
KBLCC:融合实体关键字特征的医疗领域实体分类方法
2022-01-21 02:55王星予吕学强游新冬
小型微型计算机系统 2022年1期
王星予,吕学强,游新冬
(北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101)
1 引 言
大数据时代的到来为获取信息带来了便利,面对大量的信息,信息抽取可以帮助人们快速的从大量文档中获取有效的信息并对有效信息进行分析,因此信息抽取得到了广泛的应用.实体抽取是信息抽取中十分重要的内容,同时也是构建知识图谱、对话系统、机器翻译等的基础任务,近年来,随着机器学习、深度学习等方法也被广泛应用于实体抽取研究.智慧医疗的出现打破了传统医疗的禁锢[1],在互联网+医疗健康的背景下[2],人工智能在医疗健康方面的应用是大势所趋,越来越多的学者开始从事医疗领域实体抽取、关系抽取等信息抽取研究.
在现有的实体抽取研究方法中,常常将数据处理为字符级或是词级,作为模型的输入部分.词级的数据往往是通过各类分词工具得到,错误的分词结果可能会导致错误的抽取结果,分词的准确性就会直接影响到实体抽取的准确性.而词性、词频、词长、依存句法分析等可以辅助进行实体抽取的特征也大多是基于词的,如果采用字符级的数据作为输入,则无法直接融入词级特征,而目前也鲜有可用于字符级的特征.同时,现有的实体抽取研究大多聚焦在模型和方法上的改进,较少聚焦在特定领域数据的独特性上.
对于上述问题,KBLCC方法聚焦医疗领域数据,根据医疗数据特点融入字符级特征,提出一种融合实体关键字特征的医疗领域实体分类方法.抽取医疗实体中的检验指标、疾病、症状这3大类,在进行实体抽取任务的同时完成了实体分类任务,因此可以将其转化为序列标注问题.本文主要有以下3点贡献:1)构建了一个医疗领域实体抽取人工标注语料库;2)提出融合字符级的关键字特征,并采用TF-IDF辅助构建了医疗领域关键字表;3)提出了KBLCC方法用于医疗领域实体分类,搭建了融合实体关键字特征的BERT-BILSTM-CNN-CRF混合模型,融合BILSTM模型和CNN模型,BILSTM模型进行全局特征抽取,再通过CNN进行局部特征抽取,提高抽取准确性.通过进行大量对比实验,相较其他方法,使用KBLCC模型在准确率、召回率和F1值上都取得了最好的实验效果,可见KBLCC模型在进行医疗领域实体抽取并分类任务中是有效的.
2 相关工作
早期的实体识别方法一般由人工提取特征,主要是基于规则的方法和基于统计的方法.Abney[3]使用Bootstrapping自动生成规则的方法提取实体.周昆等人[4]提出基于本体论和规则匹配的中文人名识别方法,这种方法在特定语料上得到了良好的效果.吴琼等人[5]提出了一种运用统计与规则相结合的方法来识别时间表达式的方法,使用条件随机场识别时间单元,筛选出正确触发词,根据规则对时间表达式边界进行定位,得到了不错的识别效果.Kraus等人[6]通过构建正则表达式,识别了大学医疗系统临床记录中的药品、剂量等医疗实体.何云琪等人[7]提出,在统计特征上融合句法和语义将这一系列特征输入CRF模型中来识别其中的疾病实体.通过构造规则模板进行实体识别的方法需要人工构造规则,且在面对复杂数据的数据时,难以达到较好的抽取效果.
深度学习是机器学习的一个重要的发展方向,是机器学习中十分重要的领域,利用深度学习来解决NER(Name Entity Recognition)问题已经成为当前的一种重要趋势.与传统的实体识别方法相比,深度学习的最大的优势是它可以通过算法提取出处理过的数据的特征,而不需要通过人工的方法得到,且有较强的迁移能力.Peters等人[8]提出利用大量的无标记语料,来训练神经网络模型,从语言模型中学习到额外的特征,来提升序列标注任务的性能.王银瑞等人[9]提出了Trans-NER模型,运用迁移学习,双向循环神经网络进行训练,实验效果优于其他模型.Kuru等人[10]使用层叠双向长短时记忆网络的方法,来提取文本中的全局特征,实验过程中,在7种不同语言上进行了对比实验,并且都取得了良好的识别效果.Lample等人[11]提出使用BILSTM-CRF的方法,用BILSTM替换卷积神经网络来处理单词序列,并最终在多个序列标注任务上取得了较好的效果.Zhang等人[12]提出了Lattice LSTM模型,将词汇信息融入到基于字符的模型中.Liu等人[13]提出了WC-LSTM模型,该方法没有改变BILSTM的结构,而是在输入的字向量中融入词汇信息.王子牛等人[14]提出使用BERT-BILSTM-CRF模型进行中文实体识别研究,首先用BERT模型进行训练,再用BILSTM模型获取上下文特征,最后经过CRF模型解码,该方法取得了不错的实验效果.
近年来,运用深度学习方法进行医疗领域实体抽取的研究也逐渐增多.Almgren等人[15]提出一种基于字符的深度双向递归神经网络的医疗命名实体识别方法,实验结果比经典模型提高了60%.张帆等人[16]运用深度学习算法对医疗文本数据中的五大类目标实体进行识别,提升了识别效果.李慧林[17]等人提出基于块表示的神经网络模型,在医疗文本上进行命名实体识别,与传统模型实验结果相比得到了更好的F值.杨文明等人[18]提出IDCNN-BiLSTM-CRF、IndRNN-CRF这两种模型对数据集中的疾病、症状、检查、治疗4种实体进行抽取,并通过实验验证了模型的有效性.李丽双等人[19]提出了一种基于CNN-BILSTM-CRF模型的生物医学命名实体识别研究,取得了良好的实验效果.梁文桐等人[20]提出基于BERT模型来识别医疗电子病历中的实体,实验结果和基线模型相比有所提升.医疗领域实体抽取和通用领域相比,难点在于语料中的专业名词较多,待抽取实体较为复杂,因此在医疗实体抽取问题中多使用双向LSTM充分利用上下文信息以提高抽取准确性.
通过对国内外命名实体识别相关工作进行分析,可以发现,近年来在进行医疗实体抽取任务时,大多使用双向LSTM模型.还可以发现现有的实体抽取研究中鲜有基于字符级的特征,因此提出的KBLCC方法融合实体关键字特征、加入BILSTM模型进行医疗领域实体分类研究.

图1 整体结构图Fig.1 Overall structure diagram
3 医疗领域实体分类模型
KBLCC方法将医疗领域实体分类问题转化为序列标注问题,构建医疗领域关键字表,提出一种融合实体关键字的医疗领域实体分类方法,抽取数据集中的检验指标、疾病、症状这3种实体,模型整体结构如图1所示.整个模型主要分为3个模块:
1)BERT向量化模块:进行向量化操作,经过BERT预训练语言模型将标注数据以及关键字特征转化为字向量.
2)BILSTM-CNN特征提取模块:将字向量输入BILSTM中进行特征提取,再将预测结果经过CNN层进一步提取特征.
3)CRF序列标注模块:将CNN层输出的结果输入到CRF层进行标注,得到标注序列,从而实现医疗实体分类.
3.1 医疗实体关键字表
关键字又称保留字(keyword)往往是一篇文章的中心主旨,一句话中的重点,或是一个词汇中有代表性的关键信息,在自然语言处理任务中也经常会用到关键词或是关键字.聚焦医疗领域数据,研究医疗实体分类任务,通过观察、分析医疗领域数据,可以发现医疗领域数据中所要抽取的实体往往也都包含关键字信息,如表1中展示的数据示例所示,因此借助关键字信息辅助实体抽取任务.
表1 医疗领域数据
Table 1 Medical field data

数据示例实 体实体关键字血红蛋白可降低,便隐血试验阳性可能是急性糜烂性胃炎。血红蛋白、便隐血试验、急性糜烂性胃炎血、红、白、试、验、急、炎丙氨酸氨基转移酶升高,胆红素升高,提示可能为急性胆囊炎。丙氨酸氨基转移酶、胆红素、急性胆囊炎酶、红、急、炎肺癌表现为咳嗽,伴随胸闷,产生呼吸困难等症状。肺癌、咳嗽、胸闷、呼吸困难癌、咳、闷、难
用TF-IDF(term frequency-inverse document frequency)算法辅助构建关键字.考虑到关键字信息一般出现在关键词中,因此采用TF-IDF首先抽取医疗领域实体关键词,再通过关键词构建关键字.TF-IDF根据词在文中出现的次数,来评估一个词的重要程度.在使用TF-IDF来抽取关键词时,首先需要构建停用词表,去除语料中无关紧要的标点符号和词语,接下来就需要计算词频即词语在文件中出现的次数,如公式(1)所示,其中Nk是词k在文本中出现的次数N是文本中词的个数,再根据大量医疗领域数据,计算逆文档频率(IDF),计算方法如公式(2)所示,其中Y是语料文档总数Yk是包含词k的文档数,最后计算TF-IDF值如公式(3)所示.得到的TF-IDF值按降序排列,选择前800个作为提取出的关键词.接下来以人工的方法从抽取的关键词中筛选、提取关键字,由专业人员校验最终构建了医疗领域关键字表,再将关键字作为特征,与字向量一起输入模型进行实体分类,部分关键字示例如表2所示.
(1)
(2)
TF-IDFk=TFk*IDFk
(3)
3.2 BERT向量化模块
BERT[21]是谷歌公司2018年提出的一个新模型,BERT的出现刷新了11项自然语言处理任务的结果.BERT能够对句子中的语义信息进行识别,因此BERT模型生成的字向量包含着语境信息,这对医疗领域的实体抽取将会有很大的帮助,因此KBLCC方法采用BERT预处理模型生成字向量,提高生成的字向量的质量,以便达到更高的实体分类效果.
表2 医疗实体关键字表
Table 2 Medical entity key table

实体类别部分关键字检验指标白、红、血、验、值、数、积、药、色、试、氮、检、能、片、规、体、酶、养、间、原、查、质、醇、酯、率、…疾病 病、炎、瘤、染、症、虚、癌、征、疡、碍、毒、衰、疮、喘、疹、急、局、慢、血、栓、寒、核、阻、竭、塞、…症状 疼、痛、倦、难、少、咳、热、竭、闷、胀、泻、斑、瘦、苦、碍、大、肿、胀、痰、小、快、慢、感、喘、痒、…
在实验过程中,输入序列X=(x1,x2,x3,…,xn),对每个序列最开始的位置添加“[CLS]”字符,用于存储整个输入序列的语义信息,再用“[SEP]”分隔、区分句子,在每个句子的末尾加上特殊字符“[SEP]”.使用BERT模型训练词向量,需要进行3个Embedding操作,分别是词嵌入、句子嵌入和位置嵌入.
1)KBLCC方法的输入部分是字符级数据,首先进行字嵌入,就是经过BERT预训练模型对输入医疗领域实验数据进行Embedding操作,将输入的字符转化为向量.
2)接下来是句子嵌入,需要区分输入实验数据为句子A或是句子B,对标记语料N中的s个句子按句子所在位置的奇偶性进行划分,如N={n1,n2,…,nk,…,nn}若句子所在位置k为奇数,将这句话中每个字向量的Segment Embeddings定义为EA,如句子所在位置k为偶数,则定义为EB.
3)然后定义位置信息进行位置嵌入,标记该字符在输入数据中所处的位置.
4)最后将这3个Embedding对应位置生成的结果组合起来,得到BERT模型生成的向量T=(T1,T2,T3,…,Tn).
分别将语料中的字与输入的关键字特征通过BERT模型进行训练,生成字向量,作为BILSTM-CNN特征提取模型的输入部分.
3.3 BILSTM-CNN特征提取模块
LSTM(Long Short Term Memory)是1997年Hochreiter[22]等人提出的,LSTM的出现解决了一般神经网络模型存在的长期依赖问题.LSTM结构如图2所示,LSTM引入了门控结构,即遗忘门、输入门和输出门,通过门控结构实现了对信息的长期记忆,还可以实现信息的选择性记忆与遗忘.在此基础上,Graves A等人[23]提出了BILSTM(Bidirectional Long-Short Term Memory)模型,近年来广泛应用于各领域实体识别任务.

图2 LSTM结构图Fig.2 LSTM structure diagram

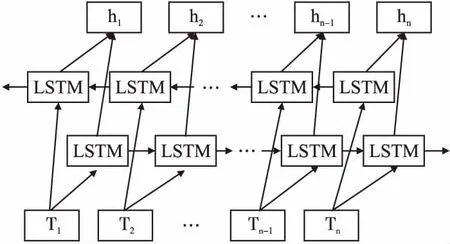
图3 BILSTM结构图Fig.3 BILSTM structure diagram
CNN(Convolutional Neural Network)是前馈神经网络中的一种,卷积神经网络的关键就在于对输入数据进行卷积操作,对数据中的隐藏特征进行提取.BILSTM有着出色的利用上下文信息的能力,对处理长距离文本中的信息有更好的效果,而CNN更适合对局部特征进行提取.
KBLCC方法将BILSTM与CNN融合进行特征提取,在BILSTM层后加入4层CNN,卷积核尺寸为(5,256)维.BERT模型生成的向量T=(T1,T2,T3,…,Tn),经过BILSTM层进行特征提取,BILSTM层输出的特征向量h=(h1,h2,h3,…,hn)包含了丰富的上下文信息、初始标记信息、关键字特征信息以及输出标记信息,再将BILSTM输出的特征向量输入CNN提取局部特征,得到输出矩阵Pn*k=(p1,p2,…,pn)其中k为定义的标签个数,Pn*k=(p1,p2,…,pn)就是输入字的各个标签打分值,如Pij为第i个字是第j个标签的打分值.但是仅依据打分值的高低进行预测,结果并不准确这就需要引入CRF模型.
3.4 CRF序列标注模块
CRF(conditional random fields),是Lafferty[24]等人在2001年提出的,常被用于词性标注、分词、命名实体识别等自然语言处理任务中,与LSTM融合解决实体抽取问题.KBLCC方法引入CRF层进行序列标注,CRF层能够对预测标签添加约束,可以在标注过程中利用已有的标注信息,比如实体中标签为“B-”的字的下一个字对应的标签应该是“I-”或“O”,CRF还能在训练过程中从数据集中学习到某些约束,比如实体中第一个字的标签应该是“B-”或“O”.
通过BILSTM-CNN特征提取模块的叙述可知,序列X=(x1,x2,x3,…,xn)经过特征提取得到了输出矩阵Pn*k=(p1,p2,…,pn),对于预测序列Y=(y1,y2,y3,…,yn)定义它的分数函数如公式(4)所示:
(4)
其中Aij为其由i标签转移为j标签的得分,各个位置分值之和为整个序列的打分值每个位置的分值由两部分组成,一部分是CRF的转移分数矩阵A,另一部分是特征提取模块的输出矩阵P.
CRF模型在进行预测时,使用动态规划算法中的维特比算法得到最优标记序列,根据最优标记序列进行标注.公式如下,其中Yr为真实标注数据序列如式(5)所示.
(5)
4 实 验
4.1 数据集和评测指标
目前可以用于医疗实体抽取的中文医疗领域的公开数据集较少,根据实际需求,本文构建了医疗领域实体抽取人工标注语料库(1)https://pan.baidu.com/s/1t-b6v3mfs_pV_InCR5Q2hQ.语料库共标注了3034条句子,句子长度在20字符到60字符之间,训练集测试集和验证集按照6∶2∶2的比例划分,训练集为1874条,测试集为582条,验证集为578条.语料库中有3种类型的实体,分别为疾病实体、检验指标实体和症状实体.3034条句子中共标注了7017个3种类型的医疗领域实体.3种实体类别的数量关系如表3所示.由表3可以看出语料库中包含的疾病、检验指标、症状实体的数量基本持平.
表3 语料库中实体标注数量表
Table 3 Number of entity labels in corpus

类别数量/个检验指标2119疾病 2298症状 2161合计 6578
表4展示了语料库的测试集验证集和训练集中3种类别的实体数量,由表4可以看出3种类别实体在训练集测试集和验证集中的数量也基本持平,保证了样本的均衡,这也为后续实验的可信度提供了保障,更能验证KBLCC方法的有效性.
表4 实体数量表
Table 4 Number of entity

类别检验指标疾病症状训练126313671286验证431471426测试425460449合计211922982161
在构建语料库的过程中考虑到医疗领域的特殊性,对数据的真实性、准确性有着较高的要求,因此语料库中的数据来源于权威的医疗领域教材中的非结构化数据,以及从一些专业可靠且权威的医疗网站,如39健康网(2)http://ask.39.net/question、快速问医生(3)http://so.120ask.com/上获取的专业医生的回答.将获取到的非结构化数据首先进行数据清洗、数据预处理,再对实验数据以及关键字信息进行标注.在对语料库中的数据进行标注的过程中,为了保证数据的真实性和增强语料的可信度,根据经过专业医疗人员校验过的检验指标、疾病、症状词典,对语料中3种类型的实体进行标注.标注样例如表5中所示,其中“B”表示医疗实体的开始,“I”表示非头实体,“-”后接实体所属类别,“jb”代表疾病类别,“zb”代表指标类别,“zz”代表症状类别.并对实体关键字特征进行标注,根据专业人员校验过的实体关键字表对关键字特征进行标注.若字符为关键字则进行标注,不是关键字则标注“无”为了验证KBLCC方法在解决医疗领域实体分类问题中是行之有效的,将F1值、准确率(P)和召回率(R)作为验证KBLCC方法有效性的评价标准,其中P、R和F1的计算公式见公式(6)-公式(8):
表5 医疗领域数据标注样例
Table 5 Examples of data labeling in the medical field

食 无B-jb管 无I-jb癌 癌I-jb有 无O的 无O病 无O例 无O可 无O有 无O咽 无B-zz下 无I-zz食 无I-zz物 无I-zz梗 无I-zz阻 无I-zz感 感I-zz,无O出 无O现 无O胸 无B-zz骨 无I-zz疼 疼I-zz痛 痛I-zz和 无O食 无B-zz管 无I-zz内 无I-zz异 无I-zz物 无I-zz感 感I-zz
(6)
(7)
(8)
4.2 实验环境及模型参数配置
通过进行实验可以发现实验环境及模型参数,会对实验结果造成影响,因此分别列举出实验环境和部分模型参数.本实验采用的是深度学习中的tensorflow框架,模型训练环境配置如表6所示.
表6 训练环境配置
Table 6 Training environment configuration

操作系统Ubuntu16.04GPU8*Tesla V100GPU显存16Gpython3.6tensorflow1.14.0
在训练医疗实体分类模型KBLCC进行医疗实体分类任务的过程中,通过进行大量的对比实验以及对模型中的参数进行微调,依据实验效果最终将模型各部分参数设置如表7所示.
4.3 实验结果分析
本文基于构建的医疗领域语料库进行了以下5组对比实验观察实验效果,实验结果如表8所示.
实验1.采用张应成等人[25]提出的BILSTM-CRF模型,在BERT模型出现之前是常用的实体抽取方法.
实验2.采用BERT-CRF模型,采用BERT模型生成字向量,将生成的字向量输入CRF模型进行训练,完成医疗实体分类任务.
表7 模型参数设置
Table 7 Model parameter settings

参数名称参数值BILSTM模型层数1CNN模型层数4batch-size32dropout值0.5max_seq_length202learning_rate1e-5
实验3.使用王子牛等人[14]提出的BERT-BILSTM-CRF模型,BERT模型生成字向量,BILSTM-CRF模型训练,这也是目前最为常用的实体抽取模型,在众多领域的实体抽取任务中取得了良好的效果.
实验4.采用BRET-BILSTM-CNN-CRF模型,在实验2模型的基础上加入4层CNN,学习局部特征以提高准确率.
实验5.采用KBLCC方法将医疗领域实体关键字特征融入BERT-BILSTM-CNN-CRF混合模型进行实体分类任务.
表8 模型实验结果
Table 8 Model experiment results
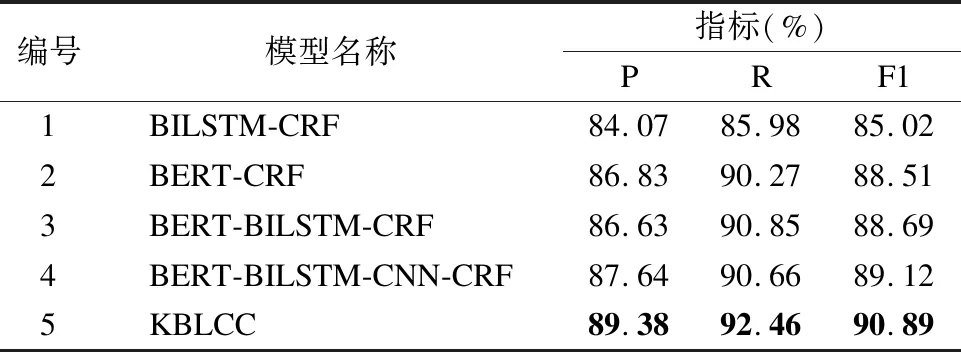
编号模型名称指标(%)PRF11BILSTM-CRF84.0785.9885.022BERT-CRF86.8390.2788.513BERT-BILSTM-CRF86.6390.8588.694BERT-BILSTM-CNN-CRF87.6490.6689.125KBLCC89.3892.4690.89
首先对实验1和实验3结果进行比较,实验3在实验1的基础上采用BERT模型进行字嵌入效果有较大的提升,准确率、召回率、F1值分别提升了2.56%、4.87%和3.67%,可见采用BERT模型进行字嵌入能够较大的提升实验效果.实验2和实验3的实验结果进行比较,实验3在实验3的基础上加入BILSTM模型在召回率和F1值上都略有提升分别提升了0.58%和0.18%.实验4加入了CNN后实验效果较实验3也有所提升,准确率提升了1.04%,F1值提升了0.43%,验证了在特征提取层加入CNN提取局部特征对实验效果的促进作用.实验5在实验4基础上融入实体关键字特征,在各个评测指标上效果都有了一定的提升,其中召回率提升了1.8%,准确率提升了1.74%,F1值提升了1.77%,在进行对比实验中KBLCC方法取得了最好的实验结果,可见融入实体关键字特征的KBLCC方法是有效的,能够在较大程度上提升医疗实体分类实验效果.
图4为模型结果柱状图,图中展示了5组实验的准确率、召回率和F1值.通过柱状图更加直观的展示了5个对比实验的实验结果以及3个评价指标的变化情况,从总体来看KBLCC方法的实验效果最好,5个实验的实验效果总体上呈上升趋势,每种实验方法对实验效果的提升有所不同,其中采用BERT生成字向量的实验效果提升最大,在都采用BERT模型进行字嵌入的实验2、实验3、实验4和实验5中,加入实体关键字特征的实验5实验效果提升最大.
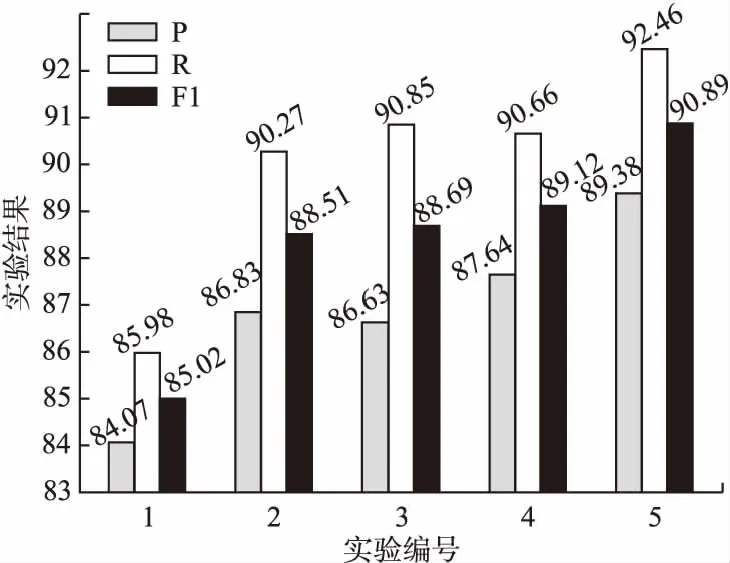
图4 模型实验结果柱状图Fig.4 Histogram of model experiment results
为了更好的展示KBLCC方法在进行医疗实体抽取并分类任务中的准确性,表9中列举了实验过程中的部分样例,从表9可以看出,第1个例子BERT-BILSTM-CNN-CRF方法抽取的检验指标实体为网织红细胞数,抽取结果并不准确,而融入了实体关键字特征“红”、“数”、“值”后的KBLCC方法抽取出更为准确的检验指标实体为网织红细胞数绝对值,在第2个例子中融入实体关键字特征“红”、“数”抽取出的检验指标实体红细胞计数要比未融合实体关键字特征抽取出的检验指标实体红细胞更加准确,第3个例子中KBLCC方法抽取出的症状实体为情绪波动大比未融合实体关键字特征模型抽取出的情绪波动更加准确,第4个例子中采用BERT-BILSTM-CNN-CRF模型抽取出症状实体尿,所抽取的实体及实体的类别都不准确,而采用KBLCC模型融入了实体关键字特征“比”抽取出检验指标类型的实体尿比重,得到了正确的 实体及实体正确的类别.显然采用KBLCC模型能够得到更好的抽取效果,能够更加准确的对医疗实体进行抽取并分类.
表9 实验部分样例展示
Table 9 Sample display of experimental part

实验模型标注结果抽取结果BERT-BIL-STM-CNN-CRF纯 B-jb/红 I-jb/细 I-jb/胞 I-jb/再 I-jb/生 I-jb/障 I-jb/碍 I-jb/性 I-jb贫 I-jb/血 I-jb/患 O/者 O/网 B-zb/织 I-zb/红 I-zb/细 I-zb/胞 I-zb数 I-zb/绝 O/对 O/值 O/减 O/少 O/。O纯红细胞再生障碍性贫血;网织红细胞数KBLCC纯 B-jb/红 I-jb/细 I-jb/胞 I-jb/再 I-jb/生 I-jb/障 I-jb/碍 I-jb/性 I-jb贫 I-jb/血 I-jb/患 O/者 O/网 B-zb/织 I-zb/红 I-zb/细 I-zb/胞 I-zb数 I-zb/绝 I-zb/对 I-zb/值 I-zb/减 O/少 O/。O纯红细胞再生障碍性贫血;网织红细胞数绝对值BERT-BILSTM-CNN-CRF红 B-zb/细 I-zb/胞 I-zb/计 O/数 I-zb/减 O/少 O/及 O/血 B-zb/红 I-zb/蛋 I-zb/白 I-zb/降 O/低 O/,O/提 O/示 O/可 O/能 O/为 O/各 O/种 O/贫 B-jb/血 I-jb/性 I-jb/疾 I-jb/病 I-jb/。O红细胞;血红蛋白;贫血性疾病KBLCC红 B-zb/细 I-zb/胞 I-zb/计 I-zb/数 I-zb/减 O/少 O/及 O/血 B-zb/红 I-zb/蛋 I-zb/白 I-zb/降 O/低 O/,O/提 O/示 O/可 O/能 O/为 O/各 O/种 O/贫 B-jb/血 I-jb/性 I-jb/疾 I-jb/病 I-jb/。O红细胞计数;血红蛋白;贫血性疾病BERT-BILSTM-CNN-CRF根 O/据 O/你 O/描 O/述 O/情 B-zz/绪 I-zz/波 I-zz/动 I-zz/大 O/的 O/情 O/况 O/,O/考 O/虑 O/应 O/该 O/是 O/属 O/于 O/更 B-jb/年 I-jb/期 I-jb/综 I-jb/合 I-jb/症 I-jb/。O/情绪波动;更年期综合症KBLCC根 O/据 O/你 O/描 O/述 O/情 B-zz/绪 I-zz/波 I-zz/动 I-zz/大 I-zz/的 O/情 O/况 O/,O/考 O/虑 O/应 O/该 O/是 O/属 O/于 O/更 B-jb/年 I-jb/期 I-jb/综 I-jb/合 I-jb/症 I-jb/。O/情绪波动大;更年期综合症BERT-BILSTM-CNN-CRF尿 B-zz/比 O/重 O/降 O/ 低O/,O/提 O/示 O/可 O/能 O/为 O/尿 B-jb/崩 I-jb/症 I-jb/引O/起 O/的 O/多 B-zz/尿 I-zz/。O/尿;尿崩症;多尿KBLCC尿 B-zb/比 I-zb /重 I-zb /降 O/ 低O/,O/提 O/示 O/可 O/能 O/为 O/尿 B-jb/崩 I-jb/症 I-jb/引O/起 O/的 O/多 B-zz/尿 I-zz/。O/尿比重;尿崩症;多尿
在采用KBLCC方法抽取医疗实体中的检验指标、疾病和症状这3种类别实体的过程中,通过对比实验发现加入实体关键字特征对不同类别的实体抽取效果的提升程度有所不同.为了观察分析加入实体关键字特征对这3类实体抽取的影响情况,将实验4、实验5中不同类别实体的实验结果展示如表10所示.
表10 实验3、实验4中不同实体类别实验结果
Table 10 Experimental results of different entity types in experiments three and four
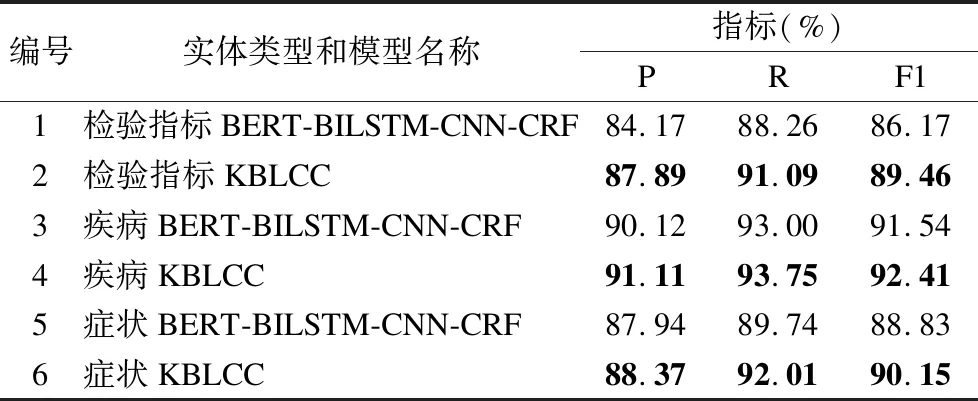
编号实体类型和模型名称指标(%)P RF11检验指标BERT-BILSTM-CNN-CRF84.1788.2686.172检验指标KBLCC87.8991.0989.463疾病BERT-BILSTM-CNN-CRF90.1293.0091.544疾病KBLCC91.1193.7592.415症状BERT-BILSTM-CNN-CRF87.9489.7488.836症状KBLCC88.3792.0190.15
由表10可知,融入实体关键字后对检验指标、疾病、症状的抽取效果都有一定的提升.为了更直观地展现出加入实体 关键字特征对这3类实体抽取效果的影响,将加入实体关键字后不同实体类别的评价指标的提升值绘制成了折线图,如图5所示.
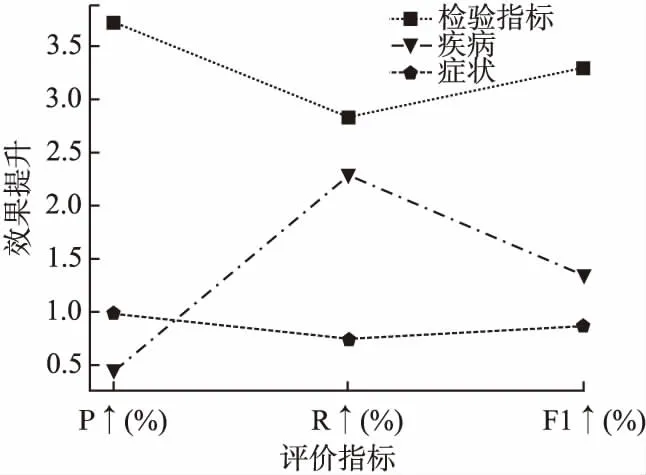
图5 融入实体关键字不同实体类别提升图Fig.5 Integrate entity keywords into different entity categories
图5中横坐标从左到右分别为准确率、召回率、F1值的提升值,折线图展示了加入实体关键字特征后检验指标、疾病、症状的提升情况.通过折线图可以清晰的看出,加入实体关键字特征后实验效果都有所提升,其中检验指标的各项评价指标提升最多,相对来说疾病的效果提升较小.同时从表10中可知,抽取疾病实体的各项评价指标分值最高,而检验指标的分值最低.检验指标这类实体的表述相对复杂,且种类较为繁多、名称偶有生僻,如麝香草酚浊度试验、天门冬氨酸氨基转移酶等,容易导致抽取效果较低,检验指标实体中也包含着较多的关键字,这些关键字能够帮助抽取出医疗实体,因此加入关键字特征后效果明显.通过进行对比实验以及对检验指标、疾病、症状3类实体抽取结果进行分析,可知使用KBLCC模型进行医疗领域实体分类能够提高准确率、召回率和F1值.
5 总结与展望
KBLCC方法旨在研究医疗领域实体抽取及分类问题,针对目前存在的中文医疗领域公开数据集较少以及在实体抽取研究中字符级特征较少等问题,构建了一个医疗领域实体抽取人工标注语料库,提出一种融合实体关键字特征的医疗领域实体分类方法.通过对大量医疗领域数据进行观察,发现待抽取的医疗实体中通常包含着一些明显的关键字信息,采用TF-IDF辅助构建关键字表,将这些关键字作为特征输入模型,采用BERT模型进行文本向量化操作生成字向量,将字向量输入BILSTM-CNN混合模型学习特征,再经过CRF层进行序列标注,最终实现医疗实体分类.经过对比实验,KBLCC方法取得了最好的实验结果.因此,采用KBLCC方法能够有效地解决医疗领域实体抽取及分类问题,能够提升实验结果的准确性.本文尚未研究关键字实体所处的位置对实体分类问题的影响,希望在后续的研究过程中能够对实验进一步的完善,达到更好的实验效果.文中提出的KBLCC方法所做实验基于医疗领域数据集,验证了在医疗领域的有效性和准确性.在解决其他领域的实体抽取及分类问题时,考虑到各领域实体一般都具有该领域的关键字特征,因而本文提出的KBLCC方法也可供其他领域借鉴,这也将成为本文后续的研究内容.
猜你喜欢
智能计算机与应用(2022年6期)2022-06-23
华人时刊(2022年1期)2022-04-26
动漫界·幼教365(大班)(2019年10期)2019-10-28
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
现代出版(2014年6期)2014-03-20
环球时报(2009-11-25)2009-11-25
小学生作文辅导·看图读写(2009年5期)2009-06-11
