
基于多重指数移动平均评估的DDPG算法
2021-11-20 03:22范晶晶陈建平傅启明1悠1吴宏杰1
计算机工程与设计 2021年11期
范晶晶,陈建平,傅启明1,,4+,陆 悠1,,4,吴宏杰1,,4
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009;2.苏州科技大学 江苏省建筑智慧节能重点实验室,江苏 苏州 215009;3.苏州科技大学 苏州市移动网络技术与应用重点实验室,江苏 苏州 215009;4.苏州科技大学 苏州市虚拟现实智能交互及应用技术重点实验室,江苏 苏州 215009;5.珠海米枣智能科技有限公司 科研部,广东 珠海 519000)
0 引 言
近年来,强化学习(reinforcement learning,RL)在很多科学领域取得的成就较为显著。通常的讲,强化学习是一个智能体(Agent)与未知环境相交互,进而学习得出一种最优策略的方法[1]。强化学习可以分为3种方法,行动者方法、评论家方法、行动者-评论家方法。行动者方法通常利用策略梯度优化。评论家方法的核心为值函数逼近。而行动者-评论家方法则结合了两个方法的优点,评论家结构是值函数的近视函数,以最大化累积奖赏为目标指导行动者选取最优动作[2]。
深度强化学习(deep reinforcement learning,DRL)采用大型神经网络策略,通过值函数取代了经典的线性函数逼近器。并且深度强化学习在各类具有挑战性的问题上都有了成功的结果,例如Atari游戏、围棋问题和机器人控制任务等[3,4]。Minh等[5]提出深度Q网络(deep Q-network,DON)算法,该算法主要是结合了卷积神经网络以及强化学习,并引入经验回放技术解决了神经网络去拟合值函数导致训练结果不收敛的问题。然而DQN等算法仅在离散低维动作空间比较适用,而对于连续动作空间的问题很难适应。策略梯度是用来解决连续状态空间问题的基础,经过反复计算跟策略参数的梯度相关的策略期望的总回报,进而更新策略参数,达到策略的收敛。Silver等提出确定性策略梯度(deterministic policy gradient,DPG)算法,随机选择动作的依据为概率分布,而DPG算法则是直接学习输出动作,输出动作增加了确定性。然而DPG的适用范围不广,策略优化也有待提高,依据策略梯度的深度强化学习方法所优化的效果更佳。Lillicrap等[6]提出DDPG(deep deterministic policy gradient,DDPG)算法,更好解决了连续动作空间的问题,取得最优解的时间步也远少于DQN。陈建平等[7]针对DDPG算法需要大量数据样本的问题,提出了一种增强型深度确定策略梯度算法,提高了DDPG算法的收敛性。何丰恺等[8]优化DDPG算法并成功应用于选择顺应性装配机器臂。此外,张浩昱等[9]改进DDPG算法并应用在车辆控制上,体现了DDPG算法很好的控制前景。
本文针对DDPG算法网络结构的不稳定性以及单评论家评估不准确的问题,提出基于多重指数移动平均评估的DDPG算法,介绍一种EMA-Q网络和目标Q网络合作得出目标更新值,并针对DDPG训练过程中行动者的学习过于依赖评论家,对多个评论家给出的Q值求平均,这样多个独立的评论家网络可以充分在环境中进行学习,降低单个评论家的不准确性。实验结果表明,比传统的DDPG算法相比,基于多重指数移动平均评估的DDPG算法准确性更好,稳定性更高。样本池部分引入双重经验回放方法,采用两个样本池分别存储不同的经验,实验结果表明,改进后的算法求得最优解需要的时间步更少,收敛速度也有明显提升。
1 相关理论
1.1 强化学习
在强化学习中,一个智能体(Agent)在不同时间步与环境交互尽可能得到累积最大奖赏。强化学习问题可以以一个五元组的形式
(1)
其中,t为时间步,T为终止时间步,r(st,at) 为在状态st采取动作at所得到的回报。
寻找出最优策略是强化学习的关键,并在该策略基础上进行决策。在强化学习中,策略为π,π(s,a) 是指在状态s下选择动作a的概率。如果策略π是一个确定的策略,在任意状态s∈S,π(s) 表示在状态s下所选择的动作a。
强化学习中用来评估策略π的好坏的是值函数,由状态值函数Vπ、 动作值函数Qπ组成,Vπ(s) 表示在状态s下,根据策略π得到的期望回报,Qπ(s) 表示在状态s下,选择动作a并根据策略π得到的期望回报。通常用Qπ(s) 来评估策略π的好坏
(2)
式(2)为Bellman方程。
强化学习中π*表示最优策略,该策略能最大化奖赏函数,对应的Q*(s,a) 可以表示为
(3)
式(3)为最优Bellman方程。
1.2 DDPG算法
无模型强化学习方法可以不需要一个完整、准确的环境模型而直接学习得到最优策略。DDPG算法属于行动者-评论家方法的一种,是属于无模型、离策略的强化学习方法。
Deepmind提出DDPG,联合深度学习神经网络以及DPG,由此得到的更优的策略学习方法。在DPG的基础上,它的优点在于策略函数μ和Q函数分别用卷积神经网络去模拟,也就是策略网络和Q网络,后续用深度学习对上述神经网络进行训练,Q函数用的是Alpha Go同样的Q函数方法。
DDPG方法包含AC算法,经验回放,目标网络和确定性策略梯度理论,其主要贡献是证明了确定性策略μw的存在:S→A, 通过给agent一个状态得到一个确切的动作,而不是得到所有动作的概率分布。在DDPG中,性能目标定义为
(4)
ρπ(s) 代表状态分布,确定性策略的目标是
(5)
θ和w分别是评论家网络Q(st,at,θ) 和行动者网络μ(st,w) 的参数,在DDPG方法中分别用于逼近动作值函数和参与者函数,用于训练的经验取自于经验回放。经验回放通常是一个用来存储四元组 (st,at,rt,st+1) 的缓冲器,其中的一部分用于行动者和评论家网络的更新。当缓冲器容量满时,较新的经验会代替旧的经验,因此只有一小部分旧经验得到保留。另外,通过给训练过程一个目标,利用目标网络来更新评论家网络,目标网络的参数通常与评论家网络的参数一样。目标网络定义为Qtar, 损失函数定义为
Ltar(θ)=(r(st,at)+γQtar(st+1,at+1,θ-)-Q(st,at,θ))2
(6)
其中,θ-是先前迭代的参数,经验回放和目标网络对于稳定DDPG方法的训练过程具有重要意义,并且有利于深度神经网络的建立。
2 基于多重指数移动平均评估的DDPG算法
基于多重指数移动平均评估的DDPG算法针对DDPG算法双网络结构的不稳定性以及单评论家评估不准确的问题,介绍一种EMA-Q网络和目标Q网络合作得出目标更新值,并针对DDPG训练过程中行动者的学习过于依赖评论家,对多个评论家给出的Q值求平均,多个独立的评论家网络可以充分的在环境中进行学习,降低单个评论家的不准确性,提高算法稳定性。样本池部分引入双重经验回放方法,提高算法的收敛性能。
2.1 指数移动平均DQN
在DQN算法的基础上,平均DQN算法又做了进一步的改进。在平均DQN的训练过程中,目标Q网络对以前学习的K个Q网络求平均得到,而不是直接在一个固定长度的时间步后,直接从目标Q网络复制值。平均DQN通过降低目标近似误差(target approximation error,TAE)的方差来提高整个训练过程的稳定性。
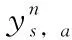
(7)
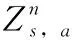
(8)
在平均DQN中
(9)
(10)
显而易见,平均DQN的性能随着值K的上升而提高,换句话说,要得到一个更好的策略需要更多的神经网络来存储参数,也意味着需要大量的内存。
为了处理需要过多的神经网络的需求,采取了式(11)中的递归形式,而不像平均DQN那样降低TAE的方差
(11)
并且与平均DQN的方差估计相比减小了一半[10]。
2.2 关于样本池的改进
优先经验回放的核心是频繁选取TD误差大的经验,以加快训练进程。然而,这要求必须在整个训练过程中掌握采样TD误差的概率,本文提出一种双重经验回放,使用两个经验池B1和B2来存储Agent的经验,其中B1和B2的工作方式相同,B2的大小为50,B1的大小为200,在双重经验回放中,非常好或者非常差的经验被视为具有高TD误差的经验,其中TD误差的公式为
φi=r(si,ai)+γQ′(si+1,μ′(si+1|θμ′)|θQ′)-Q(si,ai|θQ)
(12)
TD误差的阈值设置为0.4,当TD误差的值大于0.4时视为具有高TD误差,存储在B1和B2中,其它经验则存储在B1中。当进行采样时,从B1中采样40个样本,B2中10个样本,约占20%。随着训练过程的进行,Agent的学习的表现效果会更好,甚至取得最好的分数,因此B2中的经验不再具有高TD误差,对双重经验回放的需求随着训练过程的进行应该降低。
概率函数Pder用来表示从B2中采样的概率,随着时间的后移该概率随之降低,具体公式见下式
(13)
该步骤对训练过程的收敛至关重要,一个好的训练模型总是根据以前的成功经验进行更新,这可能会导致Agent在大部分状态具有较差的鲁棒性和灵活性。总之,使用概率函数能在训练前期加快训练过程,并且在模型趋于收敛时降低自身的作用,进一步加快收敛。
2.3 基于多重指数移动平均评估的DDPG算法
虽然DDPG在连续控制领域表现出了其优异的性能,但是稳定性方面仍然可以得到提高,在训练过程中,行动者的学习依赖于评论家,使得DDPG方法的训练对评论家学习的有效性过于敏感,为了进一步提高评论家网络的准确性,提出采取K个评论家求平均得
(14)
其中,θi表示第i个评论家的参数,该方法包含K个独立的评价网络,因此,当一个评论家为行动者提供指导时表现较差时(例如该评论家的估计值突然下降),多个评论家求平均会在一定程度上降低不良影响。并且,多个独立的评论家网络可以充分的在环境中进行学习。
有两种方法训练评论家网络,一种是利用评论家的平均值与目标评论家的平均值之间的误差(TD errors)
(15)
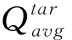
LMC(θi)=αLavg(θ)+βLtar(θi)+η(Qi(s,a,θi)-
Qavg(s,a,θ))2
(16)
其中,LMC(θi) 为平均评论家的损失函数平均值,α,β和η为权重,α,β和η都是0到1之间的浮点数,α和β加起来等于1,Lavg(θ) 为评论家网络的损失函数平均值,Ltar(θi) 为目标评论家网络的损失函数值。因为当K为1时,LMC应该等于Ltar, 即损失函数可以看作是3个两两相关部分的总和:两组评论家之间的全局平均误差、单个评论家和其对应的目标评论家之间的独立TD误差、用来减小评论家方差的单个评论家与K个评论家平均值的差值。
针对DDPG中的双网络结构的不稳定的问题,介绍一种EMA-Q网络和目标Q网络合作得到目标更新值,目标网络具体更新公式
θEMA←αθQavg+(1-α)θEMA
(17)
(18)
θμ′←βθμ+(1-β)θμ′
(19)
行动者网络的参数更新
(20)
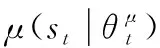
根据上述具体优化过程,下面给出基于多重指数移动平均评估的DDPG算法的流程,如算法1所示。
算法1:基于多重指数移动平均评估的DDPG算法
(1)随机初始化K个评论家网络Qi(s,a|θQi), 行动者网络μ(s|θμ) 及它们相对应的权重分别为θQi和θμ,i=0,1…k-1, 初始化EMA网络QEMA, 权重为θEMA←θQavg,K个目标评论家网络Q′i, 目标行动者网络μ′, 权重为θQ′i和θμ′,θQ′i←θQi,θμ′←θμ, 原始样本池B1, 高误差样本池B2初始为空,B2内存较小,时间步T
(2)while episode do
(3) 初始化一个随机过程Nt用于探索动作
(4) 获得初始观察状态s0
(5) while t=0,T do
(6) 根据当前策略和高斯噪声at=μ(st|θμ)+Nt选择动作
(7) 执行动作at, 得到rt,st+1
(8) 将 (st,at,rt,st+1) 存储在两个样本池B1,B2中
(9) 从样本池B1中随机采样一部分,B2随机采样一小部分,约占10%
(10) 通过最小化损失函数来更新每个评论家网络:LMC(θi)=αLavg(θ)+βLtar(θi)+η(Qi(s,a,θi)-Qavg(s,a,θ))2,Lavg(θ) 为评论家网络的损失函数平均值,Ltar(θi) 为目标评论家网络的损失函数值,LMC(θi) 为平均评论家的损失函数平均值。
(12) 更新目标网络的参数:
θEMA←mθQavg+(1-m)θEMAθQ′avg←nθQavg+(1-n)θQ′avg,θμ′←qθμ+(1-q)θμ′, 其中,θEMA,θQavg,θμ分别为EMA网络、评论家网络、策略网络的权重,m,n,q都是(0,1)之间的浮点数。
(13) end
(14)end
3 实验部分
为了验证基于多重指数移动平均评估的DDPG算法的有效性,本文将原始DDPG算法和基于多重指数移动平均评估的DDPG算法分别实验于经典的Pendulum问题和MountainCar问题,实验环境为OpenAI gym,为一个开源的仿真平台。OpenAI Gym是开发和比较强化学习算法的工具包。OpenAI Gym由两部分组成:①gym开源库:gym开源库为用于强化学习算法开发环境,环境有共享接口,用于设计通用的算法;②OpenAI Gym服务:用于对训练的算法进行性能比较。
3.1 实验描述
3.1.1 MountainCar 问题
在MountainCar问题中,一辆小车沿着一维轨道行驶,停在了两座小山之间,小车企图到达较高的一座山上,然而由于其动力不足不能直接到达山顶,而是需要来回行驶获取更多的动能,才能到达山顶。如果消耗的能量越少,则回报值越大。图1给出了Mountain Car问题。
图1 Mountain Car
状态为2维状态,分别通过位置、速度来表示,可以表示为:s=(p,v), 其中p∈[-1.2,0.6],v∈[-0.07,0.07], 动作为1维动作,有3个能够选择的动作:向左加速,向右加速,不加速,分别用+1,-1,0表示,即动作a={-1,0,+1}。 一开始,会随机地给小车一个位置以及速度,小车来回行使的过程中不断学习。当小车到山顶之后(“星”形标记处),或者是当时间步超1500时,情节会立即结束,重新开始另一个情节。
3.1.2 Pendulum问题
倒立摆是控制方面中的经典问题,钟摆从一个随机的位置开始,通过施加一个力(作用力的范围是[-2,2]),Agent的主要任务为学习到一个最优的策略,使它先摆动起来,最终保持钟摆直立。图2给出了Pendulum问题。

图2 Pendulum
状态为3维状态,钟摆的位置代表其中的2维,速度代表另一维。具体可以表示为:s=(cosθ,sinθ,v), 其中θ∈[-1,1],v∈[-8,8], 动作为1维动作,代表了对钟摆所施加的力,具体可以表示为:a∈[-2,+2]
3.2 实验设置
实验运行硬件环境为Inter(R) Xeon(R) CPU E5-2660处理器、NVIDIA Geforce GTX 1060显卡、16 GB内存;软件环境为Windows 10操作系统、python 3.5、TensorFlow_GPU-1.4.0。
对于每个实验,一些实验参数是固定的。使用Adam 优化器对神经网络的参数进行优化,行动者网络和评论家网络的学习率分别为2×10-5、 2×10-4, 折扣率为0.99。目标网络的更新参数为0.01,在探索过程中,方差为0.2的零均值高斯噪声被加进行动中。对于每个训练过程包含300个情节,每个情节有15次循环,每个循环中有100个时间步。批处理固定值为64,经验回放缓冲器是长度为105的循环队列。在DDPG中,行动者及评论家网络均含有两个隐藏层(128个单元),在基于多重指数移动平均评估的DDPG算法中,参数α,β,η分别设置为0.6、0.4、0.05,评论家的个数设置为5。
3.3 实验结果分析
DDPG算法和指数移动平均的DDPG算法以及基于多重指数移动平均评估的DDPG算法在Mountain Car和Pendulum环境中实验,实验结果在本部分详细说明,并进一步客观地分析实验结果。
为了评估评论家的可靠性和稳定性,采用平均回报值进行评估。在DDPG方法、指数移动平均的DDPG方法及基于多重指数移动平均评估的DDPG方法中,agent与独立环境交互,得到每7个周期的10条路径的平均奖赏作为性能的评估,损失函数的值显示了整个训练过程的收敛性。
DDPG算法、指数移动平均的DDPG算法以及基于多重指数移动平均评估的DDPG算法分别在Pendulum、Mountain Car环境中进行实验,对于图中的实验结果,在两个实验中,平均回报值增加然后收敛,损失函数随着训练进程的加快直至结束逐渐趋向于0,如图3(a)、图3(b)所示,由指数移动平均的DDPG算法获得的平均回报值在大部分情节远大于原始DDPG算法所获得的平均回报值,而加入多评论家的指数移动平均的DDPG算法获得的平均回报值比指数移动平均的DDPG方法更大,此外,从图3(a)、图3(b)中两幅图可以很明显看出,与原始DDPG算法和指数移动平均的DDPG算法相比,基于多重指数移动平均评估的DDPG算法的平均回报值变化范围最小,因此,基于多重指数移动平均评估的DDPG算法的稳定性和有效性得到了有效的验证。此外,基于多重指数移动平均评估的DDPG算法中平均回报值突然下降较少且很快回归正常。在Mountain Car环境中,尽管3种方法的奖赏很相似,但是可以看出在整个路径中基于多重指数移动平均评估的DDPG算法大部分情节不存在奖赏的突然下降。图4(a)、图4(b)所示的平均损失函数也相当不同,从实验结果可以明显看出,基于多重指数移动平均评估的DDPG算法的损失函数值相比指数移动平均的DDPG算法更小,且随着训练进程的加快更快的趋向于0,验证了基于多重指数移动平均评估的DDPG算法的收敛性能更好。
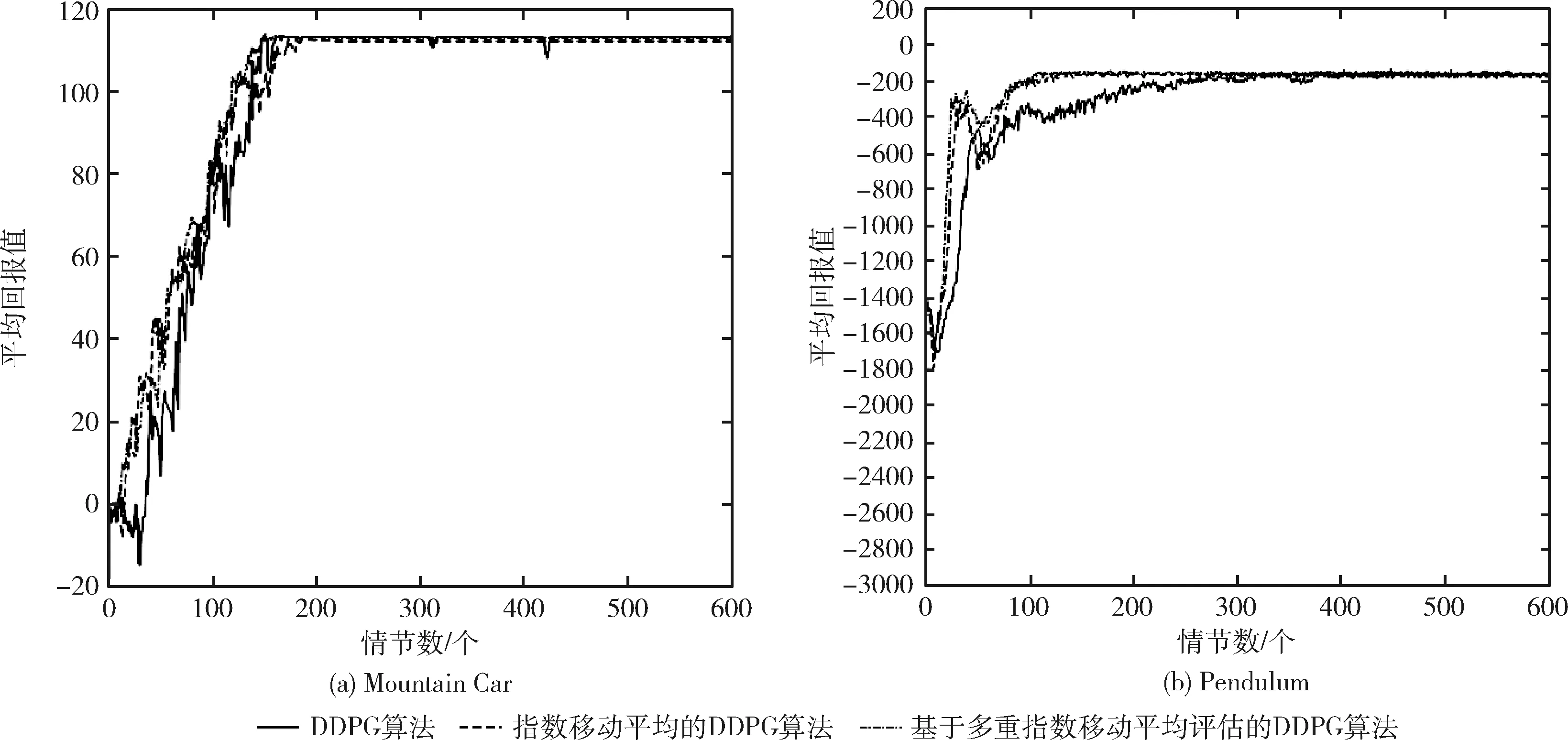
图3 3种算法的平均回报值实验对比
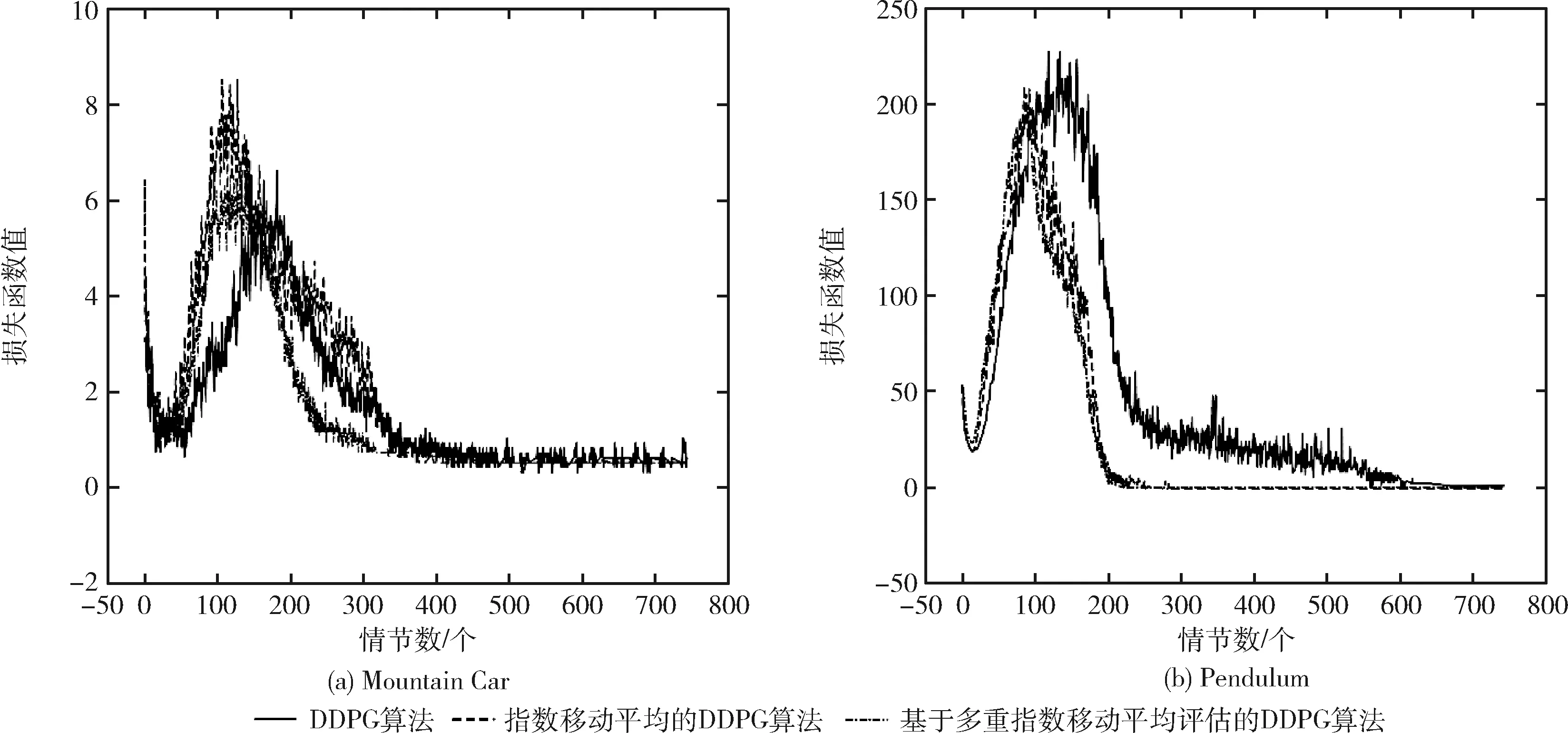
图4 3种算法的损失函数值实验对比
对于双重经验回放部分,我们将DDPG算法与加入双重经验回放的DDPG算法在Pendulum实验中测试了这部分改进内容。如图5所示,黑色的虚线部分代表了收敛的近
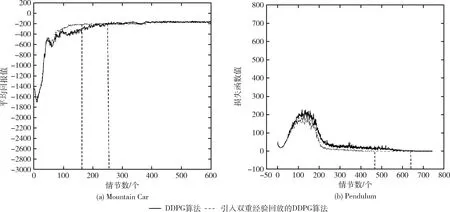
图5 Pendulum问题中DDPG算法是否引入双重经验回放的实验对比
似时间,由图5(a)中,可以看出引入双重经验回放的DDPG算法在160个情节处逐渐收敛,而原始DDPG算法的收敛时间大致在250个情节,图5(b)中可以看出引入双重经验回放的DDPG算法大致在470个情节收敛,而未引入双重经验回放的DDPG算法在630个情节收敛,因此由实验结果可以明显可见双重经验回放确实加快了训练的过程。
4 结束语
本文针对DDPG算法双网络结构的不稳定性以及单评论家评估不准确的问题,提出基于多重指数移动平均评估的DDPG算法,介绍一种EMA-Q网络和目标Q网络合作得出目标更新值,并针对DDPG训练过程中行动者的学习过于依赖评论家,对多个评论家给出的Q值求平均,多个独立的评论家网络可以充分的在环境中进行学习,降低单个评论家的不准确性。样本池部分引入双重经验回放方法,提高算法的收敛性能,实验结果表明,比传统的DDPG算法相比,基于多重指数移动平均评估的DDPG算法的收敛性能更好,稳定性更高。
本文主要针对Pendulum和Mountain Car两个实验验证基于多重指数移动平均评估的DDPG算法的性能,从实验结果可以看出,基于多重指数移动平均评估的DDPG算法的收敛性更好,稳定性更高。但是算法中的超参数的设置均为人工设置,因此在未来的工作中将重在调整损失函数的参数为可训练的变量,使得算法收敛性更好,稳定性也有所提升。
猜你喜欢
贵州社会科学(2022年8期)2022-10-12
网络文学评论(2022年4期)2022-08-11
中国音乐(2022年3期)2022-06-10
党课参考(2021年20期)2021-11-04
鸭绿江(2020年29期)2020-11-15
火花(2019年8期)2019-08-28
小哥白尼(军事科学)(2019年6期)2019-03-14
党课参考(2018年20期)2018-11-09
绿色中国(2016年1期)2016-06-05
新闻传播(2015年3期)2015-07-12
