
基于轨迹数据的道路客运班车停留站点位置提取方法*
2021-09-17 07:25高中灵
交通信息与安全 2021年4期
李 军 解 超 王 林▲ 高中灵
(1.中国交通通信信息中心 北京100011;2.北京交通大学交通运输学院 北京100044)
0 引 言
道路客运班车在运行中的停留场所主要包括客运站、停靠站、配客点、加油站、服务区、交通拥堵点、信号控制交叉口等。除此之外,还包括道路客运非规定的旅客乘降场所,如市区内的常规公交站点、旅游景点、宾馆等。笔者将除交通拥堵点、信号控制交叉口之外的道路客运班车停留场所称班车停留站点。识别并有效提取班车停留站点位置,可为道路客运的客运站站址选择、定制出行乘降站点设置、出行信息服务等提供依据和支持。目前,获取班车停留站点位置主要利用大量的人工调绘[1]或专门的测量设备采集[2-3]的传统方法。在当前城市化快速发展进程中,班车停留站点位置变化快,尤其是客运服务经营者可以灵活设置旅客乘降站点后,班车停留站点将随旅客预约出行需求动态调整,其位置变动更为频繁,而依靠传统方法获取班车停留站点成本高、周期长,远远无法满足实际需求。
当前,出租车、公交车、道路客运班车等营运车辆通过车载GNSS(global navigation satellite system)设备采样得到车辆的移动轨迹数据。轨迹数据是交通状态、路网结构以及司乘行为的数据映射,蕴含了较为丰富的信息[4-5]。基于出租车轨迹数据挖掘的交通领域应用已较为广泛,主要包括交通状态分析[6]、出租车运营管理和支持[7]、出行规律与特性分析[8]等。其中,出租车运营管理和支持是应用最为广泛和深入的1个方面,如从出租车轨迹数据中提取乘客上下客地点时空分布[9]、乘客出行热点区域[10]等信息,作为出租车停靠站选址[11]、打车需求预测[12]的依据,从而为出租车的寻客策略和调度提供指导。
相对而言,道路客运班车轨迹数据的挖掘研究相对较少,但也逐步开始应用。除在交通状态分析[13]和班车安全监管[14]等领域应用外,一些学者还研究了班车轨迹数据的深层次挖掘应用,包括提取停车场位置[15]、计算车辆尾气排放量[16]等。由于班车在停留场所处的轨迹数据特征与出租车因乘客乘降生成的轨迹数据特征类似[17-18],因此,可以借鉴出租车轨迹数据挖掘的既有研究,将道路客运班车轨迹数据作为提取班车停留站点位置的数据源。
通过分析道路客运班车停留轨迹数据的典型特征,在轨迹数据预处理基础上,提出基于改进DBSCAN算法的道路客运班车停留站点提取流程和方法,基于京津冀区域的道路客运班车轨迹数据进行实证分析,对提出方法的可行性、效率和准确度进行验证,为道路客运班车停留站点位置的高效、精准、低成本的提取提供方法和技术支撑。
1 班车停留轨迹数据特征及预处理
1.1 轨迹数据特征
班车在道路上以相对稳定的速度正常行驶时,轨迹点一般沿道路呈均匀、线性分布,且比较连续、平滑。如果出现停留的情形,车辆会有一定时间的停驶或小范围不规则运动,轨迹点在该区域的数量通常较多,且往往呈聚集分布,见图1中区域A~D,区域A为在出发城市客流聚集点设置的供班车配客的配客点,区域D为出发城市的客运站。
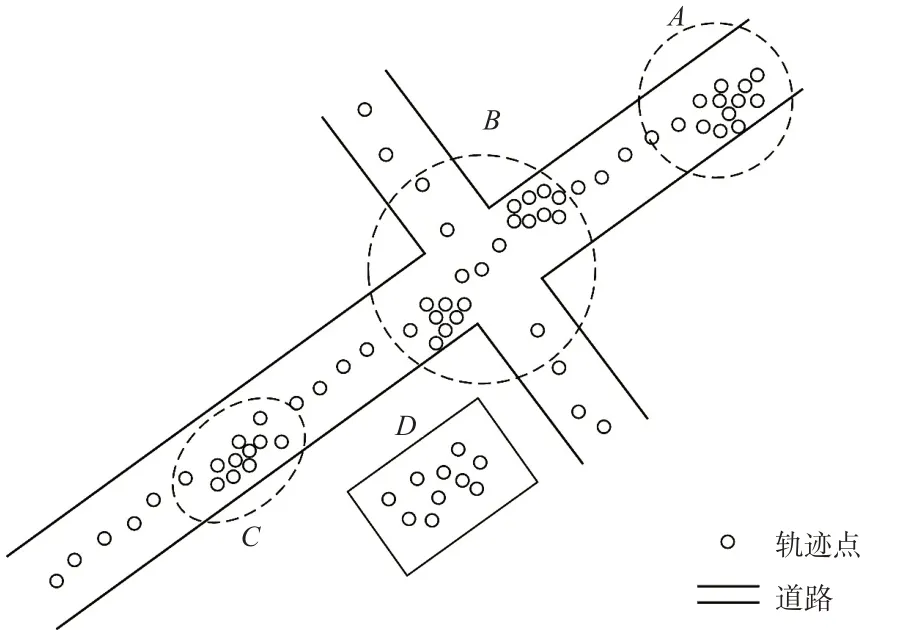
图1 班车轨迹点的空间分布Fig.1 Spatial distribution of regular bus trajectories
虽然如此,在交通拥堵点(区域C)和信号控制交叉口(区域B)的轨迹点分布与其他停留场所仍有所差异。交通拥堵点的轨迹点分布通常呈现带状形态,信号控制交叉口的轨迹点距离道路交叉口较近且呈对称分布,而且2处的车辆停留时间往往没有在班车停留站点停留的时间长[1]。
通过对比,可以总结出非交通拥堵点和信号控制交叉口的班车停留站点的轨迹数据所具备的典型特征:①轨迹点分布密度大,形成明显的点簇;②大部分轨迹点的速度属性为零;③停留时间较长;④距离道路中心线有一定的距离;⑤与信号控制交叉口有1个相对固定的距离。
1.2 轨迹数据预处理
由于车载GNSS设备的多样性、班车行驶环境的复杂性等因素的影响,班车轨迹数据易出现诸如位置偏移、漂移、属性值异常等问题,甚至会出行错误数据或冗余数据,影响班车停留站点的提取,因此,需要对班车轨迹数据进行预处理。
1.2.1 基于两级缓冲区的偏移数据预处理
过滤远离道路偏移数据较为有效的方法是在道路中线的基础上构建缓冲区,之后将缓冲区以外的数据删除。为提高计算效率,引入大小两级缓冲区进行异常轨迹点过滤的方法,即首先通过大缓冲区高速粗略筛选,剔除远离目标道路的轨迹数据,之后通过小缓冲区精细筛选,剔除与道路距离较近但不在道路上的轨迹数据[19]。
根据误差理论,假设道路网的定位误差为σ,车辆定位误差最大为τ,道路单向路宽为w,车宽为d,将班车轨迹点距离道路网的最大距离设置为缓冲区的半径ρ,见图2。计算见式(1)。
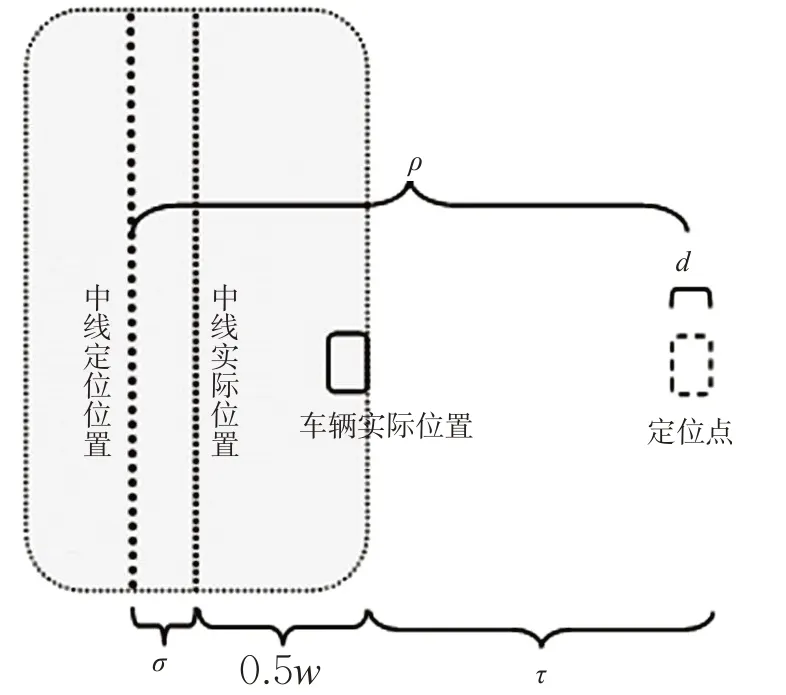
图2 车辆定位误差Fig.2 Position error of vehicles

通常道路网的定位精度取为σ=5 m,车辆定位误差τ=5 m,高速公路和城市快速路的大部分单向路宽w为10~16 m,大型车辆车宽d为2.55 m,则缓冲区半径ρ取值为13~16 m。
1.2.2 漂移数据的修正和预处理
在班车行驶过程中,当卫星信号遇建筑物产生折射、因树木等半透明物体被严重削弱或受大型电力设备影响等类似强因素干扰时,轨迹数据会发生比较明显的波动,即出现数据漂移,见图3。
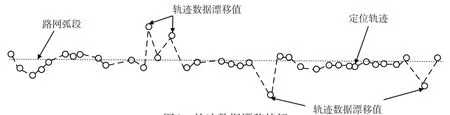
图3 轨迹数据漂移特征Fig.3 Drift characteristic of trajectory data
由图3可知,车辆轨迹数据漂移值的主要特征是速度或者经纬度信息出现异常。在数据预处理时,笔者采用道格拉斯-普克(Douglas-Peucker,DP)算法进行漂移值的预处理。提取3个位置相邻的轨迹点,分别为点A、点B、点C,三角形ABC顶点B至AC边的垂直距离为h,见图4。首先,根据三角形面积公式,计算三角形ABC的面积。

图4 漂移数据处理方法Fig.4 Processing method of drift data

式中:lmax为允许偏移的最大值,一般由地图精度、车载GNSS设备精度与道路宽度之和计算得出。比较h与lmax的大小,如果h<lmax,则直线AC段作为曲线AC的近似;如果h>lmax,则将曲线AC近似为直线AB和BC这2段。
2 基于改进DBSCAN算法的提取方法
根据班车停留轨迹数据的特征分析可知,班车停留轨迹点通常聚集成1个高密度的点簇。因此,识别班车停留站点位置的1个关键步骤是检测出轨迹数据中的高密度点簇,最常用的方法是使用数据挖掘中的空间聚类技术。选择DBSCAN算法对班车停留场所的轨迹点进行识别,并结合轨迹点簇的空间尺寸限制条件对DBSCAN算法进行改进。
2.1 DBSCAN算法
2.1.1 相关定义
DBSCAN是基于密度聚类算法中的1种比较典型且简单有效的算法。该算法将簇定义为密度相连的点的最大集合,能够将具有足够高密度的区域划分为类,并可在有“噪声”的空间数据库中发现任意形状的类。对于1个具有n个点的集合D,DBSCAN算法涉及的相关定义如下。
定义1。点的Eps邻域。空间中任意1个点p的Eps邻域是指以p为圆心,以Eps为半径的区域内包含的点的集合,即NEps(p)。数学公式表达为NEps(p)={q∈D|dist(p,q)≤Eps}。
定义2。核心对象。如果1个点的Eps邻域内至少包含Min Pts个点,则将其称为核心点,否则称为边界点或噪声点。
定义3。直接密度可达。如果点p在点q的Eps邻域内且q是核心点,称从q到p是直接密度可达的。
定义4。密度可达。如果存在1个点链p1,p2,…,pn,其 中p1=q,pn=p,对 于pi∈D(1≤i≤n),pi+1是从pi关于Eps和Min Pts直接密度可达的,则点p是从点q关于Eps和Min Pts密度可达的。
定义5。密度相连。如果点集D中存在1个点o,使得从点o到点p和q均关于Eps和Min Pts为密度可达的,那么点p和q则关于Eps和Min Pts是密度相连的。
定义6。簇。如果存在点集D,则簇C是D的1个满足以下条件的非空集合:①∀p,q,如果p∈C,且从p到q是密度可达的,则q∈C;②∀p,q∈C,则p和q是密度相连的。
定义7。噪声点。点集D中不属于任何簇的点为噪声点。
2.1.2 计算步骤
DBSCAN算法主要通过调整Eps和Min Pts这2个参数进行聚类中心的提取。算法的主要步骤如下。
步骤1。搜索数据集D中未被处理的对象。如果q尚未被处理,则查询q的Eps邻域NEps(q),如果包含的对象数不小于Min Pts,则建立新簇C,将NEps(q)中的全部点添加到C中。
步骤2。依次搜索C中未被处理的对象p,查询p的Eps邻域NEps(p),如果NEps(p)包含至少Min Pts个对象,则将NEps(p)中未被划分到任何簇的对象添加到C中。
步骤3。重复执行步骤2,继续搜索C中未被处理的对象,直到C中所有对象均被处理完成。
步骤4。重复执行步骤1~3,直到所有对象均被划分到某个簇或被标记为噪声。
2.2 改进的DBSCAN算法
由DBSCAN算法的计算流程可知,该算法的每1次计算均包含了1次邻域查询,而邻域查询等效于对整个数据集的1次遍历,当处理的数据量特别大时,邻域查询需要耗费较长时间。因此,提高DBSCAN算法效率的关键是减少邻域查询的范围。
笔者所提出研究问题的应用场景为利用DBSCAN算法提取班车停留场所,即班车停留站点。根据班车停留轨迹数据的特征分析,班车停留站点包括客运站、停靠站、配客点、加油站、服务区以及非规定的站外旅客乘降场所,聚类后所得的任意1个点簇事实上代表1个地理实体。在实际中地理实体的空间尺寸是有限的,因此,其所对应停留场所的点簇也具有有限的空间尺寸。因此,笔者以既有研究为基础[15],针对班车停留站点提取应用的特殊性,设定1个距离阈值限制邻域搜索空间,对DBSCAN算法做如下改进。
将点簇的空间尺寸进行限制,设置点簇中的任意2点间的距离不大于dmax。在执行DBSCAN算法前,首先,计算包含所有对象的最小外包矩形,并在该地理范围上构建空间格网,其中格网单元的边长为dmax;然后,确立每个对象与格网单元的对应关系,建立格网索引。见图5,标注圆圈的格网为当前格网,灰色格网为邻域搜索格。根据格网的最小点密度阈值ρmin,筛选出待处理的格网集合{Gst|Denst≥ρmin},将位于待处理格网集合中的对象组成搜索数据集合D。

图5 空间格网索引Fig.5 Spatial grid index
2.3 提取流程
依据预处理后的班车轨迹数据筛选停留轨迹点,通过改进DBSCAN算法并结合班车停留轨迹特征提取共性位置,进而生成班车停留站点位置。具体流程如下。
2.3.1 坐标系的转换
原始班车轨迹数据的坐标基于WGS-84坐标系,为便于后续步骤中的距离计算,将班车轨迹数据由地理坐标系转换至UTM投影坐标系。
2.3.2 班车停留轨迹点的筛选
在原始轨迹数据中筛选出速度零值点,为了剔除一些偶发因素(车载GNSS设备误差)导致的速度零值点,通过距离、方向等指标进行筛选。
对于班车的2个连续轨迹点Oi和Oi+1,如果VOi=VOi+1=0,dis(Oi,Oi+1)≤ds,并且angledif(Oi,Oi+1)≤angs,则将Oi判断为班车停留轨迹点。对于信号控制交叉口点Olc,如果dis(Oi,Olc)≤dlc,则将Oi判断为在交叉口的班车停留轨迹点,在后续的计算中将其剔除。
2.3.3 班车停留轨迹点聚类及中心提取

2.3.4 班车停留站点位置提取

3 实证分析
3.1 数据来源
班车的轨迹数据通过车载GNSS设备采样得到。原始的班车轨迹数据集本质上均为班车轨迹点集,由多行采样记录构成,每条记录代表1个轨迹点,包括车牌号码、时间戳、经纬度坐标、速度、方向等车辆基本行驶数据,数据示例见表1。

表1 班车轨迹数据示例Tab.1 Samples of regular bus trajectories
以京津冀地区作为研究区域,实证数据来源于2018年5月1日—31日从北京始发至河北、天津的136条客运班线的班车轨迹数据,共计258万个轨迹点。根据全国道路运输车辆动态信息公共服务平台的统计,京津冀区域平均每小时在线班车数量为4 300辆,1 h可产生约40万条班车轨迹记录。京津冀区域在线班车1 h的轨迹数据空间分布见图6。
图6可以直观地反映车辆轨迹在该区域内的分布情况,大部分的车辆轨迹集中于市区内,且越靠近城区轨迹点越密集。从北京市区域内的车辆轨迹来看,由于北京市的路网呈环形放射状,进出北京主要放射道路有较多的轨迹点位分布,这些轨迹随道路的走向呈条形分布。车辆轨迹在郊区县的分布较为分散,与市区内的车辆轨迹分布相比间隔较大。

图6 京津冀区域在线班车1 h的轨迹数据分布Fig.6 Distribution of one-hour online regular bus trajectories in the Beijing-Tianjin-Hebei region
3.2 班车停留站点提取结果
在对轨迹数据预处理的基础上,基于改进DBSCAN算法生成班车停留站点。考虑到营运车辆上安装的车载GNSS设备不可避免地会存在定位误差,结合车辆行驶特点,将距离参数ds设置为15 m,角度angs设置为65°。综合考虑生成班车停留站点的应用场景并结合统计经验,将Eps和Min Pts分别设定为20 m和5。在构建空间网格索引时,dmax和ρmin分别设定为100 m和10。
在停留轨迹点的聚类中心坐标计算完成后,dc设置为50 m,Smin设定为2,dm设定为3 m,剔除因交通拥堵因素产生的簇心,融合距离较近的聚类中心并筛选出可能为班车停留站点的簇心,利用缓冲区法剔除信号控制交叉口因素产生的簇心。最终从轨迹数据提取出了282个班车停留站点。
图7为班车停留站点的提取过程:图7(a)表明了站点附近的轨迹点,图7(b)表明了由改进DBSCAN算法生成的5个聚类中心点,图7(c)表明了由停留点聚类中心生成班车停留站点。
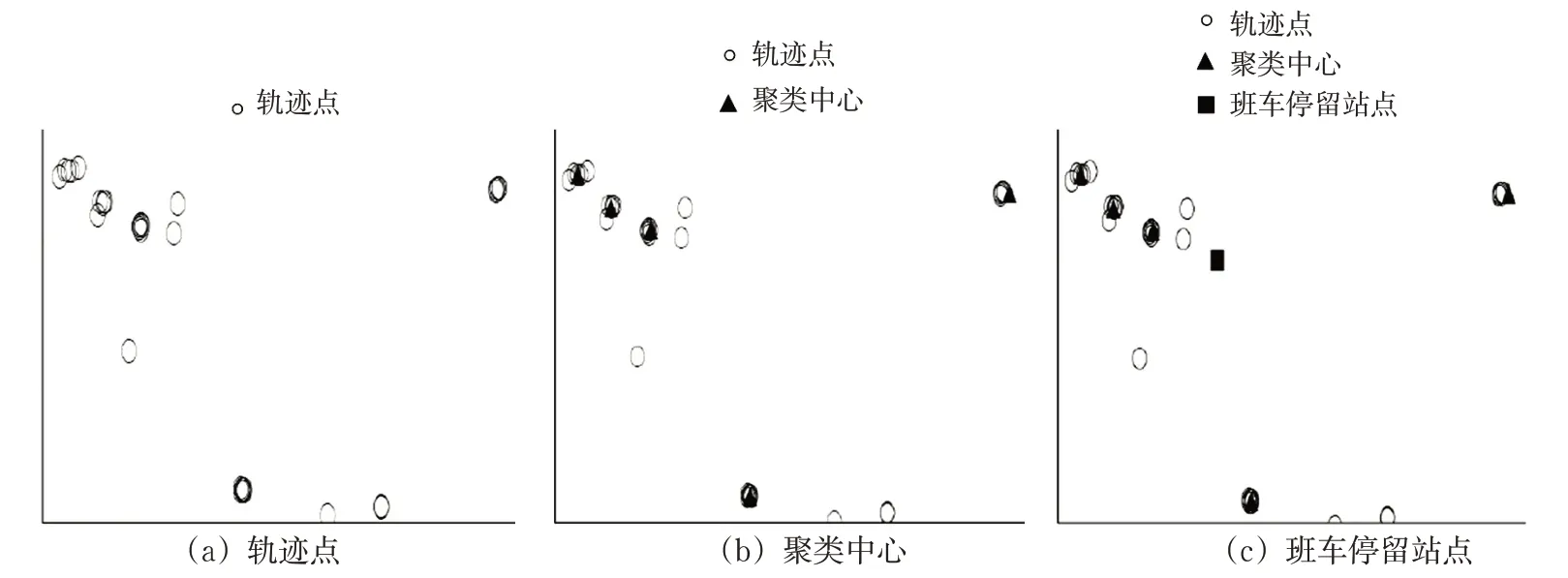
图7 班车停留站点提取过程Fig.7 Extraction process of regular bus-parking stops
3.3 方法效率分析
为验证改进DBSCAN算法提取班车停留站点的效率,从研究数据中选取了包含不同数量轨迹数据的子集,分别使用传统DBSCAN算法和改进DBSCAN算法对各子集进行聚类处理,记录并统计2类算法的执行时间以及生成班车停留站点的数量,见图8。由图8可见:改进DBSCAN算法平均执行时间减少了59.72%,提高了算法执行效率,而且所生成的班车停留站点数量与传统算法基本一致。因此,该方法可以在实际工作中用于班车停留站点的提取。
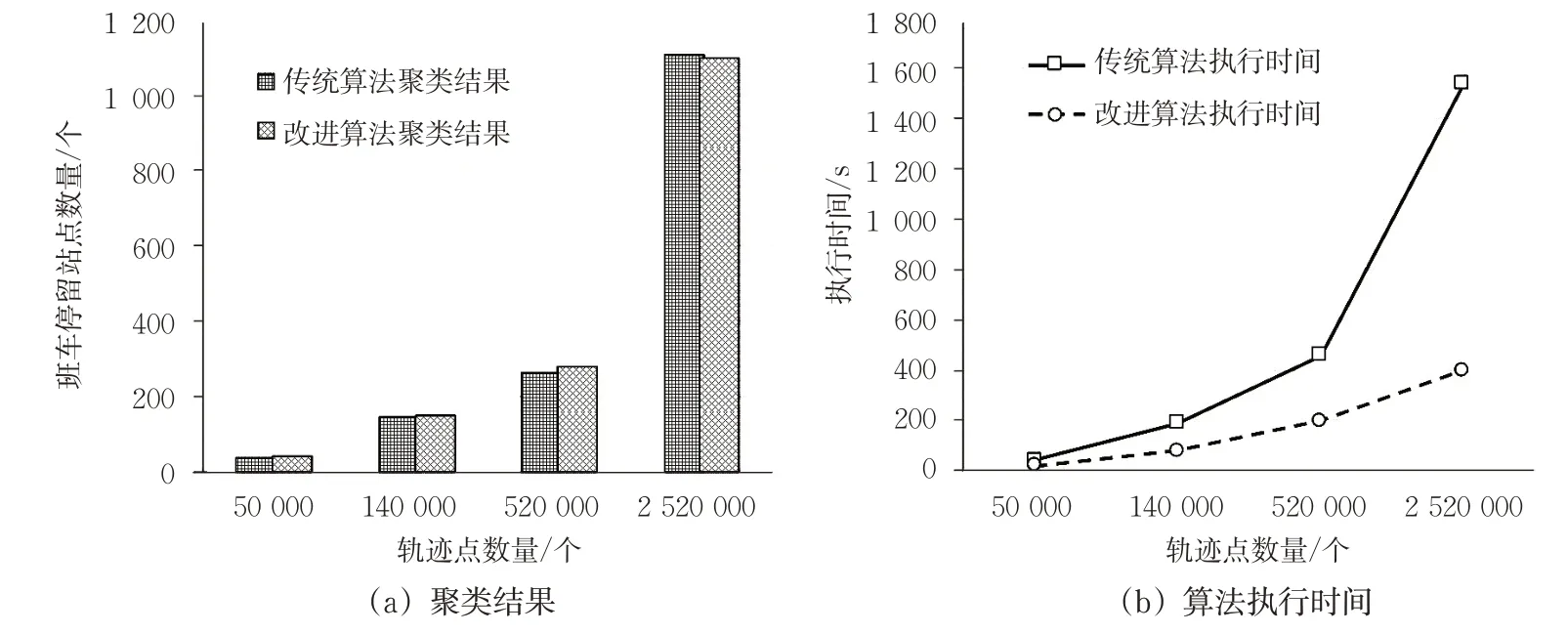
图8 改进算法的效率分析Fig.8 Efficiency analysis of the improved algorithm
3.4 准确度验证与典型实例分析
为验证所提取的班车停留站点位置的准确度,将生成的282个班车停留站点叠加到卫星影像图上,验证其与卫星影像图的匹配程度。经过比较,有256个站点为真实的班车停留站点,26个站点是交通拥堵点、信号控制交叉口等,班车停留站点提取的正确率为90.78%。虽然算法中对交通拥堵点和信号控制交叉口这2类班车停留场所进行了剔除,但由于二者与其他班车停留站点轨迹数据的相似性较高,仍存在将其误提取为班车停留站点的情况。
根据对提取的282个班车停留站点的统计分析,客运站和停靠站2类停留站点数量最多,占比为59%,其次为客运枢纽、旅游景点、常规公交站等站外乘降场所。图9为所提取的4类典型班车停留站点与卫星影像图的匹配效果。图9(a)是1个客运站。图9(b)是1个旅游景点的停车场,图9(c)是1个城镇的道路交叉口,经调研发现,2处场所存在经常性旅客乘降的情形,且具备作为乘降站点的道路条件。图9(d)是1处高速公路的常发交通拥堵点,由于交通拥堵点与班车停留站点的轨迹特征非常相似,导致此处被误提取为班车停留站点。

图9 班车停留站点与卫星影像图的匹配效果Fig.9 Superimposed effect of regular bus parking stops in satellite images
4 结束语
分析了道路客运班车停留轨迹数据的典型特征,在轨迹数据预处理基础上,建立了基于改进DBSCAN算法的班车停留站点提取方法,提出了班车停留站点提取流程,基于京津冀区域的136条道路客运班线的班车轨迹数据进行了实证分析。实证结果表明:①基于轨迹数据共提取了282个班车停留站点,其空间分布与车辆轨迹数据分布以及实际状况较为吻合;②改进DBSCAN算法提高了算法执行效率,平均执行时间减少了59.72%,且所生成的班车停留站点数量与传统算法基本一致;③将生成的282个班车停留站点叠加到卫星影像图上,经过比较,有256个站点为真实的班车停留站点,26个站点是交通拥堵点、信号控制交叉口等,班车停留站点提取的正确率为90.78%。
DBSCAN算法需要提前确定Eps和Min Pts这2个参数的值,而参数的确定将对聚类效果有一定程度的影响,下一步将根据不同停留轨迹数据的特征,研究相应的参数选取优化方法,以更准确地剔除交通拥堵点和信号控制交叉口。此外,随着定制客运的发展,将旅客预约出行需求数据与班车轨迹数据相结合,探索定制客运乘降站点的设置方法,也是1个值得研究的方向。
猜你喜欢
中国科学数据(中英文网络版)(2020年4期)2021-01-20
空间科学学报(2020年6期)2020-07-21
吉林大学学报(理学版)(2020年3期)2020-05-29
小学科学(学生版)(2020年4期)2020-05-21
环球时报(2019-08-09)2019-08-09
时代邮刊(2019年20期)2019-07-30
自动化学报(2018年7期)2018-08-20
周口师范学院学报(2016年5期)2016-10-17
小说月刊(2015年8期)2015-04-19
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
