
基于变量优选的苹果糖分含量近红外光谱检测
2021-11-18 07:51张立欣杨翠芳王亚明
食品与机械 2021年10期
张立欣 杨翠芳 陈 杰 王亚明 张 晓
(1.塔里木大学信息工程学院,新疆 阿拉尔 843300;2.南京理工大学理学院,江苏 南京 210094)
消费者在购买水果时,除了注重颜色、大小、形状等外部品质外,对内部品质口感也极为看重,其中糖分含量直接影响其口感。传统糖分含量的检测方法为破坏性或侵入性测量,不仅费时、费力,而且还破坏了水果的完整性。
近些年,近红外光谱(near infrared spectroscopy,NIR)分析技术因具有快速、便捷、无损的优点逐渐被用于农产品检测中,如苹果[1-2]、葡萄[3-4]、水蜜桃[5]、红提[6]、香梨[7]、滑皮金桔[8]等。在光谱分析中,经常会受到背景等随机因素的干扰,因此需对光谱数据进行预处理[9],常用的光谱预处理方法有一阶导数、二阶导数[10]、标准正态变换[11]、多元散射校正[12]、平滑变换[13]、标准化、归一化、中心化等。白铁成等[14]采用不同的预处理方法对南疆沙尘区骏枣叶片的光谱数据进行预处理,分析发现不同方法对散射噪声的处理能力存在差异。陈杰等[15]分别采用小波变换、多元散射校正以及二者结合的方法预处理数据,最后使用偏最小二乘法对3种方法预处理过的光谱数据建立羊肉水分含量的预测模型,结果表明,采用多元散射校正预处理方法建立的模型预测能力优于小波变换,采用2种结合的预处理方法建立的模型最优。为降低模型的复杂度,减少共线性的干扰,需要提取特征波段[16],常用的方法有连续投影算法[17]、竞争性自适应重加权算法[7]、主成分分析[18]、无信息变量消除法[19]、随机蛙跳算法[20]等,成甜甜等[21]分别采用随机青蛙、无信息变量消除法、竞争性自适应重加权法提取特征波长后建立偏最小二乘模型,结果显示模型预测效果整体提升。程介虹等[22]提出了一种改进联合区间的随机蛙跳算法选择特征波长,通过联合区间偏最小二乘法对全谱进行变量初选,此时得到的波长对目标变量变化最为敏感,将其作为随机蛙跳算法的初始变量子集,以解决其运行时间较长、效率较低的问题。袁凯等[23]采用3步混合策略,提出了间隔偏最小二乘、区间变量迭代空间收缩法和迭代保留信息变量联用的特征变量选择方法,对生鲜鸡胸肉的近红外光谱进行特征波长选择,建立了鸡肉水R分检测模型。结果表明,建模波长数量经3步选择后减少为全光谱建模的0.76%,但模型精确度和稳定性逐步提高。Fang等[7]将连续投影算法、竞争性自适应重加权算法、RELIEF 3种方法选取的特征变量组合起来建模,取得了很好的预测效果。在模型建立方面,有线性模型,如偏最小二乘回归[21],也有非线性模型,如神经网路[24]、随机森林[25]、迁移学习[26]、极限学习机[27]等。
尽管已有研究利用光谱技术和成分含量指标,取得了相对理想的预测效果,但是在对光谱数据进行分析时,一般只采用一种预处理方法,忽略了多种预处理方法相结合效果更优的可能性。选取特征波长变量时,一般只采取一种方法,或者多种方法串联起来,逐步减少特征变量的个数,虽然模型简化了,但是不同的波长选取方法各有侧重点,如果有重要的特征变量在某一步中漏掉,将永远不可能参与建模,影响模型的预测效果,而将多种特征变量组合起来建模的,目前鲜有报告。研究拟在总结前人研究的基础上,基于近红外光谱技术,以新疆阿克苏的红富士苹果为研究对象,依据光谱数据和糖分含量的实测数据,采取多种组合方式对光谱数据进行预处理,采用不同方法选取特征变量,以选出的特征变量的组合作为输入自变量,分别建立线性和非线性的糖分含量预测模型,重点研究不同的光谱预处理方法、特征变量和建模方法对预测结果的影响,以期为进一步研究糖分含量的便携式检测装置提供理论参考。
1 材料与方法
1.1 材料与仪器
1.1.1 材料
以阿克苏的红富士苹果为试验对象,在试验中所使用的苹果均产自红旗坡农场,挑选表面没有缺陷、直径范围为65~85 nm且大小均匀的苹果样品,去除表面的污垢,放置在冰柜内保存,控制在4 ℃,试验前分批拿出,待其恢复到室温(20~25 ℃)后开始试验。
1.1.2 主要仪器
糖度盐度两用仪:MASTER-BX/S28M型,日本ATAGO公司;
推扫式高光谱分选系统:Hyperspspectral Sorting System型,北京卓立汉光公司。
1.2 试验方法
光谱测定范围为900~1 700 nm(实际可测量到1 750 nm),光谱分辨率5 nm,光谱采样点4 nm。选取果身中心前后左右4个方位,提取大小为20像素×15像素,4个面均进行提取,共1 200像素点,选取平均值为该样本反射率。通过自带的ENVI5.3 软件提取ROI的光谱值,最后导出为Excel文件。选用糖度盐度两用仪,对苹果采集了高光谱图像的部位挖取适量果肉,深度为皮下0.5 cm左右,压榨出汁水进行糖度测量,测量3次取平均值,以此来作为苹果糖度的标准值。
1.3 数据预处理
采用的光谱数据预处理方法有一阶导数(1-DER)、二阶导数(2-DER)、标准正态变换(SNV)、多元散射校正(MSC)、SG平滑变换(SG)、标准化(STD)、最大最小归一化(MMN)、中心化(CEN)。
1.4 提取特征波长
主要采用连续投影算法(SPA)、竞争性自适应重加权算法(CARS)来选取特征波长变量。
1.5 建模方法
偏最小二乘回归法(PLS)集主成分分析、典型相关分析和多元线性回归分析3种分析方法的优点于一身,可以避免数据非正态分布、因子结构不确定性和模型不能识别等潜在问题。并且能较好地解决样本个数少于变量个数等问题,特别当各变量内部高度线性相关时,用偏最小二乘回归法更有效。
极限学习机(ELM)是一种简单易用、有效的单隐层前馈神经网络学习算法,不同于传统的训练算法(如BP算法等),ELM算法对输入层的权值和偏置进行随机赋值,然后用求Moore-Penrose广义逆矩阵的方法直接解出隐含层到输出层的权值。ELM算法需要手动设置的参数只有隐含层结点个数,算法执行过程中不需要人工调整参数,避免了传统训练算法反复迭代的过程,快速收敛,极大地减少了训练时间,所得解是唯一最优解,保证了网络的泛化性能。
1.6 模型验证
采用Kennard-Stone算法将数据集以3∶1的比例划分为训练集和测试集,依靠训练集建立模型,测试集将通过已经建立好的模型进行验证,以测试集的均方根误差(RMSE)、拟合优度(R2)作为标准来评判模型的优劣,计算公式:
(1)
(2)
式中:
RMSE——均方根误差;
R2——拟合优度;
n——样本个数;
yi——第i个样本的观测值;
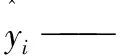
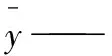
2 结果与分析
2.1 原始光谱分析
采集的红富士苹果高光谱数据中,剔除异常值后,共得到160个样本,其原始光谱曲线如图1所示。
近红外光主要是对含氢基团X—H(X为C、N、O)振动的倍频和合频吸收,其中包含了大多数类型有机化合物的组成和分子结构的信息。选用连续改变频率的近红外光照射某样品时,由于试样对不同频率近红外光的选择性吸收,通过试样后的近红外光线在某些波长范围内会变弱,透射出来的红外光线就携带有机物组分和结构的信息。从图1可以看出,950 nm附近处有一个明显的峰,这是O—H基团的3倍频吸收带,1 060 nm处的峰是N—H基团的3倍频带,1 180 nm处的波谷位于C—H的3倍频带,1 440 nm处的波谷是H2O 2倍频吸收带等。如果样品的组成相同,则其光谱也相同,反之亦然。因此,近红外光谱分析法是一种间接的分析技术。在对未知样本进行分析之前,需要获得样品的光谱数据和用化学分析方法测得糖分含量的真实数据,建立光谱和糖分含量的关联模型。如果建立了光谱与糖分含量的对应关系,那么只要测得样品的光谱,就能很快预测其糖分含量。采用KS算法,以3∶1的比例划分训练集和测试集,训练集用于建立光谱和糖分含量的关联模型,测试集用于检验模型。训练集和测试集的划分结果如表1所示。
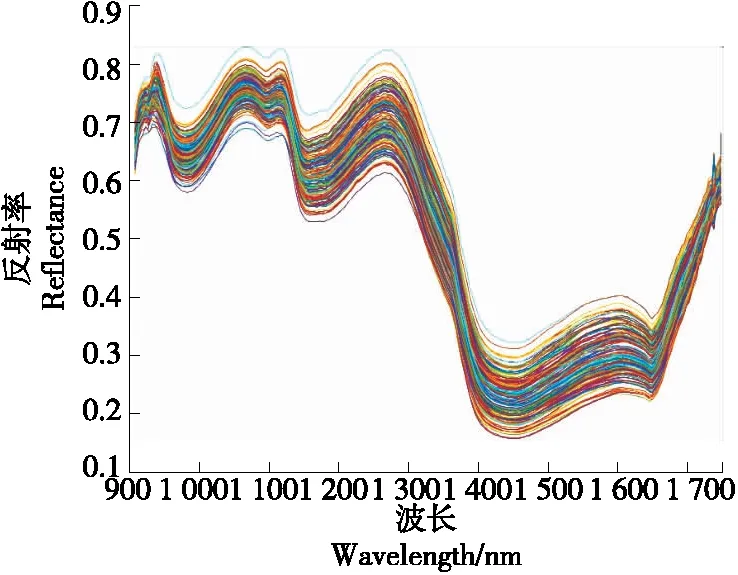
图1 原始光谱图
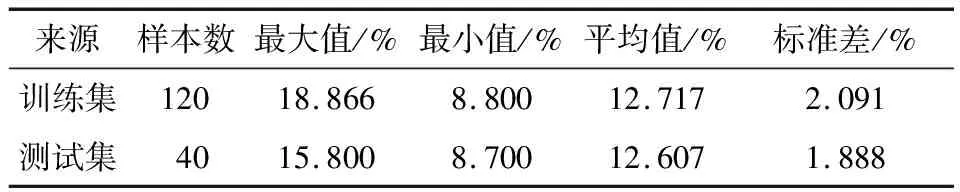
表1 训练集和测试集的划分结果
测试集和训练集的第一主成分、第二主成分分布如图2所示。
从图2可以看出,测试集的主成分都落在训练集的对应主成分范围之内,说明数据的划分是合理的。
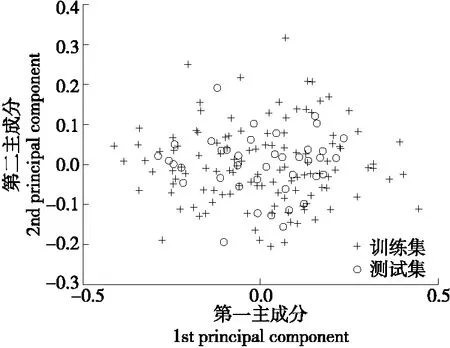
图2 训练集和测试集的主成分分布
2.2 光谱数据的预处理
在近红外光谱应用时,经常会受到背景等随机因素的干扰,因此需对光谱数据进行预处理。根据预处理的效果大致分为基线校正、散射校正、平滑处理和尺度缩放4类。每一类又包含多种预处理方法,基线校正包括一阶导数(1-DER)和二阶导数(2-DER)等,散射校正包括标准正态变换(SNV)和多元散射校正(MSC),平滑处理是SG平滑(SG),尺度缩放包括标准化(STD)、最大最小归一化(MMN)、中心化(CEN)等。对于光谱数据进行分析时,没有普适的预处理方法,通过对已有预处理方法按照预处理的目的进行分类再排列组合是选择最佳预处理方法的一种有效途径[9]。因此,对于每一类中包含的预处理方法进行for循环,按照表2从上到下的顺序一次从每类预处理方法中选择一种(0代表不作此类变换),共得到3×3×2×4=72种组合的预处理方法。

表2 预处理方法
原始光谱数据分别经过这72种方法预处理之后,建立PLS模型,交叉验证的均方根误差(RMSECV)和拟合优度如图3所示。
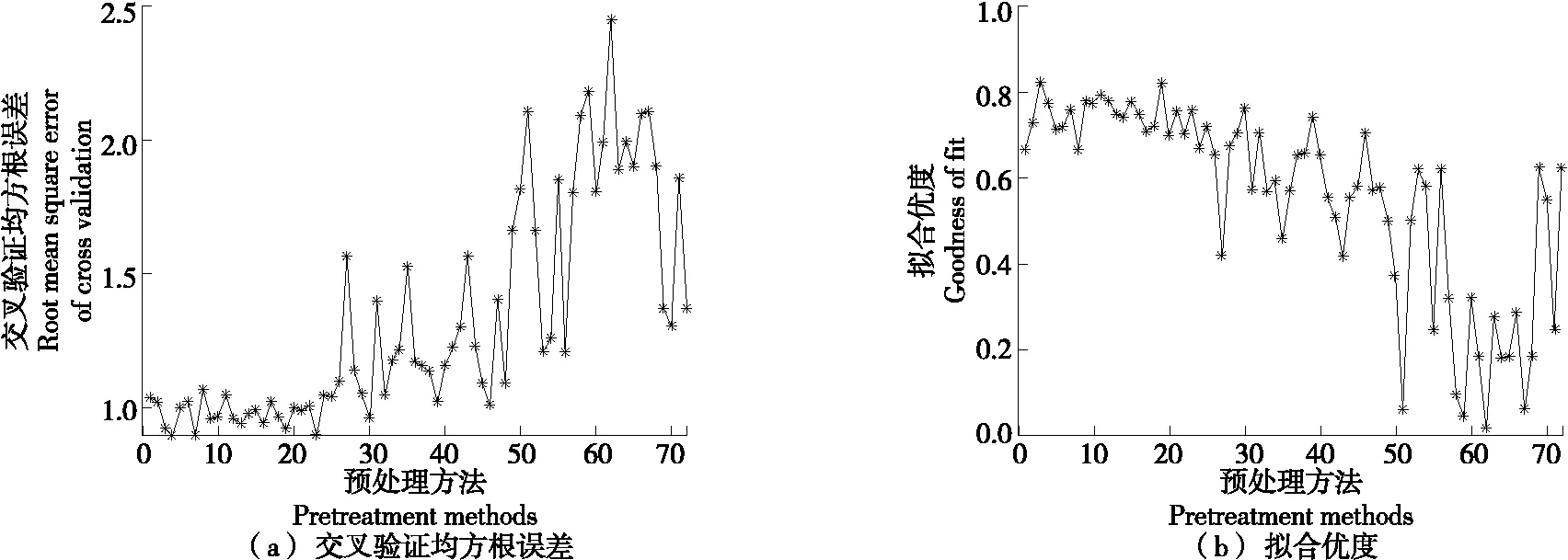
图3 不同预处理的预测效果
从图3可以看出,不同的预处理方法预测效果存在差异,刚开始,交叉验证的均方根误差有减小的趋势,拟合优度有增加的趋势;在第4种预处理到第26种预处理之间,交叉验证的均方根误差和拟合优度基本处于稳定状态;在第27种预处理方式到第62种预处理方式之间,交叉验证的均方根误差有波动上涨的趋势,拟合优度波动下降;从第63种预处理方式开始,交叉验证的均方根误差波动下降,拟合优度波动上升。这可能是由于在某些预处理过程中,波长变量的重要信息被屏蔽掉了,影响模型的预测效果。比较而言,第4种预处理方法对应的RMSECV最小,为0.898 9,拟合优度为0.772 2。为提高模型的预测效果,以下均采用第4种预处理方法,即中心化预处理方法。
2.3 特征波长选取
光谱能够体现所含物质的成分及含量,但也包含大量的冗余信息,在利用光谱数据分析之前,需要提取特征波长变量,以减少共线性的影响,提高模型的稳健性[16]。分别采用连续投影算法(SPA)、竞争性自适应重加权算法(CARS)提取特征变量。采用SPA算法进行变量选择,指定波长变量数为2~50,采用均方根误差最小来确定最终变量个数,变量选取过程如图4所示。
从图4可以看出,随着所选变量个数的增加,均方根误差有递减的趋势,当所选变量个数为7时,均方根误差为1.121 0,此后随着所选变量个数的增加,均方根误差并无明显减小反而有递增的趋势。这是由于过少的变量参与建模,遗漏掉重要的解释变量,导致模型的预测精度较低;过多的变量参与建模,又会引起变量之间的共线性。综合分析,选取出7个特征波长变量,对应波长为:911.06,932.90,1 065.87,1 110.91,1 385.35,1 612.63,1 665.41 nm。
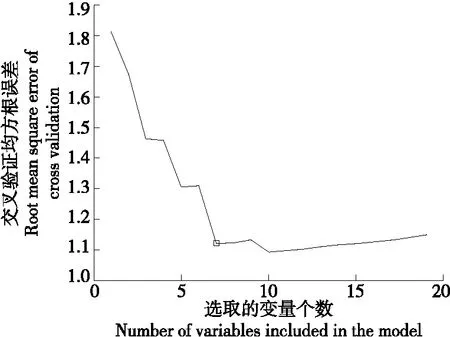
图4 变量的选取过程
采用CARS算法选择特征波长变量,迭代50次,以均方根误差最小来确定波长变量数,选取过程如图5所示。
从图5可以看出,随着迭代次数的增加,均方根误差呈先减小后增加的趋势,到第17次迭代时,均方根误差达到最小为0.831 4,此时选出的52个特征波长变量,对应波长为:1 049.87,1 053.06,1 059.46,1 062.66,1 069.07,1 078.70,1 136.81,1 140.05,1 143.30,1 153.06,1 156.31,1 159.57,1 162.83,1 166.09,1 169.35,1 172.61,1 175.88,1 179.15,1 195.51,1 248.20,1 268.08,1 375.21,1 378.59,1 422.67,1 426.08,1 429.48,1 432.89,1 436.30,1 511.78,1 518.68,1 522.14,1 598.63,1 602.13,1 605.63,1 609.13,1 612.63,1 616.14,1 619.64,1 623.15,1 626.66,1 630.18,1 644.25,1 647.77,1 651.29,1 654.82,1 661.87,1 676.01,1 679.55,1 683.09,1 690.17,1 697.27,1 700.82 nm。
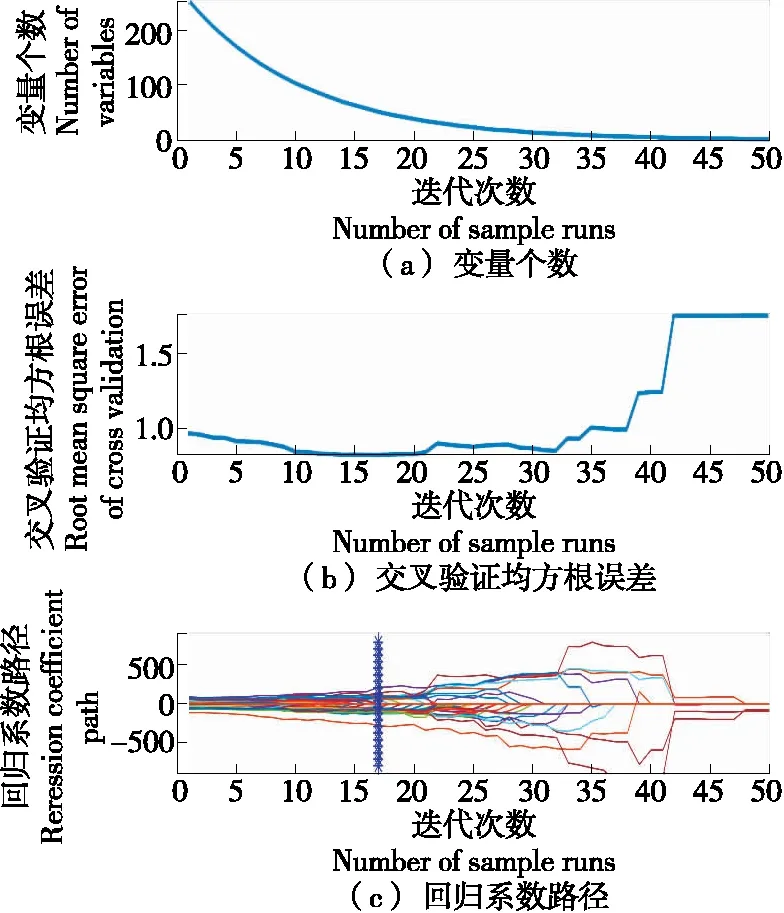
图5 变量选取结果
SPA和CARS两种方法选取的变量如图6所示。从图6可以看出,SPA和CARS方法选取的特征波长变量只有一个在1 069 nm处重合,其他波长变量并没有重合。SPA算法选出的911.06 nm特征波长,它位于C—H基团的4倍频吸收带附近,CARS算法选出的1 049.87,1 179.15,1 429.48 nm的特征波长分别位于N—H基团的3倍频、C—H的3倍频、O—H的2倍频吸收带附近。SPA算法和CARS算法都只是选出了部分与物质成分相关的变量,为了使波长变量更全面地反映物质的成分信息,考虑将两种方法选出的特征变量组合起来。
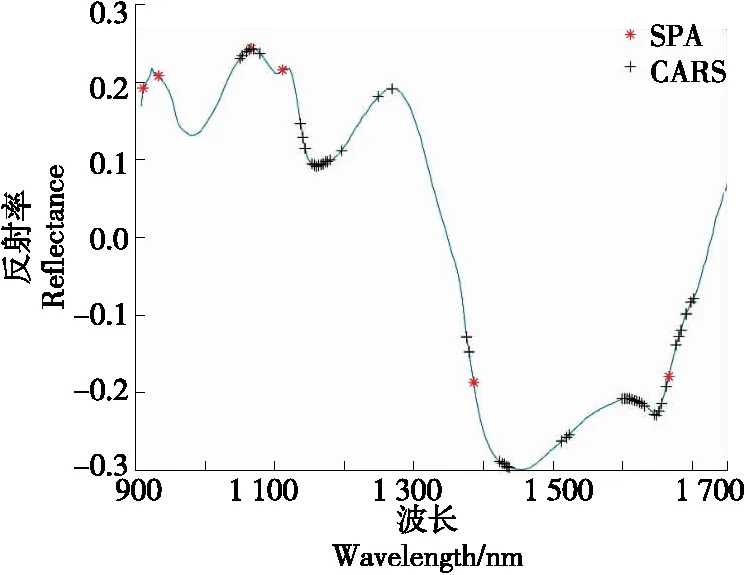
图6 选取的变量
2.4 模型建立
分别以SPA选出的7个特征波长变量、CARS选出的52个特征变量、两种方法选出的特征变量的组合共58个作为输入自变量(重合的特征波长变量只计算1次),分别建立线性模型和非线性模型。
线性模型选用经典的PLS模型,模型的预测效果如表3所示。从表3可以看出,将SPA和CARS方法选取的特征变量组合起来作为建模的输入自变量,比单一的一种方法选出的特征变量建模的精度高,这是因为不同的特征变量反映的物质内部品质结构不同,多特征变量组合参与建模,可以更全面地反映物质的组成结构。
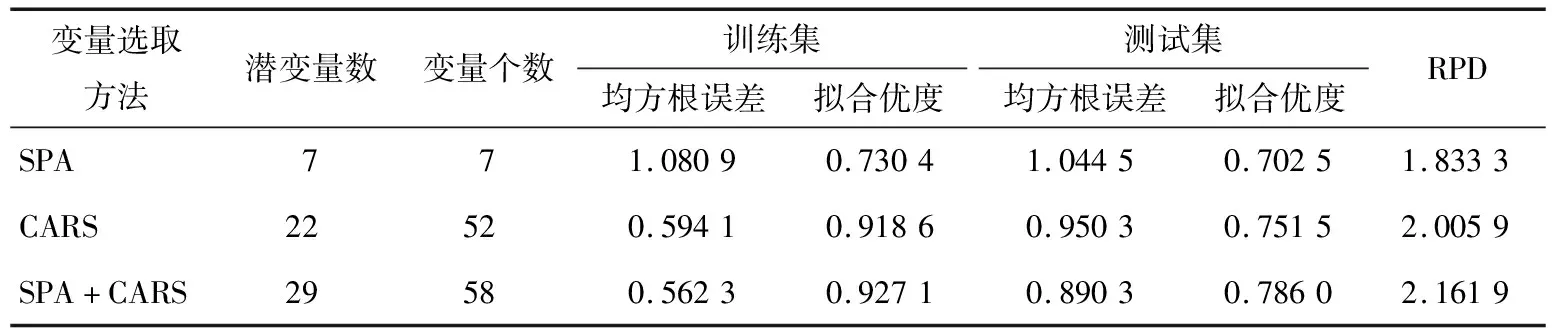
表3 PLS模型的预测结果
采用非线性的ELM算法建模,分别以SPA选出的特征变量、CARS选出的特征变量、组合的特征变量参与建模,选择sigmoid函数作为激活函数,通过反复尝试,隐含层节点数分别取30,23,33,模型的预测效果如图7所示。从图7可以看出,组合的特征变量建模效果优于单一方法选出的特征变量的建模效果。与表4进行比较,可以发现,同样的特征变量参与建模,ELM模型的预测精度更高,这是由于苹果内部的结构复杂,除了线性结构外,还有其他的非线性结构,因此,非线性的ELM模型预测效果优于线性的PLS模型。
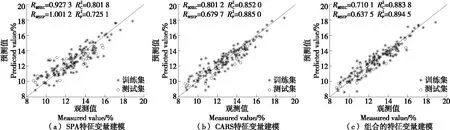
图7 ELM模型的预测结果
3 结论
对于中心化预处理之后的苹果光谱数据,将连续投影算法选出的特征变量和竞争性自适应重加权算法选出的特征变量组合起来,能够更全面地反映物质的成分信息,建模效果优于单一方法选出的特征变量的效果。同样的特征变量参与建模,非线性的模型比线性模型更能反映苹果内部的复杂结构。后续将研究多种方法选取特征变量,讨论对模型预测效果的影响。
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
环境技术(2022年1期)2022-03-21
阅读(科学探秘)(2021年8期)2021-09-01
潍坊学院学报(2020年2期)2021-01-18
照明工程学报(2020年1期)2020-06-16
照明工程学报(2020年1期)2020-06-16
飞天(2019年6期)2019-07-08
制导与引信(2017年3期)2017-11-02
新高考·高二数学(2015年2期)2015-05-27
海军航空大学学报(2015年4期)2015-02-27
