
数据空间中一种基于步进的后映射(SPM)迭代方法
2021-11-12 02:17吉露,曹斌
智能计算机与应用 2021年9期
吉 露, 曹 斌
(1 贵州大学 大数据与信息工程学院,贵阳 550025;2 中铝智能科技发展有限公司, 杭州 310000)
0 引 言
当前,数据正呈现着海量、多样和动态的特点,使得数据集成和数据管理需要遵循pay-as-you-go的模式[1],数据的管理是在管理过程中逐步的完善,这有别于传统的数据库系统以及数据集成系统中高成本、高功能的集成和管理技术。因此,数据空间以“pay-as-you-go”的模式来管理这些海量、动态,异构数据为目标的新型数据管理方式应运而生[2-3]。然而,由于数据间的模式异构带来数据的检索效率下降,一定程度上阻碍了数据空间的发展。
将数据空间看作是一个虚拟的空间,在其中管理许多的数据源,而不去考虑其结构和位置[4];这样做的目的是不需要任何领域专家协助的情况下,提供基本的功能服务,信息的检索和关键字检索等。然后创建自动的语义映射,这将导致多种可能的语义映射,映射的结果有些是正确的,有些并不完全正确,这带来了第一类不确定映射,概率模式映射和可靠中介模式映射用来处理多个可能映射之间的不确定[5]。在概率映射和可靠中介模式映射中,系统需要选择一个阈值,数据空间中语义映射的数量较大,选择一个阈值成为一项不确定的任务,会带来数据丢失。
针对模式匹配,COMA系统通过组合多个匹配器来提高两个输入模式之间的语义映射[6];另一个系统SF以两个图模式作为输入,并在模式的对应节点之间生成映射作为输出[7]。PORSCHE从一组基于树的多个输入模式中提供了一个中介模式[8]。这些系统都只是接受两个源模式作为输入,而其它系统接受多个模式但通常都带有领域专家的反馈,数据空间的应用领域中,用户可能没有足够的技能来操作映射器或提供精确的映射,并且连接到数据空间的源模式具有异构的结构,可以是文件,关系数据库,XML存储库,web页面等。因此,数据空间需要一种新的数据集成方法。数据空间中的集成是“pay-as-you-go”现收现付方式[9]。对于数据空间这样的数据管理场景下,黄毅芳等人将本体的概念引入到数据空间中[10];在引入本体概念的情况下,苏畅提出一种基于hash映射,将记录映射为空间中的一个个点,进行映射结果的分块[11];寇月等人提出了语义项映射方法,考虑数据源间的语义关联[12];Kuicheu等提出了一种将概率映射与可靠度(RMedMap)结合的方法,通过设定阈值来确定可靠的映射集,容易带来数据的丢失[13]。本文提出了一种后映射方法(SPM)来处理这种映射的不确定性,不需要选择阈值。引入可能性理论,将可靠的映射集合进行排序并划分为可能性分布的子集,给每个子集分配一个递归可能度函数,其是源模式和目标可靠的中介模式间最可靠的映射。本文提出的SPM算法与现有的概率映射(possibility)、概率-可靠映射(RMedMap)以及falcon映射进行了对比。
1 处理可靠映射间的不确定性
1.1 数据空间中的映射架构
数据空间中,模式匹配和可靠映射的映射架构如图1所示。从连接到数据空间的数据源,首先提取其内部图表示;其次,进行语法,语义和结构匹配,来推导出图表示之间的语义和结构关系,将语义和结构关系合并在一起,产生可能的中介模式;最终,系统计算中介模式的可靠度,生成可靠的语义映射传递给查询。
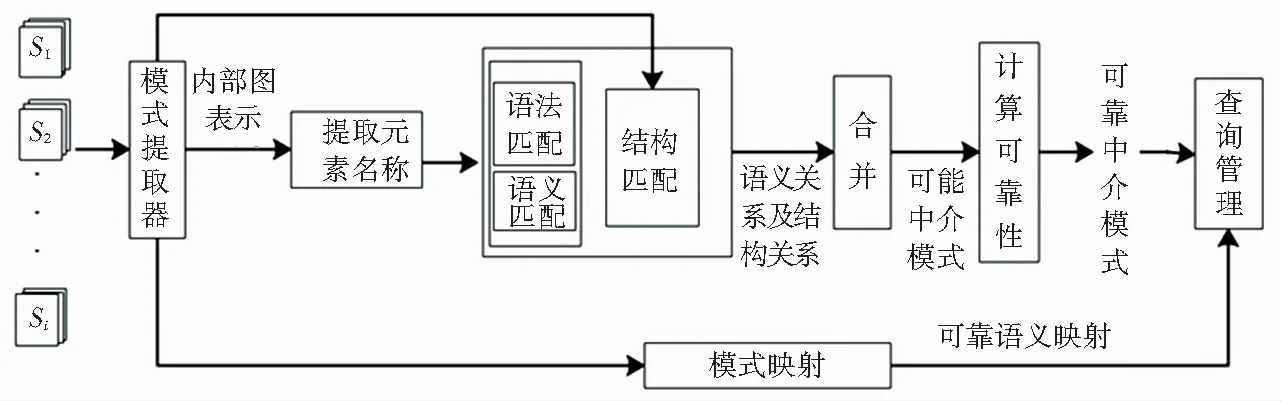
图1 映射架构
1.2 可靠的模式匹配和映射原则
1.2.1 相似性计算
假设两个源模式Si和Sj,ei和ej分别是Si和Sj的两个非叶元素节点,非叶元素节点是从源模式的对应图表示中收集的概念,并非是其叶子结点。引入信息熵概念计算元素ei和ej的语义相似度,式(1):
(1)
其中,IC(c)=-log2p(c)是元素e所含的信息量,δ是正实数。
基于元素节点ei和ej所处的图模式中的位置,计算ei和ej之间的结构相似度[13],式(2):
(2)
其中,d(e)是e在这个模式图表示中的等级,d(MS(e1,e2))表示e1,e2最近的父节点的位置距离。
根据语义关系以及结构关系合并,构建出可能的中介模式,如对于铝电解的原料构成成分中的两个源模式S1和S2,如图2所示。
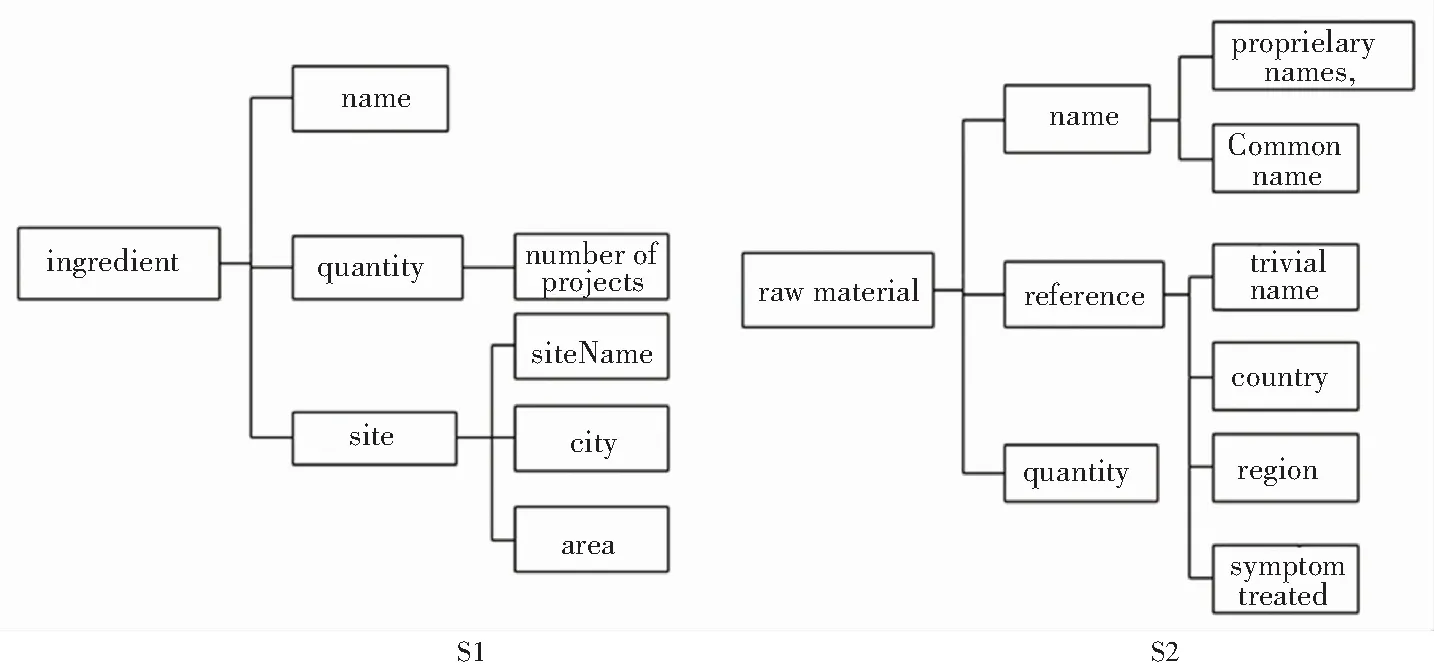
图2 模式对比
对于源模式S1和S2,S1中的ingredient通常是用于氧化铝浓度分析的元素,是关于元素的常见信息,name可以是一个普通名称(CommonName),科学名称(ScientificName), 方言(VernacularName),raw material是氧化铝原材料的元素,当用户进行查询时,计算相应的可靠度d(m)将S1中ingredient映射到S2中的raw materia,得到两个模式间可能的映射为:(ingredient,raw material)、(site,reference)和(name,name)等。
1.2.2 可靠度计算
考虑到一组可能的中介模式的实例T和给定的源模式Si,其目的就是要找出T关于Si是否可靠,并赋予T一个关于Si的可靠度。可靠度从两个方面来考虑,首先以结构角度来检验T相对于Si是否可靠,称为结构可靠度,若T的根节点在结构上是可靠的,那么T相对于Si则是可靠的。结构可靠度的计算方法为结构上等同于Si子节点的T的子节点数与Si的子节点数之比。T相对于S的结构可靠度公式(3)如下:
(3)
计算T关于Si的可靠度,式(4):
(4)
其中,d(e)是元素e所属组元素之间的相似值,p(e)表示在中介模式中遇到元素e实例的概率,是包含e的中介模式的数量除以中介模式的总数的比值。
如果满足条件(1)和(2),T对Si是可靠的:
(2)dT/Si>β。
对于上文提到的源模式S1和S2,表1给出了一组5种可能的相互不同的映射mi(i=1,…,5)及其相应可靠度。

表1 可能映射及可靠度
2 可能性理论
语义映射的数量较大时,阈值的选择可能成为一项不确定的任务,并可能导致信息丢失。因此,引入了基于可能性理论的后映射方法(SPM),用于管理可靠映射之间的不确定性。
可能性理论是一种专注于处理不完全信息的不确定性理论,类似于概率论。通过使用一对称为可能性和必要性测度的对偶函数来消除概率,而不是仅使用一个。也就是说,事件分离的可能性程度是单个事件可能性程度的最大值。相反,事件关联的必然性程度是单个事件的最小必然性程度。
使用最大值和最小值运算,以及对RmedMap方法的弥合,符合计算简单性的要求。在许多的真实应用中,这种不确定性具有相当粗略和定性的性质。但在可能性理论中,不确定性的建模可能仍然是定性的。因此,需要使用一个有限的完全有序的可靠性等级链,在这里用在0~1之间的数λ来表示,λ1=0<λ2<λ3<…<λn=1。
2.1 后映射算法
构建DSSP的目的是为用户提供信息检索或关键字搜索等基本功能。因此,系统产生的结果应考虑与DSSP连接的源中所有可用的信息。rMedMap是一种基于可靠性的方法,使系统能够利用源中尽可能多的可用信息,相比之下,概率映射是一种基于概率的方法,考虑的可用信息较少。本文提出的后映射方法利用连接到DSSP的源中所有信息。SPM映射方法是一种基于步进的方法,其使用后一组可用信息的结果提供当前可用信息集的结果,如图3所示。
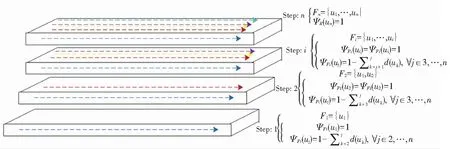
图3 步进的后映射方法
在step1中,系统只处理子集F1及其相应的特征函数ΨF1,在step2中进一步对子集F1进行扩展,构造出子集F2及其对应的特征函数ψF2,ψF2也携带后一个特征函数ψF1的信息,以此类推。
2.2 SPM映射过程
引入可靠映射定义,对于源模式S,目标模式T,一个可靠的中介模式是一个(T,dT/Si),T是可能的中介模式,dT/Si是T对于S的可靠性程度。
一个与标签tag(xi,xj)相匹配的标签是一个四元组:
Tag(xi,xj,sim(xi,xj),op(xi,xj))
(5)
sim(xi,xj)为xi和xj之间的语义相似性,op(xi,xj)是xi和xj在结构上的相似度。例如,对于实验数据集中ingredient与raw material之间的匹配标签为:
tag(ingreditnt,rawmaterial)=(ingredient,
rawmaterial,0.78,≡)
一个可靠的映射m是一对元组(m,d(m)),m是S和T之间的一组相互不同的一对一标签匹配结果,d(m)是映射M对S的可靠度。根据已给出的应用实例,得到一个可靠的映射:
(m1,d(m1))=
((ingredient,rawmaterial),0.78,≡),
(quantity,quantity,0.93,≡),(name,name,0.93,≡),(site,reference,0.5,≡)
S和T之间得到的可靠的映射集M是一组成对的组合:
M={(m1,d(m1)),(m2,d(m2)),(m3,d(m3)),(m4,d(m4)),(m5,d(m5))}是一个可靠的映射集,是源模式和目标模式之间相互独立的可靠映射集。为语义映射分配可靠度有利于克服自动生成的多个映射之间的不确定性,管理所得到的可靠映射集,大多数方法采用了可靠性阈值。阈值方法会导致一个层面的不确定性。事实上,如果语义映射是互不相同的,那么可靠度的值取决于系统自动产生的语义映射的数量。如果语义映射的数量较高,则可靠性会较低,这样选择一个阈值来进行可靠映射集的选择成为了一项不确定的任务。例如,若选择一个阈值为0.1,隐藏在映射m5中的数据信息会丢失,这是因为d(m5)<0.1,。为了解决这样的不确定性问题,引入可能性理论,引导系统处理所有可用的数据信息,提出了SPM映射方法,将可靠的映射集划分为可能性分布的子集。为了构造这些子集,对得到的映射集合M中的元素进行降序的排序,并且向该集合固定的增加两个可靠映射元组,(mhigh,d(mhigh))和(mlow,d(mlow)),使得d(mhigh)=1,d(mlow)=0。一个有序集合U={(u1,d(u1)), ……,(un,d(un))}是一个可靠的映射集M通过降序得到,并使得:
(1)d(u1)>d(u2)>…>d(un)
(2)(u1,d(u1))=(mhigh,d(mhigh))
(3)(un,d(un))=(mlow,d(mlow))
通过得到的可靠映射集,将加入的两个可靠映射元组构成集合,可以构建一个有序的映射集U={(u1,d(u1)),(u2,d(u2)),……,(u7,d(u7))},且满足:
(1)(u1,d(u1))=(mhigh,1)
(2)(u2,d(u2))=(m1,0.272)
(3)(u3,d(u3))=(m2,0.235)
(4)(u4,d(u4))=(m3,0.210)
(5)(u5,d(u5))=(m4,0.176)
(6)(u6,d(u6))=(m5,0.106)
(7)(u7,d(u7))=(mlow,0)
得到的映射集合U为一个n>1的有序映射集,并且1-d(ui)=d(d(un+1-i)),U={(u1,d(u1)),(u2,d(u2)),…,(u7,d(u7))},使d(u1)>d(u2)>…>d(un)。定义n个子集Fi,Fi={u1,u2,…,ui}(n为子集Fi的数目),特征函数ψFi由映射集的可靠度得到,1≤i≤n,对应的特征函数如下:
Fi={u1,u2,…,ui}
(6)
(7)
基于上述实例以映射子集F1为例,映射子集F1相应特征函数,式(8)。
(8)
根据这个例子,还可以构造可能性分布的子集F2,F3,F4,F5,F6和F7及其对应的特征函数。ψF2,ψF3,ψF4,ψF5,ψF6和ψF7,迭代特征函数ψFi与可靠度函数d(u)比较,Fi⊆U。
设Fi是U的第i个子集,使得uj1,uj2∈U,其中至少一个属于Fi,Fi(uj1)>Fi(uj2),当且仅当d(uj1)>d(uj2)。
可靠匹配算法如下:
输入:可能的中介模式T1,T2,…,Tm
源模式Si
输出:可靠的中介模式
计算模式间语义相似度以及结构相似度,得到标签匹配元组tag,合并得到可能的可靠中介模式T
可行理论:引入两个额外的可靠中介模式,(mhigh,d(mhigh)),(mlow,d(mlow)),使得d(mhigh)=1,d(mlow)=0。
开始
循环j=1~m
判断 计算中介模式T对于源模式S的可靠度d(m)
得到可靠映射元组M,根据其可靠度d(mi)降序排序
返回降序排序的映射集U
迭代映射 定义N个子集Fi,Fi={u1,u2,…,ui},根据式(5)特征函数得到新可靠度,获得降序排序后的映射子集,映射子集不断迭代,直到结束
结束循环
提取所有可靠映射集
结束
3 实验分析
本算法使用java语言实现,在IntelliJ IDEA平台上实现。为验证本方法的可行性,从国内某铝厂数据平台中获取实验数据集进行实验。共选取120个数据集,共4类,其中有6个数据集词汇与结构上都相似,34个数据集词汇不相似,结构上相似,12个数据集词汇上相似,78个结构上不相似数据集,见表2。

表2 数据集分布
采用标准指标对方法进行评估,即精度、召回率与F-measure方法作为映射方法的指标。T是由映射工具提供的非空映射,Te是由专家匹配器提供的非空映射。
Presicion:表示由映射工具产生的映射中正确映射的比例,式(9)。
(9)
Recall:表示由系统提取的正确映射的比例,式(10)。
(10)
F-measure:是建立在精度Presicion和召回率Recall上面的一个折衷,式(11)。
(11)
表2列出了结构与语义不同的4种数据集,将本文提出的SPM算法与已有的算法进行比较,结果如图4、表3所示。
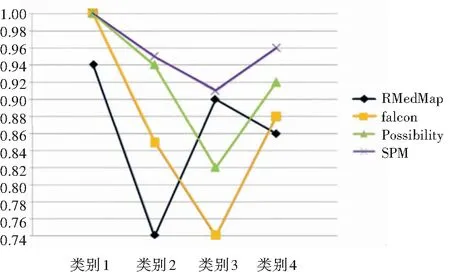
图4 不同方法的查准率比较
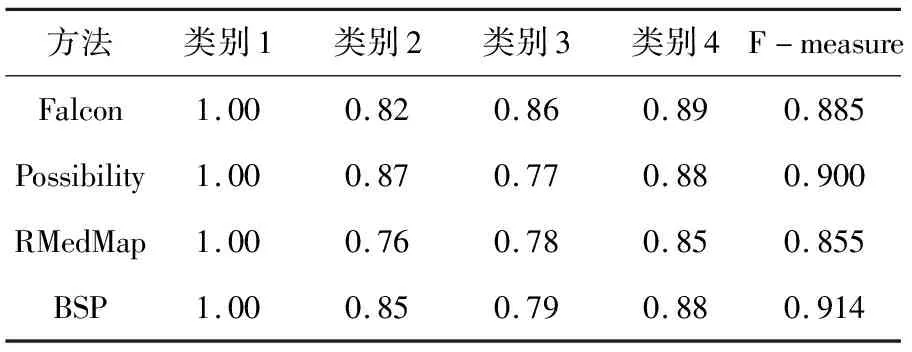
表3 查全率与F-measure方法比较
由上述结果对比可看出,对于词汇与结构都相似类别的数据集,在每一种方法中的映射效果都较好,Falcon、Possibility以及RMedMap方法得到的精度与召回率相对来说都比较高;对于F-measure综合指标,本文的映射方法能够比较好的得到较好精确的映射结果,综合评价效果较好。
对于类别2来说,本文的方法得到的精确率较高,在Recall方面,次于Possibility方法;查全率方面,本文的算法有待提高。对于类别3和类别4来说,精确度在这些方法中具有优势,召回率方面有待提高,从F-measure结果来看,SPM方法在精确度与召回率两个方面最好。
4 结束语
本文针对数据空间中动态的数据集成方式及数据空间平台上的不确定性映射问题,提出基于可能性理论的后映射方法,管理独立的源模式自动提供的可靠映射。本文的方法使系统自动管理包含在自动提供的映射中的所有可用信息,使用降序排序的方法,得到所有的可靠映射集合,在得到高可靠映射结果的同时得到了所有可用的信息,但在查全率上还有待提高。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年11期)2022-06-14
中学生数理化·高一版(2022年1期)2022-04-05
北京化工大学学报(自然科学版)(2022年1期)2022-03-13
建材发展导向(2021年19期)2021-12-06
现代计算机(2021年10期)2021-05-28
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
长江学术(2015年1期)2015-02-27
