
一种新型的自适应多核学习算法
2021-09-22 04:10聂逯松常方圆常学智金有为刘国晟付加胜韩霄松
吉林大学学报(理学版) 2021年5期
聂逯松, 常方圆, 常学智, 刘 畅, 金有为, 刘国晟, 付加胜, 韩霄松
(1. 吉林大学 共青团吉林大学委员会, 长春 130012; 2 吉林大学 护理学院, 长春 130012;3. 吉林大学 生物与农业工程学院, 长春 130022; 4. 长春中医药大学 医药信息学院, 长春 130117;5. 吉林大学 符号计算与知识工程教育部重点实验室 长春 130012; 6. 吉林大学 计算机科学与技术学院, 长春 130012; 7. 吉林大学 软件学院, 长春 130012;8. 中国石油集团工程技术研究院有限公司, 北京 102206)
核学习是一种解决非线性分类和回归问题的方法, 但传统的核分类器都是基于单个核. 针对基于传统特征的分类问题, 构建的特征通常从不同角度描述数据, 将这些特征完全映射到同一空间进行分类效果不佳, 多核学习(multiple kernel learning, MKL)[1]可解决上述问题. MKL可将多个子核整合到一个统一的优化框架内以寻求最佳组合. 研究表明, 使用多核模型可提升学习模型的性能, 同时获得可解释的决策函数. 但多核算法的应用存在核函数组合方式多样且不易选取, 很难找到多核函数解决问题的最优解以及计算复杂度较高等缺陷. 目前, 多核学习方法主要分为合成核方法、 多尺度核方法和无限核方法三类. 而针对多核学习方法的优化则围绕优化组合系数和选取基核函数展开. 优化组合系数有两种方法, 即一阶段法和二阶段法. 一阶段法主要优化包括组合系数和分类器参数的目标函数, Bach等[2]考虑了支持向量机(SVM)的核矩阵圆锥形组合, 并证明这种组合系数的优化可简化为凸优化问题, 称为二次约束二次规划(QCQP); Lanckriet等[3]提出了一种基核矩阵的半正定性优化方法; Feng等[4]提出了利用判别核对准作为度量准则以计算核函数的组合系数方法; Niazmardi等[5]实验表明, 利用度量准则计算组合系数的方法分类精度较低. 而二阶段法则分别考虑组合系数与分类器参数, 即先优化组合系数后, 再集成以优化分类器参数, Gu等[6]采用该方法进行分类, 提出了一种非监督计算组合系数的MKL方法, 之后又利用非负矩阵分解和核非负矩阵分解方法获得组合系数的最优解[7]; Yeh等[8]将顺序最小化技术(SMO)与梯度投影法相结合, 提出了一种二阶段多核学习算法, 提高了系统的整体性能. 二阶段法随着核数量的增加, 精度和速度都比一阶段法好. 在选取基核函数方面, Kavazoglu等[9]研究表明, 高斯核函数的鲁棒性强于多项式核函数; Bazi等[10]利用遗传算法进行支持向量机核函数参数的选取; Hu等[11]利用高斯核函数和Sigmoid核函数各自的特点, 设计了多核学习算法分别发挥其优势; 李阳等[12]将多核方法与矩阵化最小二乘支持向量机相结合应用于肺结节的识别, 取得了较好的结果.
本文提出一种自适应的多核学习算法(self-adaptive multiple kernel learning, SaMKL), 该算法能根据数据分布有效地将特征空间进行划分, 并解决核函数参数的优化问题, 避免了传统人为设计核函数组合的主观性, 从而提高了寻找最优核参数的速度.
1 自适应多核学习算法
为进一步提升多核学习的性能, 本文提出一种自适应的多核学习算法. 首先, 进行基于聚类的相似维发现, 根据不同数据集的数据分布对特征进行聚类, 在每个聚簇内进行基于相似维的单核学习, 即利用SVM对每个聚簇进行学习; 其次, 为进一步提升学习效果, 采用蚁群算法优化每个SVM的核参数, 从而得到最优的核函数组合; 最后, 利用算法集成层将生成的各最优核函数组合, 生成最优的学习结果. 算法流程如图1所示.
1.1 基于AP聚类的相似维发现
SaMKL的自适应性主要体现在可根据每个特征的不同分布, 利用不同核函数映射到不同的高维空间, 本文利用聚类算法发现分布相似的维度, 即相似维发现, 然后将每组相似维映射到不同空间. AP聚类算法(affinity propagation, AP)[13]是一种基于近邻传播的聚类算法, 其最大特征就是无需在运行算法前人为确定聚类的个数, 且聚类效果不依赖初值, 本文采用AP聚类进行相似维的发现.
AP聚类在数据点之间存在两类信息交换, 分别为吸引度r(i,k)和归属度a(i,k),r(i,k)表示数据点k适合作为数据点i聚类中心的程度,a(i,k)表示数据点i选择数据点k作为其聚类中心的程度,s(i,k)表示数据点i和k的相似度.初始情形下,a(i,k)=0,r(i,k)采用如下公式进行更新:
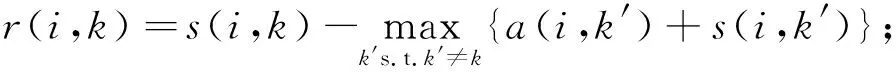
(1)
a(i,k)采用如下公式进行更新:
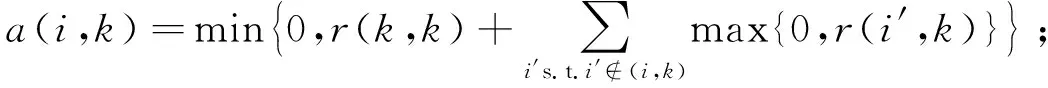
(2)
a(k,k)的更新公式为
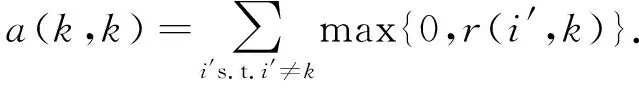
(3)
对于点i,a(i,k)+r(i,k)取最大值时的k值, 当k=i时, 确定点i为一个聚类中心, 否则确定数据点k是点i的聚类中心.同时, 为防止数据震荡, AP算法引入了衰减系数, 即每个信息值等于前一次迭代更新信息值的λ倍再加上此轮更新值的(1-λ)倍. 算法流程如图2所示.

图1 自适应多核算法流程Fig.1 Flow chart of self-adaptive multiple kernel algorithm
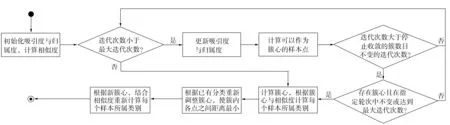
图2 AP聚类算法流程Fig.2 Flow chart of AP clustering algorithm
1.2 基于相似维的单核学习
本文采用SVM对相似维发现后的数据进行单核学习, SVM是常用的单核学习算法, 其基本模型是定义在特征空间上间隔最大的线性分类器. SVM的学习策略是间隔最大化, 可形式化为一个求解凸二次规划问题, 也等价于正则化的合页损失函数最小化问题, 其学习算法即为求解凸二次规划的最优化算法.
对于输入空间中的非线性分类问题, 可通过非线性变换将其转换为某维度特征空间中的线性分类问题, 在高维特征空间中构建线性SVM. 由于在线性SVM学习的对偶问题中, 目标函数和分类决策函数都只涉及实例与实例之间的内积, 所以不需要显式地指定非线性变换, 而是采用核函数替换其中的内积. 核函数表示通过一个非线性转换后两个实例间的内积, 设K(x,z)为一个核函数, 则存在一个从输入空间到特征空间的映射φ(x), 使得对任意输入空间中的x,z, 均有
K(x,z)=φ(x)·φ(z).
(4)
本文采用高斯核函数(也称为径向基核函数):
K(xi,xj)=e-γ‖xi-xj‖2,γ>0.
(5)
由于高斯核函数是局部性较强的核函数, 应用广泛, 无论对大样本还是小样本性能都较好, 因此本文选择高斯核函数进行实验.高斯核函数最重要的两个参数是惩罚因子C和核函数系数γ:
1) 惩罚因子C用于控制损失函数的惩罚系数, 类似于LR的正则化系数.C越大, 其惩罚松弛变量越强, 使松弛变量接近0, 即对误分类的惩罚增大, 趋向于对训练集全分对的情况, 会出现训练集测试时准确率很高, 但泛化能力较弱, 易导致过拟合; 若C值较小, 则对误分类的惩罚也较小, 容错能力和泛化能力增强, 但也可能欠拟合.
2) 核函数系数γ表示高斯函数幅宽, 代表泛化能力.γ越大, 高斯函数越细长, 对未知样本分类越差; 反之, 平滑效应过大, 会影响训练集的识别率, 导致学习失败.
1.3 基于蚁群优化算法的核优化
SaMKL的自适应性还体现在对每个聚簇的SVM利用蚁群优化(ant colony optimization, ACO)算法[14]进行自动参数寻优, 从而提高算法的准确率. 蚁群优化算法受蚂蚁觅食行为的启发, 核心是蚂蚁之间通过化学信息素进行通信. 蚂蚁在路径上释放信息素, 当蚂蚁遇到还未走过的路口时, 就随机挑选一条路走, 同时蚂蚁释放浓度与路径长度成反比的信息素. 当后来的蚂蚁再次碰到该路口时, 即选择信息素浓度较高的路径. 这样最优路径上信息素的浓度越来越大, 使蚂蚁群找到了巢穴与食物源之间的最短路径. ACO算法流程如图3所示. SVM的参数选取是参数的组合优化问题, 本文用ACO算法进行搜索, 最终得到每个SVM合适的参数组合.

图3 蚁群优化算法流程Fig.3 Flow chart of ant colony optimization algorithm
蚁群优化算法将目标函数作为评判优化结果的直接因素, 本文利用F1值判断分类算法的执行效果.F1值在精度(precision)P与召回率(recall)R之间进行了权衡, 计算方法如下:

(6)
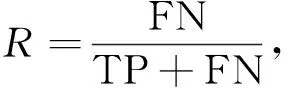
(7)
(8)
其中TP表示被判定为正样本的正样本, FP表示被判定为正样本的负样本, FN表示被判定为负样本的正样本.
综上, 可得:
算法1自适应多核学习算法.
步骤1) 输入数据集, 用AP聚类算法进行相似维发现, 将特征集合划分为M组;
步骤2) 利用划分好的相似维将数据集划分为M组;
步骤3) 针对每组数据进行SVM学习, 并利用蚁群算法的优化核函数;
① 蚁群算法参数初始化, 目标函数设置为F1值, 每只蚂蚁编码为M组位置向量(C,γ)×M;
② 根据每只蚂蚁分配的位置向量, 利用训练集对每组数据通过SVM进行学习;
③ 初始化ACO中的信息素;

先计算当前迭代次数条件下编号为i的蚂蚁的转移概率, 再计算当前迭代次数条件下所有蚂蚁的转移概率;
⑤ 更新蚁群位置, 直到当前迭代次数k下所有蚂蚁的位置向量都更新完毕:
⑥ 利用信息素挥发因子与激励因子更新当前迭代次数k下所有蚂蚁的信息素值;

⑨ 更新种群迭代次数,k=k+1;

步骤4) 对M组数据进行优化和SVM后, 针对二分类问题, 利用投票法集成每组数据的输出, 得到最终分类结果.
2 数值实验
2.1 数据获取及实验设计
UCI数据集是美国加州大学欧文分校收集的用于机器学习的数据库, 因其数据格式标准、 内容丰富, 所以在机器学习过程中被广泛应用于测试各类开发程序. 为选取适用于进行相似维发现及多核融合的数据集, 同时方便计算数据测试结果的F1值, 本文选择特征数较高且数据样本量适中的二分类数据集, 各数据集信息列于表1.

表1 数据集信息
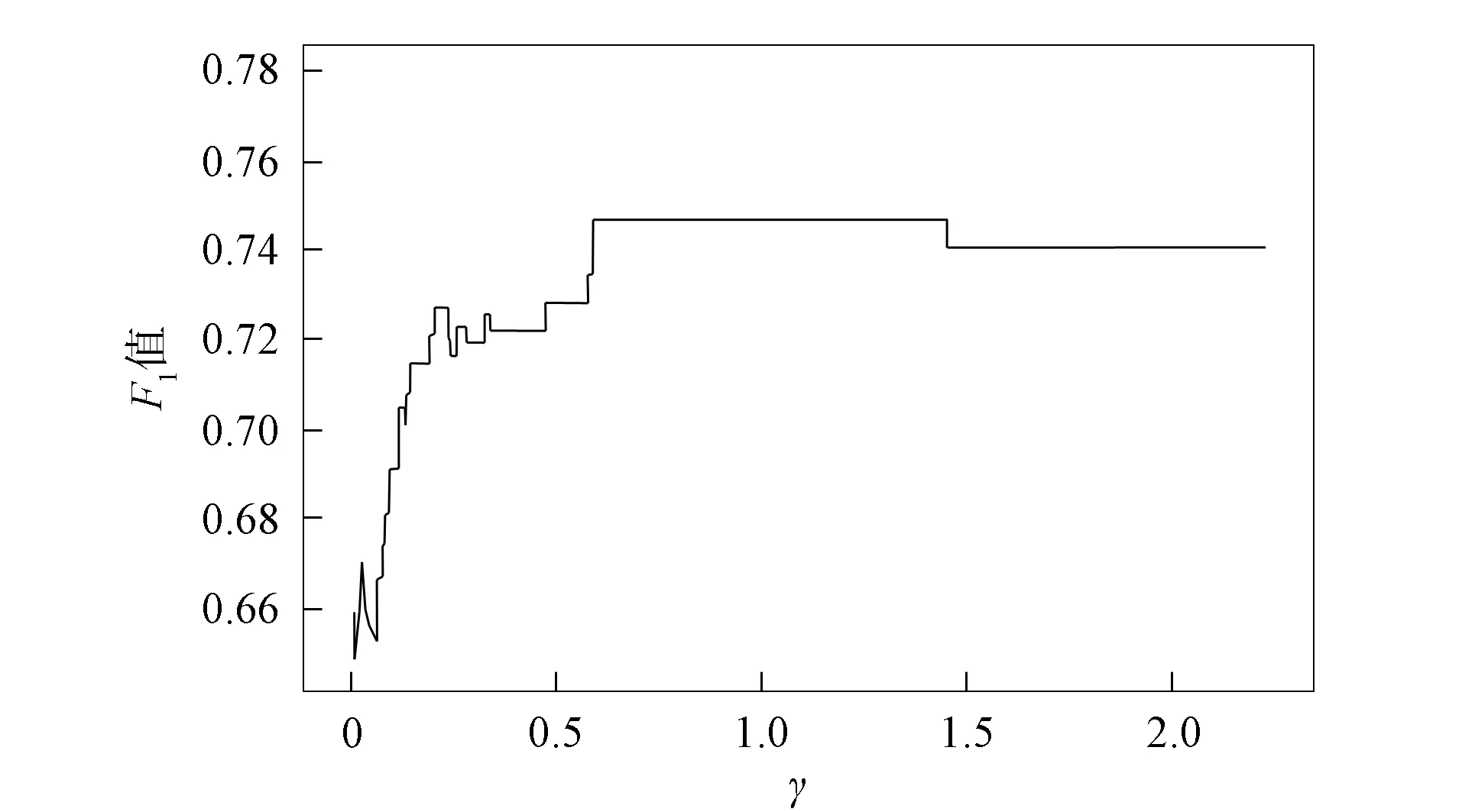
图4 当C=1时, 高斯核函数下F1值与γ值的关系曲线Fig.4 Relation curve between F1 value and γ value under Gaussian kernel function when C=1
本文按8∶2将数据集分为训练集和测试集两类. 为提高ACO的寻优效率, 在实验中对C和γ值范围进行特别优化.惩罚因子C表示SVM对分类错误的容忍程度, 为保证算法优化结果的有效性并提高优化效率, 将其上界设定为训练样本数量的1/5, 下界设定为1.
对于参数γ, 计算默认γ值公式为
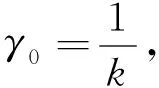
(9)
其中k为样本类别数量, 本文采用的测试集均为二分类问题, 因此k=2,γ0=0.5.为得到γ的合理取值范围, 以cylinder-bands作为测试集, 令γ在[0.01γ0,5γ0]内进行搜索, 步长为0.01γ0,C=1, 所得F1值如图4所示.由图4可见, 当γ=0.703时,F1取得峰值.为使蚁群移动幅度维持在一个能使优化结果取得较优解的范围内, 实验中将[0.01γ0,5γ0]设定为γ值的取值范围.
2.2 实验结果分析
为验证SaMKL的效果, 本文在上述标准测试集中分别运行SVM和SaMKL, 实验结果列于表2. 本文将ACO的各变量初始化为: 迭代次数gen=200, 种群大小m=100, 信息素挥发因子ρ=0.8, 激励因子Q=1. 实验结果均为10次重复实验后所得. 由表2可见, SaMKL相比于SVM在分类准确率和F1值方面均有明显提升, 证明了SaMKL的优势.
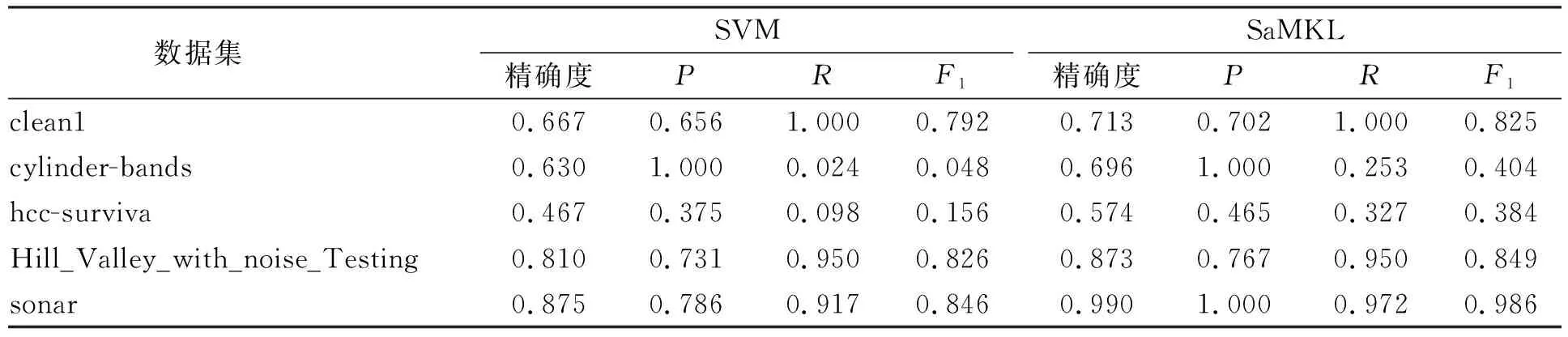
表2 SVM和SaMKL实验结果对比
3 应 用

图5 某学生的成长能力分布Fig.5 Distribution of a student’s growth ability
将本文算法应用于吉林大学团委“吉小鹅”APP中. 应用中需要体现学生在使用“吉小鹅”APP进行项目设计完成后的成长能力分布, 由于学生数量较大, 统计的相关成长因素较多, 本文算法可将多种成长因素自动归类, 并分别进行评价, 最终通过合成层进行总体评价. 根据本文算法划分的成长因素可被命名为成长能力、 科研能力、 领导能力、 协作能力和竞赛能力, 结果如图5所示.
综上所述, 针对样本基数较大、 维数较高、 特征复杂的数据集训练问题, 本文提出了一种自适应多核学习算法, 该算法能自适应地对特征进行划分, 再基于该划分进行多个不同的单核学习, 利用蚁群算法进行自适应地参数寻优, 并利用数据集分布自适应地确定每个单核学习机参数的取值范围, 通过与SVM实验结果进行比较, 本文算法能自适应地找到最优的核函数, 分类效果比传统的单核学习SVM更优, 鲁棒性与普适性更好.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
