
基于BiLSTM+Self-Attention的多性格微博情感分类
2022-01-24 08:36冯媛媛刘克剑李伟豪
西华大学学报(自然科学版) 2022年1期
冯媛媛,刘克剑,李伟豪
(西华大学计算机与软件工程学院,四川 成都 610039)
近年来,微博已成为最受欢迎的社交网络平台之一。人们可以通过微博随时、随地分享和交流信息,表达情感和发表观点,实现信息的即时分享、传播互动。截至2020 年10 月,微博月活跃用户已达5.23 亿。微博所携带的大量信息流尤其是公众情感,对舆论起着重要作用。
情感分类是情感分析的研究主题之一,根据情感极性对文本进行分类。一般地,情感极性分为3 类:积极、中性和消极。现有的情感分类技术主要分为:基于情感词典的分类方法、基于传统机器学习的分类方法和基于深度学习的分类方法。基于词典的方法主要利用情感词典和语言规则进行情感分类。Turney 等[1]计算评论中的情感极性均值,并将其作为评论整体的情感极性。同时,有研究[2-4]表明,否定词、程度副词等对于判断整个句子的情感极性有相当大的影响。王银等[5]在大连理工大学的情感词汇本体库基础上,构建了程度副词词典、否定词词典、网络用语词典、表情符号词典以及关系连词词典5 个词典,通过权值计算微博文本情感值。张公让等[6]通过建立程度副词词典、否定词词典和情感词典,对各家快递服务的客户评价实现了情感预测。虽然基于词典的方法可以获得很好的分类效果,但是该方法严重依赖于情感词典,灵活性和适应较差。
基于传统机器学习的方法通常是从语料库中提取有效的文本特征,实现情感分类。Zhang 等[7]将条件随机场(CRF)运用到文章句子的语境分析中,通过分析句子的语境,有效提取情感特征,实现情感分类。Gao 等[8]调查了用户容忍度和商品知名度对情感分类的影响,提出了一种近似解码算法(approached decoding algorithm)对商品评论进行情感分类。冯成刚等[9]比较了常用的3 种机器学习算法(SVM、NB 和K最邻近算法)、3 种特征选择方法(信息增益、互信息、加权似然对数)以及特征权重方法(布尔权重、词频权重,词频-逆词频)对中文微博情感分类的影响。Haque 等[10]利用线性SVM、梯度下降和随机森林等机器学习方法对亚马逊3 个种类的商品评论进行情感分类,其中SVM 在音乐领域的分类效果最好。基于传统机器学习的情感分析方法分类效果趋于更准确,但它依赖于带有标记的语料库的质量。
基于深度学习的方法主要是利用词向量对文本中的词语进行表示,进而构建句子级或篇章级的语义表示,通过采用深度学习模型学习文本中的情感特征,实现情感分类。目前大多数情感分类主要采用基于深度学习的方法。胡荣磊等[11]将长短记忆网络(LSTM)与注意力机制结合,对酒店评论文本进行了情感分析。Xu 等[12]在LSTM的基础之上,引入了一种缓存机制来帮助循环单元更有效地保存情感信息。贵向泉等[13]提出将时序卷积网络(TCN)与BiLSTM+Attention 模型相融合的文本情感分类方法,利用TCN的因果卷积和扩张卷积结构获取更高层次的文本序列特征,并通过双向长短期记忆网络进一步提取全局特征,最后,引入自注意力机制(self-attention)帮助模型优化特征向量,提高情感分类的准确度。
由于微博有字数限制,文本偏口语化、生活化,使用网络流行语和表情符,因此,对于实现微博文本情感分类来说是一个挑战。学者们提出了一些方法来提高情感分类的准确率。金志刚等[14]结合表情符和文本情感特征,通过CNN 捕获局部特征,并将其作为情感分类器的输入,训练出微博情感分类器。李勇敢等[15]从中文微博观点句识别、情感倾向性分类和情感要素抽取3 个方面实现了中文微博情感自动分析。针对现有大多数微博文本情感分析未结合深度学习模型和情感符号的情况,张仰森等[16]提出了一种双重注意力模型的方法,构建了一个包含情感词、否定词、程度副词、网络词和微博表情符的微博情感符号库,通过将注意力模型和情感符号相结合,有效增强了捕获微博情感语义的能力。Barbosa 等[17]在普通文本特征的基础上,提取了微博文本特有的一些特征,包括转发、回复、hash-tag、URL、标点符号、表情符号以及以大写字母开头的单词数目等,采用有监督的方法实现Twitter 文本的情感分类。
值得注意的是,目前大多数情感分类研究忽略了用户性格这一因素。心理学研究表明,性格会影响人们的表达方式。不同性格的人在表达情感时,表达方式会有所不同[18]。心理学领域的“大五”理论,定 义 了5 种 人 格 特 征,分 别 是 开 放 性(openness)、责任性(conscientiousness)、外向性(extroversion)、宜 人 性(agreeableness)、神 经 质(neuroticism)。外向型人格的人在表达时使用的词语通常与社交活动、家人相关。拥有高宜人人格的人更具有同情心、乐于助人,与人相处融洽。责任型人格的人通常比较可靠,有责任心,自律。刘亦真[19]基于微博平台,分析研究了不同人格倾向的微博用户在情绪表达上的特点。Verhoeven 等[20]在短文数据集上训练性格分类模型,将其输出作为元特征来预测Facebook 用户的性格特征。张岩峰等[21]利用微博用户的文本及行为等特征,使用提升决策树、支持向量机以及贝叶斯逻辑递归3 种机器学习方法进行实验,得出通过微博的文本特征和非文本特征都能分析出用户人格特质的结论。
在以上情感分类研究中,大多数在提取文本情感特征时,并没有考虑到用户性格特征,但也有研究者结合了用户性格特征。袁婷婷[22]通过建立性格词典并利用LTSM 模型对不同性格的文本进行情感预测,但忽略了上下文语境信息也会影响情感分析。贾莉等[23]在结合用户性格信息的基础上利用BiLSTM 模型,在微博文本情感预测上虽然有所提升,但未充分利用到文本的局部信息。吴小华等[24]提出了BiLSTM 结合自注意力机制的模型来进行情感预测,但没有考虑到性格对语句表达有所影响这一因素。为此,本文在结合用户性格信息的基础上,提出了一种利用双向长短期记忆网络和自注意力机制来实现微博情感分类的方法。该方法通过提取不同性格的用户情感特征,分别训练出各自的基本分类器,再采用集成学习策略进行结果融合,进而实现情感分类。
1 相关研究工作
1.1 大五人格模型
大五人格模型是研究者运用最广的一种模型。大五人格模型将人格划分为5 个维度:开放型、外向型、宜人型、责任型和神经质型。表1 列出了不同人格的主要表现。
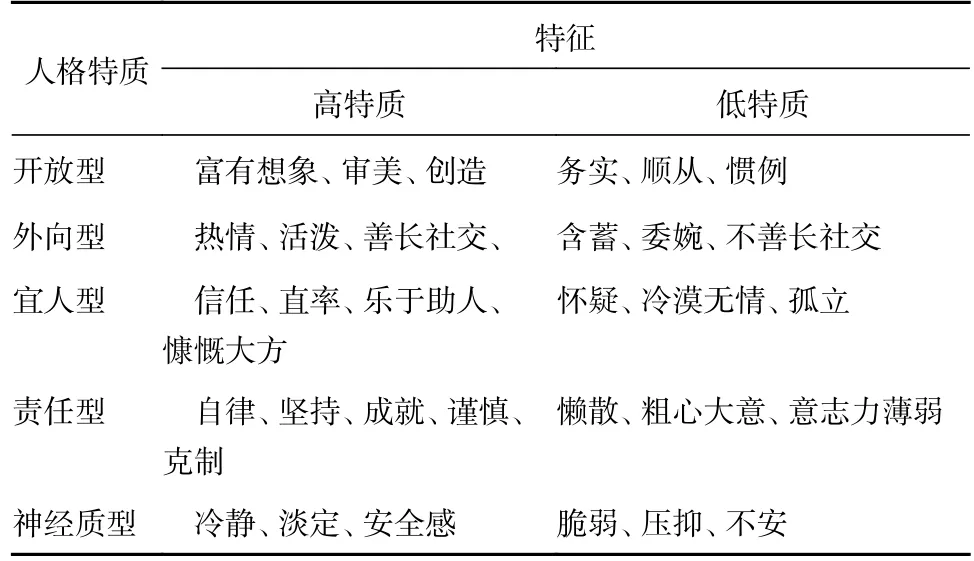
表1 大五人格特征
在对微博文本进行情感分析时,笔者发现不同性格有不同的表达特点,例如:高外向型人格在表达时通常使用“聚会”“团队”“老铁们”等与家人、朋友以及社交相关的词语;低外向型人格则会使用“宅”“安静”等词语。为了能够增强这些词语对情感表达的贡献率,更好地提取不同性格的深层次情感特征,本文在BiLSTM的基础上采用了自注意力机制对微博中词语的重要程度进行权重分配。
为了有效提取不同性格的情感特征,需要对微博用户的性格进行预测和分类,因此,本文提出了一种基于规则的性格分类方法来对微博用户的性格进行预测和分类,根据性格分类结果,将微博文本进行分组,并分别提取不同性格分组的文本情感特征。该方法能够充分利用用户性格信息有效提取情感特征。
1.2 双向长短期记忆网络(BiLSTM)
循环神经网络(RNN)是传统前馈神经网络的延伸。然而,标准的RNN 却有梯度消失和梯度爆炸问题。为了解决这2 个问题,Hochreiter 等[25]提出了长短期记忆网络(LSTM),但是,LSTM 只能获取正向的信息,无法获取逆向的信息。对于文本来说,理解前后文信息对其更加有帮助。BiLSTM 由一个正向的LSTM 和一个逆向的LTSM 所组成,能够同时获取上下文信息[26]。BiLSTM 结构图如图1 所示。

图1 BiLSTM 模型结构

1.3 自注意力机制(self-attention)
自注意力机制[27],就是将注意力集中在需要重点关注的目标上,分配更多的权重,获取目标的更多细节信息,忽略不重要的信息。自注意力机制是对自己本身的词语进行Attention 计算,不用考虑直接距离长短,能够充分考虑句子之间、不同词语之间的语义及语法联系,捕获句子的内部结构。其计算公式为

式中:Q,K,V为模型中计算得到的向量矩阵;f(Q,KT)计算Q和K的相似度;dk为词向量维度;起调节作用,通过Softmax 函数进行归一化。
2 结合BiLSTM 和自注意力机制的微博情感分类模型(P-BiLSTM-SA)
基于性格特征,结合双向长短记忆网络和自注意力机制,本文提出了一种BiLSTM 和自注意力机制相结合的微博情感分类模型(P-BiLSTM-SA 模型),总体结构如图2 所示。首先,将用户性格相似的文本归为一类,因为相同性格的人,其表达方式具有相似性;接着,对文本进行预处理并利用word2vec 训练出词向量,形成词向量矩阵;然后,将各组词向量矩阵分别作为BiLSTM的输入,经过BiLSTM 层输出后进入Self-Attention 层,对特征进行权重赋值,提取深层次的情感特征,从而训练出5 个基于不同性格的情感分类器和一个通用情感分类器;最后,根据集成学习融合分类器预测结果,输出最终情感分类结果。图2 中:E、A、C 分别表示外向型、宜人型、责任型;H 和L 表示性格的高、低特质,例如HE 为高外向型,LE 为低外向型;All 表示通用文本,即数据集中所有微博用户的文本。

图2 模型总体结构
2.1 基于微博用户性格的文本分组
本文采取基于规则的方法来对用户性格进行预测。在进行性格预测时,由于开放型和神经质型较难区分[28-29],所以本文只考虑了其余3 种人格:外向型、宜人型和责任型。
2.1.1 特征表示
微博用户发表的微博内容包括了图片、视频、地理位置信息等。同时,用户在微博中的交互行为[30]会在一定程度上反映出该用户真实性格。为此,本文结合了文本信息和用户行为特征综合预测用户性格。表2 示出了用户微博信息中的具体特征表示。

表2 特征表示
2.1.2 性格分类
熵权法是一种确定多因素综合评价问题中各因素权重系数的有效方法。本文利用该方法计算影响性格判定的指标权重,从而计算出影响性格判定的最终值。具体步骤如下。
1)将各指标进行标准化,得到标准化值Y,其中Ypc,Yv,Yl,Ym,Yli,Yc,Yre,Yf,分别为指标Photo_Comment_Num,Video_Num,Location_Num,Mention_Num,Like_Num,Comment_Num,Retweeted_Num,Follower_Num的标准化值。
2)根据Ej=计算出各指标的信息熵。通过信息熵计算出各指标的权重。Ej表示第j个指标的信息熵;pij表示在第j个指标前提下,第i个用户在该指标中的概率。其权重计算公式为

式中Wi表示第i个指标的权重,即Wpc,Wv,Wl,Wm,Wli,Wc,Wre,Wf,分别为指标Photo_Comment_Num,Video_Num,Location_Num,Mention_Num,Like_Num,Comment_Num,Retweeted_Num,Follower_Num的权重。
3)计算影响性格判定的最终值,并根据表3进行性格判定。表中:C(u)、J(u)、Y(u)分别表示微博用户u的微博内容丰富程度、交互主动性以及影响力;k1,k2,k3,k4,k5,k6为判定式的阈值。

表3 判定规则
a.外向型人格。
外向型人格的人一般喜欢参加各类社交活动,与他人分享自己的经历[17],所以发表的微博数量较多,通常带有图片、小视频或者地理位置信息,并且能获得较多的点赞和评论。此外,外向型的人与他人的互动也较为频繁。因此,外向型的人往往会在他们的微博中更多的提及(@)他人,参与互动;具有内向型人格的人发表较少的微博,获得的点赞、评论以及转发也非常少。微博用户u发表的微博内容特征计算公式为

b.责任型人格。
具有责任型人格的微博用户发表的微博更倾向于表达自律、责任感及条理等内容,发表的微博能够受到更多的关注,影响力较大,受到转发数、点赞数以及@数这3 个因素影响。微博用户u的微博影响力[31]计算公式为

c.宜人型人格。
宜人性型人格的人性格开朗,助人为乐、谦逊、值得信赖,充满正义感,拥有较多的粉丝,由于比较重视自己的形象,所发布的微博通常充满积极性和正能量。被转发微博的数量越多,该用户的交互主动性[30]就越高,同样的,粉丝数量对交互主动性也有影响。微博用户的交互主动性计算公式为

各阈值的确定依据了微博用户分别在外向型、责任型和宜人型3 类性格计算中得到的各类性格最终值的平均值和标准差。为了平衡数据,取标准差的算术平方根。如果其值高于平均值与算术平方根之和,则该用户为高特质;如果其值低于平均值与算术平方根之差,则该用户为低特质。
2.2 结合BiLSTM 和self-attention的情感分类器构建
在本文中,基于用户性格以及通用文本的情感分类器皆是由BiLSTM+self-attention 机制训练得到,网络结构如图3 所示。

图3 基于性格分类的情感分类器构建
2.2.1 BiLSTM 层
对于微博文本,为了更准确地理解词的语义信息,需要考虑前后文本联系,且词与词之间具有长程相关性。虽然LSTM 能够捕获较长距离的语义依赖关系,但是普通的LSTM 只能捕捉正向的语义信息,忽略了逆向的语义信息。BiLSTM 模型由一个正向的LSTM 和一个逆向的LSTM 组成,能够同时捕捉句子的前后文信息。因此,本文采用BiLSTM 模型对微博文本进行语义信息编码。对于一条微博文本{v1,v2,···,vt}(vt∈Rd,vt为词向量矩阵,d为词向量维数),则BiLSTM 模型输出为h={h1,h2,···,hN},H∈RN×d,N为句子长度,d为隐藏层维度。
2.2.2 self-attention 层
自注意力机制通过对BiLSTM 每一个输出状态hi加权,从而得到一个既联系上下文信息又重点突出不同性格情感特征的微博句子表示向量矩阵,为

式中:C表示句子中每个词加权后的特征表示;∂i表示第i个词对于整条微博文本的重要程度,其计算公式为

2.2.3 情感分类
模型的最后一层为全连接网络层,采用Softmax 函数作为激活函数,计算微博文本各个情感标签的预测概率,其计算公式为

式中:W=[w1,w2,···,wn]为全连接网络层的权值;b=[b1,b2,···,bn]为偏置数。
2.3 情感分类器分类结果融合


图4 情感分类器预测结果融合
3 实验与分析
3.1 实验数据
本文实验所用的数据来自于从新浪微博爬取的228 个微博用户数据,包括用户的微博内容和作者基本信息。数据集中,微博文本共10 万1 649 条。删除转发微博,并进行清洗过后,采用半自动化的方式对文本进行情感极性的标记,其中,积极微博有2 万5 138 条,消极微博有2 万3 783 条。本文按照7∶2∶1的比例将微博文本分为训练集、验证集和测试集。
同一位微博用户可能同时具有多种性格,因此会属于不同的性格集合。根据所爬取微博用户的基本信息,分别计算微博用户在外向型、宜人型和责任型的相应数值,在此基础上分别得到3 类性格类型的均值和标准差,并取标准差的算术平方根。根据2.1.2 节的方法计算得到:外向型的平均值为152.46,标准差的算数平方根为16.22;宜人型的平均值为680.01,标准差的算数平方根为45.27;责任型的平均值为1284.55,标准差的算数平方根为80.16。因 此,阈 值k1,k2,k3,k4,k5,k6分 别 为168.69,136.24,725.28,634.74,1 364.71,1 204.39。其中,在爬取的微博数据集中,低责任型性格的微博文本数量很少,所以在本文中不予考虑。基于微博用户性格的各文本分组的数据分布详情如表4所示。

表4 数据集分布
3.2 模型实验参数设置
在实验中,词向量为200 维,优化函数为Adam,损失函数为多元交叉熵。各模型具体参数如表5 和表6 所示。

表5 P-BiLSTM 和P-LSTM 参数设置

表6 BiLSTM-SA 和P-BiLSTM-SA 参数设置
3.3 实验指标评价
为了验证本文提出模型的有效性,本文采用以下4 个指标进行评价。
1)准确率(accuracy):被模型正确预测的微博文本数量占所有微博文本数量的比例。
2)召回率(recall):被正确预测为积极(消极)的微博文本数量占实际为积极(消极)的微博文本数量的比例。
3)精确率(precision):被正确预测为积极(消极)的微博文本数量占所有被预测为积极(消极)的微博文本数量的比例。
4)F1值(F1score):由精确率和召回率的加权处理得到。F1值越大,模型效果越好。

3.4 微博情感分类实验
3.4.1 模型对比实验
在本文模型中,采用了自注意力机制来学习不同性格微博用户的文本表达特征。在采用相同数据集的基础上,将本文提出的模型P-BiLSTMSA 与P-LSTM[22]、P-BiLSTM[23]以及未融入性格因素的模型BiLSTM-SA[24]进行了对比。其对比实验结果如表7 所示。
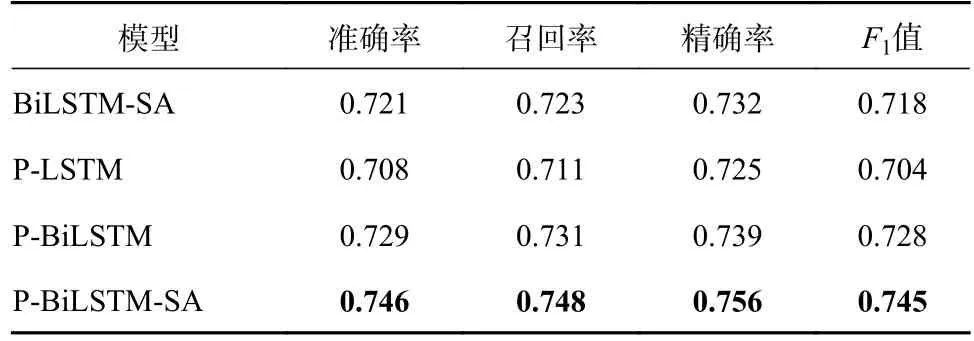
表7 模型实验对比结果
1)与BiLSTM-SA 相比,P-BiLSTM-SA的情感分类效果更好,说明融入性格因素对于微博情感分类具有一定的帮助。
2)模型BiLSTM-SA 和模型P-BiLSTM,在4 种指标上的表现相接近,说明在模型训练过程中,自注意力机制能获取到更深层次的情感信息,而且根据性格对文本分类也有利于模型提取不同性格的特征。2 种方法都对微博文本的情感分类有效。
3)与P-BiLSTM 相比,P-BiLSTM-SA 在准确率、精确率、召回率和F1上平均提升了0.017,说明利用自注意力机制关注文本的局部关键信息对情感分类有一定的帮助。
总之,对比其他3 个模型,本文模型在准确率、召回率、精确率和F1值上的效果更优。说明事先根据用户的性格对微博文本进行分类,使得模型中的自注意力机制能够有针对性地学习到不同性格的深层次情感特征,从而有利于提升情感分类效果。同时,通过集成学习方法融合各分类器输出,减少了泛化误差。
3.4.2 实例实验结果对比
性格影响人的表达方式。为了验证性格对情感分类的有效性,本文选取了另外爬取的11 位微博用户的微博文本(约1 400 条),基于P-BiLSTMSA 模型和BiLSTM-SA 模型再次进行了测试,测试结果如表8 所示,P-BiLSTM-SA 模型在4 个评价指标上的表现明显优于BiLTM-SA,再次证明了本文所提出模型的有效性。为了更加形象地对比这2 个模型的预测效果,表9 给出了一些实例的具体实验结果对比。可以看出:HC 性格的用户通常具有责任心、认真且自律;HE 性格的用户充满热情,活泼;HA 性格的用户通常直率、大方;“累”“痛苦”往往是LE 性格的用户在表达消极情绪时所具有的特征;文本(3)和文本(5)虽然都在阐述某人能力不错,但由于不同性格的表达方式有所差异,所以2 个文本表达的情感完全不同;文本(6)和文本(7)都在表达积极的情感,高特质用户倾向于积极向上的表达方式,而低特质用户的表达方式则是恰好相反,说明发表这2 条文本的微博用户虽然都是宜人型和外向型人格,表达的情感极性也相同,但因为这2 个用户在两类性格方面的高低特质不同,各自表达情感的方式也就完全不同。本文提出的模型P-BiLSTM-SA 能在训练中更好地学习到这些深层次情感信息,从而提升了微博的情感分类效果。

表8 P-BiLSTM-SA 与BiLSTM-SA 实验结果对比

表9 模型P-BiLSTM-SA 和模型BiLSTM-SA 部分实例预测结果对比
4 结论
本文基于不同性格的微博用户在表达情感时各不相同的特点,提出了一种结合性格因素的深度学习模型P-BiLSTM-SA。该方法既考虑到BiLSTM能学习文本前后文语境信息,兼顾了全文整体特征的优势,又利用self-attention 机制表示不同特征的重要性,捕获了深层次的情感特征。最后通过实验验证了本文方法的有效性。
在互联网上,表情符号、颜文字等也是人们表达情感的途径之一,未来可考虑将这些因素纳入情感分析之中。同时,许多用户在微博上采用多语言混合的方式表达情感,比如:“我今天very happy”,未来可考虑对此类文本进行语码转换以提升情感分类效果。
猜你喜欢
中国德育(2022年12期)2022-08-22
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
作文大王·低年级(2022年3期)2022-03-19
奥秘(2021年1期)2021-03-15
计算机系统应用(2021年2期)2021-02-23
意林·全彩Color(2019年8期)2019-09-23
小学生作文·小学低年级适用(2018年12期)2018-04-11
软件导刊(2017年4期)2017-06-20
校园英语·下旬(2016年2期)2016-03-18
