
基于二次引导图像滤波的跨模态语音增强方法*
2021-11-02 02:00马玉洁倪旭昇赵新民钱盛友
测试技术学报 2021年5期
马玉洁,倪旭昇,邹 孝,董 胡,2,赵新民,钱盛友
(1. 湖南师范大学 物理与电子科学学院,湖南 长沙 410081;2. 长沙师范学院 信息科学与工程学院,湖南 长沙 410100)
0 引 言
语音增强技术通常被用来处理语音的噪声污染问题. 相比传统的语音增强方法,一些新兴的语音增强方法效果更好,如:结合听觉掩蔽效应、压缩感知、深度学习的语音增强方法[1]. 随着视听交互研究的逐渐兴起,利用跨模态技术对信号进行处理的方法也开始受到关注,研究人员将原本分开处理一维声音信号和二维图像信号的技术转向创造性的跨模态处理[2]. 我们可以利用图像处理技术来处理语谱图,这种技术已应用于音乐转录、乐器声音分离、降噪等[3-5]. 相反,我们可以从视为语谱图的图像中产生声音信号,这种技术称为图像到声音的映射或模式回放[6-9].
Han等[10]将监督学习的方法扩展到去噪中,在没有受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)预训练的情况下对深度神经网络(Deep Neural Networks,DNN)进行训练,DNN被训练直接学习从损坏语音的语谱图到干净语音的语谱图的频谱映射. 这种使用DNN进行语音增强的方法通常比较复杂,需要大量的实验组,实时性不强. 王杰等[11]提出利用图像处理技术中的双边滤波算法对非平稳语音信号进行去噪,该方法可以从视觉上分析声音的时频特性. 但双边滤波通常效率偏低且在细节处理上有可能会产生梯度反转. 引导图像滤波(Guided Image Filtering,GIF)是在双边滤波的基础上提出的一种图像滤波处理方法,同样具有保持图像边界并对图像进行去噪的的特性,同时,GIF在细节处理上优于双边滤波且时间复杂度与窗口大小无关.
到目前为止,利用跨模态技术处理语音信号的方法还甚少,多数利用语谱图进行语音增强的方法也较为复杂[12,13]且参数多为人工设定. 粒子群优化(Particle Swarm Optimization,PSO)算法在工程上用于求解优化问题,因其需要调整的参数较少,结构简单而被广泛使用,而且相对于其他启发式优化算法来说,其能在最短的时间内获得更稳定的高质量最优解. 本文将一维时域语音信号转换为二维图像信号,以语谱图为媒介,利用二次引导图像滤波(Secondary Guided Image Fltering,SGIF)进行语音增强处理,并利用PSO对SGIF中的参数进行优化,最后通过重叠相加法和傅里叶反变换得到增强的语音信号.
1 算法原理
1.1 语音信号的语谱图
语谱图也称语音频谱图,其中,横坐标表示时间,纵坐标表示频率,坐标点的像素值代表语音信号的能量,能量值的大小由颜色来表示. 它能将语音的许多特征通过二维图像呈现出来,采用二维平面表达三维信息. 我们可以以它为媒介完成跨模态处理.
语音通常是一种随机的非平稳信号,具有时变性,带噪语音信号的数学表达式为
x(t)=f(t)+s(t),
(1)
式中:f(t)为纯净的语音信号;s(t)为噪声信号;x(t)为带噪语音信号. 对式(1)进行短时傅里叶变换(STFT)变换为
X(k,l)=F(k,l)+S(k,l),
(2)
其中,
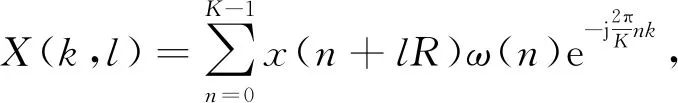
(3)
式中:k和l分别为频率点和时间点;K为帧长;R为帧移;ω(n)为实数窗序列. 带噪语音信号语谱图的数学表达式为
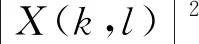
(4)
归一化语谱图为
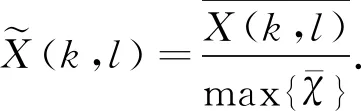
(5)
1.2 图像滤波处理方法
1.2.1 引导图像滤波
GIF最初在2010年由He等提出[14]. GIF的核心是引导图像I与滤波输出图像q,两者以像素k为中心存在一种局部线性关系,即
qi=akIi+bk, ∀i∈ωk,
(6)
式中:ωk为半径r的一个方形窗口;(ak,bk)为窗口ωk中的线性系数.为了使输入图像p与输出图像q最接近,根据无约束图像复原方法将其转化为最优问题
qi=pi-ni,
(7)
式中:ni为噪声;pi为qi受到噪声ni污染的退化图像,其代价函数为
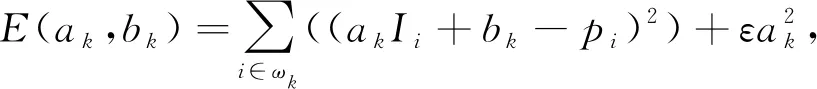
(8)
式中:ε为用来防止ak过大的正规化参数.要保证输出图像和输入图像之间差异尽可能小,关键在于求出ak和bk的最优解,通常利用最小二乘法求解出线性系数(ak,bk).求解式(8)得
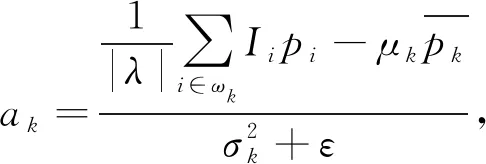
(9)
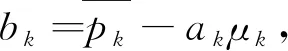
(10)
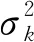
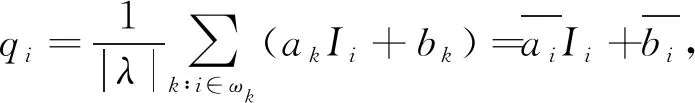
(11)
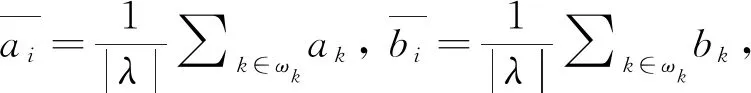
(12)
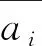
1.2.2 二次引导图像滤波
低信噪比情况下,语谱图显示噪声主要集中分布在高频段,利用一次GIF并不能有效估计高频段信息,即带有噪声的输入图像p经过一次GIF的图像q在不同频段上仍有残余噪声. 为克服一次GIF的缺陷,可用SGIF来进一步抑制噪声[15]. 该模型是将第一次GIF后的输出图像q作为SGIF的引导图像,经过SGIF输出后的图像为最终增强后的语谱图q′. 利用GIF进行去噪时,去噪效果是由引导滤波器的正规化参数和窗口半径决定的. 为了使经过初次估计输入图像的结构信息后能够更好地保留其细节信息,所提出的SGIF窗口的设置应该比GIF的窗口小. 因此,两个滤波器组中正规化参数和窗口半径不同,为了准确估计噪声信号,本文利用PSO算法对滤波器组中参数进行优化.

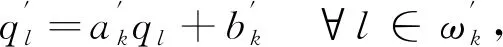
(13)
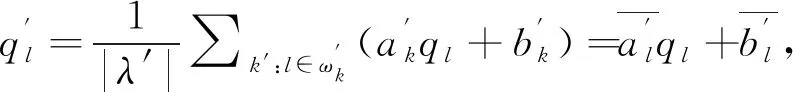
(14)
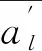
1.2.3 参数优化
GIF平滑效果与正规化参数ε和窗口半径r有关,不同的待去噪图像以及不同的滤波器需要设置不同的参数组,参数的设置直接影响着最终的去噪效果.
PSO算法是核心思想为群智能优化的一种全局优化算法,最优问题具体包括3个特征:位置、速度、适度函数. 通过对一群随机粒子进行搜索,利用迭代找出相应的最优解. 假设搜索空间为D维,种群中有m个随机粒子,其中第i个粒子的位置用向量Xi=[xi1,xi2,…,xiD]表示,速度用向量Vi=[vi1,vi2,…,viD],i=1,2,…,m表示.第i个粒子个体搜索到最优位置为pBesti,全局最优位置为gBest,其中pBesti=[pBesti1,pBesti2,…,pBestiD],gBest=[gBest1,gBest2,…,gBestD].通过pBesti和gBest可以更新粒子的速度及位置,具体公式为
vij(t+1)=
σ*vij(t)+c1*rand1j*(pBestij(t)-xij(t))+
c2*rand2j*(gBestj(t)-xij(t)),
(15)
xij(t+1)=xij(t)+vij(t+1),
(16)
式中:c1为控制个体经验的影响权重;c2为控制社会认知的影响权重;rand1j,rand2j为范围[0,1]的随机实数;σ为惯性因子.
本文利用PSO算法时优化的是两个参数,所以搜索空间是二维的,文中直接利用结构相似性(Structual Similarity,SSIM)作为适度函数[16],则此时t时刻第i个粒子的位置为
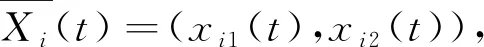
(17)
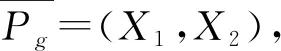
1.3 语谱图的增强及时域信号的恢复
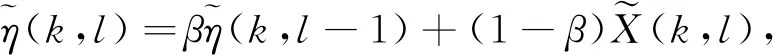
(18)
式中:k和l分别为频率点和时间点;β为取值为0~1的遗忘因子. 本文方法得到的增强语谱图为
y(k,l)=max{X(k,l)-αq′(k,l),0},
(19)
式中:α为0~αmax的常数. 归一化处理
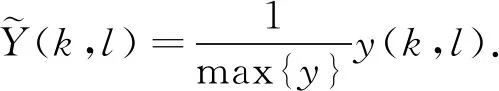
(20)
应用逆IFFT合成时域增强语音
f(t)=IFFT{G(k,l)X(k,l)}.
(21)
增益为
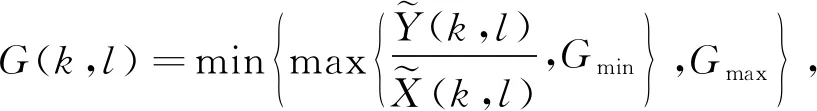
(22)
式中:Gmin∈[-30 dB,-10 dB],用于限制残留噪声的最小值,Gmax=1. 基于PSO优化的二次引导图像滤波(SGIF-PSO)语音增强方法框图如图 2 所示.

图 2 基于SGIF-PSO语音增强方法框图
2 实验结果与分析
本文利用Matlab2017b版本下进行的仿真实验对本文算法的增强效果进行验证. 选用的语音数据来源于NOIZEUS中纯净语音信号sp10文件,噪声为高斯白噪声,信噪比分别为0 dB、5 dB、10 dB. 信号采样频率设为8 kH,量化精度为 16 bit,帧长为25 ms,帧移为10 ms,窗函数为hamming窗. PSO算法种群大小为50,最大迭代次数为200,C1=2.8,C2=1.3,权重系数ωmax=0.9,ωmin=0.4. 将本文方法与传统谱减法、文献[11]双边滤波法、GIF、未进行粒子群优化的SGIF方法进行比较,结果采用信噪比(SNR)及语音质量感知评估(PESQ)作为评价指标.
首先使用本文的语音增强方法对含5 dB白噪声的带噪语音信号进行增强.
图 3 对比了增强前后语音信号的波形图和语谱图,通过时域波形可以看出,本文算法能够有效抑制带噪信号中的噪声,增强后的语音整体含噪幅度明显降低,且波形图基本保持完整,语谱图中对高频处的噪声抑制作用更加明显.
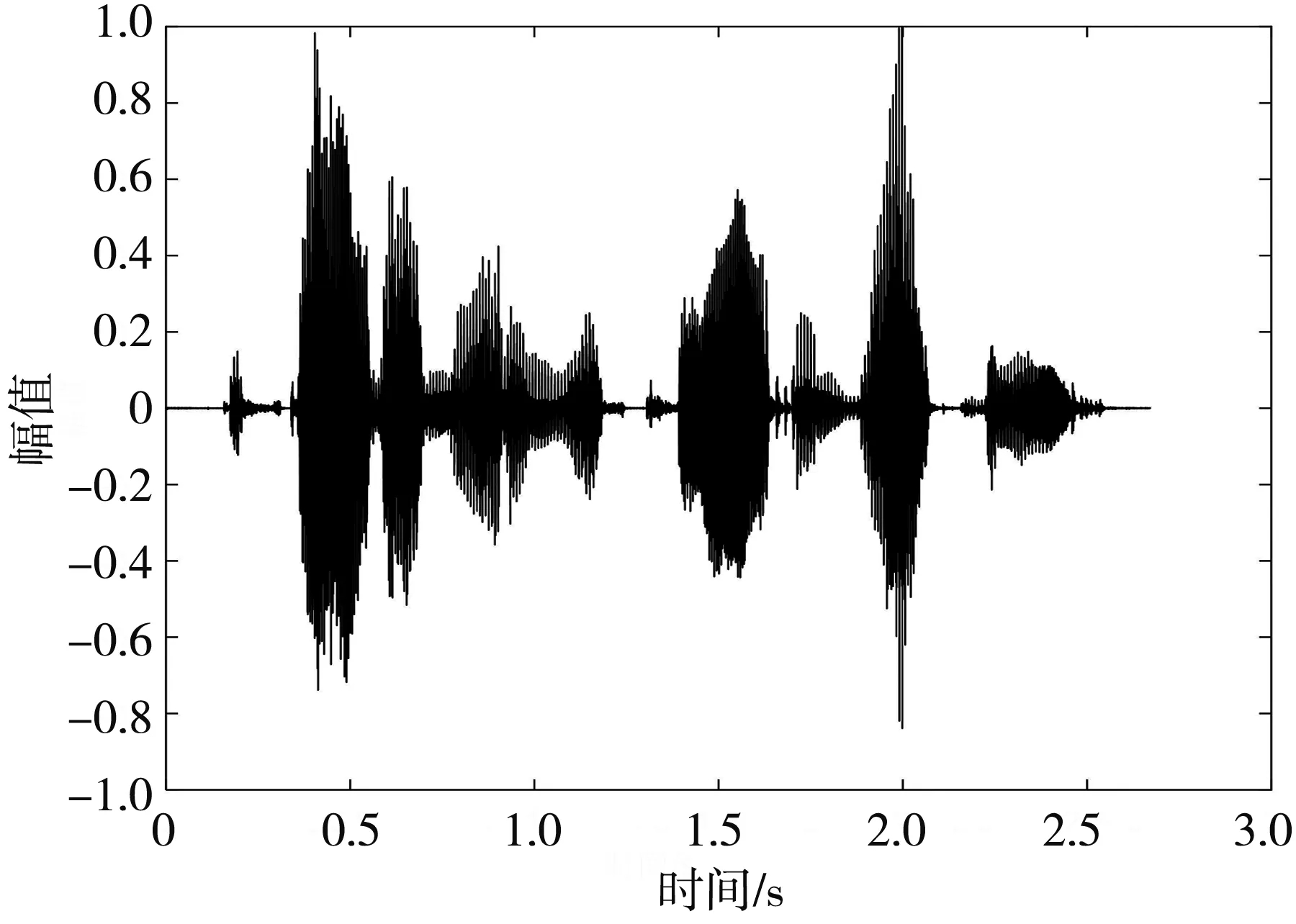

(a) 纯净语音
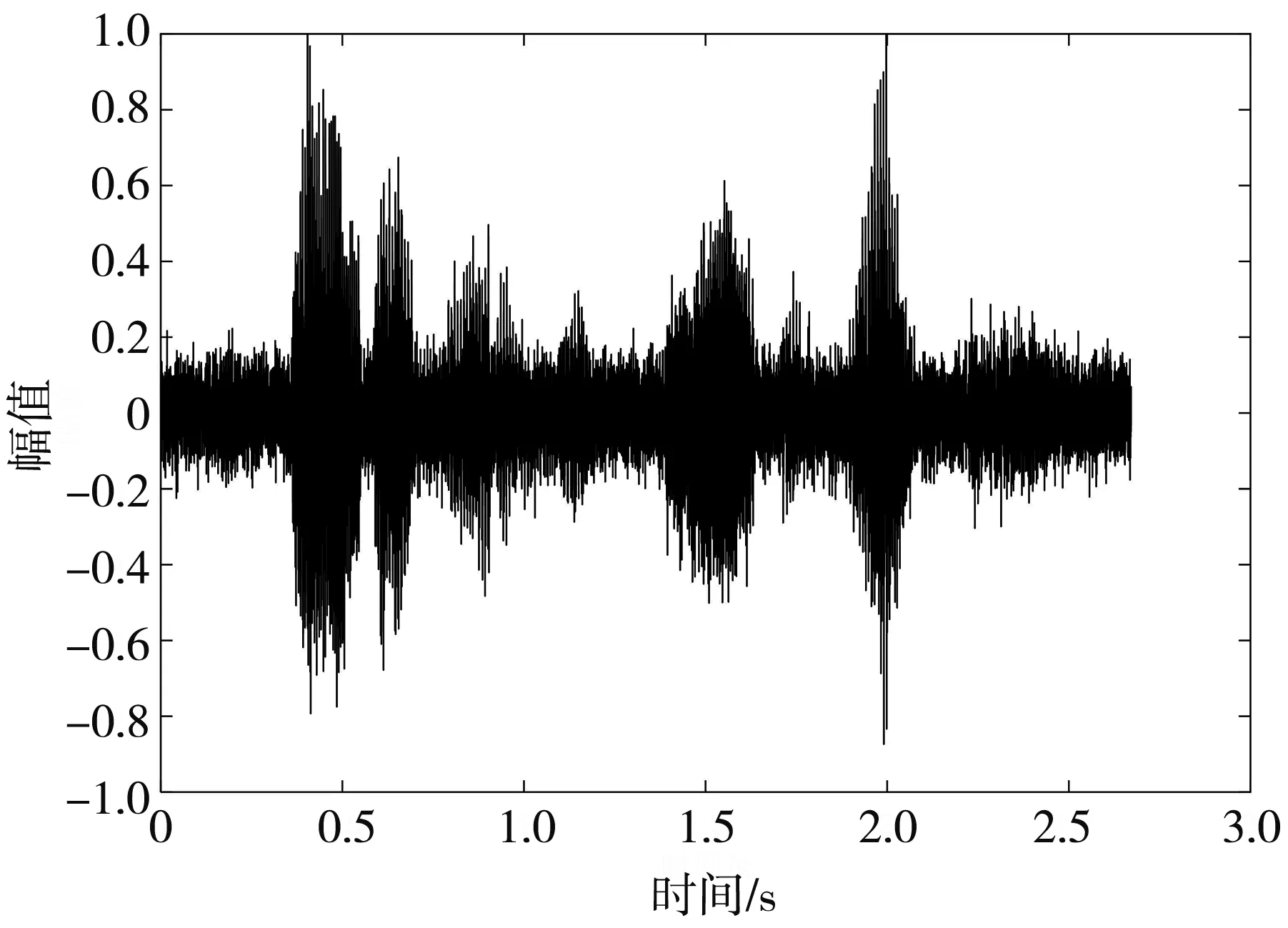
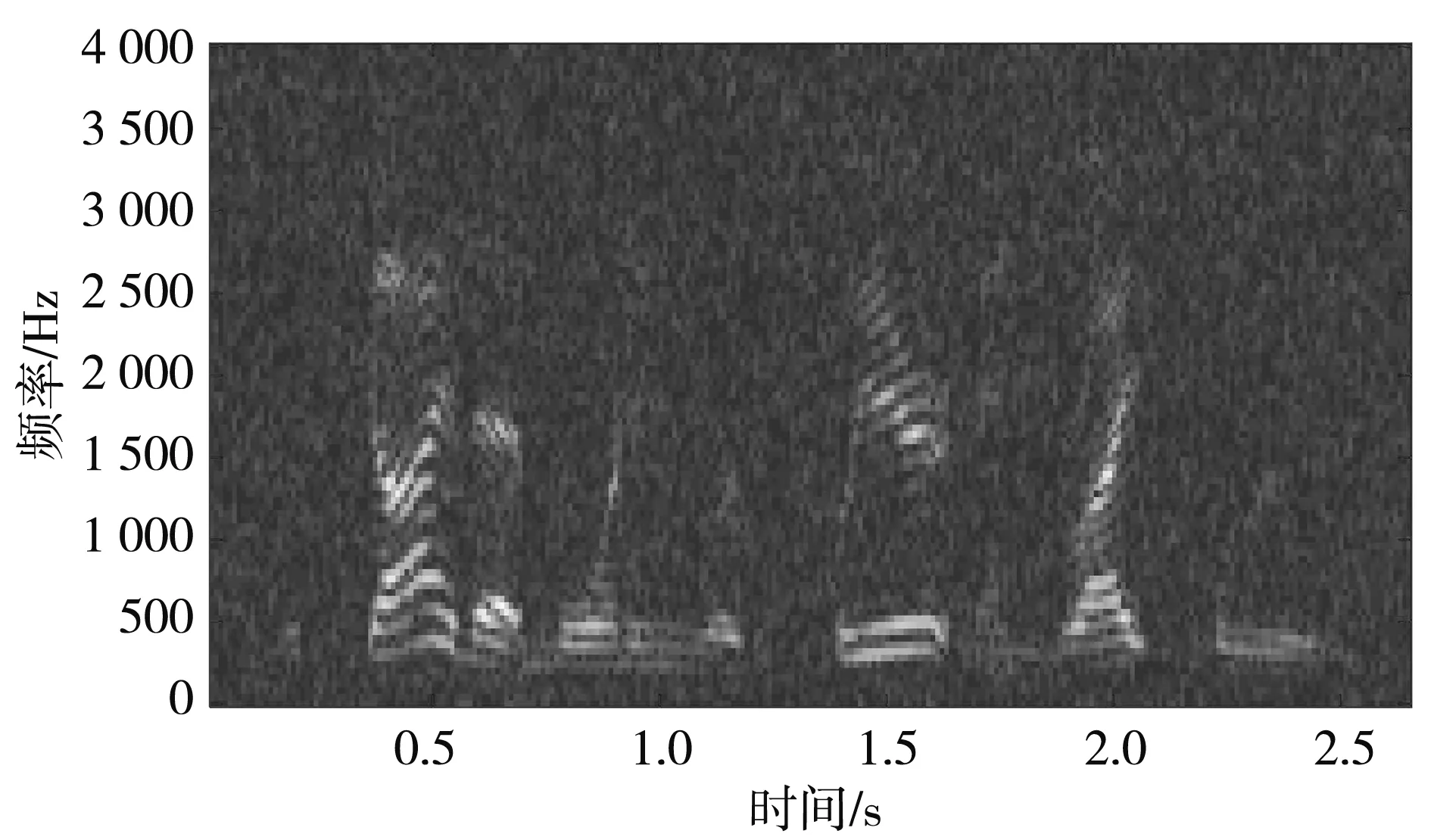
(b) 带噪语音
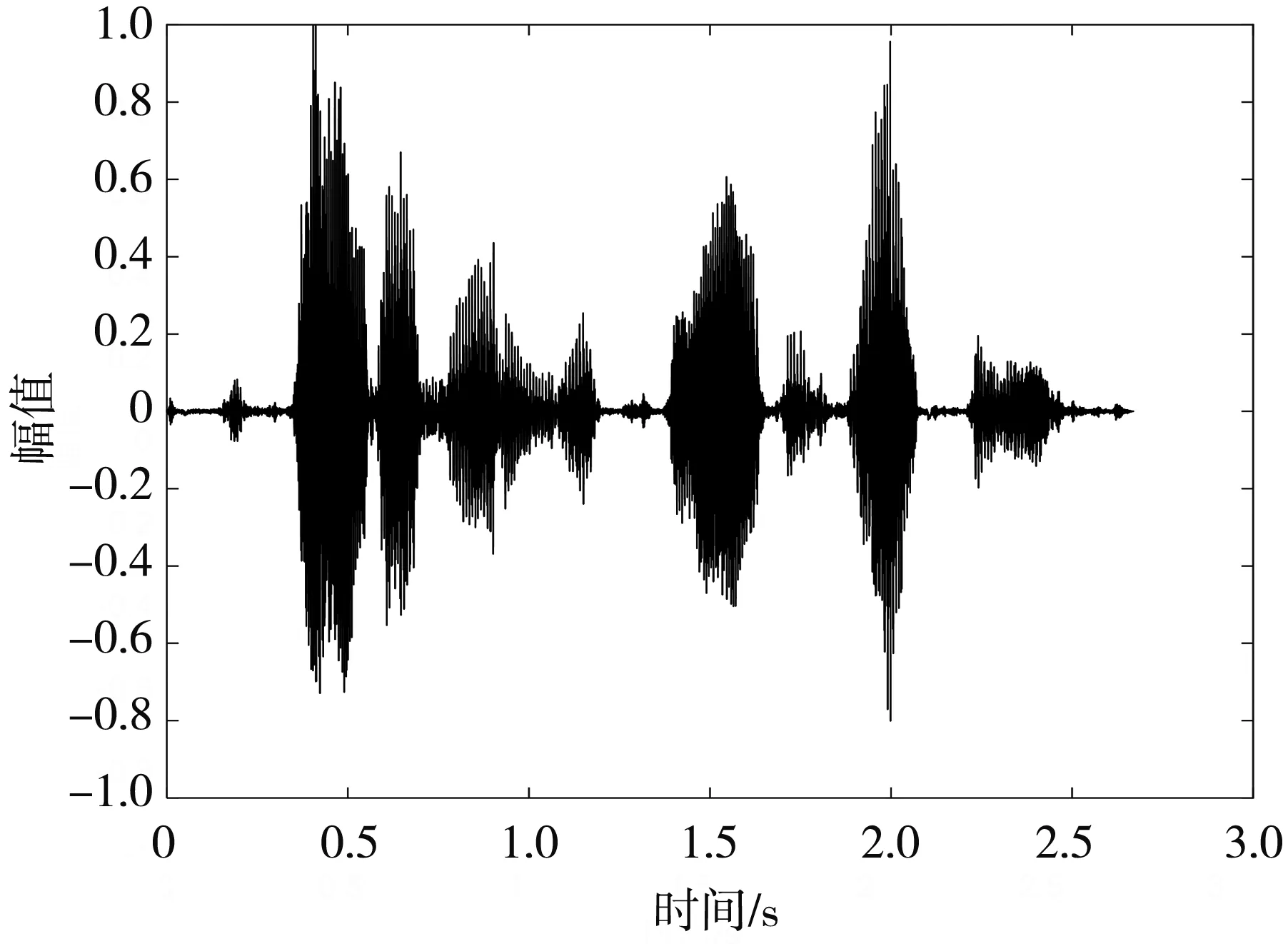

(c) 增强语音
表1 对比了5种方法在含不同信噪比噪声情况下语音增强后的SNR结果,可以看出5种算法均能够降低噪声. 低信噪比情况下,会导致语音信号与噪声信号的边缘模糊,利用图像处理技术能够在有效去噪的同时最大限度地保持图像边缘信息. 本文算法优于谱减法、文献[11]双边滤波法、一次GIF和未进行粒子群优化的SGIF的方法,信噪比提升能力更强. 对比文献[11]中的方法,本文所提方法不会产生梯度反转,在细节处理上更好,不同类型不同信噪比的背景噪声均能被有效抑制. 实验中虽然对于Babble噪声的去噪效果略低于White噪声和Factory噪声,但是总体上本文算法具有良好的鲁棒性.
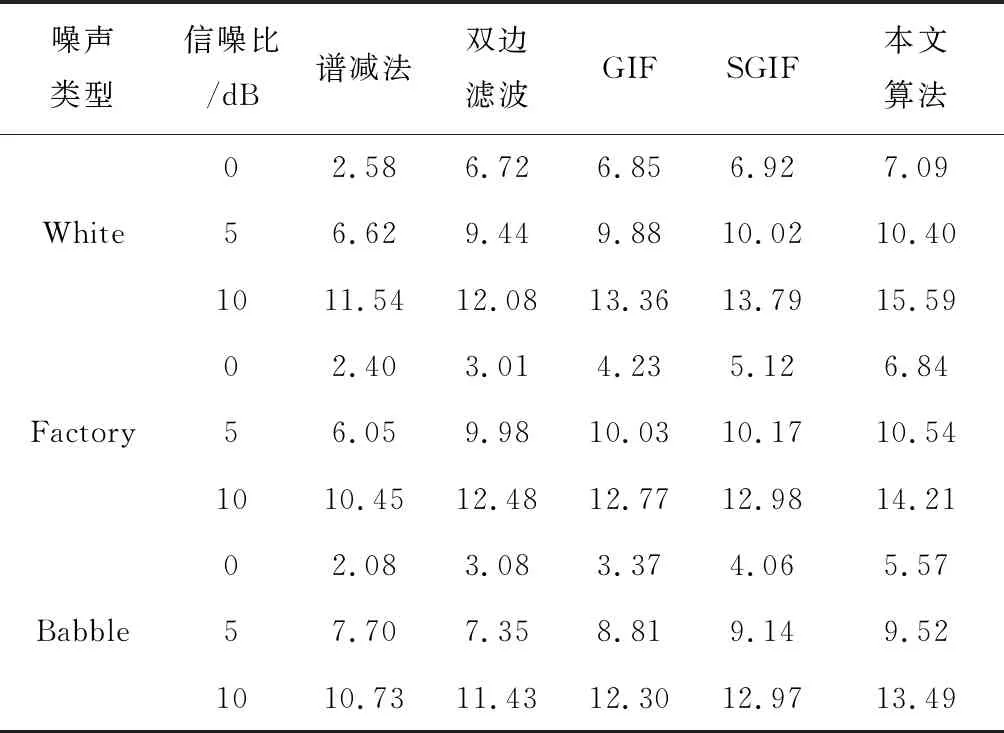
表1 5种算法输出SNR结果对比
表2 为5种语音增强算法在不同输入噪声的不同信噪比下的PESQ结果. 对比可得本文语音增强方法的PESQ值高于其他4种算法. 所提语音增强算法在White类噪声下增强效果最好,相对于谱减法PESQ增加可达0.58;虽然其他3种图像滤波方法具有保边去噪效果,但本文所提语音增强方法的输出语音整体感知质量更高.
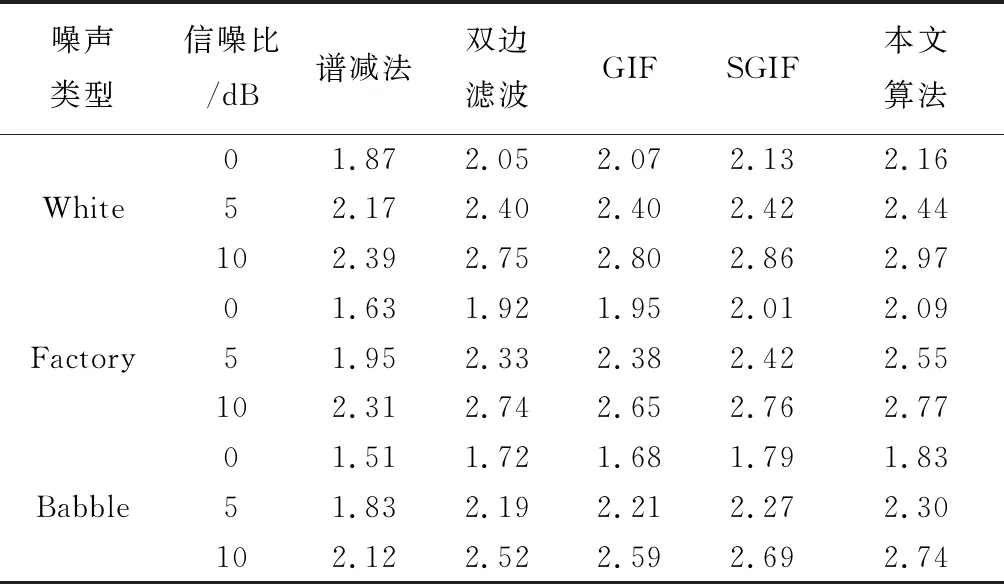
表2 5种算法PESQ结果对比
3 结 语
针对低信噪比情况下非平稳带噪信号中语音噪声在一定程度上重合,导致语音信息的边缘被噪声覆盖的问题,本文采用图像处理技术,将语谱图作为媒介,实现图像到声音和声音到图像的创造性转换,达到跨模态处理的目的. 文中提出的语音增强方法具有更好的保边去噪性,可以直接从带噪语音的归一化语谱图及其增强语谱图中计算出增益函数,无需进行噪声估计. 当噪声强时,引导图像边缘遭到破坏无法提供准确的引导信息,去噪效果遭到破坏. PSO优化的SGIF克服了在低信噪比的情况下一次GIF不能有效估计图像的高频信息的缺点,能够通过调整滤波器组中的参数减少不同频段的噪声残留. 实验表明,改进的引导滤波有更好的边缘平滑度和滤波效果,在PESQ和SNR评价方面有较好的性能,为后续的语音信号研究提供了相对纯净的语音信号.
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2019年9期)2019-10-26
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
雷达学报(2017年3期)2018-01-19
空间控制技术与应用(2015年3期)2015-06-05
遥测遥控(2015年2期)2015-04-23
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
