
面向科技人物简历的信息抽取方法
2021-11-20 01:56杨永秀蔡东风何佳蔚
计算机工程与设计 2021年11期
杨永秀,白 宇,蔡东风,何佳蔚
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引 言
专家信息推送是企业信息服务的重要内容。知识图谱能够有效整合多源异构数据,具备快速检索的优点[1],是实现专家信息推送的有效方法。为构建科技人物图谱,需要从非结构化的科技人物简历中提取出人物相关信息。
现阶段对非结构化文本的信息抽取通常转化为序列标注任务,主要以基于循环神经网络(recurrent neural network,RNN)的深度学习方法为主。该方法有基于字和基于词两种,均难以同时具备语义信息丰富度高与未登录词数量少的优点,现有方法多将运算后的字特征与词特征融合作为新词特征[2,3],不能完全保留字特征的语义,融合过程中字特征对新特征贡献较少。现有信息抽取方法多使用基于深度学习及条件随机场(conditional random fields,CRF)的序列标注模型[4-7],对训练集中分布较少的句式特征拟合困难。为此有人将序列标注模型与分类模型结合用于信息抽取任务[8,9],然而分类模型难以学习前后文特征分布与标签约束,现有结合方法使分类模型整体贡献度较低,并没有发挥出模型的优势,不能弥补序列标注模型的特征选择偏差。目前将两类模型结合用于文本信息抽取的文献相对较少。
基于上述问题,本文提出以下两种解决方案:
(1)为全面保留文本语义信息,有效表达科技人物简历中的领域术语,采用面向研究领域专业术语的字词协同表示方法以提高简历文本的表达能力,使用双向长短时记忆网络(long short term memory,LSTM)结合CRF模型完成对简历文本的标注,该方法有效减少了未登录词的数量且保证了文本信息丰富度。
(2)针对现有的信息抽取模型难以捕捉科技人物简历中特殊句式及信息间关联关系,存在学习经历识别偏好的问题。提出将梯度提升决策树(gradient boosting decision tree,GBDT)[10]模型用于学习经历和工作经历所包含的时间及单位信息的分类矫正方法。
1 科技人物简历信息抽取
科技人物简历信息的抽取对文本特征表达的质量要求较高,本文提出字词协同的文本表达方法以全面表征科技人物简历的语义信息。考虑到简历信息抽取过程中的长距离依赖性[11],将双向LSTM-CRF的模型对简历文本进行建模,即利用双向LSTM提取字词协同表达文本特征,输出标签概率,通过CRF层引入标签约束,寻找最优标签序列。科技人物简历中描述工作经历与时间经历的语言结构相似,现有序列标注模型未能获取到学习经历与工作经历的前后文特征差异。因此本文提出使用GBDT算法对工作经历与时间经历中的时间和单位信息再分类,为了节约训练时间成本在深度学习的识别结果的基础上,对每个待分类项提取文本特征最后使用GBDT算法重新区分它们所属的经历类别。本文整体任务流程,如图1所示。

图1 科技人物简历信息抽取流程
2 面向领域术语的字词协同表达方法
本文所使用的科技人物简历来源丰富,研究领域信息中,常见不同领域的专业术语,其中不乏部分中英文、标点符号混合词汇,如“桑蒂苷”、“诃子”、“POP原子钟”等。现有的文本表达方法未能有效表达上述领域术语,导致模型对研究领域信息识别困难。表1为科技人物简历中多语种混合信息的数量以及包含专业术语的研究领域信息数量占研究领域信息总数量的比重。

表1 关于研究领域信息的统计结果
图2为研究领域信息所涉及的不同学科及其分布情况,具体展示了前20个占比较多的学科。

图2 研究领域信息中所涉及的学科及其分布情况
基于上述情况由于文中一词多义现象较多,为了充分保留语义信息,采用基于字词协同的双向LSTM结合CRF的序列标注模型对文本特征进行提取得到序列化标签。模型整体结构如图3所示。
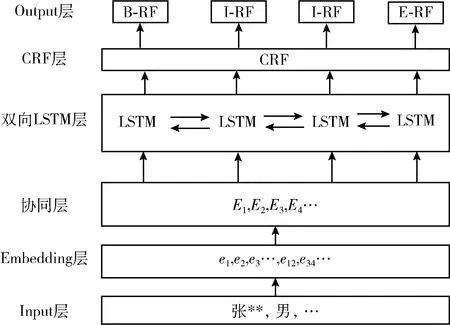
图3 字词协同序列标注整体模型框架
2.1 双向LSTM-CRF模型
相比于传统的Elman-RNN和Jordan-RNN[12],LSTM更加具备处理长距离依赖问题的优势,缓解了RNN训练过程中的梯度爆炸和梯度消失问题。在序列标注任务中,多采用CRF层取代双向LSTM的softmax输出层,其中双向LSTM并不会直接输出模型预测的标签,而是将待标记对象对应所有备选标签的概率输出至CRF层,采用全局归一化的方法,在整个句子级别进行建模。有效解决了原有模型的标记偏置问题。模型结构如图4所示。

图4 双向LSTM-CRF模型
对于给定一条非结构化文本序列
X=(X1,X2,X3…Xn)
(1)
假设其所对应的标签序列即网络输出的目标序列为
y=(y1,y2,y3…yn)
(2)
则双向LSTM层的输出分值由以下公式得出
(3)
其中,A代表转移分数矩阵,P代表双向LSTM层输出的分数矩阵。对于给定的文本序列X, 整个网络得到的目标序列y的概率为
(4)
其中,YX代表句子X的所有可能标签序列,在训练过程中使得正确序列的对数概率最大化

(5)
最后根据式(6)进行解码得到最终的预测标签
(6)
2.2 字词协同表示方法
由于本文的科技人物来自不同的领域,语料中涉及多学科的专业知识,为了避免出现更多的未登录词,与Zhang等[13]提出的Lattice LSTM对字词特征结合的方法不同,本文并没有利用所有潜在的词特征,而是首先选取了置信度较高的分词结果,采用更加细粒度的方式利用词特征补充字特征的方式,以加强对该字的重新表达,字词协同方法如图5所示。

图5 字词协同
如图5所示,例如句子“微波遥感”常被分词为“微波”和“遥感”,在预训练词向量模型中,得到的输出e1,2和e3,4分别代表“微波”和“遥感”,而在预训练字向量中得到的输出e1,e2,e3,e4分别代表“微”、“波”、“遥”、“感”。而后将6个向量进行联合拼接以得到对这4个字重新表达的强特征向量,具体公式如下所示
E1=e1+e1,2
(7)
E2=e2+e1,2
(8)
E3=e3+e3,4
(9)
E4=e4+e3,4
(10)
最后将字词协同特征向量送入模型中训练得到最终的输出结果。
3 基于GBDT的分类矫正
大部分科技人物简历中会首先描述作者教育背景,导致模型对学习时间及学习经历识别有所偏好。如例1中所示模型错误地将该信息识别为学习单位。对于工作时间和工作单位来说,如例2所示,简历中常见“毕业后进入……工作的表达”此类信息往往紧随某段学习经历后,现有模型难以捕捉该句式特点,在例2中错误地将该信息识别为学习经历。针对以上问题,提出基于机器学习的分类方法对时间和单位信息再矫正。其中GBDT通过残差学习,利用前一轮学习器的误差实现小梯度样本的正确划分,对不常见及一些极端样本处理能力较强。张春祥等[14]将该方法用于词义消歧任务;封化民等[15]将GBDT用于网络入侵检测;刘金元等[16]将GBDT算法用于航班延误分析。因此,本文提出基于GBDT的简历信息再分类方法,以序列标注模型识别出的学习时间、学习单位、工作时间、工作单位4类信息,作为最小分类单位,提取待分类对象的语言学特征,使用GBDT判断该信息所属经历类别。
例1:江**,男,中科院半导体所研究员。
例2:毕业后进入中科院山西煤炭所工作。
3.1 特征提取
本文提取科技人物简历中信息之间的关联关系、分类对象的前后文是否具备特定语言格式、科技人物简历中是否具备关键词信息3项作为待分类对象特征。表2为本文所采用的特征说明。

表2 特征提取说明
对于某待提取对象,首先寻找其所在简历是否出现相关经历关键词,以该信息距离最近的关键词为准。然后针对
待抽取对象寻找其所在的分句,并在分句内查找关联信息,判断是否具备特定语言格式。具体提取流程见表3。

表3 特征提取流程
3.2 GBDT分类算法
分类决策树是一种以树状图为基础的对实例进行分类的有监督机器学习算法。常用的生成算法有ID3、C4.5、CART。梯度提升决策树算法的实质是以决策树为基函数的提升算法,在训练过程中采用残差拟合的方式,首先选择梯度大的样本计算信息增益[17]。当达到预设的迭代次数或剩余样本梯度足够小不需再去拟合时结束。最后以累加的方式得到最终的结论。训练过程中第M棵决策树如式(11)所示
(11)
其中,M代表决策树个数;Φm代表决策树参数;T(x;Φm) 是决策树。具体训练过程如下:
(1)初始化提升树
F0(x)=0
(12)
(2)采用向前分布算法,得到第m步的模型为
Fm(x)=Fm-1(x)+T(x;Φm)
(13)
(3)利用经验风险最小化来计算下一步参数Φm
(14)
(4)其中L为损失函数采用平方误差损失函数计算,如式(15)所示
L[y,F(x)]=[y,F(x)]2=
[y-Fm-1(x)-T(xi;Φm)]2
(15)
4 实验结果及分析
本文所使用的简历文本是从多家研究所及高校的科研人员主页中获取的非结构化的简历文本共3000条,每条包含150至700个汉字,16种待抽取信息共64 379个标注项。按照7∶1∶2分为训练集、验证集和测试集。图6为各项信息分布及所含标注项数量。

图6 各项信息分布及所含标注数量
4.1 评价标准
本文采用精确率(P)、召回率(R)和F1值作为评价指标。在测试过程中,只有当一个信息的边界和信息类型都完全正确时,才认为该信息识别正确。评价标准具体定义如下
(16)
(17)
(18)
其中,Tp为模型识别正确的信息个数,FP为模型识别出的不正确的信息个数,FN为模型未识别到的正确信息个数。
4.2 实验结果及分析
本节将设置科技人物简历中研究领域信息抽取实验,选择在总体抽取结果以及研究领域抽取结果表现较好的序列标注模型以支持下一步对时间和单位分类矫正的实验。最后将会给出最终模型对所有信息的抽取结果并针对实验结果予以分析。
4.2.1 研究领域信息抽取方法对比
研究领域信息结果见表4,表4展示了本文所使用的基于字词协同的信息抽取方法及现有其他方法对研究领域信息的抽取结果。表4中所有的模型若涉及到LSTM均使用一层双向LSTM,且双向LSTM层节点数均设置为120,模型迭代次数均为30次,训练过程中使用Dropout算法[18]防止过拟合。
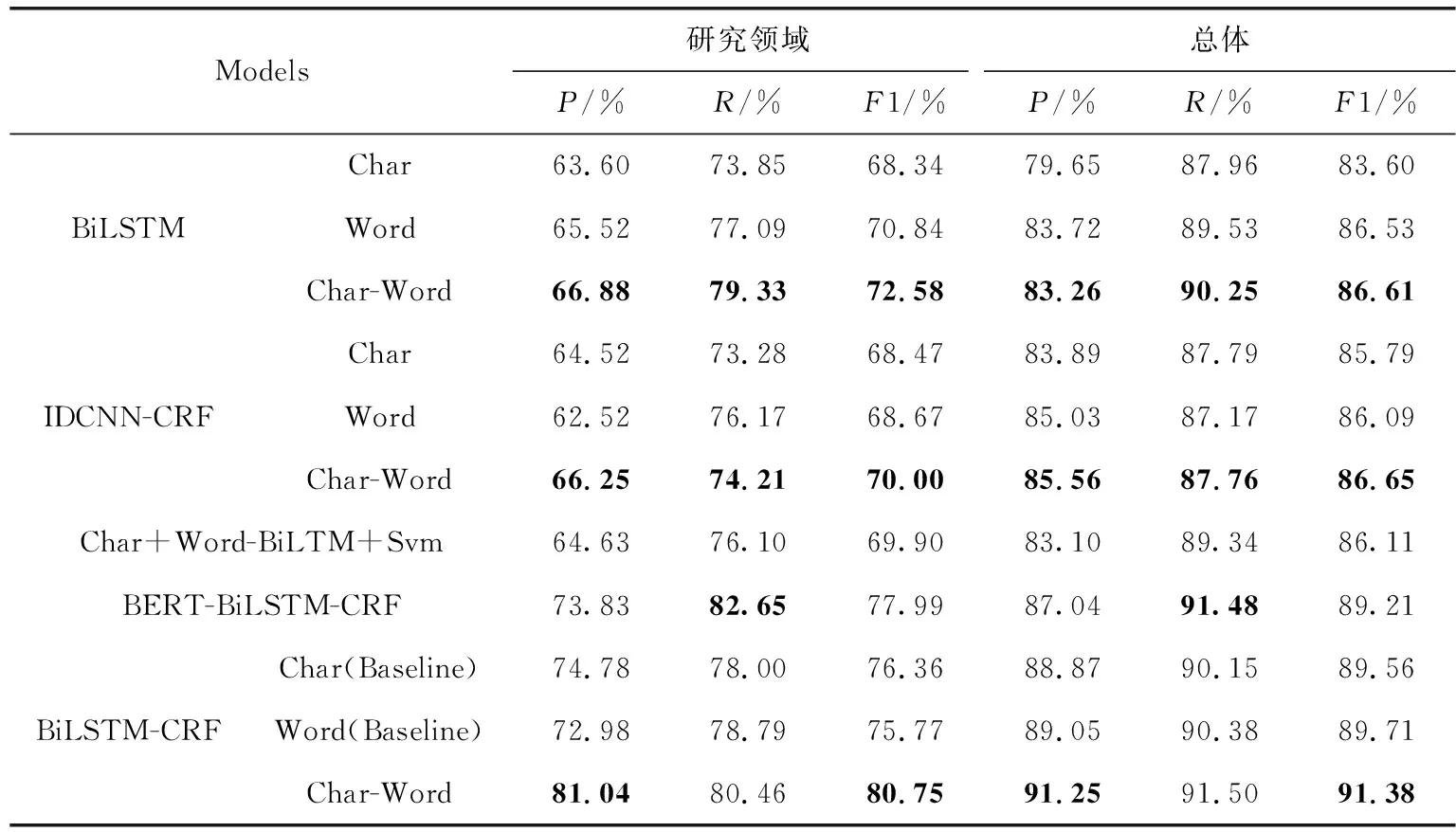
表4 序列标注模型抽取结果对比
根据表4中各模型对研究领域信息抽取的精确率、召回率和F1值可以看出,基于字词协同的文本表达方法能够有效提高模型对研究领域信息的识别性能。相比于Strubell等[19]和Huang Z等[20]提出的方法本文所采用的模型照比基于字和基于词的双向LSTM-CRF模型对研究领域信息识别的F1值分别提升了4.39%和4.98%。在总体的抽取结果上分别提升了1.82%和1.67%。本文还与殷章志等[8]中提出的字词模型融合方法做了对比,实验结果表明本文的字词协同方法更适合对科技人物简历信息进行抽取。而Devlin等[21]提出的BERT动态文本表达方法,由于其中的遮挡语言模型会随机掩盖住文本中15%的单词。为了减少这种随机遮挡所带来的负面影响,BERT对训练数据规模要求较高,由于本文中使用的数据规模有限,因此很难达到期望的效果。该模型虽然获得了最高的召回率但是在精确率以及F1值上照比本文提出的方法表现较差。
4.2.2 分类矫正方法对比
在上述的实验中,已经获得了在研究领域以及总体抽取结果上最优的序列标注模型。接下来针对上述序列标注模型对学习时间、学习单位、工作时间、工作单位分类混淆的问题,为了使GBDT更有针对性,对易分类混淆的信息进行区分,同时节约训练过程的时间成本,在原有序列标注模型识别基础上只针对以上4类提取特征重新区分它们所属经历类别,至于其它错误暂不予修正。在这部分实验中设置了同等数据条件下决策树算法、KNN(K-nearest neighbor,KNN)算法以及使用RBF核函数的支持向量机算法(support vector machine,SVM)与本文提出的基于GBDT分类算法进行对比。实验中GBDT模型的学习率设置为0.5、迭代次数设置为20、树的最大深度设置为5。决策树模型的最大深度同样设置为5,SVM的惩罚系数设置为1,KNN模型的K近临数设置为4。以基于字词协同的双向LSTM-CRF模型为该部分实验的基线模型,分类实验结果见表5。

表5 分类实验结果
实验结果可以看出使用机器学习的分类算法均能在原有序列标注模型分类的基础上提高两种时间和单位信息的分类正确率。其中本文所提出的基于GBDT的分类方法照比基于字词协同的双向LSTM-CRF对工作时间、工作单位、学习时间、学习单位识别的F1值分别提升了1.29%、1.26%、1.97%、2.03%。其中对学习时间和学习单位识别的精确率提升了3.34%和3.16%,对工作时间和工作单位识别的召回率同样提升了2.4%和2.26%。说明基于GBDT的再分类方法一定程度上解决了基于字词协同的双向LSTM-CRF模型对学习时间和学习单位的分类偏好问题。其中KNN模型的分类性能相对较差,这是因为KNN模型通过计算样本之间的距离来进行决策,随着数据维度的增加,一些不常见的特征样本并没有出现在观测点附近,导致模型预测精度稍差。而基于决策树和SVM的分类方法,虽然具备相对较高的鲁棒性,但仍然不能处理一些极端样本。当样本特征中有两个值分别指向不同的类别,而
另一个特征态度不明确时,模型很难进行判断。相比而言,GBDT算法可以通过增加决策树的数量来减少模型的偏差[22],通过多个分类器的集成,增加了模型的多样性,更好地容忍训练集中的样本偏差具备更强的泛化能力,对极端样本的处理能力更强。
4.2.3 实验结果分析及最终抽取结果
以黄胜等[11]所提出的双向LSTM-CRF模型为例,以下是基于字、基于词以及基于字词协同方法的对比实例。
例3:从事年轻双星/多重星高分辨率观测研究。
字特征:轻双星/多重星高分辨率观测
词特征:年轻双星/多重星高分辨率观测
字词协同特征:年轻双星/多重星高分辨率观测
例4:研究重点是非粮植物菊芋的综合开发。
字特征:非粮植物菊芋的综合开发
词特征:是非粮植物菊芋的综合开发
字词协同特征:非粮植物菊芋的综合开发
由上例可以看出,基于字词协同的抽取方法能够结合字特征以及词特征的优点,在基于字特征和基于词特征的方法一个识别正确,而另一个识别错误的情况下能够进行修正。
针对部分信息分类混淆的问题,以基于字词协同的双向LSTM-CRF的序列标注模型为基础,下面是一个具体的分类实例。
例5:王**,现为中科院半导体所研究员。
序列标注:学习单位
GBDT:工作单位
例6:1996~1999,助教,桂林电子科技大学
序列标注:学习时间
GBDT:工作时间
由上例可以看出使用GBDT再分类的方法能够有效缓解序列标注模型对学习时间、学习单位、工作时间、工作单位的分类偏差,充分验证本文所提方法更适合对科技人物简历信息进行抽取。表6是基于GBDT矫正的字词协同科技人物简历信息抽取结果。
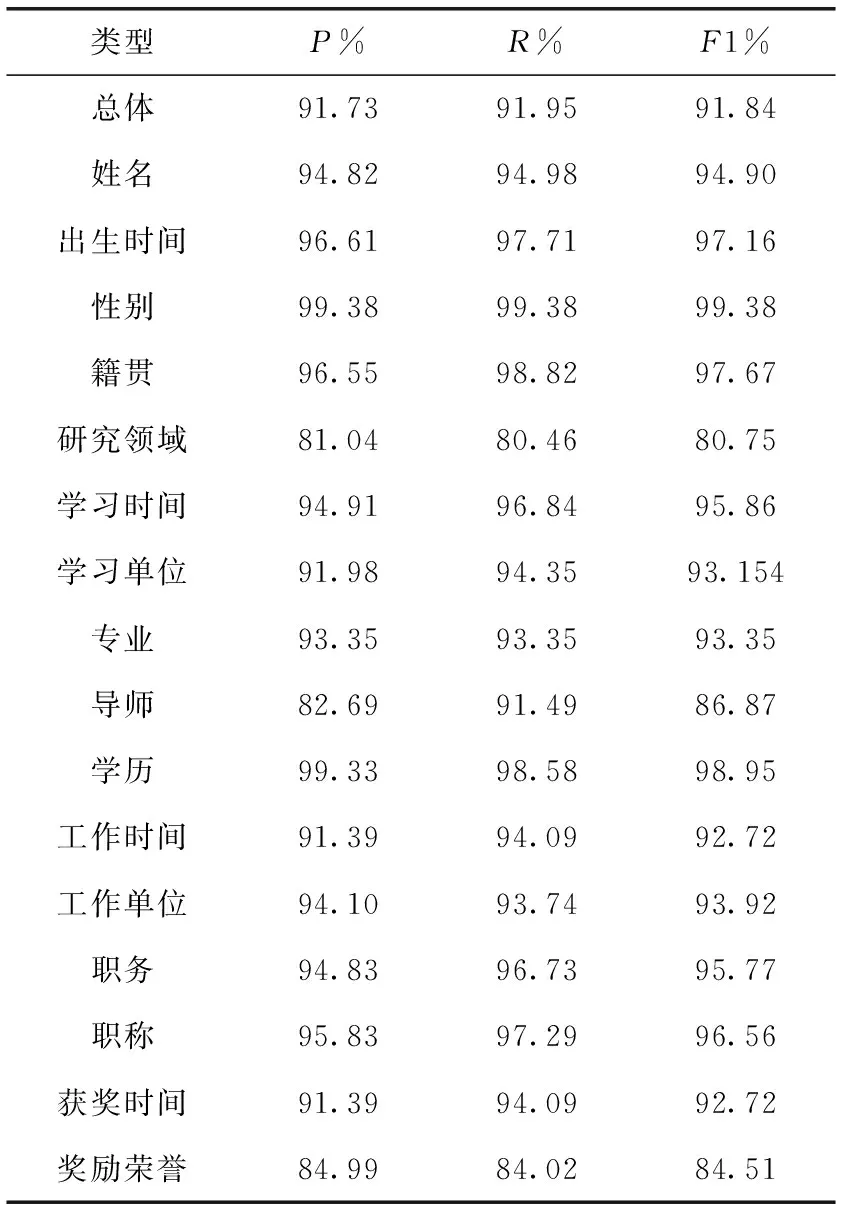
表6 科技人物简历信息最终抽取结果
5 结束语
本文对科技人物简历信息的抽取将重心放在了对研究领域信息的识别以及对工作经历和学习经历所包含的时间和单位信息的识别上。针对科技人物简历包含较多专业名词及领域术语,现有序列标注方法很难对科技人物简历中研究领域信息进行识别,本文提出一种基于字词协同的简历信息抽取方法。实验结果表明,使用字词协同的方法在多个模型上均能够提高模型对研究领域信息的识别性能,其中字词协同双向LSTM结合CRF的模型,在抽取结果上优于现有其它序列标注模型。为了充分发挥序列标注模型以及分类模型的优点,提高模型对工作经历和学习经历所包含的时间和单位信息的分类性能,本文提出了基于GBDT的信息再分类方法。实验结果表明,该方法能够解决序列标注模型对上述信息的分类不平衡问题,提高了模型对工作经历和学习经历中时间和单位信息的识别能力。
本文中所使用的语料涉及多个学科不同领域的人物简历,但每个领域所包含的简历数量较少,且信息数量分布不均,在下一步的任务中,考虑使用文本数据增强的方法以扩充语料中不同领域科技人物简历数量,进一步提升模型对研究领域信息抽取性能,在分类算法上,由于当前特征提取工作仍然需要人工参与,下一步工作考虑使用深度学习自动提取文本特征。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
科学大众(2020年23期)2021-01-18
青年生活(2019年23期)2019-09-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
汽车观察(2019年2期)2019-03-15
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中国卫生(2016年5期)2016-11-12
中共南宁市委党校学报(2015年4期)2015-02-28
生物进化(2014年2期)2014-04-16
