
多模型加权融合的文本相似度计算
2021-11-20 03:23田红鹏
计算机工程与设计 2021年11期
田红鹏,马 博,冯 健
(西安科技大学 计算机科学与技术学院,陕西 西安 710600)
0 引 言
在文本相似度计算领域中,其主要是扮演着自然语言处理的一种基础性工具的角色。目前,这种计算方式在很多领域中都能够看到其身影,比如在处理对话以及数据采集问题上均会使用[1]。Islam等[2]提出了一种基于语料库的语义相似度测量和最长序列匹配算法来测量文本的语义相似度,可以在文本表示等领域专注于计算两个句子或两个短段落之间的相似度。李晓等基于Word2Vec模型的基础上,把句子进行了简化处理,并形成向量空间中的向量运算,然后根据矩阵之间的关联度对句子语义中的相似度进行了检验和论证[3]。其所使用的设置方式,对于强化相似度结构的精准性起到了显著作用。Magooda等[4]提出了一个基于TF-IDF和语言模型相结合的方式将计算出的相似度根据新的加权总和对检索到的文档进行重新排序。有效克服了模糊理解文章的语义和上下文的问题。Kusne等[5]提出文本距离算法,将文本距离分解为词间的稀疏矩阵,基于文本向量空间距离进行求解。Tashu等[6]为了解决语义和上下文的问题,提出了使用词移距离算法的成对语义相似性评估。该方法依靠神经词嵌入来衡量词之间的相似度。Pontes等[7]证明了局部上下文对于获取句子中单词的信息和改进句子分析效果显著。其系统地分析、识别并保存了句子各部分和整个句子中的相关信息,通过局部上下文降低均方误差并增加相关性分析来改进句子相似性的预测,同时也提出了语料库的重要性。Yang等[8]基于浅层句法结构化特征的基础之上进行求解,虽然依赖树能有效解释关联关系,但无法适用于句子深层语义的解释。Ozbal等[9]使用树核函数根据输入数据的结构化表示生成不同维度的特征信息,对多种富含语义特征的句法信息进行求解,实验发现浅层语义特征与语义特征可以很好结合。
现存大多数研究仅考虑单一的文本特征或仅针对语义特征进行模型融合,本文不仅考虑文本语义、词序、主题关联性等相关语义问题,同时还结合了文本结构信息等表现形式展开分析。在此前提下,结合基于分层池化句向量的方法计算文本相似度,进而实现了不同形式在求解方面的融合,综合考虑句子语义和文本结构信息并使计算结果更优且合理。
1 相关工作
1.1 TF-IDF权重(TIi)
此权重通过两部分实现,其一是TF词频,特征词在特定一段范围之内出现的次数出现次数越多,词频量化值越大,出现次数越少值越小。通过这一数值的计算,能够进一步得出与总长度的整体比值。特征词总量共计为N,其中某词条的浮现次数为n,词频TFik即
(1)
其二逆文档频率即包含特征词条的文档数,如式(2)所示。M为全量文本,包含词条的文本置为m,包含特征词的文档越少IDF最终越大
(2)
其中,α为经验系数,通常情况下,该数值等于0.01。TF-IDF权重表示为
TIik=TFik*IDFik
(3)
1.2 词句位置权重(Pi)
美国P.E.Baxendale的调查结果显示:在文本中的重点思想实际上大部分是出现在第一句当中,而这种现象占了整体的85%,另外7%是出现在段落末尾。因此在对其比例进行计算的时候,还需要对其位置因素多加考量,要根据其不同位置来对关键词分析权重。当关键词或者核心内容都聚集在第一句或者最后一句的时候,其关键词会比其它位置的权重占比高很多。接下来对其加权函数进一步展示
(4)
其中,e1和e2为支持个性化设置,其中将e1值调整为0.2,e2值调整成0.1。x代表的时不同位置下的具体比例,且按照0-1的顺序自然排序。其中一个i的词句位置权重为Pi。
1.3 词性权重(Si)
此处对我们当前使用的汉语言词义与特征展开研究[10],需要根据关键词的含义、句法关系等来对其权重展开针对性计算[11]。对所有词语的词性特征进行归纳[12],并总结为7种,每一种词性分别所占的比例体现在表1中。

表1 中文文本词性分布占比
通过梳理表1数据我们不难发现,在这些不同性质的代表词性当中,在解释词汇内容方面,最具解释能力的词性就是动词、名词、形容词和副词。剩余3种词性的词语几乎不具备完整的词汇信息,因此会被看作数据噪音被处理掉。通过前4类词语的运用,一方面,能让其解释能力更佳,另一方面,还能进一步简化不必要的计算流程,进而使计算结果更为精准与快速。同理,得出了表2中不同词性下所对应的占比。

表2 词性权重系数
在表2所示的数据当中,Si代表的是不同词性i下的不同占比,可以发现,除了一类与二类词性之外,其它词性权重都置为零。
2 多模型加权融合算法设计
在此研究的过程中,首先充分考虑了词语出现频率的问题,构建多特征权重的量化信息,兼容TF-IDF、语句、词性。在多特征融合的前提下,对不同特征词进行了再次计算,基于其自然降序排序原则下,对特征词进行排序,其中选取前n个作为文本关键特征词。最终,在Word2Vec词向量模型中,通过计算特征词数值,得出了最终的向量形式,进而计算出比较精确的相似度数值。
通过结合实现的池化操作使用SIF模型,将不同词序和结构信息的表达类型分层分组,去除向量之间的空间距离后,可以计算出单位向量模型与分层求和的相似度结果。
为了更好强化算法的特征,并保证最终数值的准确性,将上述两种单模型线性加权计算,得到融合的计算算法(algorithm for calculating the similarity of multi-model fusion,MuMoSim)。计算如下
MuMoSim=x×MuSim+y×IIGSim
(5)
其中,MuSim为前者多特征融合度量计算结果,IIGSim为后者分层池化度量计算结果。该计算方法的流程如图1所示。

图1 多模型融合文本相似度计算算法
2.1 基于多特征融合的词移距离算法
大多数基于关键词的相似度计算方法单一统计句子的关键词,为综合考虑关键特征对文本相似度结果的影响,本文采取将词频TF-IDF权重(TIi)、词性(Si)、词句位置(Pi)3个特征相结合,共同计算句子相似度。词语i在文本D中的多特征融合权重计算公式如式(6)所示
MFWi=α×TIi+β×Si+γ×Pi
(6)
式中:α、β、γ分别代表的是词频、词性和词句位置3个不同要素的相似度权重系数,0≤α≤1,0≤β≤1,0≤γ≤1,同时要满足α+β+γ=1。
本文采用层次分析法计算各特征项α、β、γ的权重,针对不同数据集设计不同权重系数取值。层次分析法针对本文特征元素进行定性和定量分析。具体步骤如下:
(1)建立层次结构模型
特征融合后的结果作为目标层,词频、词性、词句位置相似度作为准则层。
(2)构造判断(成对比较)矩阵
根据重要程度对比,得出准则层各个准则的比重。标度量化值1-9代表重要程度由低到高,两两比较减少干扰因素,最终生成判断矩阵。
判断矩阵元素标度方法
(7)
(3)层次排序及其一致性检验
计算一致性指标CI
(8)
式中:λmax为从判断矩阵得出最大特征值,n为特征向量的维度。
平均随机一致性指标RI标准值见表3,本文为三阶矩阵,RI对应表格中为0.52。计算一致性比例CR

表3 随机一致性指标
(9)
通常情况下,若CR<0.1,假设判断矩阵已通过最一致性测试,否则不符合一致性。对函数向量进行归一化后,将生成权重向量为α、β、γ的取值。
根据组建的多特征融合权重,可以得出富含信息的特征,其中包含大量的文本信息。在多特征融合的词移距离算法中,使用内置多特征权重之间转移词的代价计算来代替算法中对两个文本中两个词转移代价的计算。假定ki和kj分别为两篇数据文本囊括的关键词。计算转移代价
(10)
构建转移矩阵Tki,kj以保证文本D中所有关键词ki完全转移到文本D′中,结合原始算法的矩阵定义,需要添加以下约束
∑kjTki,kj=MFWki|D
(11)
∑kiTki,kj=MFWkj|D′
(12)
式(11)定义的约束指定从关键项ki转移的总成本必须等于关键特征的权重系数,式(12)定义的约束规定转移到关键项kj的总成本必须等于此特征项的组合权重因子。因此计算文本转移的总代价公式如下
(13)
本小节提出的距离优化目标,就是使上述总代价Ic最小。因此文档D与文本D′之间的欧氏距离如式(14)所示
(14)
为了确保最终相似度计算结果加权过程不受其它因素干扰,此处本文将计算出来的相似度进行处理,使结果位于0~1范围内。经过运算,我们可以得到文档之间的相似度如式(15)所示
(15)
2.2 分层池化IIG-SIF句向量的相似度计算
(1)改进信息增益计算方法
对于平滑逆频句向量模型只考虑通用数据集上的词频信息来计算词权重,为了使特征词能够在更大程度上影响计算任务,必须要综合性的考虑增强各种因素,其中包括考虑特征词对不同文本的影响。所以此处添加了类内词频因子β和类内、类间判别因子δ。将两个影响因子看作新的元素进行数据筛选,计算公式如下所示
IIG(T)=IG(T)×β×δ
(16)
此处假设语料中各类型文本集合为Ci,i∈[2,n]。β表示语料集合中某特征词在集合中出现次数与语料当中词总量的比值,这样能够更大程度客观表述特征词和类别之间的相关性。类别Ci中单词w的类内词频公式如下
(17)
其中,m表示集合中词总量,Nij表示某特征词汇在集合中出现次数。类内词频因子越大,说明特征词汇与本类的相关程度越高,此词语对于这个集合的语料更具有代表性。
δ刻画的是对于不同的语料集合进行筛选。如果一个词只在一个类别中频繁出现,而在其它类别中不太可能出现,则说明该词在类别之间具有较高的区分度和较高的属性对比度。此处区分度计算如下
(18)

(19)
简言之,类别之间的分离程度越大,类别内部的划分程度越小,文本的区分程度就越大,特征词w对类别Ci的贡献就越大,并且能够更好地表示类别中包含的信息。特征词区分度定义如下
(20)
(2)基于特征贡献度因子的选词方法
原SIF模型具有领域自适应的优势,在不同语料库中使用仍然能保证优秀的性能,但当具体到各语料库中的集合时,不同词对任务的贡献不同及其权重的问题不考虑修正。此处在第一小节的基础上,增加针对文本任务的特征贡献度因子,其表示如式(21)所示
TCF(w)=IIG(T)Weight(w)
(21)
其中,Weight(w) 表示原模型中对特征词的设定。
生成句向量需要根据数据集中不同类别特征词的分布,采用改进的信息增益特征选择方法提取出任务贡献因子。需要将任务贡献度低的数据项剔除,需要将任务贡献度低的数据项剔除后再展开计算,这是实现运算结果准确性的基础。模型算法过程如下算法1。首先对各个特征词的出现频率进行了求解,其次对增益算法进一步升级增强后,对任务贡献因子求解,随后根据任务贡献度因子值大小进行降序排序,修正特征词表,最终将词向量加权平均得到句向量。
算法1: 分层池化的IIG-SIF句向量模型
输入: 词向量集合vw; 句子集合S; 语料库p(w); 分类训练集Ci
输出: 句向量集合vs
(1)forallsentencesinSdo

(3)endfor
(4) Create matrix X whose columns arevs
(5) Create first singular vectoruby X
(6) Create word order vectordby X
(7)forallsentencesinSdo
(8)vs←vs-uuTvs
(9)vs.append(d)
(10)endfor
分层池化的IIG-SIF计算相似度过程如下:
(1)数据预处理。将标准化、去停筛选后的文本数据集合定义为S′1、S′2。
(2)句向量生成。采用改进的特征贡献度因子生成模型句向量Sv1和Sv2。
(3)相似度计算。利用向量Sv1和Sv2之间的余弦距离计算文本之间的相似度,即
(22)
3 实验设计与分析
3.1 实验环境及数据
具体实验环境见表4。

表4 实验环境
为了凸显本文方法的有效性,实验在数据集选取时引入中文和英文的句子对、短文本集合等4种数据集,以验证在不同语言、不同粒度下的实际表现情况。具体的数据体现见表5。
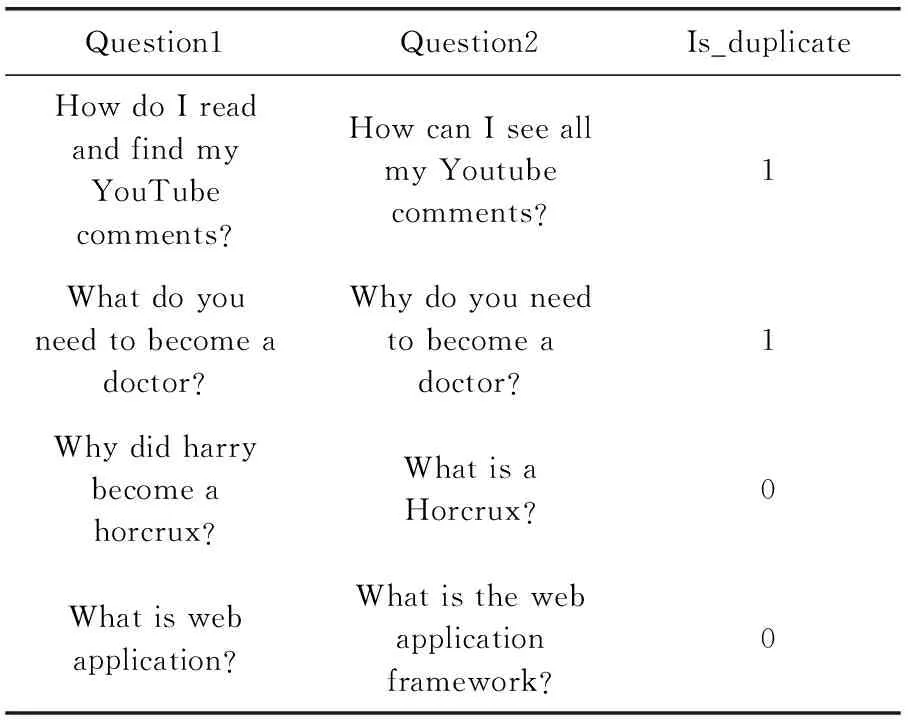
表5 Quora数据集示例
数据集Ⅰ如表5所示,其源自Quora数据集。其中囊括了39万余英文句子,由Question1、Question2及Is_duplicate 这3部分组成,在此数据集中语义标注为人工标注,若语境结果表述的含义相同或相似则Is_duplicate置为1,反之为0。
数据集Ⅱ选择了20余类英文的热点话题,其中包括财经、历史、体育、科技等。将话题文本总量较少的文本类型剔除后,剩余6组共计3000条数据以供使用,其中3组文本类别相似,其余3组不相似以供对比。
数据集Ⅲ选择STS中文文本语义相似度语料库,见表6。数据集的评分区间为[0,5],即0为语义相反或毫不相关,5为相似度极高。该数据集分为两组数据,其中包含27 490个句子对,其各个相似度评分的数据量分布不均,大部分为相似度极高数据集,因此,需要筛选数据,最终本文剩余8000个句子对展开实验分析,尽量保证各个相似度评分下的数据量大小一致。

表6 ChineseSTS数据集示例
数据集Ⅳ选取自复旦大学的中文文本分类数据集。下载的原始数据编码格式是gb18030,因此需要将数据格式转为utf-8编码格式后使用。train.zip训练集共9804篇文档,test.zip测试集共9832篇文档,都分为20个类别。其中无用数据需筛选,部分类别的文档数量较少,无法使用。本文选择计算机、环境等7类数据量充足的数据以供使用。
3.2 实验设计
在实验过程中首先做预处理,对数据进行删除和过滤等处理。与此同时,本文使用了相同的区间值,即[0,1],在对相关数据进行观察和研究之后,对评分较低的语句进行了二次标注,即统一标上1,而评分结果为2或0时置为0。
接下来,本文使用jieba工具包对采集到的数据进行分词,并对特征词的TF-IDF系数予以求解,然后对所有词汇按照其不同特征值进行细分,最终归结为4类,并分别进行标注。而在此之前,要先对短文本数据进行筛选,并对其中不同词语的位置予以定位,进而得出不同词性的权重。另外,对于句子对比而言,应将初始权重均匀设置为1。这种做法,一方面能够降低文本长度对结算结果造成的影响,另一方面也能够最大限度提升计算过程的便利性。至此将数据代入式(6)计算出融合后的权重系数大小。
第三步结合现有资料,利用已有流行库来对Word2Vec词向量进行数据集训练。其中选用模型Skip-gram模型(sg=1)。设定其基本参数,结合实际情况将窗口大小设为5,向量维度300,初始默认学习率设置为0.001。并且使用一些初始化后随机的向量来表示不在语料库中的词语。
最后进行分层池化相关操作。先对各个特征词的出现频率进行了求解,再将增益算法增强后对任务贡献因子求解。模型依然按照原始模型当中参数进行设置。模型系数a设置为0.0001。
3.3 实验结果与分析
(1)实验1:选取特征词最佳占比
在实验过程中,选择使用多特征融合模式下适用的词移距离算法时,在选取词语这一过程中,不同选取比例会影响文本相似度计算的结果。选取的比例过小,就会导致模型可能会忽视一些文本信息,影响算法的计算结果;但如果选取的比例过大,而这些信息中包含了一些与模型不兼容的信息,模型涉及的冗余信息过多,这导致算法效果不佳、精准度无法得到保证。
聚类被广泛应用在信息挖掘模型中,因为这种模式不仅不需要事先训练,同时还能够免去标注、分类等复杂环节。所以在从此实验过程中,本文重点采用了当下聚类效果出众的K-means、DBSCAN算法中来确定特征词占比。鉴于数据集Ⅱ在聚类算法中也经常使用,也得到了大部分研究者的认可。基于此,本文将在这一数据集的前提下,选择归一化互信息指标(normalized mutual information,NMI)来评测聚类结果好坏。当NMI值越大,说明聚类的效果越好,即说明该算法包含的文本信息越多。在图2中,不同比例特征项对聚类结果的差异十分明显。

图2 文本特征词对聚类的影响
由图2可知,如果选取60%的文本特征词,聚类的效果是最好的。若是选取的比例小于60%,就会出现模型包含的文本信息量不足,造成算法的效果不理想,若是选取的比例大于60%,就会造成文本的冗余,削弱文本与文本之间的独立性,造成算法的效果不准确。
(2)实验2:针对加权因子进行取值。
该实验的数据集选自数据集Ⅳ中的部分内容,结果见表7。

表7 不同x和y取值下的实验结果
由表7可知,通过增加多特征融合和词移距离算法的权重,就能够进一步提升召回率,因此这种做法能够最大限度保证数据运算的准确性和文本特征的多元性。通过实验结果可知,当x选取0.6,y选取0.4的时候,召回率最高,最终本文确定x和y的取值分别为0.6和0.4。
(3)实验3:融合方法的对照实验
为了验证本文算法的有效性,选择了准确率、召回率和F1值作为评价指标,通过将本文算法(MuMoSim)与未融合多特征的词移距离算法(MuSim)、基于分层池化IIG-SIF句向量算法(IIGSim)、传统的词移距离算法(WMDSim)和基于SIF句向量算法(SIFSim)进行对比来进行验证。实验结果见表8。
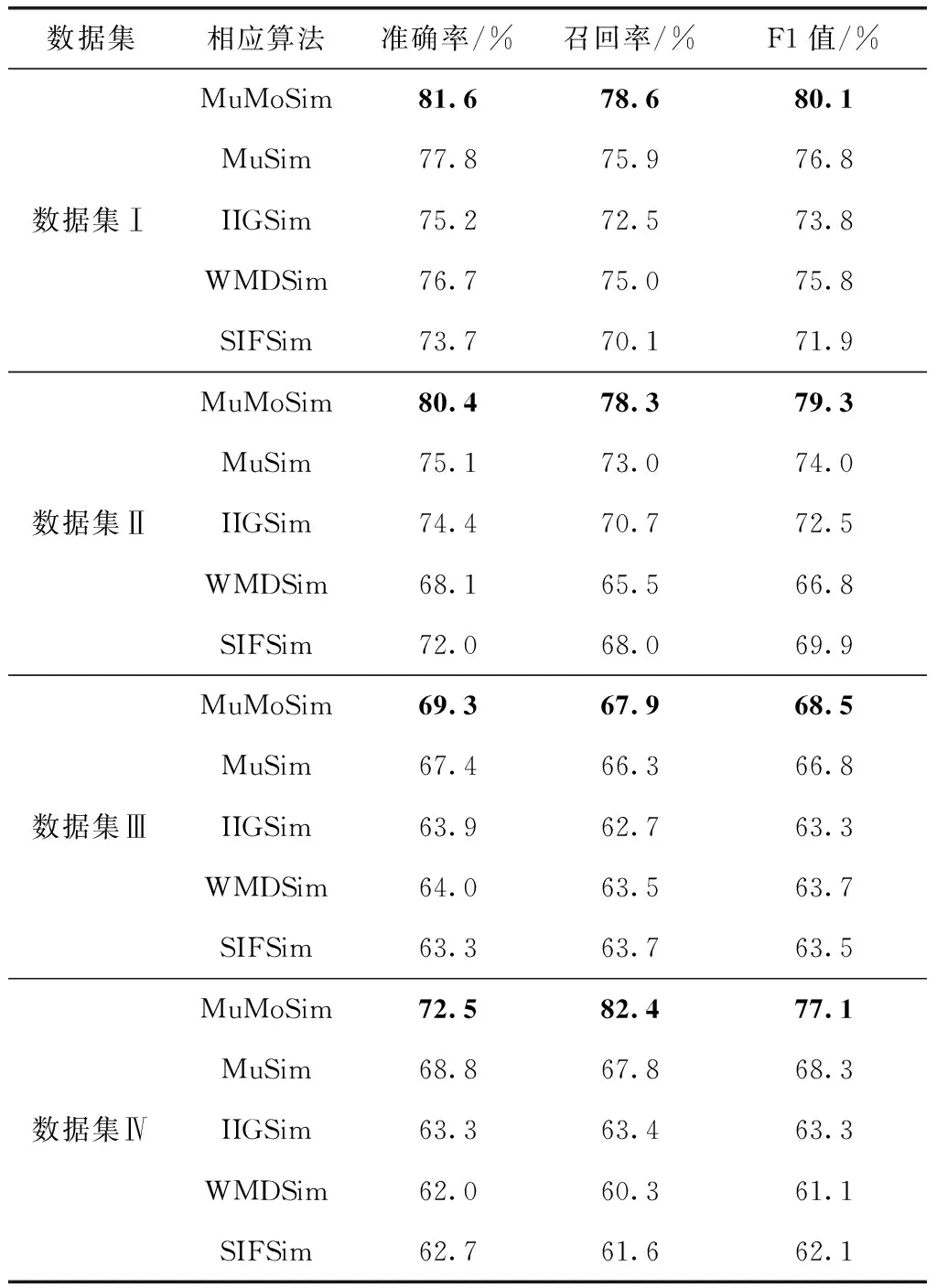
表8 融合方法对照实验结果数据
由表8可以看出,在这4种数据集下,本文算法(MuMoSim)在3个评价指标上都获得了比较高的数值,评价指标取得的值越高,说明算法的效果越好。这是因为本文算法能够实现词义、语义等多种信息的有效采集和处理。而在这一前提下提出的多特征融合权重,结合数据特征能够更为精准解释词语转移距离。结合分层池化相关内容,根据数据集中不同类别特征词的分布,采用改进的信息增益特征选择方法提出任务贡献因子,计算出句向量大小。由于本文算法还提前设置了最佳的文本特征词的占比,这从一定程度上提高了算法运行的效率。
(4)实验4:不同文本相似度算法的对比实验。
将本文算法与文献[13,14]相关融合算法做对照实验,以F1值为评价标准,实验结果见表9。

表9 4种数据集下3类相似度算法F1值/%
由表9可知,文献[13]的算法虽结合反义与否定两种信息,但其语义词典不完善,明显在不同的数据集有不同的影响,在英文新闻数据处理方面效果起伏较大。文献[14]的相似度计算算法虽然获取了句子的词形特征、词序特征、句长特征,但在语义相似度处理方面存在不足,影响相似度结果。而本文在此次研究中,提出MuMoSim的算法,既考虑了最佳的文本特征占比,还设置了最佳权重,让最终结论更为精准。由实验结果可知,本文算法在4种数据集中在F1值下的表现都要优于其它两种方法,更具有竞争性。
4 结束语
首先,本文在传统词移距离算法的基础上加入了特征融合机制,融合多特征来解决权重单一对词移距离算法的影响。其次,引入分层池化IIG-SIF句向量模型,在一定程度上增强文本结构信息和词汇排序问题。最后,通过对前两种方法进行加权融合,得到最终算方法。实验结果表明,本文的算法与之前基线模型进行相比,在评价指标F1值上有了明显的提升,得到了较好的文本相似度计算结果。
在后续的研究过程中将继续对本文的方法加以改进,例如引入外部知识来弥补中文数据库效果差的弊端,增强中文的语义信息,提高文本相似度的计算结果。
猜你喜欢
当代陕西(2020年17期)2020-10-28
开放教育研究(2020年2期)2020-03-31
计算机技术与发展(2018年8期)2018-08-21
人大建设(2018年5期)2018-08-16
中国机械工程(2017年22期)2017-12-02
现代语文(2016年21期)2016-05-25
应用科技(2015年5期)2015-12-09
中文信息学报(2015年4期)2015-04-21
大连民族大学学报(2015年2期)2015-02-27
河南科技(2014年15期)2014-02-27
