
基于图卷积神经网络的专利语义模型构建研究*
2021-10-12 12:27余军合邓慧君施培妤胡国建
机械制造 2021年9期
□ 沙 鹤 □ 余军合 □ 邓慧君 □ 施培妤 □ 胡国建
宁波大学 机械工程与力学学院 浙江宁波 315211
1 研究背景
当前,专利数据量庞大,简单的关键词检索已经无法满足设计人员在短时间内匹配关联度较高的专利的需求。专利智能检索能够极大地缩短设计人员的查阅时间,提高工作效率。
随着大数据技术与信息科学处理技术的出现和发展,如何将数据处理技术与方法应用于专利语义网络,引起了学者的广泛关注,同时为专利智能检索提供了技术支持。
基于专利语义模型进行专利检索时,可以通过输入一个词、一句话或一段文字进行查询,而不必考虑文本中是否包含有关键词。构建高准确性的语义模型,是提高专利检索准确度的重要方式。语义模型的发展由基于词袋模型向基于向量模型跨越。杨宏章等[1]基于专利文本结构构建专利语义模型,提高了检索效率。Zhang Longhui等[2]提出一种基于领域内高平均值频率术语的专利语义模型,用于目标主题专利的查询。姜春涛[3]提出基于关键词和依存关系树的图模型,为专利智能分析提供语义支撑。王秀红等[4]针对领域专利知识库构建,提出由专利文本向量表示专利语义信息的方法。曹洋[5]基于文本排序算法提取文本中语义信息,构建拓扑图,提升了文本主题的语义准确性。刘斌等[6]采用神经网络提取专利和论文的特征,实现论文与专利之间的联系,并提出基于深度学习的专利语义模型。Wu Hengqin等[7]针对技术专利中领域专业技术难以识别的问题,提出应用深度学习的方法来自动识别目标专利。吴素雪[8]提出一种基于卷积神经网络的专利语义模型,提高了检索准确度。随着机器学习算法的发展,在向量模型下构建专利语义已成为研究的热点,不仅仅局限于关键词的检索是这一方法的重要应用特点。
深度学习在自然语言处理方面,Srivastava等[9]采用受限玻尔兹曼机对文档进行主题建模,Hill等[10]使用多层感知机卷积神经网络、循环神经网络等对文档进行建模。前者只考虑词语间的主题关系,不考虑文档内的语序问题,后者则主要以滑动窗口对文本建模。在文本分类中,郭利敏等[11]通过卷积神经网络对小批量文字生成批量文本,将古籍汉字的识别问题转换为卷积神经网络的分类问题。最近,图网络模型的新发展引起了研究人员的广泛关注,越来越多的图网络模型被人们所熟知[12]。Yao Liang等[13]采用图卷积神经网络(GCN)进行文本分类,提出基于文本的图卷积神经网络模型。Liu Xi’en等[14]对图卷积神经网络进行深一步研究,构建张量图卷积神经网络,用于整合各种图形的异构信息。
图网络可以依靠节点之间的信息传递来捕捉图中的依赖关系,图卷积神经网络依托于可以建立不规则数据结构的图网络,这给笔者基于图卷积神经网络构建专利语义模型提供了理论基础。
2 专利语义模型构建方法
构建基于图卷积神经网络的专利语义模型,主要思路是通过确定网络节点和节点间的连边关系,构建合适的网络模型,能够基于节点特性和整个网络结构性质,结合神经网络算法来提取专利语义信息。
在基于图卷积神经网络的专利分类模型部分,笔者通过构建专利文本中专利与摘要、摘要中字与字的连边关系进行图网络的构建。
为了探究字与字构建模型的语义和词与词构建模型的语义的差异性,基于词频-逆向文档频率(IF-IDF)算法对摘要进行主题词提取,通过摘要主题词与关键词间的节点关系对摘要中字与字构图方式进行了研究分析。
在基于余弦相似度的图卷积神经网络模型分析部分,笔者对两种不同构图方式构建的图卷积神经网络模型进行分类,并基于分类效果图分析模型的可靠性。结合相似专利与基准专利,在基于两种构图的图卷积神经网络模型下进行余弦相似度计算,通过相似度对比分析两个模型的效果。
笔者基于设计方法学中的三种设计人员常规检索专利方式,以功能、功能-原理、功能-原理-结构三种检索式为研究对象,将针对三种检索式的设计需求作为检索语句嵌入图网络,进行相似专利的匹配。基于返回用户检索的结果,采用专利检索评估方法来评估不同检索式的优劣。
基于图卷积神经网络的专利语义模型构建方法具体流程如图1所示。
3 图卷积神经网络构建方法
3.1 图卷积神经网络
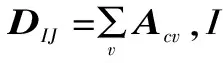
(1)
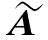
通过叠加多个图卷积神经网络层来合并高阶邻域信息:
(2)
式中:H(k)为第k层输入的特征矩阵;H(k+1)为第k+1层输入的特征矩阵;Wk为经过k层训练得出的权重参数。
两层图卷积神经网络可以允许在两个最大距离的节点间进行消息传递,因此,尽管图中没有直接构建的专利与摘要的边,但是两层图卷积神经网络允许在文档之间交换信息。笔者在初步试验邻接矩阵时发现两层图卷积神经网络的性能优于一层图卷积神经网络,但更多的层数并不能提高性能。
3.2 异构网络图
笔者在专利与摘要主题词的连边上应用词频-逆向文档频率权重。在构建摘要主题词与摘要主题词间的连边时,为了应用全局词共现信息,在专利库中所有摘要主题词上使用一个固定大小的滑动窗口来收集共现信息。通过应用点互信息算法来计算两个摘要主题词节点之间的权重。点互信息算法是一种常用的词关联度量方法,应用点互信息算法相比应用单词共现计数,可以获得更好的结果。
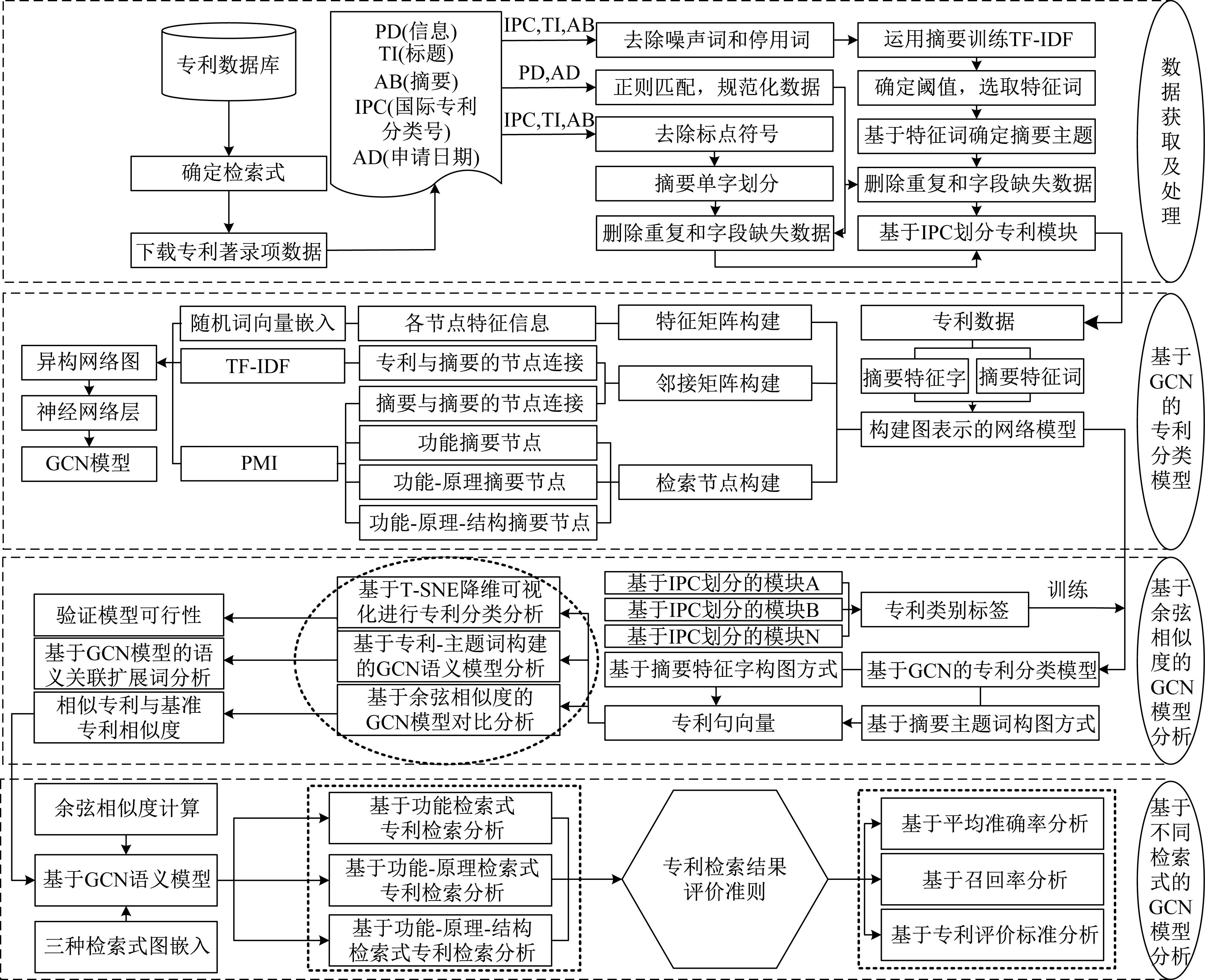
▲图1 基于图卷积神经网络的专利语义模型构建方法流程
邻接矩阵Acv为:
(3)
式中:S(e,j)为两个主题词间的点互信息值数据集;M(i,j)为专利与摘要主题词的词频-逆向文档频率权重数据集。
S(e,j)为:
(4)
p(e)=W(e)/W
(5)
p(j)=W(j)/W
(6)
p(e,j)=W(e,j)/W
(7)
式中:W为滑动窗口总数;W(e)为在一个专利库中包含邻接矩阵中行摘要主题词的滑动窗口数;W(j)为在一个专利库中包含邻接矩阵中列摘要主题词的滑动窗口数;W(e,j)为在一个专利库中同时包含行摘要主题词和列摘要主题词的滑动窗口数;p(e)为行摘要主题词在整个训练专利文本中出现的概率;p(j)为列摘要主题词在整个训练专利文本中出现的概率;p(e,j)为行和列摘要主题词在整个训练专利文本中同时出现的概率。
点互信息值为正,表示主题词与主题词间的相关性较大。点互信息为负,表示主题词与主题词间的相关性较小或不存在。所以,仅给点互信息值为正的两个摘要主题词节点连边。
逆向文档频率关系式为:
Q(tl)=log(N/b+0.01)
(8)
式中:Q(tl)为摘要主题词tl的逆向文档频率数据集;N为专利库中专利的总数;b为包含摘要主题词tl的专利数。
词频-逆向文档频率权重M为:
M=PQ(tl)
(9)
式中:P为邻接矩阵行中摘要主题词tl在邻接矩阵列所有专利中出现的次数。
笔者基于字与词的语义差异性,构建基于专利-单字符和专利-主题词两种异构图的图卷积神经网络模型,进行语义模型的研究。构图中,需要分别对数据进行字符级别的分词与主题词提取处理。单字符提取主要通过单字划分实现。主题词提取时,先对专利摘要进行数据预处理,再应用词频-逆向文档频率算法选出专利主题词。两种构图方式举例见表1。
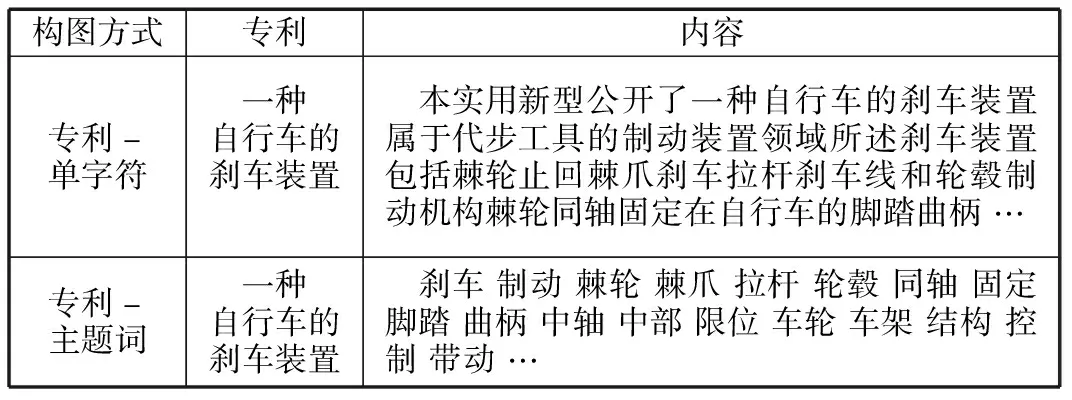
表1 构图方式举例
两种构图方式的图卷积神经网络结构如图2所示。图2中,数据集的全部文档可以表示为D= {d1,d2,d3,…,dn},n为数据集中专利文档总数。数据集中基于专利-主题词构建异构文本图时,全部主题词可以表示为W={w1,w2,w3,…,wm},m为数据集中专利摘要文本主题词的总数。数据集中基于专利-单字符构建异构文本图时,全部单字符可以表示为C={c1,c2,c3,…,cx},x为数据集中专利摘要文本字符的总数。

▲图2 两种构图方式图卷积神经网络结构
4 试验数据集
笔者基于incoPat专利数据库检索所需专利数据,采用自行车基本设计结构25个不同配件的关键词,分别搭配自行车主题用于检索专利数据,共计检索专利32 684条。由于外观设计型专利技术特征基于设计图来展示,与摘要关联较小,因此笔者选取实用新型和发明专利作为分析数据,筛选出专利共计27 406条。
试验数据中,自行车的国际专利分类号繁多,共计484种。将国际专利分类号作为训练标签类别分类特征不明显,因此笔者的试验基于模块化设计思想,结合国际专利分类号查询,将国际专利分类号映射至设计模块。自行车按模块设计可划分为车架系统设计模块、车轮系统设计模块、车座系统设计模块、导向系统设计模块、传动系统设计模块、制动系统设计模块。基于这六个模块,结合国际专利分类表,进行专利类别标签划分。专利类别标签划分见表2。

表2 专利类别标签划分
5 试验结果分析
5.1 分类效果
笔者基于Python编程软件和张量框架构建图卷积神经网络模型,在图卷积神经网络结构中,卷积层第一层和第二层的嵌入维度设置为200。随机选择训练集的20%作为验证集,为防止过拟合,设置抛出隐藏节点率为 0.5,学习率为0.01。设置200个训练周期,若连续10个周期的验证损失率没有降低,则停止训练。模型采用准确率、召回率、综合评价分数,进行性能评价。
将处理后的数据输入所构建的图卷积神经网络模型,为体现方法的适用性,选择专利-单字符构图方式和专利-主题词构图方式进行对比试验。采用专利-单字符构图方式,输入节点数为30 258。采用专利-主题词构图方式,输入节点数为66 032。试验结果表明,基于专利-单字符构图方式的图卷积神经网络模型,分类整体的平均准确率为0.810 3,基于专利-主题词构图方式的图卷积神经网络模型,分类整体的平均准确率为0.793 7。两种构图方式的分类效果对比见表3。
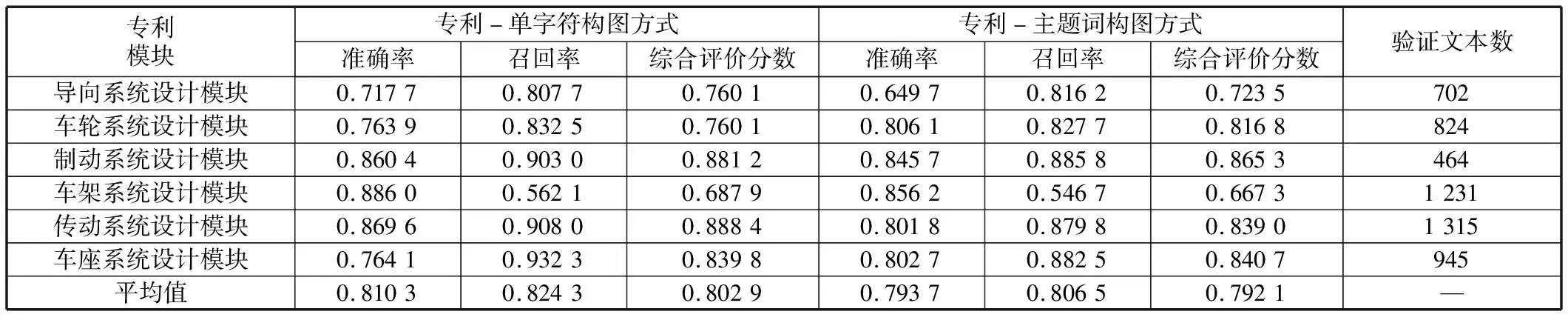
表3 两种构图方式分类效果对比
5.2 专利分类可视化
使用t分布随机邻居嵌入算法进行高维向量降维可视化,对学习到的文档嵌入可视化。两种构图方式的专利分类可视化如图3所示。图3中,+表示传动系统设计模块相关专利,▲表示导向系统设计模块相关专利,■表示车座系统设计模块相关专利,▼表示车架系统设计模块相关专利,●表示车轮系统设计模块相关专利,★表示制动系统设计模块相关专利。
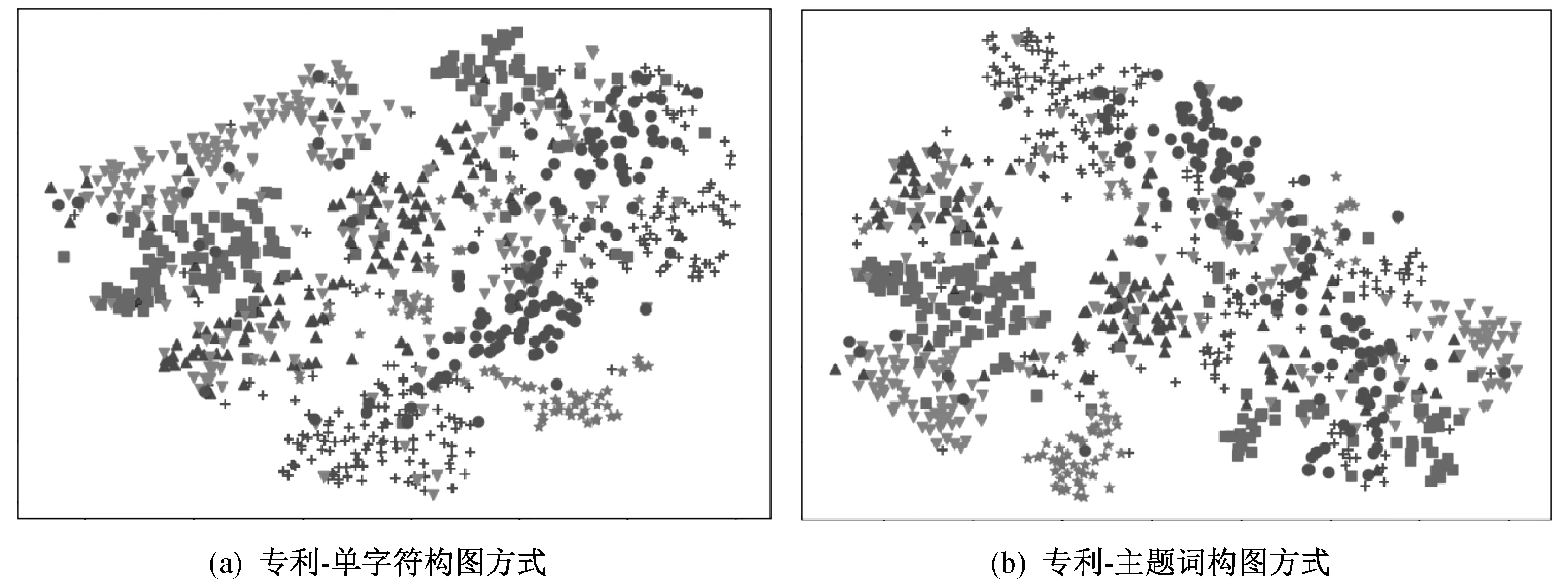
▲图3 两种构图方式专利分类可视化
由图3可以看出,带有相同标签的专利彼此接近,在向量空间中可以区分出六种类型。六种类型各自聚集在一起,这意味着大多数摘要主题词与对应的设计模块密切相关。由图3还可以看出,车架系统设计模块专利分类效果差于其它类别,这是由于车架系统设计模块相关专利中的摘要会涉及许多其它模块相关专利的主题词,车架系统设计模块相关专利和其它模块相关专利的耦合性较强。
5.3 专利语义模型效果
为了进一步对不同构图方式的专利语义模型效果进行分析,将六类基准专利作为基准向量,对各类相似专利与对应的基准向量进行余弦相似度计算,得到专利语义模型的准确性。笔者所选用的测试专利与基准专利见表4。

表4 测试专利与基准专利
两种构图方式的专利语义模型余弦相似度如图4所示。由图4可知,六大类共18项专利中,16项专利在基于专利-单字符构图方式图卷积神经网络的专利语义模型中与基准专利的余弦相似度大于基于专利-主题词构图方式图卷积神经网络的专利语义模型。因此,在向量空间中,基于专利-单字符构图方式图卷积神经网络的专利语义模型的基准专利与测试专利之间的向量更为接近,模型呈现的语义关系更加准确。这说明了基于专利-单字符构图方式图卷积神经网络的专利语义模型的效果优于基于专利-主题词构图方式图卷积神经网络的专利语义模型。
6 检索分析
6.1 专利查询评价标准
专利查询结果往往通过召回率与准确率来衡量,召回率计算时并没有考虑用户因素和相关文档的排名。目前也有一些算法,如综合评价分数,对召回率进行改进,但是对于专利集合未知的检索需求还存在一定问题。鉴于此,Magdy等[15]提出一个结合结果中相关文档排名情况的专利检索评价标准,计算式为:
(10)
(11)
式中:H为专利检索评价标准值;Zmax为返回给用户的最大检索专利数;rq为第q个相关文档的排名;a为相关文档数;R为Zmax中的相关文档数。
对于专利检索,最基本的衡量在于召回率,这个结果关注检索算法的查全率。
平均准确率对于单个主题而言,指每条相关专利被检索后的平均准确率。平均准确率是反映系统相关专利排名的一个指标,检索结果中相关专利排名越靠前,平均准确率就越高。如对于一个检索句,返回结果相关专利有五个,排名为1、4、7、9、13,则平均准确率计算结果为:
(1/1+2/4+3/7+4/9+5/13)/5=0.552
专利检索评价标准不仅考虑检索结果中相关专利的排名情况,而且兼顾召回率。专利检索评价标准值越大,说明检索算法的召回率越高,相关专利的排名越靠前。
6.2 不同检索式对比
在较好的专利-单字符构图方式图卷积神经网络的专利语义模型的基础上,基于设计方法学对设计人员常规使用的检索方式进行研究,对专利描述文本按功能-原理-结构、功能-原理、功能三种不同检索式进行对比试验。采用三种句式进行语义检索,分别为:① 为了达到防止刹车锁死的目的,主要通过刹车器的弹性件与移动座之间的动作关系来实现,刹车器的构成部分有夹臂、滑槽、制动组件、轴部、弹性件;② 为了达到防止刹车锁死的目的,主要通过刹车器的弹性件与移动座之间的动作关系来实现;③ 为了达到防止刹车锁死的目的。检索出相似专利文本,按照相关程度从高到低排序,选取前几项专利。三种检索式余弦相似度分析见表5。

▲图4 两种构图方式专利语义模型余弦相似度

表5 三种检索式余弦相似度分析
由表5可以看出,余弦相似度排名前几位的专利虽然应用功能不完全相同,但是专利的摘要内容与检索文本内容有所关联,这符合检索文本的目标主题。由余弦相似度可知,检索文本内容越丰富,最为相关的专利的余弦相似度就越小。这是因为在空间语义模型中,句子越长的文本,所包含的语义越丰富,语义吻合度极高的文本相对就越少。
6.3 检索结果分析
在基于专利-主题词构图方式图卷积神经网络的专利语义模型中,对于专利描述文本“为了达到防止刹车锁死的目的,主要通过刹车器的弹性件与移动座之间的动作关系来实现,刹车器的构成部分有夹臂、滑槽、制动组件、轴部、弹性件”,文本主题词为“刹车”“锁死”“夹臂”“滑槽”。笔者为提高专利文本语义分析的准确性,提取主题词的相关扩展词进行协同验证,将训练后的基于专利-主题词构图方式图卷积神经网络的专利语义模型输出的38 531个主题词词向量与目标主题词进行余弦相似度计算,进行相似词扩展。将余弦相似度阈值设定为0.7,选取语义近似的五个词,语义关联词扩展结果如图5所示。
专利检索评价数据选用专利语义模型输出的余弦相似度排名靠前的300条专利数据,作为文档库专利。此外,将其中的前30条作为返回给用户的检索最大结果数。通过主题词及其语义关联词的包含与否作为评价专利是否相关的依据,统计结果见表6。
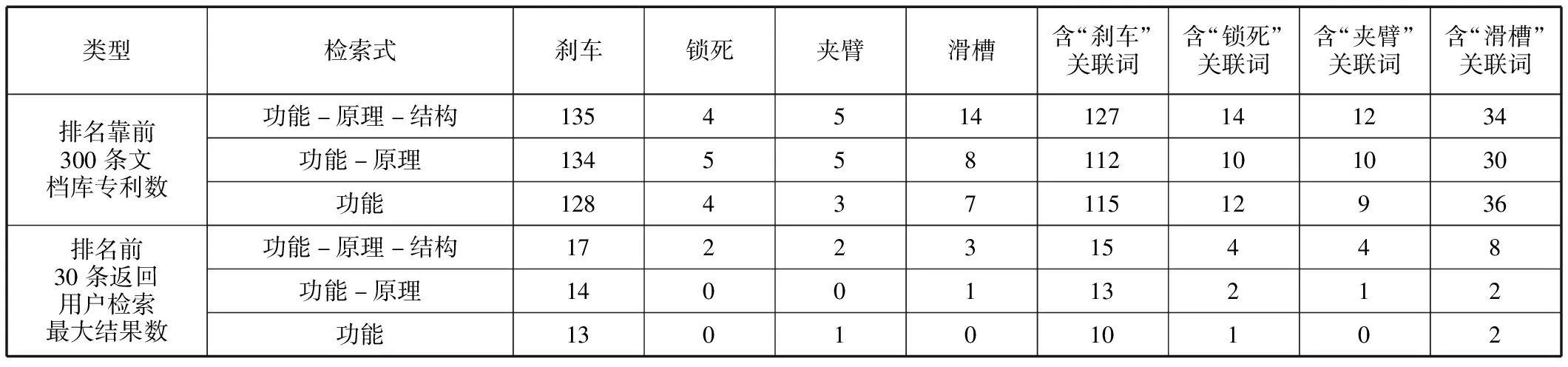
表6 主题词及语义关联词相关专利统计结果
选用的评价标准主要有平均准确率、召回率、专利检索评价标准,专利检索评价结果如图6所示。
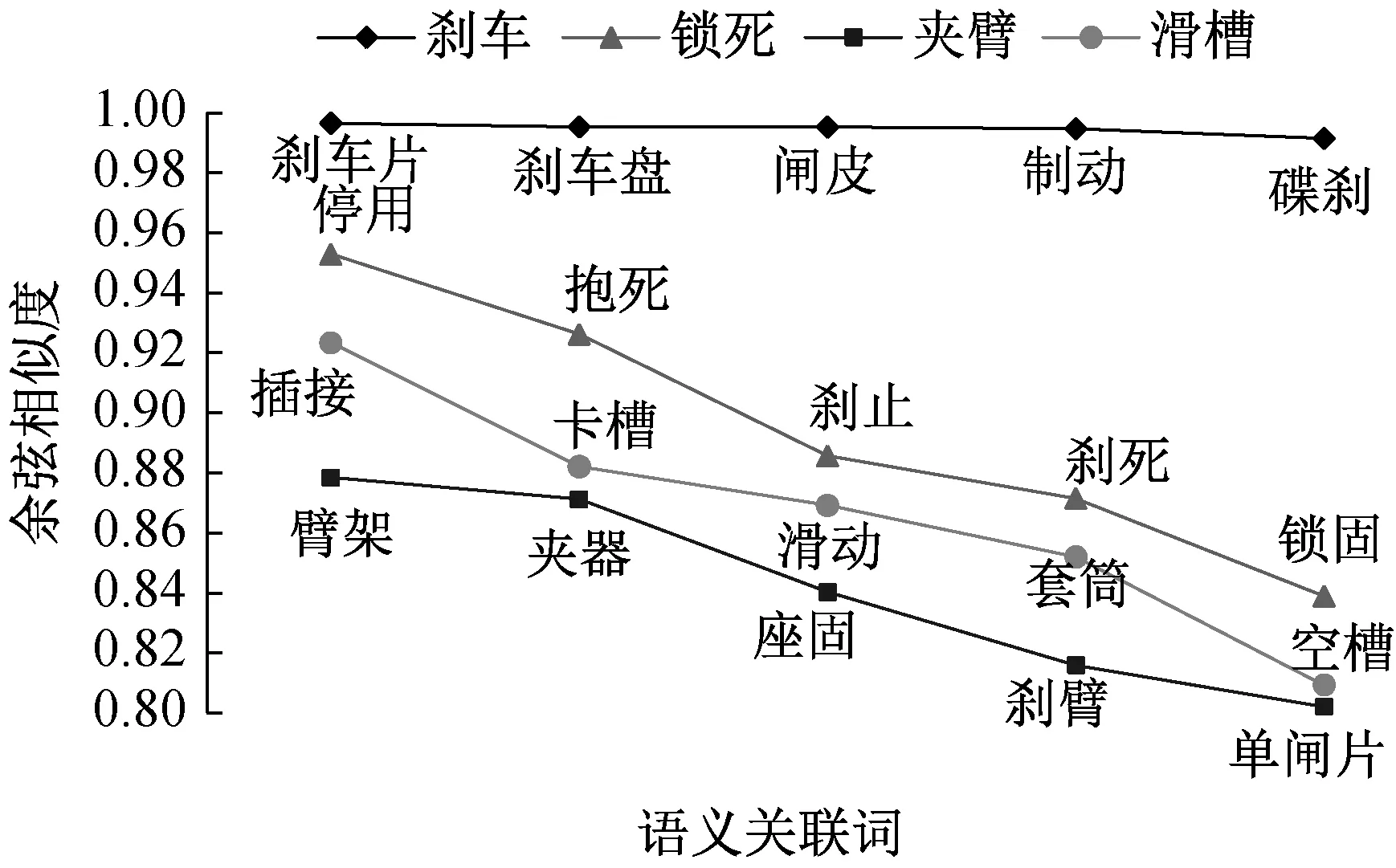
▲图5 语义关联词扩展结果
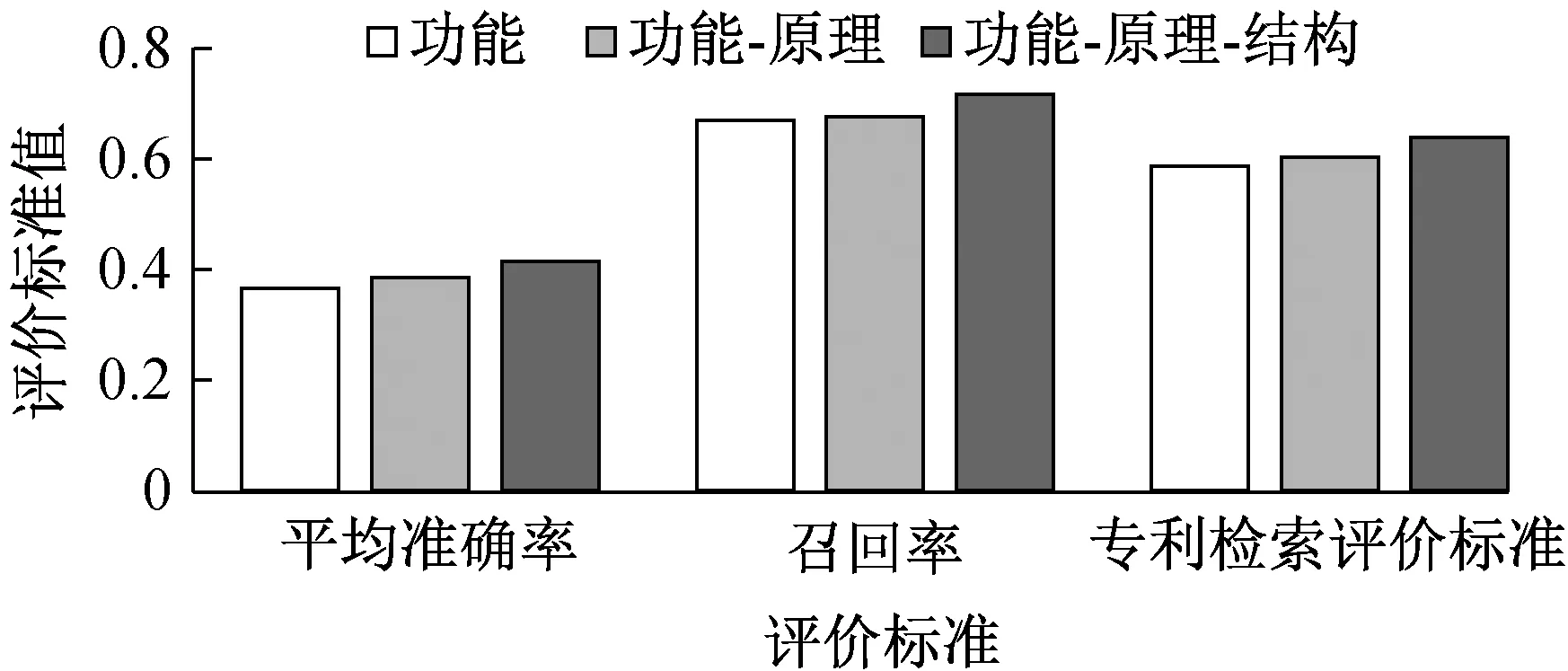
▲图6 专利检索评价结果
由图6可知,功能-原理-结构检索式效果相比功能-原理、功能检索式更好,因此,基于专利-单字符构图方式图卷积神经网络的专利语义模型在功能-原理-结构检索式中检索效果更佳。
7 结束语
专利由于专业性和专利词汇的相似性,不能简单将普通文本直接应用于专利检索。笔者通过构建基于图卷积神经网络的专利语义模型来对专利领域进行检索,通过不同构图方式和不同检索式来对模型进行评估,通过数据分析和对比可知,采用基于专利-单字符构图方式图卷积神经网络的专利语义模型,结合功能-原理-结构检索式,在检索效果方面更佳。笔者基于图卷积神经网络构建的专利语义模型在一定程度上使检索变得更加智能,可以为设计人员获取设计创新知识提供更佳有效的专利检索方式。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
老年医学与保健(2017年6期)2017-02-06
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
疑难病杂志(2014年12期)2014-04-16
质量与标准化(2010年5期)2010-05-03
