
YOLOv3-tiny的硬件加速设计及FPGA实现*
2021-12-23 06:40陈浩敏姚森敬辛文成王龙海
计算机工程与科学 2021年12期
陈浩敏,姚森敬,席 禹,张 凡,辛文成,王龙海,任 超
(1.南方电网数字电网研究院有限公司,广东 广州 510623;2.天津大学电气自动化与信息工程学院,天津 300072)
1 引言
随着人工智能浪潮的不断迭起,各种网络模型层出不穷,在图像分类领域有:AlexNet(Alex Network)[1]、VGGNet(Visual Geometry Group Network)[2]、GoogLeNet(Google LeNet)[3]和ResNet(Residual neural Network)[4]等,在目标检测领域有:RCNN(Regions with CNN features)[5]、Fast RCNN(Fast Regions with CNN features)[6]、SSD(Single Shot multibox Detector)[7]和YOLO(You Only Look Once)[8]等。表1列举了几种典型的图像分类网络模型,从表1中可以看出,网络模型的精度越来越高,但随之而来的是网络的结构越来越复杂,网络的规模越来越大,因此网络模型的训练及前向推理过程也变得十分缓慢。表1中,GMACs表示每秒10亿(=109)次的定点乘累加运算。

Table 1 Typical image classification network models表1 典型图像分类网络模型
网络的性能越强其所需要的计算力也就越高,为了加速网络的运算通常使用专用的硬件,如现场可编程门阵列FPGA(Field Programmable Gate Array)。FPGA是一种半定制、可重构的专用集成电路,具有功耗低、灵活性好、性能强的特点。Cloutier等人[9]使用FPGA进行手写字母识别的相关加速工作,受制于当时芯片的制造工艺没能取得较好的结果。Zhang等人[10]使用HLS(High Level Synthesis)的设计方法,提出了基于Roofline的模型分析方法,在XILINX Virtex7 FPGA上实现了AlexNet网络的卷积层设计,消耗了较多硬件资源。Ghaffari等人[11]提出一种通用卷积神经网络加速框架,使用LeNet5对设计架构进行测试,未能取得较高的计算力。Lu等人[12]使用快速 Winograd 算法进行卷积运算的加速,提出了一个能够在FPGA上运行Winograd快速运算的算法架构,设计较为复杂。Li等人[13]提出一种基于FPGA的端到端卷积神经网络加速器设计方法,以此提高加速器的吞吐率,然而灵活性较差。Venieris等人[14]提出一种基于FPGA的动态可重构卷积神经网络加速框架,采用脉动阵列的方式设计硬件加速单元,动态可重构的设计需要在使用时对FPGA反复烧写,模型部署较为复杂。FPGA进行硬件加速依然存在较多的挑战,硬件加速的性能与FPGA的片上资源有直接关系,如何使用有限的硬件资源设计出高效的硬件加速架构是十分重要的研究问题。YOLOv3-tiny[15]具有优秀的目标检测能力,但模型所需的计算力依然较大,难以实现面向嵌入式领域的应用。
本文设计一种YOLOv3-tiny的硬件加速方法,并在FPGA平台上进行实现。从定点化、并行化和流水化3个角度对模型进行硬件加速设计,使用XILINX Vivado开发套件,在XILINX XC7Z020CLG400-1平台上对上述研究内容进行设计验证,分别设计了卷积、池化、上采样和YOLO Detection硬件加速IP,在Vivado IDE上完成了基于Zynq7020的片上系统SOC(System On Chip)搭建,分别从计算速度、资源利用率和功耗效率等方面对设计进行了综合性能分析。
2 基本理论
2.1 YOLOv3-tiny网络结构
YOLOv3-tiny是YOLOv3网络的精简版,其与YOLOv3模型性能的对比如表2所示。表2中FLOPS(FLoating-point Operations Per Second)表示每秒浮点运算次数,Bn表示Billion。在未对网络进行剪枝、压缩等操作之前,YOLOv3-tiny所需的计算量和权重大小远小于YOLOv3的,但模型识别精度低于YOLOv3的。主要是因为其主干网络较浅,为了提升速度牺牲了一部分精度。

Table 2 Performance comparison between YOLOv3-tiny and YOLOv3 models表2 YOLOv3-tiny与YOLOv3网络模型性能对比

Figure 1 YOLOv3-tiny network structure diagram图1 YOLOv3-tiny网络结构图
YOLOv3-tiny的主干网络由卷积层、BN层[16]和池化层等构成,预测分支网络由卷积层、上采样层和张量拼接层等组成,网络结构如图1所示。模型特征图输入尺寸为416×416×3,输出13×13×255,26×26×255 2个尺度的预测结果,主干网络由7层卷积层构成,卷积核尺寸均为3×3,步长均为1,每个卷积层之后紧跟着一个步长为2的最大池化层,池化单元尺寸为2×2,主干网络是典型的直筒型卷积神经网络结构,且卷积与池化计算统一,便于进行硬件加速实现。
多尺度的预测是YOLOv3网络的一大特点,提高了网络模型的泛化能力和检测精度。不同尺度的网格单元相结合能够增强网络对目标的预测能力。对于YOLOv3-tiny网络来说,需要设计的硬件加速单元有:卷积计算单元、池化计算单元、上采样计算单元和YOLO Detection计算单元。需要强调的是,YOLO Detection为网络输出的最后一层,作用是输出边框预测及类别判断信息,其输出结果除tw、th(tw表示网络预测边框的宽,th表示网络预测边框的高)以外均需使用Sigmoid函数进行处理。
2.2 定点化原理
定点化的计算能够显著提高计算效率,一个定点数由符号位、整数位和小数位组成,其总位宽为W,整数部分位宽为I,量化因子为W-I-1,本文使用S_float(32)、int(W)、I_float(32)分别表示原始浮点型数据、定点量化后的数据和定点数反量化的数据,三者之间的关系可用式(1)表示:
int(W)=S_float(32)*2W-I-1
I_float(32)=int(W)/2W-I-1
(1)
当总位宽与整数部分位宽固定时,即可使用式(1)进行数据的量化与反量化,将W-I-1称为量化因子,不同的量化因子具有不同的精度,量化因子越大相应的数据精度就越高。为了衡量定点化后数据损失的精度,通常将定点化之后的样本数据进行反量化,并与原始样本数据进行对比,总体的量化精度损失[17]可使用式(2)进行描述:
(2)
其中,N表示待量化的数据总个数。
定点化过程中数据整数部分位宽和量化因子的选择十分重要,前者决定了定点数所能表示的数据范围,后者决定了定点数据的精度。
2.3 并行化原理
文献[18]对卷积神经网络中的并行性做了详细介绍,本文在此基础上对并行性进行简单分析。卷积运算是网络计算中的主要计算单元,因此对并行性的分析主要针对卷积计算单元。
(1)卷积核间并行性:卷积核间并行是指每个卷积计算的卷积核是相互独立的,所有的卷积核共享输入特征图。因此,卷积核间的计算不存在相互依赖的关系,可以同时进行。
(2)特征图间并行性:特征图间的并行性是指对于输入特征图来说,每一组卷积核都有与之对应的特征图。当进行卷积计算时,每个卷积核与对应的输入特征图进行乘加计算。实际计算时可将每个特征图与对应卷积核进行并行计算,然后将计算得到的结果相加即可。
(3)特征图内并行性:一个特征图共享一个卷积核,因此可以将特征图上的卷积滑窗同时进行运算,在一个特征图上的不同位置使用共享的卷积核进行并行运算,可减少循环的次数。
(4)卷积核内并行性:以3×3的卷积核为例,整个计算过程需要进行9次乘法与8次加法运算,如果使用串行计算共需要循环9次;如果将卷积核与特征图滑窗展开为向量,可同时进行9次乘法运算,然后再进行1次加法运算即可完成整个计算。
2.4 流水化原理
流水化的设计思想被广泛应用于硬件设计中。本文以3级流水线对流水化的设计思想进行简单分析,从图2可以看出,对于3个任务,串行设计需要耗时9个时钟周期,并行设计需要耗时3个时钟周期,流水化设计需要耗时5个时钟周期。
横向比较可知:并行化的计算速度最快,但并行化的过程需要将硬件资源加倍,图2中所需的硬件资源为串行的3倍,流水化的设计无需将所有的硬件资源都加倍,但依然需要消耗额外的存储单元和寄存器等。

Figure 2 Serial,parallel and pipeline structure 图2 串行、并行和流水化结构
纵向比较可知:串行设计1次仅能计算1个子任务,并行化与流水化1次能够计算3个子任务,区别在于并行化是对彼此独立的任务1次执行多个相同的子任务,流水化是对彼此独立的任务1次执行多个不同的子任务。
因此,并行化主要面向没有数据依赖关系的任务间,流水化主要面向有相对数据依赖的任务内,流水与并行的同时应用能够大幅提高任务的运行效率。本文将网络模型的流水化抽象为2个层级,宏观上的流水化可在网络的各层级之间进行设计,微观上的流水化可在具体的层内展开设计。
3 硬件加速设计
3.1 定点化设计
(1)数据范围。
数据进行定点化之前需对数据范围进行统计,以此确定定点数的位数,本文对YOLOv3-tiny定点化前后的各层权重和偏置数据分布进行统计,并对定点化前后的数据精度损失进行对比。YOLOv3-tiny共有13层卷积层,定点化前各层权重和偏置的总体分布如图3和图4所示,从图中可知,各层权重与偏置数据主要集中分布在0附近。本文分别使用8位,16位以及32位定点数进行定点化设计,从精度损失和计算资源消耗2个方面对设计进行评估。

Figure 3 Overall distribution of weights图3 权重总体分布图

Figure 4 Overall distribution of bias图4 偏置总体分布图
为了衡量定点化后的数据精度损失,本文使用式(1)对定点化后的数据进行反量化,然后使用式(2)统计其精度损失,不同定点数定点化后各层的数据精度损失如表3所示。从表3可知,采用8位定点数(FP8)进行定点化数据精度损失较大,16位定点数(FP16)数据精度损失较小,32位定点数(FP32)几乎可达无损量化。因此,从数据精度角度来说,使用16位定点数能够满足设计要求。虽然采用8~16位的定点数也有可能满足权重精度的要求,但考虑到定点化的统一性以及定点数对中间层数据范围的覆盖能力,更少位数的定点数可能导致数据精度的下降。

Table 3 Weights and biases accuracy loss of each layer表3 各层权重和偏置定点化精度损失
通常网络模型中原始的数据类型为float,其占用4个字节的内存空间,32位定点数所需的内存空间同样为4个字节,因此不能节省存储空间,16位定点数所需的内存空间为2个字节,能够节省50%的存储空间,而8位定点数则能节省75%的存储空间。结合表3与图5可知,采用16位定点数进行定点化设计能够在数据的精度损失和资源消耗间取得平衡,因此本文使用16位定点数作为加速器整体的定点位数。
本文使用一个3×3的卷积运算对不同定点数的资源消耗进行仿真测试,结果如图5所示。从图5中可知,定点位数越高其所需的硬件资源也越多。

Figure 5 Resource consumption diagram图5 资源消耗图
(2)数据溢出处理。
对于YOLOv3-tiny网络来说,数据溢出主要出现在卷积的计算过程以及计算结果的输出中,各层的权重、偏置、输入数据只参与计算过程,无需进行数据的更新(此处指本层输入数据)。因此,权重、偏置、输入数据的溢出处理直接使用舍去高位保留低位的方法。而卷积计算过程中的数据累加,则使用更大范围的定点数据类型暂存计算结果,设计中本文使用32位定点数。对于卷积计算的最终输出结果,本文使用16位定点数进行表示,当发生数据溢出时,直接使用定点数据的最大值代替该值,避免造成更大的精度损失。对于池化层、上采样层和YOLO Detection层,其计算过程不存在数据累加、乘积等造成数据溢出的问题,因此直接使用16位定点数,当发生数据溢出时,直接使用定点数据的最大值代替该值。
3.2 计算单元并行化设计
(1)卷积计算单元。
卷积计算单元的结构如图6所示。卷积计算单元的数据输入共有2种AXI4-Stream数据流:一种用于权重和特征图数据的传输,记为INA Stream;一种用于偏置和中间计算结果的传输,记为INB Stream。
①INA Stream。

Figure 6 Structure of convolution calculation unit图6 卷积计算单元结构
输入与输出通道的循环分块因子分别记为q和p,通过改变q和p的大小即可实现对并行度的控制。对于权重数据,本文仅将本次计算所需的权重传输至片上BRAM,因此片上BRAM的大小为:p×q×k×k,其中k为卷积核尺寸。对于特征图的输入,本文设计q个3行的缓存结构,记为“Line Buffer”,通过移动与插入即可实现输入数据的缓存。对于卷积计算的滑窗,本文设计3×3的窗口,记为“Window”,将“Line Buffer”内的数据不断移动到“Window”内即可实现卷积滑窗计算的功能。对于卷积计算的特征图输出,本文使用可编程逻辑PL(Programmable Logic)内部的AXI4-Stream协议设计FIFO结构,FIFO深度设置为2。
②INB Stream。
由于循环分块因子的引入,本次卷积计算的结果需要和上次循环的计算结果累加,然后再作为本次计算的最终结果传输至片外存储。因此,需要设计片上存储结构,对本次循环所需要累加的数据进行存储,缓存大小和输出通道的循环分块因子p相等;此外,当完成一个输出通道的卷积计算时,需要将偏置与当前计算结果相加,然后再进行激活输出,偏置的片上缓存大小也同输出通道的循环分块因子p相等。
③循环分块因子。
本文使用“ARRAY_PARTITION”与“PIPLINE”指令对卷积计算单元进行优化。设置不同的循环分块因子(AXI4-Stream位宽64,一次传输4个通道,因此循环分块因子为4的倍数),进而得到不同循环分块因子下的资源消耗,结果如图7所示。从图7中可知,随着循环分块因子的增加,硬件资源的消耗几乎也成倍增加,考虑到实验平台Zynq7020的资源配置,本文最终将系统的循环分块因子设置为32,即p=q=32。

Figure 7 Resource consumption of different cyclic blocking factors图7 不同循环分块因子资源消耗
(2)池化计算单元。
池化计算单元的设计相较于卷积计算单元要简单,池化层中不存在权重与偏置,也无需设计复杂的片上存储结构与计算流程,卷积计算单元中将循环分块因子设置为32,为了保持系统设计的一致性,本文将池化层的循环分块因子也设置为32。池化层中的输入与输出通道数相等,且各通道间的池化运算不存在数据依赖,池化计算单元的设计可用图8描述。
池化计算单元的数据输入与输出均为AXI4-Srteam,由于YOLOv3-tiny中的池化步长固定为2,本文设计32个2行的缓存结构,通过移动与插入即可实现输入数据的缓存;对于池化计算的滑窗,设计2×2的窗口,将“Line Buffer”内的数据不断移动到“Window”内即可实现池化滑窗计算的功能,每完成一次池化计算即可将计算结果输出,无需进行片上存储。

Figure 8 Structure of pooled computing unit图8 池化计算单元结构
池化计算单元的优化设计与卷积层相同,本文使用“PIPLINE”对输入通道下的循环进行优化,使用“ARRAY_PARTITION”对行缓存数组进行分割。
(3)上采样计算单元。
YOLOv3-tiny中仅有一层上采样层,上采样层的输入输出特征图尺寸固定,分别为13×13,26×26,因此上采样层的设计仅针对这一组参数即可。上采样的计算过程与下采样刚好相反,上采样计算单元的设计与池化层十分类似,每完成一次上采样计算即可将计算结果输出,无需进行片上存储,其优化方式也与池化层相同,这里不再进行赘述。
(4)YOLO Detection计算单元。
YOLO Detection为网络输出的最后一层,其作用是输出边框预测及类别判断信息,图9是其输出向量示意图,输出结果除tw、th以外均需使用Sigmoid函数进行处理。图9中,tx表示网络预测边框的横向相对坐标,ty表示网络预测边框的纵向相对坐标。YOLO Detection计算单元的数据输入无需使用行缓存,也无需设计片上存储结构,数据以AXI4-Stream的形式输入,计算单元直接对输出数据进行处理,然后将结果输出,由于未涉及到片上存储,因此优化设计只需使用“PIPLINE”即可。该计算单元的设计不同之处在于Sigmoid函数的定点化硬件实现以及如何对tw、th进行特殊处理。Sigmoid函数可用式(3)表示:
(3)

Figure 9 YOLO Detection output vector图9 YOLO Detection输出向量
本文使用HLS中的“math.h”函数库对Sigmoid函数进行实现。从前文可知,16位定点数的整数位为7,小数位为8,符号位为1,因此对于一个16位定点数,其所能表示的数据为[-128,128),最小数据精度为2-8,以最小数据精度为间隔,16位定点数所能表示的数据共有65 535个。因此,能够得到等数量的Sigmoid计算输出。本文将输出结果与标准float型数据的运算结果进行对比并绘制输出曲线图,从图10可知,除点p1(-128,1)与p2(-7.625,0.5625)外,定点化后的Sigmoid输出曲线与原始曲线基本重合,将p1、p2 2个异常点剔除后,使其与标准输出相等,得到修复后的输出曲线,如图11所示。

Figure 10 Output curve before repairing abnormal points图10 异常点修复前输出曲线

Figure 11 Output curve after repairing abnormal points图11 异常点修复后输出曲线
对于YOLO Detection计算单元,不需要片上存储单元,因此本文仅使用“PIPLINE”对其进行优化。
3.3 层间流水化设计
层间流水化与层间数据的传递关系密不可分,对于ARM+FPGA架构的神经网络加速器来说,网络各层的数据传递可用图12来描述。使用FPGA构成卷积、池化等计算单元的加速器,同时常用AXI4总线进行数据传输。图12的结构中只有当卷积层或池化层的计算结束后才能开始下一层的计算,计算开始之前与计算完成之后均需要使用AXI4总线进行片外存储的数据访存,频繁的数据传输将会限制加速器的计算性能。

Figure 12 Structure of network data transmission 图12 网络数据传输结构图
由网络各层的计算特性分析可知,标准卷积层的计算需要遍历所有的输入通道数据才能得到一个完整的特征输出,因此卷积层的计算需要等上一层的计算完成之后才能进行。池化层的计算是对各个输入通道数据的下采样,通道间的计算没有数据依赖。理论上可将卷积与池化合并为一个计算单元,但此时会失去各个计算单元独立运算的灵活性。
如图13所示,本文提出网络各层间的流水化设计方法,依然设计不同的加速器计算单元,但在FPGA内部使用硬件控制器将不同的加速单元连接起来,可通过控制器选择完成计算后的数据流向,对于卷积和池化来说,当完成部分卷积计算后,可对计算完成后的数据直接进行池化运算,然后再将数据传输至片外存储,以此降低数据的传输次数,提高加速器的整体性能。

Figure 13 Pipeline structure of each network layer 图13 网络各层流水化设计结构
3.4 层内流水化设计
相对于层间来说,层内的流水化设计具有更大的设计空间,本文以卷积层的流水化设计为例进行详细的分析。流水化的设计思想是将一个大的任务分割成几个小的子任务,每个子任务对应着1级流水,任务执行时不同任务的子任务能够被同时执行,从宏观上来说一个时钟周期能够完成一个大任务的运算。如图14所示,本文将卷积层的计算分为5个子任务,分别为:行缓存、卷积滑窗、卷积计算、数据累加和计算输出,因此整个流水线为5级流水设计。

Figure 14 Pipeline structure of convolutional layer 图14 卷积层流水化设计结构
流水线的工作流程如下:首先使用行缓存对输入数据进行读取;然后卷积滑窗从行缓存提取需要进行卷积运算的特征数据;接着卷积计算单元将提取出的特征数据与不同卷积核进行卷积运算,再将计算结果传输至数据累加单元,进行不同卷积核计算结果的累加,从而得到本次计算的输出结果;最后将输出结果送入计算输出单元的FIFO单元进行临时存储,同时将上一次计算的结果输出至片外存储单元。
显然,整个流水线中卷积计算单元的计算复杂度和时间复杂度均最高,该单元需要完成大量的乘加计算,因此是限制整个流水周期的关键路径。本文给出的解决方法是在卷积计算单元内引入并行设计,使用更多的硬件资源进行计算,能够大幅降低时间复杂度,同时使用定点数据降低计算复杂度。
4 系统实验
加速器测试平台使用Z-turn Board开发板,Z-turn Board是深圳市米尔科技有限公司推出的一款以XILINX Zynq作为主处理器的嵌入式开发板,核心芯片为Zynq7020,这里不作具体介绍。
4.1 实验设计
本文使用Vivado软件对各IP进行综合设计,生成比特流文件,然后在软件开发包SDK(Software Development Kit)环境下进行YOLOv3-tiny网络的复现。实验平台的资源配置如表4所示。表4中PS(Processing System)表示处理系统。
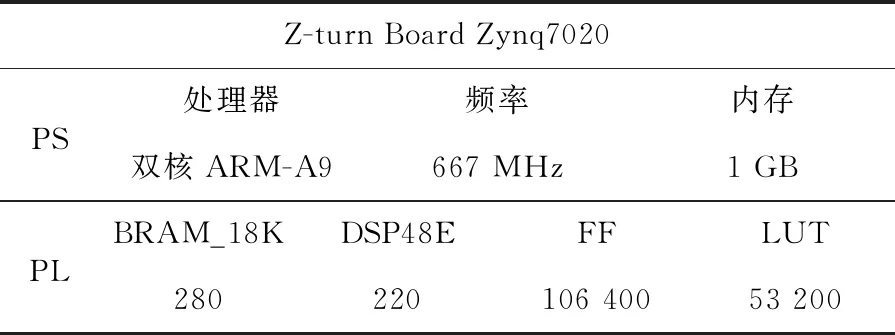
Table 4 Resource of experimental platform表4 实验平台资源
实验设计分为:仅使用ARM、使用加速器但不引入层间流水化和使用加速器并引入层间流水化3部分。仅使用ARM进行实验的设置比较简单,不作详细设计分析。

Figure 15 IP connection of accelerator without interlayer pipeline system 图15 加速器无层间流水系统IP连接
使用加速器不引入层间流水的实验设计中,系统各IP连接方式如图15所示,AXI4 Stream数据流通过AXI Switch0选择进入相应的计算单元内,待计算结束后再通过AXI Switch1将计算结果输出,各IP并行排列,每进行1次加速计算仅能使用其中1个加速器,待该计算完成后再开始新的一轮加速运算。
使用加速器引入层间流水的实验设计中,系统各IP连接方式如图16所示,AXI4 Stream数据流通过AXI Switch0选择进入卷积计算单元内,并通过AXI Switch1将卷积计算结果输出到池化等计算单元内,最后通过AXI Switch2将计算结果输出。每进行1次加速计算能使用其中2个加速器,无需进行数据的二次传输。

Figure 16 IP connection of the accelerator with interlayer pipeline system图16 加速器有层间流水系统IP连接
4.2 实验结果
实验中FPGA端的时钟频率为100 MHz,ARM端的时钟频率为667 MHz,使用系统计时器记录模型前向推理的时间段,用以评估计算延时。其中,不使用加速器的模型推理是基于Darknet框架在ARM-A9上进行实现的。使用加速器的2种模型,本文在SDK中分别设计了各自的代码框架。从YOLO官方网站可以知道,YOLOv3-tiny所需的GOPS(Giga Operations Per Second)为5.56,本文将从资源消耗、计算延时、功耗和GOPS 4个角度对实验结果进行分析。
对于GOPS,需要做相应的转换,转换公式如式(4)所示:
(4)
其中,Ts为前向推理时间。
相关实验结果如表5所示,从表5中可知:对于资源消耗,引入层间流水前后并未造成较大幅度的资源消耗,两者基本一致;对于计算延时,使用加速器能够大幅提升网络的推理速度,且引入层间流水的加速器设计的推理速度最快,是仅使用PS端进行模型推理的290.56倍,相较于未进行流水化设计的方法,层间流水能够减少48 ms的推理时间。对于片上功率,相较于未加速的设计,使用加速器后的功率增加约1 W,且采用层间流水加速的设计其功耗相对更低,因此层间流水的设计在一定程度上既降低了功耗也提高了加速器的推理速度。对于GOPS,引入层间流水的加速器设计具有最大的GOPS,且能量效率最高。
总的来说,在Z-turn Board平台上系统总体GOPS可达10.692,虽然并未达到实时推理的加速性能,但实现了高达290.56倍加速性能,对工程化实现具有一定的参考价值。此外,实验所用平台的硬件资源较为紧张,若在硬件资源更为丰富的平台上进行设计,增加网络的输入输出并行度,并提高PL端的时钟频率,相信能够获得更高的加速性能。

Table 5 Experimental results表5 实验结果
下面对系统设计的综合性能进行评估,将本文与前人的相关工作进行综合对比分析。为了能够全面地对系统设计性能进行说明,分别选取了采用不同设计思路的卷积神经网络加速器设计方法的相关文献,并从多个角度对性能指标进行对比,相关结果如表6所示。
文献[10]给出了一种专用的卷积神经网络加速器,针对AlexNet网络的前5层卷积层进行加速,并对每一层使用设计空间搜索的方法得到每层的最优设计参数。与本文的工作相比,文献[10]的加速器虽然取得了更高的GOPS,但使用了更多的计算资源,且从能量效率与GOPS/DSP来看,本文的设计要优于文献[10]的。与本文的设计目标相同,文献[11]设计了一种通用的卷积神经网络加速器,并使用LeNet5对加速器的设计进行测试,在与本文相同的实验平台上仅获得了1.62 GOPS的计算力,得益于更低的计算数据位,其单位BRAM的利用率要高于本文的。文献[19]采用混合设计的思路,对YOLOv1-tiny的第1层卷积与最后1层卷积设计专用的计算单元,其他中间层采用通用计算单元,在与本文相同的实验平台上,虽然PL端时钟频率高于本文的,但加速器的整体性略低于本文的。针对YOLOv2-tiny,文献[20]设计了一种专用的硬件加速系统,并采用低位数据对网络进行量化与再训练,其在与文献[10]相同的平台下取得了高达464.67 GOPS的计算性能,各方面设计性能均要优于本文的设计,但其可拓展性能较差且需要对网络进行二次训练,时间成本更高。

Table 6 Comprehensive comparison of system design performance表6 系统设计性能综合对比
5 结束语
本文对YOLOv3-tiny网络进行硬件加速设计,从定点化、并行化和流水化的角度分别完成了卷积、池化、上采样和YOLO Detection硬件加速IP的设计。并在Z-turn Board平台上对加速器的整体性能进行了测试,从资源消耗、计算延时、功耗和GOPS等方面对设计进行了综合性能分析。最终,本文方法获得了10.69 GOPS的有效算力,实现了1.89 fps的YOLOv3-tiny前向推理速度,系统功耗仅为2.533 W。此外,层间流水的设计方法,在未引入额外硬件资源的情况下减少了48 ms的推理时间。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
少先队活动(2021年6期)2021-07-22
文苑(2020年10期)2020-11-07
计算机技术与发展(2019年1期)2019-01-21
天津诗人(2017年2期)2017-11-29
视野(2015年6期)2015-10-13
