
基于特征融合和代价敏感学习的图像标注方法
2021-11-20 01:56厍向阳车子豪董立红
计算机工程与设计 2021年11期
厍向阳,车子豪,董立红
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引 言
网络技术的快速发展促进了数字图像的传播,使得用户可以通过互联网的检索工具搜索访问感兴趣的图像资源。但互联网的检索工具无法理解图像内容和语义,从而无法确定哪些图像满足查询要求,在这种情况下,图像标注是一个必需的过程[1]。然而互联网中图像的数量呈爆炸式增长,仅靠人工标注是无法满足需求的。因此,图像标注转向寻求机器学习算法来自动完成。目前图像自动标注方法可分为两类:基于生成模型的方法[2-4]计算已标注图像特征和标注词的联合概率分布,然后使用该模型计算每个标签匹配待标注图像的概率;基于判别模型的方法[5-9]将图像标注问题视为分类问题,使用图像的视觉特征训练分类器,通过训练的分类器将待标注图像划分到一个或多个标签类别中。近年来,基于卷积神经网络(convolutional neural network,CNN)的判别模型为图像标注提供了多种方法。文献[7]提出了CNN-MSE方法,通过改进均方误差函数来训练CNN网络。文献[8]在CNN模型中加入多标签平滑单元构成CNN-MLSU模型。深入分析现有工作,发现基于CNN的图像自动标注研究仍面临两个问题:①CNN模型中,通过不断降采样过程使得深层的卷积层具有较大的感受野,如果感受野远大于物体的大小,那么很容易忽略小物体的特征,使图片中较小的物体不容易被标注和学习。②由于图像自动标注数据集中训练样本不足且标注类别之间数量差异较大,使得训练出来的模型泛化性能较差。为解决以上问题,本文采用卷积神经网络构造端到端的图像标注模型,选择VGG16作为基网络,在其基础上引入特征融合机制融合不同卷积层提取的多尺度特征,最后在网络训练时使用代价敏感损失函数,来缓解标签分布不平衡引发的问题,进一步提升网络的性能。
1 相关理论与技术
1.1 卷积神经网络
卷积神经网络由4个部分组成:输入层、特征提取层、全连接层和分类器。卷积神经网络结构如图1所示。

图1 卷积神经网络结构
(1)输入层。接收预处理后的图像数据。
(2)卷积层。假设X为原始图像,X0为预处理后输入网络的图像。Xi为第i层卷积特征图,由卷积核和偏置项计算出,卷积计算过程如下式
Xi=f(Xi-1⊗wi+bi)
(1)
式中:wi表示第i层卷积中卷积核的权重矩阵;bi表示第i层卷积的偏置项;⊗表示2D卷积运算操作;f(·) 表示激活函数,一般采用线性整流函数(ReLU),公式如下

(2)
(3)池化层。池化层也称子采样层,通常使用平均池化(mean pooling)或最大池化(max pooling)。卷积操作后为了减少特征维数,降低数据复杂度,对特征进行池化操作,通过对下采样子区域取平均值或最大值来对特征图进行下采样。特征提取层通过对特征图重复执行卷积和池化操作,来递归提取高层特征。
(4)全连接层。在卷积神经网络的最后一般会连接全连接层来得到最后的分类结果,经过特征提取层对图像数据进行非线性特征提取后,输入到全连接层对特征进行聚合。将特征提取层看成自动提取图像特征的过程,提取完特征以后,仍需要通过全连接层来完成分类的任务。
(5)分类器。常用的分类器有Softmax分类器和Sigmoid分类器,分类器可以将最后一层全连接层的输出转换为当前样本属于每类标签的概率分布情况。
1.2 多核选择网络
Inception结构仅是简单的对不同尺度的特征图进行融合,因此,文献[10]设计了Selective kernel(SK)网络将多分支网络结构与软注意力机制相结合,有选择地融合不同尺度的特征信息,使网络更好获取不同感受野提取的信息。SK网络结构如图2所示,主要包含Split、Fuse和Select这3个操作。

图2 SK网络结构
Split:使用不同尺寸的卷积核对输入特征图X进行特征提取,得到特征图U1和U2。
Fuse:通过对特征图U1、U2进行逐元素相加,然后进行全局平均池化操作得到特征图S。将特征图S输入全连接层进行线性变换,提取通道维度的信息,具体操作如下所示
Z=δ(β(WS))
(3)
式中:δ(·) 为ReLU激活函数,β(·) 为批标准化操作。W∈Rd×c表示全连接层的参数,d为经过全连接层后输出的维度。
Select:特征Z输入全连接层,再使用Softmax函数来进行归一化得到U1,U2的通道权重a和b。然后将通道权重乘以对应的U1,U2得到A1,A2。最后,将A1,A2逐元素相加得到最终的融合特征A。
1.3 损失函数

(4)
(5)
多标签损失(multi label loss,ML Loss)函数定义为
(6)
式中:N表示样本数量;C表示标签类别数;yij∈[0,1] 表示网络预测第i个样本中包含第j个标签的概率,yij由下式计算
(7)
式中:xj为网络模型最后一层第j个神经元的输出。
2 基于特征融合和代价敏感学习的图像标注算法
2.1 基本思想
融合不同卷积层的特征可以提高网络的学习能力,低层的卷积特征具有较多的细节特征,但是噪声多;高层卷积特征语义信息丰富,但分辨率低,易忽略细小特征。直接将高低层特征连接在一起来融合特征会引入大量无用特征,增加网络的参数量和计算量,影响网络的性能。因此,本文借鉴SK网络的思想去融合不同层提取的多尺度特征,使得融合的特征能够更加全面的描述图像的内容,并改进损失函数引入代价敏感学习,使得不同类型标签的误分类代价具有较大差异。
首先将预处理后的样本输入到网络模型中,利用预训练的VGG16网络模型的卷积层进行特征提取生成特征图;其次将得到的特征图输入到采样层进行维度调整,再输入L2归一化层;然后特征融合层融合不同卷积层提取的多尺度特征;最后连接融合特征与全连接层的神经元,通过分类器得到每个标签标注样本的概率,提取前K个概率最大的标签作为标注结果。训练过程中使用代价敏感损失函数对网络参数进行训练,经过多次训练获得最终的图像标注模型。
2.2 代价敏感的多标签损失函数
本文对损失函数进行了修改加入权重敏感系数和错分敏感系数,设计代价敏感的多标签损失(cost sensitive multi label loss,CSML Loss)函数,计算公式如下
(8)
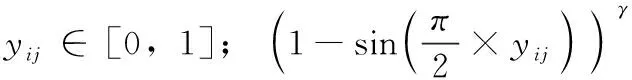
(9)
式中:Smin表示数据集中出现频率最低的标签的数量;Sj表示数据集中第j个标注词出现的频率;β表示权重控制系数,通过调节β值可以控制不同标签在计算损失值时的权重。
式(8)中的错分敏感系数用来控制难易标签的权重,可以看出当预测值yij越接近真实值时,错分敏感系数值越小。通过降低简单标签在计算损失值时的权重,从而降低简单标签的损失值,使得网络把训练的重点放在难标注的标签上。权重敏感系数用来控制不同类别标签的权重,通过提高低频标签的权重,从而增加低频标签的损失值,使得损失函数把训练的重点放在低频标签上。因此,低频标签和难标注的标签在计算损失值时将被赋予较大的权重,而高频标签和易标注的标签将被赋予较小的权重。
2.3 融合多尺度特征的卷积神经网络
2.3.1 模型框架
为了更好地解决图像自动标注领域存在的问题,本文在VGG16模型基础上设计了新的网络结构,如图3所示。网络模型包含有13层卷积层、4层最大池化层、3层采样层、1层特征融合层和3层全连接层。卷积层使用的是VGG16在ImageNet数据集上预训练的参数进行初始化。本文网络主要是在VGG16框架中添加特征融合层来融合高低卷积层提取的多尺度特征,从而提高网络的标注性能。

图3 本文算法网络结构
为保证卷积特征在输入特征融合层时在通道维度上相匹配,采样层使用1×1的卷积在通道维度上进行降维或者升维操作。由于不同卷积层特征的激活值不同,直接对多尺度特征进行操作,会导致网络无法稳定训练。因此,在输入特征融合层前进行L2归一化操作,对卷积特征进行归一化。
2.3.2 特征融合层
特征融合层融合操作主要分为3个部分:①从卷积特征中提取多尺度特征;②改进SK网络融合特征;③融合层融合多尺度特征。
使用自适应最大池化(adaptive max pool,Ada-MaxPool)操作提取多尺度特征,自适应最大池化中输入任意大小的特征图,都能产生指定大小的输出。因此,使用不同尺寸的自适应最大池化操作就可以提取到不同尺度的图像特征。自适应最大池化首先需要根据输出特征图的大小计算滤波器的尺寸(Size)和步长(Stride),然后将得到的尺寸和步长输入最大池化中提取特征,Size和Stride的计算公式如下
Stride=floor(inputSize÷outputSize)
(10)
Size=inputSize-(outputSize-1)×Stride
(11)
式中:floor(·) 为向下取整,inputSize为输入特征的尺寸,outputSize为输出特征的尺寸。
多尺度特征的提取过程如图4所示,使用自适应最大池化操作将图中a×a×N的特征图转化为1×1×N、2×2×N、4×4×N的特征图。将3层卷积层的特征都经过自适应最大池化层进行多尺度特征提取,相同尺寸的特征输入到改进SK网络中进行融合。
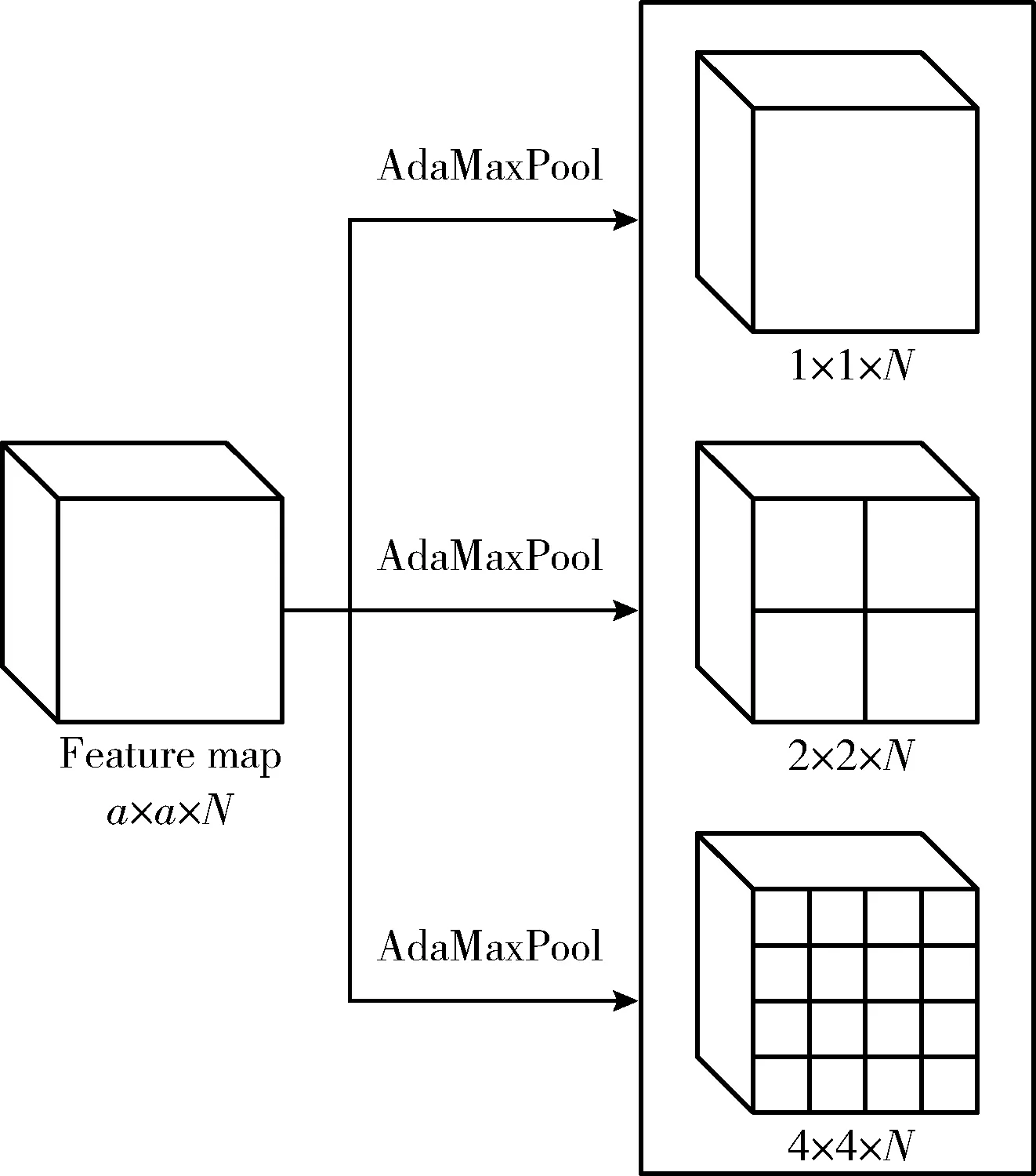
图4 多尺度特征提取
改进SK网络融合特征。如图5所示,与原始的SK网络相比,本文去掉了Split操作,改为直接输入从不同卷积层中提取的多尺度特征。使用SK网络不仅能在通道维度上加强重要特征并压缩无用特征,还能根据不同层卷积特征的重要程度来融合特征,使得不同层提取出来的特征可以相互补充,并且该过程由网络自主学习。该操作包含以下步骤:

图5 改进SK网络结构
(1)输入相同尺寸的特征图F1、F2、F3进行对应位置元素相加得到融合特征F。再对融合特征F=[f1,f2,…,fc] 在通道维度上进行全局平均池化操作,得到代表每个通
道上全局信息的特征S∈R1×c, 计算公式如下所示
(12)
(2)特征S经过两层全连接层,第一层对特征S进行降维得到特征图Z∈R1×d; 第二层对特征图Z进行升维,然后使用Softmax函数激活,生成各层卷积特征的注意力权重a,b,e∈R1×c。 具体计算公式如下所示
Z=ReLU(W1S)
(13)

(14)
式中:W1∈Rd×c表示第一层全连接层的参数,Wa、Wb、We∈Rc×d表示第二层全连接层的参数。
(3)根据计算的注意力权重对特征图F1、F2、F3加权更新并融合,得到融合后的特征V=[v1,v2,…,vc], 如式(15)所示
V=a·F1+b·F2+e·F3
(15)
最终得到融合后尺寸为1×1×N、2×2×N、4×4×N的特征图,并将3种不同尺度的特征输入到融合层中。
融合多尺度特征。融合层结构如图6所示,先通过flatten操作将特征图展开,scale操作对展开后的特征使用不同的权重系数来进行缩放,最后通过concat操作将多尺度特征连接起来输入到全连接层。scale操作中的权重系数可以看作去除偏置项的神经元,重要的特征设置较大的权重系数,辅助特征设置较小的权重系数,并且设置的权重系数可以在网络学习过程中自适应调节,自动更新不同融合特征的权重值。
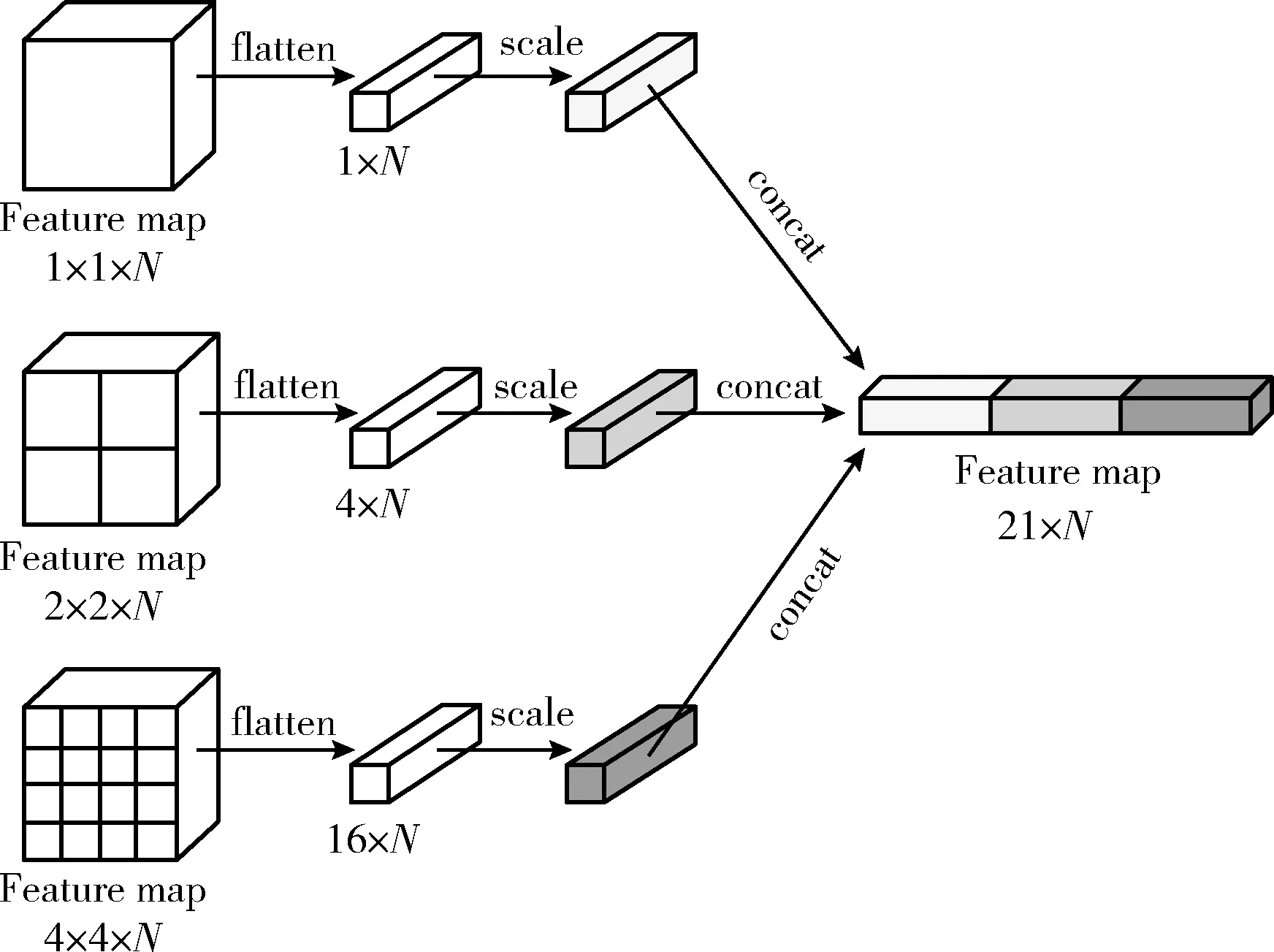
图6 融合层结构
3 算法验证与分析
3.1 数据集与评价指标
3.1.1 数据集
IAPR TC-12数据集包括19 627张图片和291个标注词,其中17 665张图片用于训练,1962张图像用于测试。数据集涵盖了运动、城市、风景、动物、建筑物和植物。训练集中平均每张图片包含5.7个标注,平均每个标签标注347.7张图片,最少标注词的训练样本量只有44张,最多标注词的训练样本量有4999张。
ESP game数据集包括20 770张图片和268个标注词,其中18 689张图片用于训练,2081张图像用于测试。数据集涵盖了徽标、绘画、风景和个人肖像。训练集中平均每张图片包含4.7个标注,平均每个标签标注326.7张图片,最少标注词的训练样本量只有18张,最多标注词的训练样本量有4553张。
3.1.2 评价指标
(1)平均准确率P。计算数据集中每个标签正确预测占实际预测的比例,并根据该数据集中的标签类别数量进行求和平均,计算公式如下
(16)
式中:N表示标签类别数;Precision(yi)表示在数据集中正确预测标签yi的总数;Prediction(yi)表示在数据集中预测标签yi的总数。
(2)平均召回率R。计算数据集中每个标签正确预测占真实标注的比例,并根据该数据集中的标签类别数量进行求和平均,计算公式如下
(17)
式中:N表示标签类别数;Precision(yi)表示在数据集中正确预测标签yi的总数;Ground(yi)表示在数据集中真实标注标签yi的总数。
(3)综合性能F1。由于平均召回率和平均准确率都是重要的评价指标,只有当平均召回率和平均准确率都高时,模型才有良好的性能。因此,需要计算F1值,以反映模型的综合性能,计算公式如下
(18)
(4)N+指数。统计至少正确预测过1次的标签个数,表示模型在数据集所有标签上的覆盖性能,计算公式如下
(19)
式中:N表示总的样本数;Sgn(·)表示符号函数计算公式如下
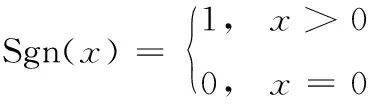
(20)
3.2 实验环境与参数设置
实验基于Tensorflow深度学习框架,使用NVIDIA TITANXp GPU进行计算,操作系统为Ubuntu16.04,编程语言为Python。训练中参数设置见表1。

表1 参数设置
3.3 实验方案及结果分析
3.3.1 实验方案
方案1:探究SK网络中降维全连接层节点数d对网络性能的影响。将降维全连接层节点数分别设置为32,64,128进行对比实验。
方案2:损失函数比较。使用多标签损失(ML Loss)函数和代价敏感的多标签损失(CSML Loss)函数训练本文设计的网络与原始VGG16进行对比实验。
方案3:本文方法与其它图像标注方法进行对比。与近些年提出的先进方法进行对比,涉及方法包括:KCCA、2PKNN_ML、SEM、SNDF、ADA、CNN-Regression、CNN-MSE和CNN-MLSU。
3.3.2 结果分析
方案1:降维全连接层节点数对网络性能影响的实验结果见表2。

表2 不同融合方案性能对比
从表2可以看出,当降维全连接层节点数为32和64时,网络都可以取得较优的性能;当降维全连接层节点数为128时,网络性能较差。节点数在取32时,不仅能够保证网络性能,而且还可以减少网络的参数量。因此,本文网络将降维全连接层节点数d设置为32。
方案2:损失函数比较方案的实验结果见表3、表4。
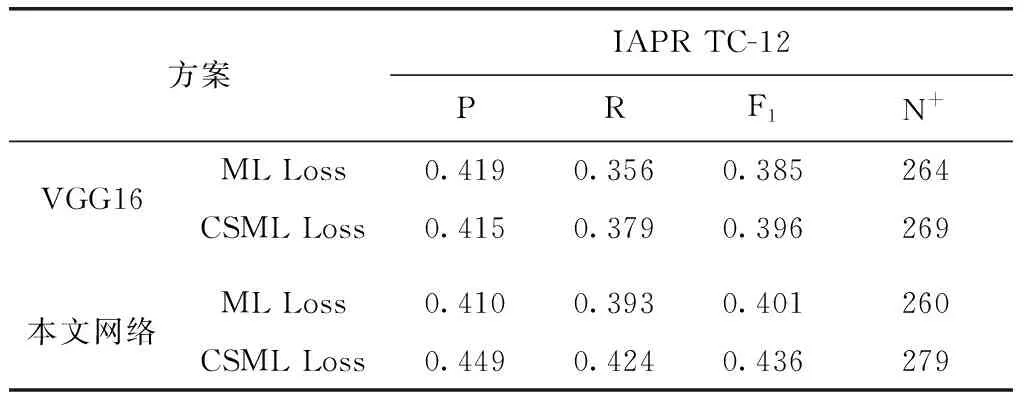
表3 损失函数性能对比(IAPR TC-12)

表4 损失函数性能对比(ESP game)
对表3、表4分析可以得出,代价敏感多标签损失(CSML Loss)函数相比于多标签损失(ML Loss)函数,在IAPR TC-12数据集和ESP game数据集上均有较好表现,尤其在平均召回率和N+指数上有明显提升。N+指数和平均召回率可以表明本文提出的损失函数能够缓解训练中标注类别不平衡对网络的影响,提升对低频词的标注性能。表中数据还可以分析出本文改进的网络相比于原始VGG16取得了更好的效果,并且本文网络的参数仅为0.77亿个,远小于VGG16中1.35亿个参数。
方案3:对比不同图像标注方法在IAPR TC-12和ESP game数据集上的平均准确率P、平均召回率R和综合性能F1。表5给出了本文方法与其它图像标注算法在IAPR TC-12 数据集上的实验结果对比,表6给出了本文方法与其它图像标注算法在ESP game数据集上的实验结果对比。

表5 本文算法与其它图像标注方法实验结果性能对比(IAPR TC-12)

表6 本文算法与其它图像标注方法实验结果性能对比(ESP game)
通过表5可以看出,本文方法相比于最近提出的SEM方法,在平均召回率与平均准确率上高出3个和4个百分点;与同样使用卷积神经网络的CNN-MLSU方法相比,本文方法在平均召回率和平均准确率上高出4个和1个百分点。综合来看本文方法在IAPR TC-12数据集上与其它的方法相比,虽然平均准确率低于2PKNN_ML方法,但本文模型的平均召回率和综合性能F1优于其它方法。通过表6可以看出,在ESP game数据集上,本文提出的方法较其它方法在各项评价指标上都有较好表现,与较先进的SEM方法相比,虽然在平均召回率上存在差距,但在平均准确率上优于SEM,在综合评价指标F1值上也不相上下。从整体来看本文提出的方法较其它方法在平均准确率和平均召回率上都取得一个较好的结果,从而使得综合性能F1与其它方法相比具有明显的提升。
表7列出了本文方法在IAPR TC-12测试集上有代表性的标注结果,每幅测试图像根据本文方法给出的结果选择概率最大的前5个标签作为图像的标注结果。其中表7的第一和第二个示例,场景简单且图像中物体特征明显,本文方法得出的标注结果与真实标签匹配度高。在第二和第三个示例的标注中“people”,“man”以及“house”,“building”是具有相近语义的标注词,本文方法虽然未能准确预测出真实的标签,但预测出的标签同样也符合图像的语义。表中第三个示例,真实标注显然遗漏了标签“sky”,该标签在图像中占据了很大的区域;在第四个示例中,“camera”和“hat”被识别标注,但由于其在图像中占据区域较小而被真实标注忽略,事实上“camera”和“hat”也符合图像本身的语义。表中第三、第四个示例中预测的新标签是对图像中真实标签的扩充,能够更加精确地描述图像的语义信息。

表7 IAPR TC-12数据集上的预测效果
4 结束语
本文在VGG16的基础上加入特征融合机制,融合多尺度特征提高对图像中不同尺度对象的标注能力。同时,引入代价敏感损失函数,在一定程度上提升了低频标签的召回
率,有效解决了训练过程中标签类别不平衡引发的问题。实验结果表明,本文提出的方法在标注性能上有所提升,优于其它经典方法和近年来所提出的先进方法。但本文方法未探究标注词之间的关系,无法通过标注词之间的关系来改善标注结果。如何挖掘标注词之间错综复杂的关系,是未来研究的关键问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
时代英语·高三(2014年5期)2014-08-26
