR,但只高出了0.2%。EGCFS算法在优化过程中是自适应学习且更新局部结构,但每次更新时依旧固定了邻域数目。
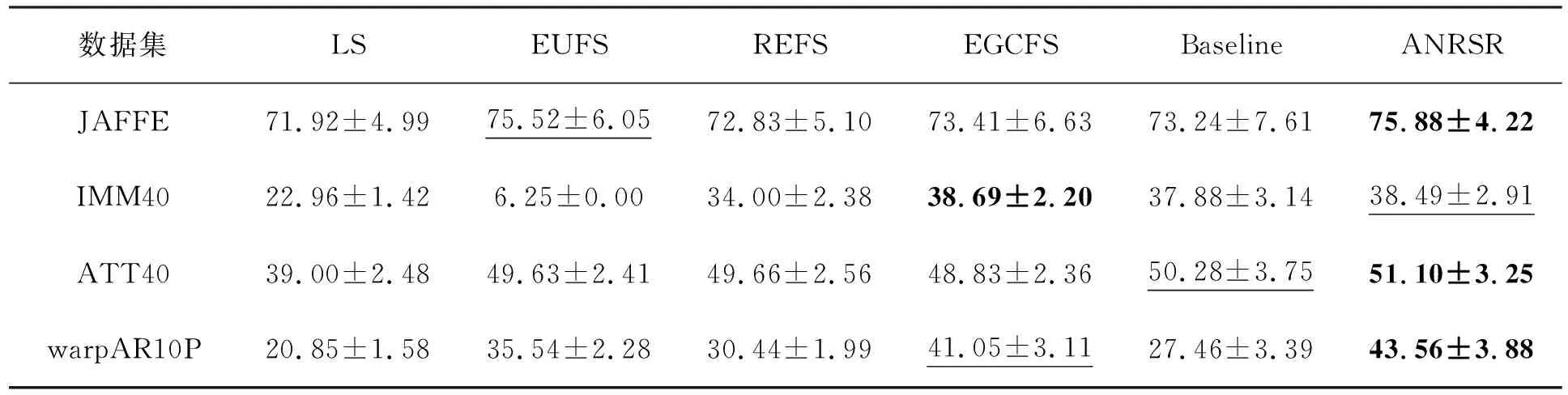
表2 所有无监督特征选择对比算法的最大聚类精度

表3 所有无监督特征选择对比算法的最大归一化互信息
为了进一步说明ANRSR所选择的特征子集是重要的且具有判别性,本节展示了ANRSR在ATT40数据集上的效果示例图。首先,从ATT40中随机的选择两个样本;然后,执行ANRSR算法,为这两个样本分别选择出20、40、60、80、100个特征。具体效果如图2所示,其中,从左到右依次是原图、选择20、40、60、80、100个特征所对应的图,白色“方块”表示所选择的特征。从图2可以看出,ANRSR算法所选择的特征倾向于有判别性的部分,如眼、鼻子、唇和脸颊,这些特征通常用来描述一个人脸的特性。这也意味着ANRSR在一定程度上可以获得最优的特征子集。

图2 ANRSR算法作用在ATT40数据集上的示例图
4 结束语
本文提出了一种基于自适应邻域和自表示正则的无监督特征选择算法。不同于已存在的基于流形结构的无监督特征选择算法,本文所提算法不需要人为地对不同的数据集指定相同且固定的邻域个数,而是根据数据集自身的稀疏稠密分布情况来确定每个样本的近邻数,进而构造拉普拉斯图,并将其与具有鲁棒性的特征自表示无监督特征选择框架相结合。实验表明,本文所提算法可以选择出具有判别性的特征子集,进而取得较好的聚类效果。然而,本文中嵌入的拉普拉斯图在模型学习过程中保持不变,拉普拉斯图是由原始数据集构造的,而原始的高维数据集往往有噪声和异常,导致自适应邻域集可能不可靠,在接下来的工作中需要探索如何在优化过程中更新邻域集构造的拉普拉斯图。
猜你喜欢
现代职业教育·高职高专(2021年11期)2021-08-27
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
新世纪图书馆(2021年12期)2021-01-19
卷宗(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
上海师范大学学报·自然科学版(2018年3期)2018-05-14
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
