
一个新的上下文感知类案匹配与推荐方法
2022-01-27 13:39许梓涛黄炳森潘微科
太原理工大学学报 2022年1期
许梓涛,黄炳森,潘微科,明 仲
(深圳大学 a.大数据系统计算技术国家工程实验室,b.人工智能与数字经济广东省实验室(深圳),c.计算机与软件学院,广东 深圳 518060)
随着司法体制改革的推进,我国有关政法领域的各项改革任务逐步完成,司法体系正不断得到完善。而随着改革的推进,“类案不同判”现象成为改革中一块难啃的“硬骨头”。为了解决该问题,我国最高人民法院早在2010年11月便出台了《最高人民法院关于案例指导工作的规定》。但作为普适性文件,指导书无法全面涵盖各类案件,同时各个基层法官对案件的解读不同,对法律裁判尺度的把握也可能存在差异,“类案不同判”的问题仍得不到很好地解决。基于该背景,大数据、人工智能等现代信息技术开始应用于司法体系,辅助司法人员进行“类案同判”,进而提高司法公信力,保证司法公正并提升司法效率[1]。
类案是指与待决案件在基本事实、争议焦点、法律适用问题等方面具有相似性且经人民法院裁判生效的案件[2]。类案匹配和推荐则是利用深度学习等人工智能技术对案件裁判文书进行智能分析,进而在数据库中找到类案,达到对比分析辅助判案的目的。进行类案匹配和推荐的研究,能提高分析和匹配大量法律文本的效率,减少法官查找相似案件的时间,提高工作效率。
现有常用的类案推荐方式主要有三种[1]:1) 根据关键词进行检索(如输入“民间借贷”检索查询相关的案件);2) 选择标签进行检索,其中标签的设置较为宽泛(例如借贷、故意杀人、醉驾、入室盗窃等与案件相关的标签);3) 利用词频统计等初级的自然语言处理和文本匹配算法进行类案匹配。上述三种类案推荐方法的优点是查找速度快、运行效率高。但都缺乏对文本上下文信息和局部重点信息的提取和建模。
为了解决这一问题,本文提出了一种基于上下文感知的类案匹配和推荐方法(context-aware similar case matching and recommendation,CASCMR).通过双向LSTM(Bi-LSTM)[3]获取法律文本的上下文信息,确保模型能从两个方向上捕获文本序列信息。之后利用CNN获取文本的局部信息,从而捕获文本中的重点法律信息。训练时通过多文本间的比对来提高模型在类案匹配上的精度,得到的模型可以实现端到端的类案推荐。
本文主要贡献如下:
1) 提出了一个新的基于上下文感知的类案匹配和推荐模型,能同时解决法律人工智能中的匹配和推荐问题。
2) 根据中国“法研杯”2018(CAIL2018)的数据集,构建了一个新的三元组法律文本数据集,可用于类案推荐任务的训练与测试。
3) 将本文提出的模型应用于CAIL2019的相似案件匹配任务,与目前最好的方法相比,匹配精度的提升效果较为明显。
1 相关工作
本文提出的模型是文本匹配技术在法律人工智能中的应用,下面将对相关工作进行介绍。
1.1 文本匹配
文本匹配是自然语言处理中的一项基本任务。法律人工智能中的许多任务可以描述为文本匹配问题,如法律问答、类案匹配等。用于文本匹配的深度学习模型可以分为三类:基于单语义文档表达的深度学习模型、基于多语义文档表达的深度学习模型和直接建模匹配模式的深度学习模型[4]。
单语义模型使用孪生网络架构[5],即利用CNN、RNN等深度学习模型进行独立编码,之后在输出的高维度向量上构建分类器以预测输出结果。编码的独立性使得模型可以提前计算并存储文本向量,从而提高运算速度,但单语义模型忽略了句子的局部结构,且无法处理长序列文本。
为了解决单语义模型的缺点,多语义文档表达模型综合考虑了文本的局部信息(如单词、短语等)和全局信息(如句子、段落等),从多个粒度获取文本向量表达,从而弥补了单语义模型在学习文本表征过程中信息丢失的问题[6-9]。因此,多语义模型不仅具备单语义模型的优点,而且能从多个粒度捕捉文本信息,增强模型对长序列文本的处理能力。本文提出的CASCMR模型就是参考多语义模型进行设计的。
上述两种模型都注重优化单个文本的语义表达能力,而不能识别可用于匹配文本的有用信息。直接建模匹配模型则考虑编码过程中文本对之间的交互[8,10-12],它们结合文本对的特征,使编码器能专注于对匹配任务最有用的特征。但是,因为无法对文本进行预先编码和存储,所以存在耗时的缺点。
1.2 法律人工智能
法律人工智能(legal artificial intelligence,LegalAI)主要专注于应用人工智能技术来帮助解决法律任务。人工智能与法律的结合,不但使该领域的工作者受益匪浅,也使人们能获得更多的法律援助。近年来,LegalAI在法律判决预测、法律问答、类案匹配等方向取得了一定的研究与应用成果[13]。
法律判决预测是根据案件的事实描述和法律法条内容来预测判决结果[14-18]。最新的研究大多会考虑法条预测、刑期预测和判决预测间的相互关系[19-20],并根据三者之间的关系进行建模。法律问答则注重回答法律领域的问题,为非法律专业人士提供可靠的法律咨询服务[21-24]。类案匹配与推荐则是本文研究的问题,相关内容在引言中已做出介绍。
中国“法研杯”2019相似案例匹配评测竞赛[25]主要是针对多篇法律文书进行相似度的计算和判断。具体而言,对于每份文书提供的事实描述文本,需要从两篇候选文书中找到与查询文书更为相似的一篇文书。本文的类案匹配任务和相关数据集与该竞赛一致。
类案推荐任务是在类案匹配任务的基础上进一步提出来的,目标是从包含多篇文书的法律文本库中,找到与查询文书最为相似的若干篇文书。
2 上下文感知类案匹配和推荐模型
本文提出了一个基于上下文感知的类案匹配和推荐模型,下面首先给出问题的定义,然后介绍模型的网络架构,最后讨论如何将模型用于类案匹配和推荐任务。
2.1 问题定义
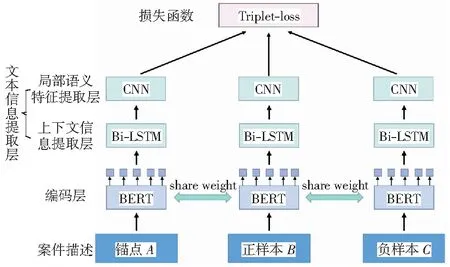
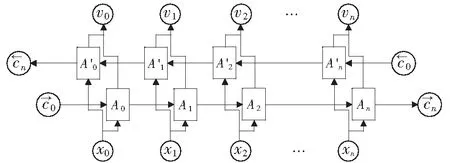
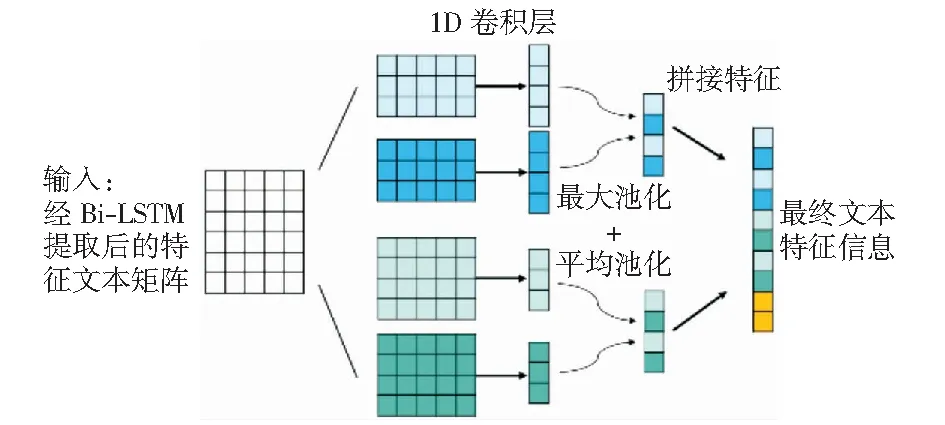
本文主要研究法律人工智能中的类案匹配和推荐问题。在训练时,给定一个四元组的集合{(da,db,dc,y)},其中da是锚文本,db和dc是样本数据,而y∈{0,1}是标签。如果y=0,表示da与db的相似度大于da与dc的相似度,即sim(da,db)>sim(da,dc).反之,当y=1时,sim(da,db) 2.1.1类案匹配 类案匹配的目标是,给定一个三元组的集合{(da,db,dc)},判断锚文本da与待匹配文本db和dc中的哪一个文本更加相似。 2.1.2类案推荐 类案推荐的目标是,对于给定的查询文本dq,从法律文本库D中找到与dq最相似的若干个文本。 本文提出的基于上下文感知的类案匹配和推荐模型的架构主要包括3层:编码层(又称词嵌入层)、上下文信息提取层和局部语义特征提取层。模型采用三元组的形式作为输入,包括锚点、正样本(类案)和负样本(非类案)。文本输入后先经过编码层进行词嵌入,再经过文本信息提取层进行特征提取,文本信息提取层又可分为上下文信息提取层和局部语义特征提取层,最后通过损失函数来实现类案靠拢和非类案远离的效果。CASCMR的架构如图 1所示,下面对各层进行详细介绍。 图1 上下文感知类案匹配和推荐模型架构示意图Fig.1 Illustration of the architecture of the context-aware similar case matching and recommendation model 2.2.1基于BERT的词嵌入 相比其他用于词嵌入的深度神经网络(例如LSTM[26]、ELMO[27]等),两阶段模型BERT[28]具有更好的普适性,其中第一个阶段是利用语言模型进行预训练,第二阶段通过微调(fine-tuning)的方式解决下游任务,让它能更适用于案情复杂的法律文本。此外,BERT的每层自注意力网络均是双向结构,能更好地建模法律文本上下文的语义信息,捕获文本长距离依赖信息。因此,使用BERT模型对文本进行编码。同时,为了让BERT更适用于法律文本领域,使用了基于中文民事文本预训练的民事文本BERT[29].对于输入的四元组法律文本数据{(da,db,dc,y)},分别求取文本da、db和dc的词嵌入向量, xwdai=BERT(da,i),xwdai∈R1×k, (1) xwdbj=BERT(db,j),xwdbj∈R1×k, (2) xwdcm=BERT(dc,m),xwdcm∈R1×k, (3) 式中:k是BERT模型的隐藏层数量。Nda、Ndb和Ndc分别代表文本da、db和dc中的token数量。 最终,通过BERT词嵌入模型,可以得到文本的词嵌入向量: Xda=[xwda1;…;xwdaNda]∈RNda×k). (4) Xdb=[xwdb1;…;xwdbNdb]∈RNdb×k). (5) Xdc=[xwdc1;…;xwdcNdc]∈RNdc×k). (6) 2.2.2基于Bi-LSTM的上下文信息提取 在这一层中,使用双向LSTM(Bi-LSTM)模型对文本的词嵌入向量Xda、Xdb和Xdc进行更深层次的特征提取。利用Bi-LSTM对序列中长距离依赖信息的捕捉能力来实现对文本的上下文信息的提取。 LSTM是RNN的一种特例,相比最原始的RNN单元,LSTM通过增加记忆单元来缓解长序列数据训练时所产生的梯度消失问题,适用于序列数据的信息提取。LSTM的结构[26]如图2所示。 图2 LSTM网络架构Fig.2 Illustration of the architecture of LSTM 其中,At是LSTM在t时刻的计算单元,xt为当前时刻的词嵌入向量输入,vt-1为收到的上一时刻LSTM的输出值,ct-1为上一时刻的单元状态,每个单元中LSTM通过遗忘门、输入门和输出门来共同保护和控制每个神经单元的状态,可以有效提取序列数据中的信息。但是,LSTM是沿序列信息方向单向进行的,只能建模一个方向的序列信息。 Bi-LSTM[3]包含一个正向LSTM和一个反向LSTM,并在两个方向上捕获信息,能够更加有效地提取文本的上下文信息,其结构如图3所示。 图3 Bi-LSTM网络架构Fig.3 Illustration of the architecture of Bi-LSTM 图3中Bi-LSTM从两个方向处理输入的嵌入向量,并得到如下向量: (7) (8) (9) 于是,通过Bi-LSTM模型,我们可以得到包含上下文信息的文本特征: (10) (11) (12) 2.2.3基于CNN的局部语义特征提取 除了对文本的上下文信息进行提取,还对文本的局部信息进行提取。这里采用了对文本局部信息抽取能力较为出色的TextCNN[30]模型。 TextCNN[30]是CNN在自然语言领域中的一个应用,其网络架构和经典的CNN模型类似,文本局部特征的抽取能力较强,具有效果好、速度快等优点,其网络架构[30]如图4所示。 图4 TextCNN网络架构Fig.4 Illustration of the architecture of TextCNN 这里TextCNN的输入是Bi-LSTM提取后的特征文本矩阵Vda、Vdb和Vdc.在池化过程中,采取了最大池化加平均池化的方法,从而更大程度地保留文本特征,而拼接后的最终文本特征不再像传统TextCNN中的一样直接用于分类,而是用来表征法律文本。 经过第i个卷积核卷积后得到的特征向量为: (13) (14) (15) (16) (17) (18) 最大池化可以表示为: (19) (20) (21) (22) (23) (24) 另外,曾尝试将BERT学习到的词嵌入向量、双向LSTM学习到的向量和CNN学习到的向量这3种向量进行多种组合搭配(包括拼接),并作为最终的文本特征。而实验结果表明,使用BERT以及双向LSTM和CNN结合起来逐层学习的向量作为最终的文本特征能够取得最好的效果。 在这一层中,利用从TextCNN网络中得到的向量对模型进行训练,之后利用相同的网络去计算查询文本dq与法律文本库中的文本di的距离,最后根据距离进行排序,选出与dq最相似的若干个法律文本。 2.3.1Triplet损失函数 Triplet损失函数[31]的输入是一个三元组,刻画的是两个候选文本与查询文本之间的距离差。为了方便说明,这里假设文本da与文本db的相似程度要大于文本dc. 在模型训练时,通过最小化Triplet损失函数使得查询文本da与两篇候选文本中相似的文本db越来越相似,而与不相似的文本dc越来越不相似。 具体来说,Triplet损失函数输入的参数是一个三元组向量,包括锚点向量、正样本向量和负样本向量,具体的计算公式如(25)所示。其中dis(Uda,Udb)是锚点与正样本的距离,dis(Uda,Udc)是锚点与负样本的距离,并通过间隔(margin)增加类间距离。 L=max(dis(Uda,Udb)-dis(Uda,Udc)+margin,0). (25) 本文选择Triplet损失函数,使得相似文本间的特征Uda与Udb更加接近,不相似文本间的特征Uda与Udc更加远离,这样有利于更好地表征不同的文本,让文本能够直接嵌入到向量空间中。这样,不仅能实现案件之间进行比较的任务,也便于后续进行类案推荐。 2.3.2类案匹配 由于已经获取了文本最终的表征向量Uda、Udb和Udc,因此可以通过计算两两之间的文本相似度来进行类案匹配。 文本间的相似度可以用向量间的二范数来度量: dis(Uda,Udb)=‖Uda-Udb‖2. (26) dis(Uda,Udc)=‖Uda-Udc‖2. (27) 其中,如果dis(Uda,Udb) 2.3.3类案推荐 完成模型训练之后,使用相同结构的网络,计算输入的法律文本dq与文本库D中的法律文本的距离: Eqi=‖Udq-Udi‖2,i∈{1,…,|D|}. (28) 然后根据得到的距离值Eqi进行排序,并根据需要推荐的法律文本数量进行案件推送。 需要说明的是,由于文本库D中的文本是确定的,因此只需要在开始时对文本库D进行一次计算,将表征出来的文本向量Udi保存下来。在进行推荐时,只需要对查询文本dq进行表征,得到Udq后再求与Udi的距离,并进行排序即可完成类案推荐。本文的方法不需要每次都将所有案件经过线性层计算相似度,因此,在效率上会明显优于传统的方法,在实际应用中能够较好地保证实时性。 为了验证本文提出的方法的有效性,我们将其应用到CAIL2019数据集上进行类案匹配和推荐。 本文使用的是中国人工智能与法律2019类案匹配第二阶段比赛的数据集(CAIL2019-SCM).数据集包含8 138条由“民间借贷”相关案件组成的四元组{(da,db,dc,y)},数据集的划分如表1所示。每个案件均摘自中国裁判文书网,案件内容一般分为原被告信息、原告诉求、事实陈述和法院裁决4个部分,案件字数范围为500~800字。 表1 数据集划分Table 1 Dataset partition 因为CAIL2019-SCM数据集没有包含案件罪名、刑期、法条等方面的标签,所以无法对类案推荐结果进行直接评估。但是,类案匹配和类案推荐在编码层和文本信息提取层的架构是一样的,只在最后的全连接输出层存在差异,所以可以利用类案匹配的准确率来评估模型性能,进而评估类案推荐的效果。 在词嵌入层,由于训练使用的数据是中文法律文档,属于民事案件,所以使用了OpenCLaP[29]中获得的预训练BERT模型,该模型使用2 654万件民事案件进行了预训练。由于BERT只能处理长度不超过512的序列,因此使用尾部截断来处理输入序列,这是因为后面的文本通常包含的信息更多。在使用BERT时,保持了模型默认的超参数。 将BERT的隐藏层数量k设置为768, LSTM的隐藏层数量k2设置为256,CNN卷积核个数k3设置为64×3,采用3种区域大小不同的卷积核{3,4,5}进行卷积,每种区域大小的卷积核有64个;设置epoch的范围为{4,6,8,10},批处理的范围为batch size∈{16,20,24,32},优化学习率的范围设置为learning rate∈{2×10-5,3×10-5,5×10-5}.其中批处理的值需要根据显存大小进行选择,本文中使用的数据集CAIL2019-SCM相对较小,所以epoch可以选择较大的值,从而提高内存利用率,且能获得更加准确的梯度下降方向。而learning rate与batch size的大小密切相关,当调大批处理大小时,也需按比例调高优化学习率的大小,从而使收敛更加稳定。参数的范围和数值选择如表2所示。 表2 实验过程中超参数的设置范围Table 2 Ranges of the values for the hyper-parameters to be tuned in the experiments 使用Adam[32]对模型进行优化,采用权重衰减代替L2正则化。相比Adam,通过AdamW能得到更好的训练损失和泛化误差。此外,使用NVIDIA Apex实现混合精度训练,用于加快训练过程。训练时使用两块NVIDIA Tesla V100 GPU,其显存大小为32 GB. 本文所涉及的源代码和脚本可从https:∥github.com/zitaozz/CASCMR获得。 表3展示了基准模型(CNN、LSTM和BERT)、CAIL2019比赛相似案件匹配任务前3名(AlphaCourt、11.2yuan和backward)[25]以及本文模型CASCMR的实验结果,表格数据为模型的预测准确率(百分比显示)。为了便于与比赛结果直接进行比较,实验中仅使用准确率作为评价指标。 表3 模型在CAIL2019-SCM数据集上的实验结果Table 3 Experimental results of the models on CAIL2019-SCM 对于基准算法中的CNN和LSTM,实验中先使用GloVe进行词嵌入,然后分别经过CNN层和LSTM层,再进行最大池化,得到特征h,最后用一个带有softmax激活函数的线性层来计算相似度,并使用交叉熵作为损失函数。对于BERT,则是直接使用预训练好的中文BERT模型编码,得到特征h,后面同样经过线性层计算相似度。 线性层的相似度计算公式如下: S(Aj)=softmax(exp(hAWhj)),j=B,C. (29) 从这个公式中,也可以很清晰地看到,对于基准算法,其相似度计算需要对两篇文本进行两两交互,因此在进行类案推荐时,由于数据库中文本较多,会导致很大的时间开销,很难进行实际应用,而本文设计的模型能够很好地解决这一问题。 从表3中可以看出,在测试集上相比基准模型提高了5%~6%,且比目前最好的方法提高了1.08%.实验结果说明,模型通过提取上下文信息、提取局部特征和修改损失函数等方法,能提高法律文本的语义表征能力,使模型能学习更多文本间的相关性信息,进而提高匹配精度。 为了验证主要模块的作用,在数据集CAIL2019-SCM上设计了多个消融实验来评估模型的性能: 1) 探究特征提取对模型精度的影响,使用缺少特征的数据训练模型,即只使用BERT进行编码,观察模型预测的准确率。通过基于成对偏好假设的方式进行训练。 2) 探究局部语义特征提取对模型精度的影响,去掉模型中的CNN网络,训练模型,观察模型预测的准确率。 3) 探究上下文信息提取对模型精度的影响,去掉模型中的Bi-LSTM网络,训练模型,观察模型预测的准确率。 消融实验的结果如表4所示。 表4 消融实验结果Table 4 Results of ablation studies 由表4可以看到,使用BERT编码后的特征直接计算的结果并不理想,而如果在BERT编码基础上增加CNN和LSTM进行更深层次的特征抽取,能有效提升模型预测的准确率。对比基准模型,LSTM是通过捕获法律文本上下文信息来提高模型对法律文本的表征能力,而CNN是通过突出局部关键法律文本信息从而提高模型对法律文本的辨识能力。从表4中可以看出CNN的特征抽取效果要略优于LSTM,而如果将两者结合则准确率能提升8%~10%. 数据集从CAIL2018-small[33]中生成,数据为三元组(A,B,C),用于类案匹配任务。数据集共分为两类,分别包含92 322和69 741条数据,共计162 063条数据。 CAIL2018-small处理前包含10个属性,共151 254条数据,只取其中的fact(事实陈述)、accusation(罪名)、relevant articles(相关法条)3个属性,之后对数据进行筛选:1) 去掉多罪名数据,2) 选择fact字数在150~600的数据,3) 去除重复的数据。 筛选后,数据包含190个罪名,共计92 325条数据。完成上面的操作后,定义了两类数据(分别记为category1和category2):1) 第一类数据仅根据accusation(罪名)属性进行划分,即法律文本A和B的罪名相同,法律文本A和C的罪名不同;2) 第二类数据根据accusation(罪名)和relevant-articles(相关法条)属性进行划分,其中A、B的relevant-articles为单法条,C的relevant-articles为多法条,使得法律文本A和B的罪名和法条都相同,而法律文本A和C的罪名相同但法条数量不同,从而确保A和B之间的相似度大于A和C之间的相似度。 将上述数据集按8∶1∶1比例随机划分为训练集、验证集和测试集。 CASCMR模型使用自定义数据集(CAIL2018-CASCMR)得到类案推荐结果,从图5-图8中可以判断模型推荐的案例与查询案例高度相关。但仅靠观察难以评估模型的性能,为此把CASCMR应用到类案匹配任务中,测试其匹配精度,从而确定模型的推荐性能。 表5展示了本文提出的模型在CAIL2018-CASCMR数据集上的实验结果,表格数据为模型进行类案匹配时的预测准确率。 表5 模型在CAIL2018-CASCMR数据集上的实验结果Table 5 Experimental results of the model on CAIL2018-CASCMR 从表5的结果可以知道,CASCMR可以精准区分不同罪名的案例,准确率达到了99.14%.在同罪名不同法条的易混淆案例上的准确率也能达到95.53%,总的准确率达到了98.67%.说明本文的模型对易混淆(同罪名不同法条)案例具有很好的辨别能力,因此在类案推荐上也能对相关案例进行精准推荐。 由于在CAIL2018-CASCMR数据集中,负样本的罪名或法条与查询案件不同,因此相比案件类型均为“民间借贷”的CAIL2019-SCM数据集更容易区分开来,且从数据集大小来看模型能够得到更加充分的训练,因此准确率也就更高了。 由于模型具有表征法律文本的特性,不难知道越相似的法律文本表征后在向量空间中就越接近,由此可以对所有向量进行排序,将与输入文本特征向量最接近的前若干个向量选取出来,并记录它们对应的文本,以及判决结果,然后返回给用户。 模型训练完成之后,在实际应用时并不需要每次都将所有案例重新进行特征抽取。可以使用训练后的模型,预先对所有法律文本进行表征,将它们转换为向量,并保存在本地。在实际应用时,只需要对新输入的文本用训练好的模型进行特征抽取,然后将该特征和已保存的特征向量进行比较。 下面对类案推荐结果进行分析。在完成对文本的所有表征后,选用的测试样例如图5所示,可以看到案例关键信息包括“无申报通道进境,无书面向海关申报,被海关关员截查”、“偷逃应缴税款人民币216.90元”等。 图5 查询案件Fig.5 Query case 经过计算和排序得到的前3个类案分别如图6、图7、图8所示。 图6 类案1Fig.6 Similar case 1 图7 类案2Fig.7 Similar case 2 图8 类案3Fig.8 Similar case 3 在此案件中,可见前3个相似案件的关键字都为“无申报通道进境,无书面向海关申报,被海关关员截查”,偷逃应缴税款金额较为接近。推荐的类案均为海关走私相关的案件,经验证,这些案件的罪名、依据法条也都一致,且刑期接近,富有较高的参考价值。 针对类案匹配和推荐中存在的效率和准确率低的问题,本文提出了一个基于上下文感知的类案匹配和推荐模型。该模型使用多语义文档表达框架,通过文本向量的预计算,进而提高文本匹配的效率。同时,模型通过Bi-LSTM和CNN处理文本,分别提取文本的上下文序列信息和局部信息,用于提高模型的预测性能。实验结果验证了本文提出的模型的有效性。之后,针对法律文本的长文本、半结构等的特点,我们计划尝试其他文本压缩和特征提取的方案,以进一步提高文本的表征能力,进而提升模型的准确率。2.2 上下文感知类案匹配和推荐框架
∀i∈{1,…,Nda} .
∀j∈{1,…,Ndb}.
∀m∈{1,…,Ndc} .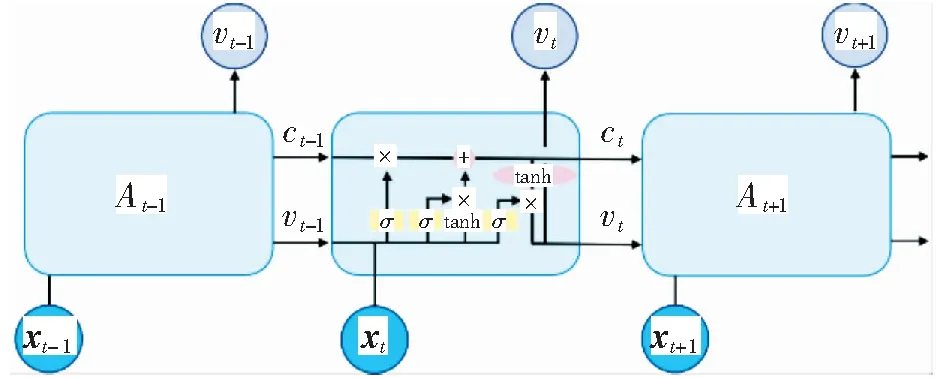
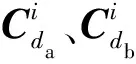
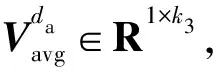
2.3 训练预测
3 实验结果与分析
3.1 数据集

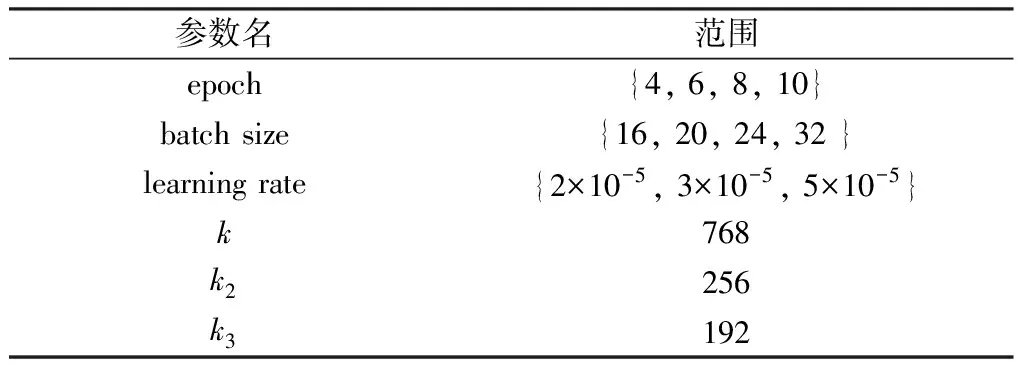
3.2 评价指标和模型参数
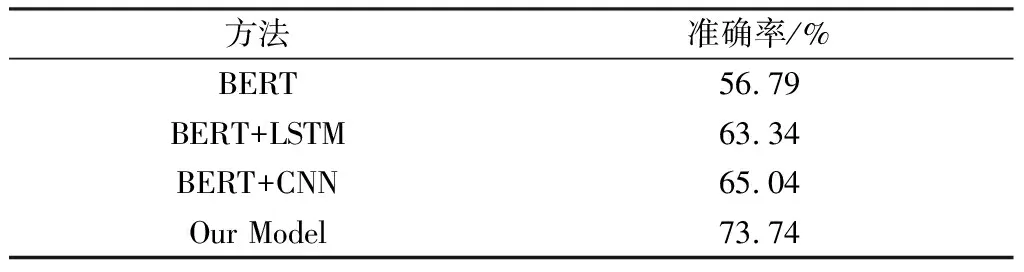
3.3 实验结果与分析

3.4 消融实验
3.5 类案推荐数据集
3.6 实验结果和分析





4 总结
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
水上消防(2021年4期)2021-11-05
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
人大建设(2017年4期)2017-07-21
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
中国报道(2009年6期)2009-06-22
