
基于SVM 的新冠疫情虚假新闻检测
2021-12-07 09:26郭文强
佛山科学技术学院学报(自然科学版) 2021年6期
郭文强,李 嫔*
(新疆财经大学 信息管理学院,新疆 乌鲁木齐 830012)
COVID-19 病例于2019 年被人类发现,作为一种新发现并对人类生命健康产生致命威胁的病毒,其传播速度快、范围广、途径多,在短短一年时间里迅速席卷各国,在疫情防控的紧张时刻,真实可靠的信息对大众的安全及健康有着至关重要的影响[1]。从一方面来看,由于网络平台言论发布相对自由,传播时速快,受众范围广,网络中出现的信息越来越鱼龙混杂,真假信息混淆,例如在消费者网络评论中,虚假的评论信息掩盖了影响消费者效用的产品质量问题,诱导消费者做出错误的购买及使用决策,成为“柠檬市场”现象出现的诱因之一。在”劣品驱逐良品“的情境下,有序、高效、平等的市场秩序难以建立和维护。
在与新冠疫情相关的虚假新闻传播速度远远高于真实信息的情形下,接收信息和识别信息的关系不可分割开来的重要性凸显。在如新冠疫情此类的突发公共卫生事件流行期间,虚假新闻不仅会导致大众的不理性行为,而且会危及到人类生命,对整个国家的政治与经济安全产生负面影响[2],因此需要迅速遏制虚假言论信息在网络平台的传播。互联网信息技术升级带来了生产效率及生活质量的提升,Web 挖掘、机器学习、人工智能等热点技术的开发与运用成为大势所趋[3]。Jindal 团队创造性地提出了虚假评论信息的定义,并将其划分为三种类型:其一为虚假评论即不真实评论;其二为不相关评论;其三为非评论相关信息,即不是关于产品的直接评论[4]。从国内的相关研究来看,与COVID-19 相关的研究多集中于定性方面,例如对虚假信息的甄别与对策,虚假信息治理的途径等[5-7],在定量与构建模型进行虚假信息识别方面的研究还有待扩展。国内关于虚假信息识别的研究大部分集中于电子商务产品、互联网销售等领域[8-10]。从国外的相关研究来看,与COVID-19 相关的研究多集中于检测模型的构建,检测技术的创新与虚假信息传播对人们产生的影响方面[11-12]。
本文以新冠疫情事件为研究对象,以各大权威性新闻网站以及新浪微博平台为数据来源,搜寻与新冠疫情相关的新闻与言论,对数据进行标签并分类,以权威性数据为真实数据集,建立辨别真实数据与虚假数据的特征,设立7 个可进行本质识别的特征属性对模型进行训练,最后获取不通核函数的分类结果。
1 虚假新闻识别模型的构建
虚假新闻识别模型的构建目的是对样本数据集中的新闻进行真假分类,将训练好的分类器运用到其他真假两类同时存在的数据集中,能够保持较高的分类准确度。模型体系主要包括三个部分,分别是新闻数据平台的选择与数据提取、特征属性的构建及划分数值选择、SVM 函数的构造,如图1 所示。

图1 虚假新闻识别模型
1.1 平台选择与数据提取
澎湃新闻由上海报业集团投入打造,以新媒体的印象走入公众视野,主要有网站、App、Wechat、新浪微博等四个主要信息发布途径,设立45 个栏目,日发布至少十几万字的内容中原创内容占大部分。作为一个官方正式新闻媒体,澎湃没有用自有资金开设线下渠道,而是由东方日报负担,因此有足够的资金保证充分的新闻采集。鉴于以上原因,本文通过澎湃新闻官网对新冠疫情辟谣信息新闻数据进行采集。
由于关于新冠疫情的真实新闻与虚假新闻相比较总数差异较大且分布的范围较为广泛,因此通过新浪微博官网、腾讯新闻官网和央视新闻官网等平台对真实新闻数据进行提取,在对数据进行预处理(去重复,去相似性,筛选与删除无效信息)之后,总共保留93 条数据。
为了保证数据的全面性和完整性,采用网络爬虫技术对新冠疫情的虚假信息进行爬取,总共爬取数据100 余条,在对数据进行预处理(筛选与删除无效信息,去重复)之后,保留93 条有效数据。
为保证识别概率的平等性以及训练分类器的准确性,采取了提取相同数量真假样本新闻数据的设计方案。提取结果含93 条新冠疫情虚假信息和93 条新冠疫情真实信息,提取的部分数据样本如表1所示。

表1 新闻样本数据提取结果
1.2 特征属性的构建
新闻的生命在于其所具有的真实性,这不仅是理论和实践的基石,更是不能打破的原则。由于当代社会浮躁风气的浸染,个人乃至媒体一味通过提高新闻阅读量与转发量追求利益,虚假新闻屡见不鲜,通过查阅相关文献和研究,发现被认定为谣言的虚假新闻有以下特征:标题浮夸;在真实事件报道的基础上添加过多主观情感;新闻字数较短,内容详尽程度低;新闻事件及官方消息来源方不明;应用名人效应混淆视听。
鉴于以上虚假新闻的特点和新冠疫情的实际情况,笔者构建了以下7 个特征属性。
(1)敏感性词汇占比。突发公共性安全事件涉及全国乃至全世界人民的生命安全,心理学研究指出,人具有“嗜血”的本质,由此负面事件的传播速度远高于正面事件的传播速度。关于新冠疫情的虚假新闻制造者往往通过敏感词汇的提及来扩大社会传播面,极易引起大众心理的恐慌和躁动,设定的特征属性中的敏感词汇包含死亡录音、逃亡、感染出逃、爆炸、坠楼自杀等。在设立过程中,没有将虚假与真实新闻的字数单独设置特征属性,而是通过将其作为特征值计算过程中的分母来体现,后续三个指标同理。
(2)地点名词与人物名词占比。虚假新闻的表现形式是多方面的。从虚假新闻的过程来看,可以分为源头性失真、传播过程失真和结果失真。在大众传媒时代,人人都是自媒体人,发布言论甚至新闻的成本几乎接近于零,人人都会发声且可发声,传媒平台的良莠不齐给虚假言论创造了滋生环境,“求热不求真”成为媒体界的一大乱象。张雷等研究指出,轻信信源是虚假新闻产生的主要原因。因此设置地点名词与人物名词占比指标,地点和人物说明越详尽,新闻可信度越高,在法制社会,若以他人名义散播谣言将受到法律的制裁,责任的归咎和个人信誉度的降低成为谣言制造及传播者不得不考虑的“发声成本”。
(3)序数词、基数词等数字信息占比。21 世纪是信息化的时代,数据信息是信息时代的重要角色,能够反映事物的面貌与发展变化规律。通过数字信息客观有效的描述,能够更精准地对表达对象进行描述和进行发展变化的反应。数字信息面对对象的内容精准且唯一,主观成分不能参杂入内。文字信息面对对象的内容不明确且存在理解多样性,由于人的有限理性存在,同一种文字表述被传达出的含义大相径庭,主观成分掺杂过多。由于上述原因,通过虚假新闻的规律研究发现,伪造信息中数字信息的占比较低甚至不出现,伪造者和谣言传播者难以对事物的数字特征进行精准的定位,通过构建序数词和基数词在新闻总字数中的占比指标能够对此现象辨别,占比越低则新闻为虚假新闻的可能性越大,反之,可能性越小。除此之外不排除伪造者对造假对象进行详细了解后同时虚构令人信任度较高的数字特征,本文对此处的考虑没有在单一特征指标中体现,而是通过多个特征值的求和来减小错判的可能性。
(4)肯定预防控制效果的前提下,食物或行为的占比。根据人类对事件可控程度不同进行划分,分为可控事件和不可控事件。新冠疫情的爆发虽有因果,但是由于人的认识的限制,对事物的真理性认知需要一个螺旋式曲折上升的过程,至今没有官方消息报道发现疫情出现的根源。虚假新闻则以此为对立面,在文字中多出现过度肯定对不可控事物的发展态势及结果的词汇,在肯定预防控制疫情效果的前提下,对事物或行为的词汇占比指标能够对此现象进行量化,主观肯定词汇出现的前提下,事物或行为占比越高,则为虚假新闻的可能性越高。
(5)是否是关于新冠疫情过度反应的负面信息。考虑到新冠疫情对大众心理状态及情绪的过度影响,真实新闻对疫情的负面消息的评论客观性高,主观评价几乎被杜绝。虚假新闻则出于政治、经济利益、社会稳定性等各方面的原因,伪造传播对疫情过度反应的负面信息,依此为出发点,构造指标,指标值为布尔型,若值为1,则表示出现过度反应的疫情负面信息,反之,则为0。
(6)专家是否与表达肯定或否定的词汇一起出现。新闻价值由若干个要件共同组成,显著性是构成价值的重要成分之一。显著性程度的高低取决于新闻中人物与事件所具有的吸引力的高低。名人的行动和言语带来的影响类似于蝴蝶效应,根据调查结果显示,出于对名人的崇拜及追随心理,大众往往倾向于相信其言语所描述和评价的事物。事业成就越高、公信力越大的人,其一举一动的新闻价值越高。新闻伪造者出于此,往往通过伪造名人的言论来进行虚假新闻的撰写与传播。在新冠疫情中,由于对疫情趋势的未知性和权威专家的理性判断,专家若与明确表达肯定或否定的词汇一起出现,则该新闻为虚假新闻的可能性越高,综上所述,构建指标,若指标值为1,表示专家与明确表达肯定或否定的词汇一起出现,反之,则为0。
(7)武汉地区评论性质指标。武汉作为新冠疫情的主要受害地区,承担着全国战役行动的主要责任,英雄的武汉人民为了防止疫情的进一步扩散,封闭一切进鄂离鄂通道,为抗击疫情做出重大牺牲和贡献。根据网络评论显示,仍有针对武汉的地方歧视主义情况出现,对一切来源于武汉的人或事物强烈排斥和诟病,超出正常的防范程度。因此,通过构建武汉是否与负面词汇一起出现的指标来对此方面的虚假新闻进行识别,若指标值为1,则该新闻为虚假新闻的可能性较大,反之,可能性较小。提取的部分样本如表2 所示,分别对每个样本的敏感词汇占比、明确肯定预防词汇占比、序数、基数词出现占比等8个数据特征进行了分析。
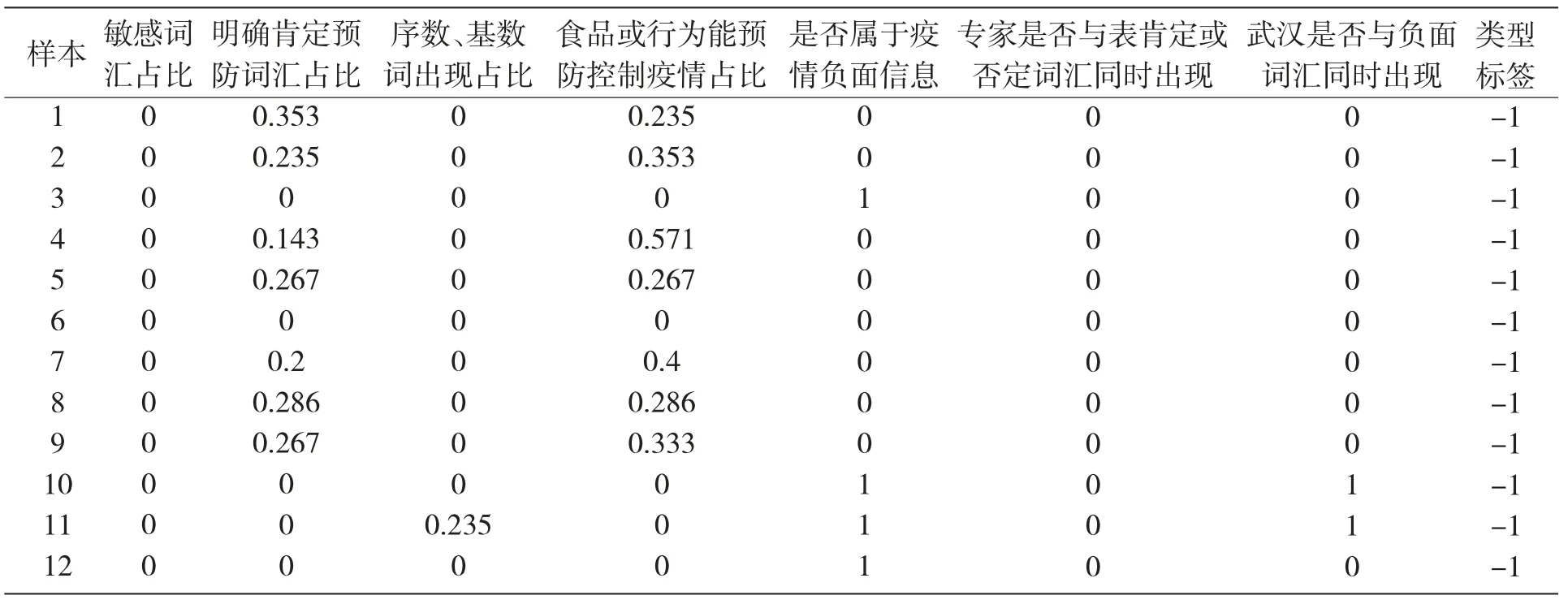
表2 样本数据特征属性值
1.3 SVM 模型构造
SVM(Support Vector Mac)为一种二分类的模型,按其功能可以分为线性和非线性两大类。SVM 主要思想是找到空间中的一个能够将所有数据样本划开的超平面,并且使得样本数据集中所有数据到这个超平面的距离最短。
按照与二维空间类似的原理,超平面的方程可表示为

假设T 为特征空间上的数据集,即
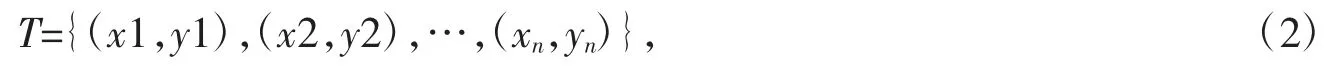
其中,yi∈{+1,-1},i=1,2,…,n,yi为类别标签,当yi=+1 时为正例,yi=-1 时为负例。
对于数据集T 和超平面,定义二者的几何间隔如下

式(4)中所表示距离为支持向量到超平面距离。
所以SVM 可以表示为以下约束最优化问题

对于线性可分的问题,可以用SVM 算法进行求解,但面对非线性可分函数,需要引入核函数,核函数的合理性在于从理论意义上来说,任何数据样本都可以找到特定映射使在低维空间中不可划分的样本到高维空间中之后线性可分。
主要的6 种核函数如表3 所示。

表3 核函数表达式
2 实验结果分析
本文采用Matlab 作为分类预测工具来对新冠疫情期间的虚假新闻进行检测,用所得数据作为训练集对SVM 分类器进行训练,在训练过程中分别采用线性核函数(Linear)、多项式核函数(Polynomia)、RBF 核函数和Sigmiod 核函数4 种核函数形式,研究不同核函数对虚假新闻检测的精准度,通过选择精准度最高的核函数分类器来作为最优检测模型。分析过程的实现使用libsvm 工具包。
2.1 参数设置
首先,对所得新闻数据分成真实和虚假两类,真实新闻集的标签设置为+1,虚假新闻集的标签设置为-1,依据所构建的7 个特征属性分别对每条数据进行计算赋值。
其次,为了提高分类结果准确性和分析过程的高效性,将6 个相互有相关关系的特征值进行加总作为分类器训练的第一维属性,提取一个独立性特征较显著的特征属性作为第二维属性。处理后的二维特征属性值的部分情况如表4 所示。将特征总值作为x 轴,单个特征值作为y 轴,得到原始数据散点分布图如图2 所示。
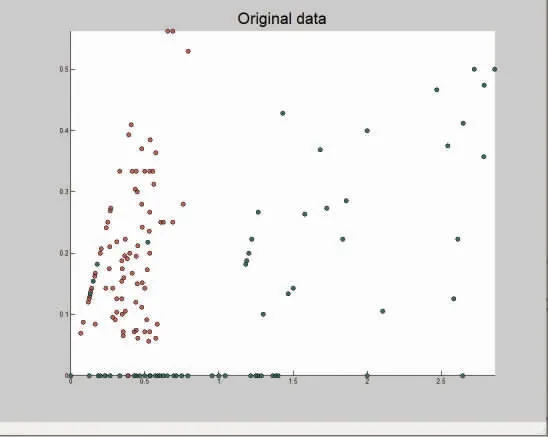
图2 原始训练数据散点图

表4 处理后二维特征属性
2.2 不同核函数分类结果
利用libsvm 工具包,采用4 种不同核函数对训练集进行训练得到的分类结果如下:
线性核函数:Accuracy=88.7097% (165/186) (classification)
多项式核函数:Accuracy=55.3763% (103/186) (classification)
RBF 核函数:Accuracy=62.3656% (116/186) (classification)
sigmiod 核函数:Accuracy=61.2903% (114/186) (classification)
各个核函数做对应的分类器边界线图如图3~6 所示。

图3 线性核函数分类图

图4 Polynomial 核函数分类图

图5 RBF 核函数分类图
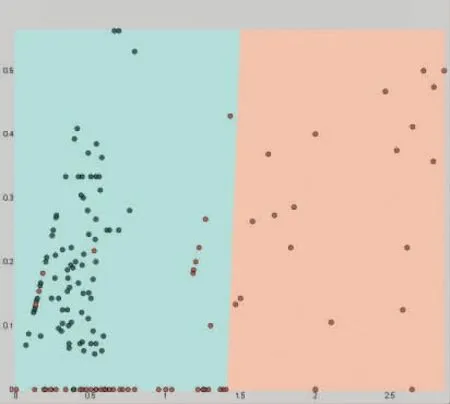
图6 Sigmiod 核函数分类图
线性核函数对数据的分类结果最好,精准度达到88.8%左右,总共186 个样本中有165 个被准确分类。RBF 核函数与Sigmiod 核函数的分类器分类效果相似度较高,二者均在61.5%左右,多项式核函数的分类效果较差,仅高于50%约5 个百分点左右。
3 结语
综上所述,在突发性公共安全事件领域,每一次新消息的产生和传播,不论真假,均调动着国民的敏感神经,对安全事件的正面或负面的影响有至关重要的影响。虚假新闻检测研究是国内新兴的研究领域,具有广阔的应用前景。目前从国内的相关研究来看,与COVID-19 相关的研究多集中于定性方面,在定量与构建模型进行虚假信息识别方面的研究还有待扩展。本文以新冠疫情事件为研究对象,以各大权威性新闻网站以及新浪微博平台为数据来源,搜寻与新冠疫情相关的新闻与言论,对数据进行标签并分类,以权威性数据为真实数据集,建立辨别真实数据与虚假数据的特征,设立7 个可进行本质识别的特征属性对模型进行训练,最后获取不通核函数的分类结果。分析结果表明,利用本文所构建的特征值和SVM 中的线性核函数方法能够对虚假新闻进行高精准度识别,分类效果较好。在未来研究中,需要结合不同的突发性公众卫生事件应用场景,提取各类事件真假信息辨别的重要特征,深究其信息产生机制,研究更高效的检测方法。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
少儿科学周刊·少年版(2015年3期)2015-07-07
