
多尺度决策系统中基于模糊相似关系的决策粗糙集最优尺度选择与约简
2021-09-15 08:03杨璇,黄兵
南京理工大学学报 2021年4期
杨 璇,黄 兵
(南京审计大学 信息工程学院,江苏 南京 211815)
由波兰科学家Pawlak所提出的经典粗糙集理论[1]是分析、处理各种类型数据的有效工具,因其自身所具有的不需任何有关数据的初步或附加信息的特性,故对处理模糊和不确定性问题的能力显得尤其突出。自提出以来,粗糙集理论在集合近似和属性约简两大方面不断做出重大贡献,在数据挖掘、图像处理、模式识别等领域得到广泛应用。
然而Pawlak经典粗糙集模型也存在不可避免的局限性。相对经典模型中的对象以符号取值,在实际生活中,所面临的数据往往并不理想,数据的缺失、不确定现象比比皆是。此外,经典粗糙集中基于等价关系的上下近似要求也十分严格。在粗糙集理论不断发展的过程中,众学者针对存在的限制对经典粗糙集进行了不同类型的拓展,至今已得到模糊粗糙集[2]、直觉模糊粗糙集[3]、不完备信息系统粗糙集[4]、优势粗糙集[5]、决策粗糙集[6]等众多拓展模型。其中,决策粗糙集是粗糙集理论与贝叶斯决策理论相结合得到的成果,旨在最大程度地降低分类风险以实现对目标概念的粗糙近似。Yao[6]针对决策粗糙集提出了一种新的规则归纳方法,通过设定决策阈值α、β来确定其容错能力,并将分类决策设为由正域POS(α,β)、负域NEG(α,β)、边界域BND(α,β)3个区域构成,进一步提高了决策粗糙集的实用价值。这吸引了广大学者的关注,对其进行了大量改进与推广。Liu等[7]提出了一种基于不完备信息系统的三支决策模型;Lin等[8]通过对论域进行模糊划分,从多源信息系统中得到多个模糊粒度,提出了一个新的模糊多粒度决策粗糙集模型;刘丹等[9]在不完备信息系统中引入邻域容差关系,从乐观、悲观、平均3个方面分别讨论了相应的不完备邻域多粒度决策粗糙集模型;Sun等[10]将概率粗糙集推广到了模糊环境下,建立了模糊决策粗糙集模型,进一步扩大了决策粗糙集的适用范围;Song等[11]基于Sun等给出的模糊决策粗糙集模型,采用启发式算法进行特征选择,进一步最小化决策代价;王鹏等[12]考虑到对噪声数据的容忍性问题,在传统模糊相似关系中引入一个限定阈值,提出一种改进的模糊粗糙集模型;Yao等[13]探讨了基于贝叶斯决策过程的近似概念的定义;王莉等[14]研究了一种新的模糊决策粗糙集模型及相应的属性约简算法;方宇等[15]在定性和定量的标准下提出了一种基于三支决策的广义代价敏感近似属性约简算法;王宇等[16]讨论了决策粗糙集属性约简的一种局部视角方法。
在现实生活中,同一属性往往会具有不同层次,并且同一属性在不同层次上取值不同。例如学生成绩可分为90~100分、80~90分、70~80分、60~70分、60分以下这5种情况,也可分别用A、B、C、D来表示优、良、中、差,或者进一步简化为及格、不及格两种情况。考虑到属性的这一特性,研究学者提出了多尺度的概念并进行了延伸,将多尺度泛化到了优势直觉粗糙集[17]、决策粗糙集[18]、对偶概率粗糙集[19]、邻域粗糙集[20,21]、变精度粗糙集[22,23]、集值粗糙集[24]等环境下进行讨论。但迄今为止,将模糊决策粗糙集模型引入到多尺度环境下的研究仍然较为少见。
为此,本文针对多尺度决策系统,建立多尺度决策系统中基于模糊相似关系的决策粗糙集模型,给出相应的最优尺度选择及约简方法,并提出一个较为简便的最优尺度约简算法。最后采用UCI数据集进行实例验证,证明本文所提模型及算法的可行性和有效性。本文所提模型及算法进一步拓展了基于模糊相似关系的决策粗糙集的研究范围,扩大和提高了基于模糊相似关系的决策粗糙集在实际应用中的广泛性与有效性,为基于模糊相似关系的决策粗糙集在多尺度决策系统下的知识获取提供了新思路。
1 预备知识
1.1 基于模糊相似关系的决策粗糙集



1.2 多尺度决策系统

由定义可知,一个多尺度信息表是由多个单尺度信息表组成的,每一个单尺度信息表的属性之间都存在一定的二元关系。因此,在进行属性约简和规则提取的过程中,往往会将一个多尺度信息表进行分解再加以处理。
定义4[17]设多尺度信息表S=(U,A),其中,aj∈A(j=1,2,…,m)具有Ij个尺度,被限制在其相应尺度的属性a1,a2,…,aj(j=1,2,…,m)构成一个单尺度信息表SK,其中,K=(l1,l2,…,lm)为一索引集合,称为S中SK的尺度组合。S中所有尺度组合的族称为S的尺度集合,记为L={(l1,l2,…,lm)|1≤lj≤Ij,j=1,2,…,m}。
定义5[17]设D=(U,C∪{d})为一多尺度决策表,其中,(U,C)为一多尺度信息表且d∉C,d:U→Vd称为决策属性。
2 多尺度决策系统中基于模糊相似关系的决策粗糙集
传统的基于模糊相似关系的决策粗糙集是基于单尺度决策表进行讨论的,单尺度决策表中的每个属性取值一定。但现实中,同一对象的同一属性可能具有多个尺度层次,且在每个尺度层次上的取值可能不同。下面给出多尺度决策系统中基于模糊相似关系的决策粗糙集模型的定义。


定理1基于定义6中的定义给出下列性质:

3 最优尺度选择及约简
3.1 最优尺度选择
最优尺度选择是从多尺度决策系统中进行知识发现和规则提取的一个重要环节,能够跳过很多不必要的数据分析工作。下面,基于多尺度决策系统,讨论多尺度决策系统中基于模糊相似关系的决策粗糙集的最优尺度选择问题,并给出相应算法。
定义7[27]设K1=(l11,l12,…,l1m),K2=(l21,l22,…,l2m)∈L。
K1≤K2⟺l1j=l2j,1≤j≤m
K1=K2⟺l1j=l2j,1≤j≤m
K1 K1∨K2=(max(l11,l21);max(l12,l22);…; max(l1m,l2m)) K1∧K2=(min(l11,l21);min(l12,l22);…; min(l1m,l2m)) 式中:≤表示偏序关系,∨表示取最大值,∧表示取最小值。 下面给出多尺度决策系统中基于模糊相似关系的决策粗糙集最优尺度选择方法的相关定义。 下面给出多尺度决策系统中基于模糊相似关系的决策粗糙集下近似最优尺度选择算法。 算法1多尺度决策系统中基于模糊相似关系的决策粗糙集下近似最优尺度选择算法 输入:多尺度决策表S=(U,C∪{d}),C={c1,c2,…,cm},Ij(1≤j≤m),Di⊆U(1≤i≤m),0<α≤1,K0=(l1=1,l2=1,…,lm=1); 输出:S关于Di的下近似最优尺度Op; 1: 设Op=L={(l1,l2,…,lm)|1≤lj≤Ij,1≤j≤m}; 4: 得到S关于Di的下近似最优尺度Op。 同理可得多尺度决策系统中基于模糊相似关系的决策粗糙集上近似最优尺度选择算法。 在对最优尺度进行选定后,考虑多尺度决策系统中基于模糊相似关系的决策粗糙集的最优尺度约简问题。下面给出相关定义。 定义9设多尺度决策表S=(U,C∪{d}),U/d={D1,D2,…,Dm}构成对论域U的精确划分,L是S的尺度集合,K=(l1,l2,…,lm)∈L;K⊆=(/;…;/;li;/;…;/;lj;/;…;/)是K的子尺度;如果K⊆是K的子尺度且K⊆≠K,则称K⊆是K的一个真子尺度。其中,“/”代表相对应的条件属性及由其所导出的模糊相似关系被删除。 定义10设多尺度决策表S=(U,C∪{d}),K=(l1,l2,…,lm)∈L,L为S的尺度集合,K⊆⊆K,Di⊆U(1≤i≤m),0≤β<α≤1。 考虑到按照上述方法进行最优尺度选择及约简的时间、空间耗费过大,下面给出获得一个最优尺度约简的简便算法。 算法2多尺度决策系统中基于模糊相似关系的决策粗糙集下近似最优尺度约简算法 输入:多尺度决策表S=(U,C∪{d}),C={c1,c2,…,cm},Ij(1≤j≤m),Di⊆U(1≤i≤m),0<α≤1,K0=(l1=1,l2=1,…,lm=1); 输出:S关于Di的下近似最优尺度约简Kr; 1: 设R(C)=C,Kr=(l1=1,l2=1,…,lm=1)=K0; 6: 得到S关于Di的下近似最优尺度约简Kr。 同理可得多尺度决策系统中基于模糊相似关系的决策粗糙集上近似最优尺度约简算法。 例1给出一多尺度决策表如表1所示。 表1 一个多尺度决策表 U={x1,x2,x3,x4,x5,x6}={{x1,x2,x3,x5,x6},{x4}},R(C)=C={c1,c2,c3},D1={x1,x2,x5},D2={x3,x4,x6},Kr=(l1=1,l2=1,l3=1)=K0; 得到多尺度决策表关于D1的下近似最优尺度约简Kr=(/,/,1)。 得到多尺度决策表关于D2的下近似最优尺度约简Kr=(3,1,/)。 对本文所提出的多尺度决策系统中基于模糊相似关系的决策粗糙集模型和其相应的最优尺度选择及约简算法,本节将给出数据实验分析以证明其可行性与有效性。其中,进行实验的硬件环境配置为主频1.80 GHz的i7-10510U CPU,8 GB DDR4内存,算法运行的软件环境为MATLAB R2016a。实验采用UCI数据库中的5组标准数据集:Wine、Wpdc、Glass、Sonar、Mess来进行仿真实验。5组数据集均为包含一定噪声数据的实际应用数据集。 表2 实验数据集 实验将本文算法和文献[11]中对比算法所得到的特征子集结果在支持向量机分类器下进行分类性能评估,其结果通过分类精度的形式来表示,具体结果见表3。显然,两类特征选择算法所得分类精度均高于原始数据集的分类精度。本文特征选择算法分类精度得到了一定程度上的提高,约简后条件属性个数明显减少,这说明原始数据集中存在一定的冗余属性,这些冗余属性在一定程度上降低了数据的分类精度。通过本文的模型及算法,可以获得较好的特征选择结果,提高数据集分类能力。由此证明,本文所提出的模型及算法是有效的。 表3 实验结果 本文针对多尺度决策系统中每个属性可能具有不同尺度层次的特性,结合基于模糊相似关系的决策粗糙集,建立了多尺度决策系统中基于模糊相似关系的决策粗糙集模型,提出了下、上近似最优尺度选择及约简的判定定理,给出了相应的最优尺度选择及约简方法。考虑到算法时间、空间复杂性问题,讨论了获得一个最优尺度约简的简便算法。最后利用5组UCI标准数据集在MATLAB R2016a环境下进行仿真实验,验证了本文所提模型及算法的有效性。在后续工作中,将进一步探索所提出的多尺度决策系统中基于模糊相似关系的决策粗糙集在审计风险判断中的应用。





3.2 最优尺度约简









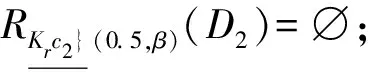

4 实验分析




5 结束语
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
聊城大学学报(自然科学版)(2022年5期)2022-10-29
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
小型微型计算机系统(2019年10期)2019-11-11
小型微型计算机系统(2019年9期)2019-09-09
计算机与数字工程(2019年8期)2019-09-03
计算机与生活(2019年3期)2019-04-18
计算机与生活(2019年3期)2019-04-18
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
太空探索(2016年5期)2016-07-12
