
采用低层特征的深度伪造图像检测方法
2022-02-25 06:45周华兵
软件导刊 2022年1期
马 喆,周华兵
(武汉工程大学计算机科学与工程学院,湖北 武汉 430205)
0 引言
近年来,深度学习在计算机视觉、自然语言处理等领域取得重大突破,超越了许多传统方法。然而,深度学习技术也对个人隐私数据、社会稳定和国家安全等造成潜在威胁。
以深度学习技术制作的虚假图像以及音视频内容在网络上传播,深度伪造技术采用“生成式对抗网络”(Generative Adversarial Networks,GAN)的机器学习模型将图片叠加到源图片上,尤其是Deepfakes 技术生成的伪造视频通过篡改或替换原始视频中的人脸信息制作虚假新闻、政治谣言,这类伪造视频人眼难以辨认,一旦被滥用危害极大,给国家安全甚至世界秩序带来风险。目前,针对深度伪造内容的检测和防御成为世界各国政府、企业及研究人员关注的热点之一[1]。
深度伪造内容检测方法大多采用多层卷积神经网络,取得了一定成果,但其仍然存在网络结构复杂、计算量大等问题。本文提出一种基于低层特征的深度伪造图像检测方法,先对图像进行预处理提取低层特征,再将低层特征通过简单的全连接网络训练实现分类。全连接网络结构简单,计算量小于多层神经网络且分类精度有所提高。
1 相关工作
基于传统的信号处理方法进行图像取证,利用图像的频域特征和统计特征来检测拼接、复制—移动、移除等伪造图像记录[2]。Chierchia 等[3]基于相机设备指纹光响应不均匀性检测小的篡改图像;Huh 等[4]设计了一个孪生网络,在来自不同相机的图像块上提取图片的噪音指纹从而实现检测;Zhou 等[5]提出基于双流的Faster R-CNN 网络,融合RGB 流与噪声流的特征学习两个模态空间信息;Liu等[6]提出一个新的深度融合网络,通过追踪边界来定位篡改区域。这些基于取证的技术已经很成熟,但是深度伪造图像通常会进行不同的压缩方式、不同的压缩率等后处理,而经过后处理的图像局部异常特征会减弱。传统取证方法关注的是局部异常特征,因此传统取证方法不能直接用于深度伪造图像检测。
近年深度伪造图像检测技术取得进展。深度伪造技术往往忽略人的真实生理特征,Yang 等[7-8]发现假人脸与真人脸在3D 头部姿态评估和关键点位置具有不一致性,因此根据SVM 分类器进行学习。但随着深度伪造技术在生理信号上的改进,此类方法会失效;早期的深度伪造图像由于技术缺陷会在人脸区域留下人工痕迹,Li 等[9]发现Deepfakes 视频留下的人工伪影,通过模拟人工伪影构造负样本使用Resnet50 网络训练分类器;Matern 等[10]利用真假脸的不一致性来区分,通过对特定区域(牙齿、眼睛等)提取的特征向量训练多层感知机进行分类。但是压缩、优化修改篡改边界等后处理和高分辨率伪造图像的出现,使这类方法的检测能力大大减弱。最近的深度伪造图像大部分借助了GAN 技术,文献[11]和文献[12]发现GAN 生成技术改变了图像的像素和色度空间统计特征,通过对特征共生矩阵的学习来区分生成图像的差异;文献[13]和文献[14]尝试用GAN 指纹来区分伪造。但这类方法只对特定的GAN 有效,无法处理未知的GAN,泛化能力不足。基于图片级的深度学习方法是当前研究热点,Nguyen 等[15]设计胶囊网络来判别造假的图片或视频,通过抽取人脸图像,用VGG-19 提取特征编码,然后输入胶囊网络;Nguyen等[16]设计了Y 型解码器,在分类的同时融入分割和重建损失,通过分割辅助分类效果;Darius 等[17]根据图像的介观特性使用CNN 网络进行分类。深度学习具有强大的学习能力,大型深度伪造图像数据集FaceForensics++的出现为这类方法提供了便利[18],但这类方法学习到的模型对压缩处理后的图像检测能力有所下降。
上述方法都在各自数据集上取得了较好效果,但仍然有许多问题亟需解决。当前的深度伪造图像检测方法大多基于深度学习,使用复杂的神经网络和大型数据集计算量较大,一些方法的检测能力会由于压缩、优化篡改边界等后处理而下降。
针对以上问题,本文提出采用低层特征的深度伪造图像检测方法,具体阐述如下:
(1)预处理图像提取低层特征并使用全连接网络训练分类器,简化了网络,减少了计算量。
(2)基于人工痕迹的方法依赖真假人脸边界以及其他特定区域的不一致性,采用图像噪声这类低层特征不会随优化边界操作而变化的特性,对优化篡改边界的数据集分类效果好。
(3)基于图片级的深度学习方法对压缩处理后的图像检测能力有所下降,为此,本文采用误差水平分析(ELA)提取压缩的图像特征,提高了压缩图像的检测准确率。
2 低层特征检测算法
2.1 网络结构
深度学习具有准确表示复杂、高维、大规模数据,进而直接提取特征的能力。特征提取分为自动提取和手动提取两种类型。自动提取指在数据集上直接训练模型,即让模型自主学习和提取能够区分真伪内容的特征;手动提取则需要对数据集进行预处理,人工提取出部分特征,进而基于已提取特征完成分类器训练。当前的方法多使用卷积神经网络自动提取图像的高级特征,使用大规模的数据训练分类器。本文提出的方法关注的是噪声、误差水平分析等低层级特征,手动提取噪声图、ELA 图,进一步转换为灰度直方图特征作为分类器的输入,使用全连接网络做分类器,简化了卷积神经网络提取特征过程。
详细的网络结构如图1 所示。将数据集根据图像真伪分为两类:①伪造图像标签为0;②真实图像标签为1。以一张大小为256 × 256 × 3 的图像为输入,对输入图像分别进行SRM 滤波以及ELA 处理得到噪声图以及ELA 图并转换为灰度图像,并根据两幅灰度图的0~255 像素值计算每个像素的个数,转化为两个1× 1× 256 维的特征向量,再拼接为1× 1× 512 维的特征向量。将3 个全连接网络作为分类器,以上述1× 1× 512 维的特征向量和对应的标签作为输入,前两个全连接层每层后加一个RELU 激活函数,最后一个全连接层输出经过softmax 函数激活,使用二分类的交叉熵损失根据输入的低层特征以及对应标签训练分类器。
2.2 真伪图像低层特征差异
在采集过程中每幅图像都有自己的独特标记,这些标记要么来自硬件(如传感器、镜头),要么来自软件组件(如压缩、合成算法)。硬软件产生的标记一般具有“周期性”或者是均匀的。一旦图像改变就会打破这种均匀,因此可以利用标记判断是否为合成图片。图2(彩图扫OSID 码可见,下同)中,对真伪图像进行噪声分析和误差水平分析,观察它们之间的差异。真实图像和伪造图像的噪声和ELA图在脸部区域(图中红框)有差异,具体体现在真实图像的噪声图与ELA 图的脸部区域五官(眼睛、鼻子、嘴唇等)与周围的脸部边界等背景近似,而伪造图像的噪声图与ELA图中五官区域与脸部边界(篡改边界)等背景部分有所不同,ELA 图中尤为显著。
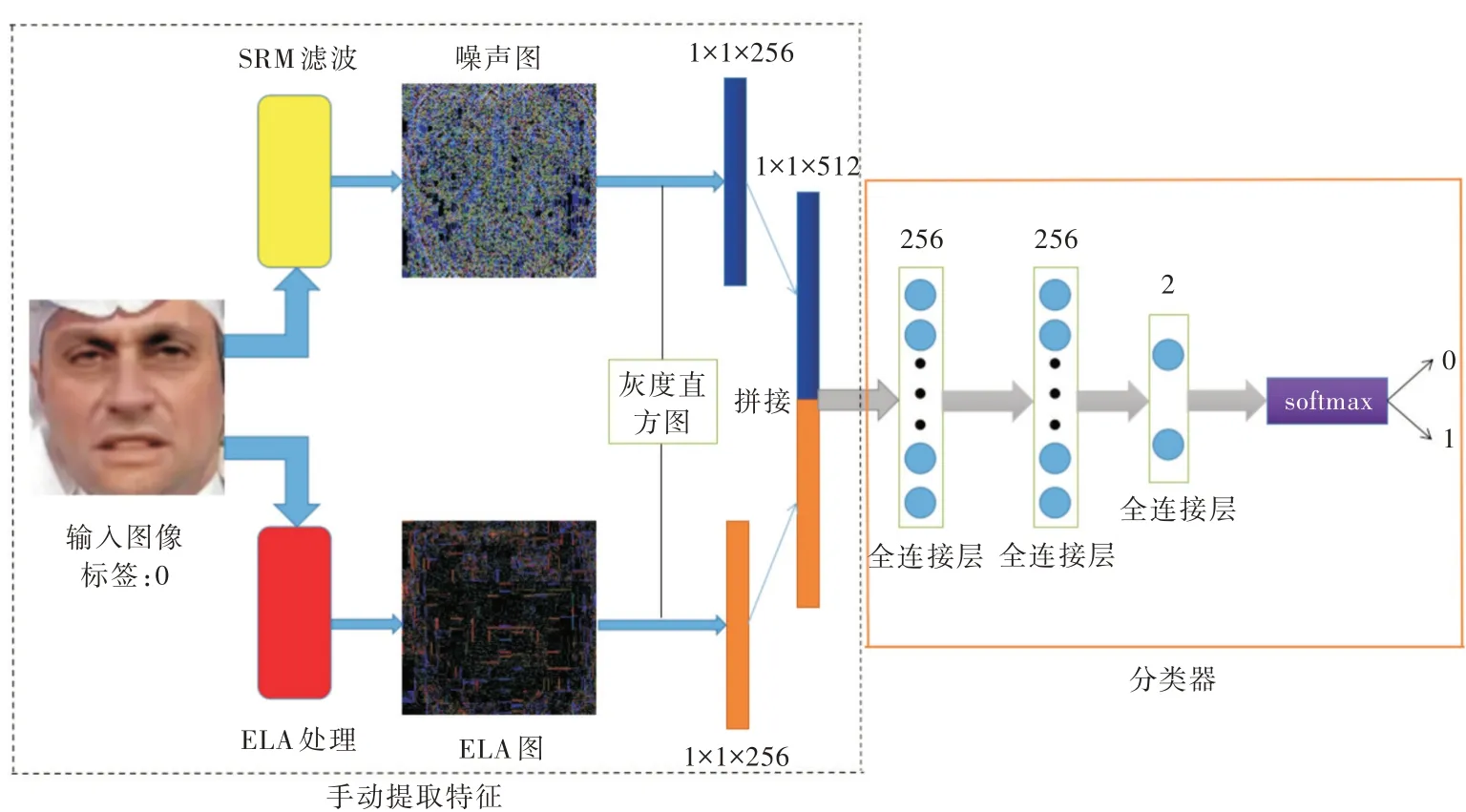
Fig.1 Network structure图1 网络结构

Fig.2 Noise analysis and ELA analysis图2 噪声分析和ELA 分析
2.3 SRM 滤波器
数字图像隐写技术指在图像中隐藏秘密信息,会改变某些像素大小。SRM 采用图像定性隐写分析框架,检测图像是否有隐写嵌入改动。SRM 采用丰富的线性和非线性空域高通滤波器对图像进行滤波,将得到的丰富噪声残差图像作为SRM 的子模型[19]。对图像某个像素的隐写嵌入改动会导致某些噪声残差图像相应位置的相邻像素相关性发生变化,SRM 方法丰富的子模型能增加隐写分析的多样性,更全面地感知隐写嵌入引起的图像相邻像素相关性变化。深度伪造图像主要篡改人脸,改变了人脸区域像素大小,可以看作隐写嵌入改动。因此,本文将隐写分析中的SRM 滤波器用于图像深度噪声特征提取器。
SRM 收集基本的噪声特征,仅使用3 个内核的SRM 滤波器即可获得不错的性能。本文将SRM 滤波器的内核大小定义为5×5×3,输出通道大小为3,其权重如图3 所示。

Fig.3 SRM filter weights图3 SRM 滤波器权重
2.4 误差水平分析
误差水平分析(Error Level Analysis,ELA)可以识别图像中处于不同压缩级别的区域,获取图像压缩时的失真情况[20]。ELA 以指定的JPEG 质量级别保存图像。JPEG 图像使用有损压缩系统,图像的每次重新编码(重新保存)都会增加图像的质量损失从而引入已知数量的错误。JPEG 算法在8×8 像素网格上运行,每个8×8 正方形均独立压缩。如果图像未修改则每个正方形应以大致相同的速率降级,所有8×8 正方形都应具有相似的潜在错误。如果对图像进行了修改,则修改所触及的每个8×8 正方形应比图像其余部分潜在错误更高。ELA 通过潜在错误的不同确定篡改区域。如果图像进行了多次压缩处理,则该图像篡改区域的潜在错误在ELA 图上会更加明显。压缩处理在深度伪造图像中较为常见,使用ELA 方法能在图像被压缩的情况下检测伪造。
2.5 方法实现
本文实验采用数据集FaceForensics++ 进行训练。选取750 个原始视频以及对应的750 个由DeepFakes 生成的伪造视频(压缩质量均为c23),然后在每个原始视频和伪造视频均提取30 帧,用人脸检测器抽取出人脸框,截取人脸时以人脸框为基准向外扩展0.3 倍,图像大小调整为256×256×3。原始视频中提取的帧为真实图像,标签为1;DeepFakes 视频中提取的帧为伪造图像,标签为0。训练集与测试集大小比例为9∶1。损失函数使用常用的二分类交叉熵损失,如式(1)所示。
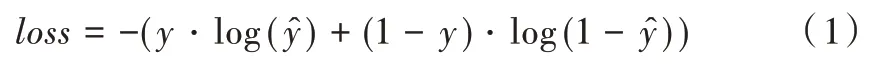
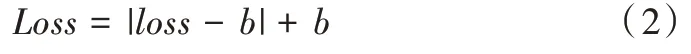
参数设置:使用SGD 优化器优化网络参数。学习率lr设为0.01,动量参数momentum 设为0.5,
每次更新后的学习率衰减值decay 设为0,不使用Nesterov 动量。网络训练迭代次数设置为100。
3 实验结果与分析
为了验证本文方法在网络结构、计算量以及分类精度上的优势,在Deepfakes(压缩率为c23)数据集中挑选未参与训练的100 个视频,每个视频提取10 帧进行模型测试。
3.1 基于图像篡改痕迹模型比较实验
文献[2]总结了基于图像篡改痕迹的模型在不同数据集上的AUC 值对比。本文模型在压缩率c23 的Deepfakes数据集上测试得到AUC 值,并与文献[9]和文献[10]的模型进行比较,AUC 值越高代表分类效果越好,具体数值见表1。由于Deepfakes 技术在替换原始人脸时对人脸边界(篡改边界)进行了优化,上述两个基于篡改痕迹的模型在该数据集上分类性能下降。本文模型分类效果较好,说明采用图像噪声这类低层特征训练的分类器对Deepfakes 的数据集分类效果较好。

Table 1 Comparison of AUC values between the proposed model and the tamper trace model表1 本文模型与基于篡改痕迹模型AUC 值比较
3.2 基于图片级的模型比较实验
接受者操作特性(Receiver Operating Characteristic,ROC)曲线一般用于二分类模型评价,ROC 曲线覆盖的面积越大,模型分类效果越好。本文方法与文献[15]的Capluse、文献[16]的Milt_task 和文献[17]的Mesonet 方法在ROC 曲线上的比较如图4 所示。从图中可以看出本文模型的ROC 曲线覆盖面积最大。
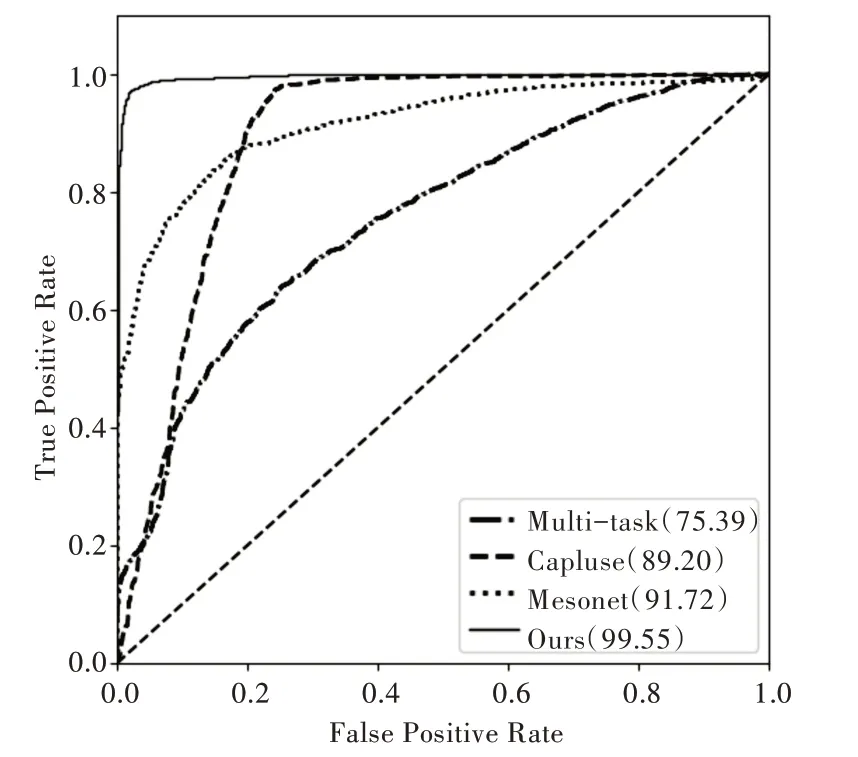
Fig.4 ROC curves of the four models图4 4 种模型的ROC 曲线
另外使用AUC 与EER 指标评价模型性能。AUC(Area Under Curve)表示ROC 曲线下的面积。AUC 值作为一个数量值,可以进行定量比较,AUC 值越高表示分类器性能越好。等错误概率(EER)用于预先确定其错误接受率以及错误拒绝率的阈值。等错误率值越低,分类器的准确度越高。本文方法与上述文献的3 种方法在AUC 值和EER 值上的比较如表2 所示,从表中可以看出,本文模型的AUC 值(99.55%)最大,而等错误率(2.5%)最小。
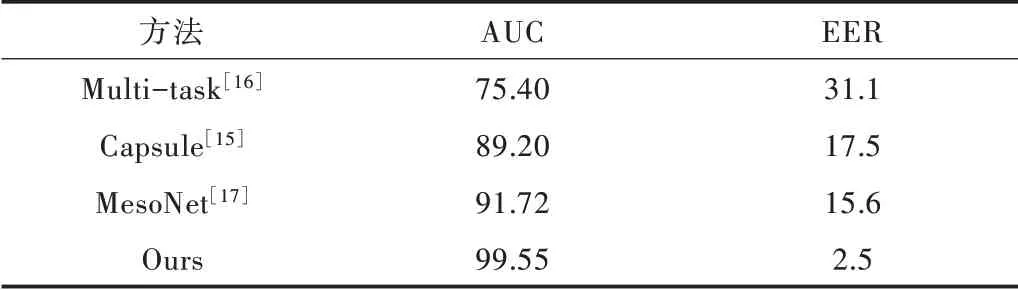
Table 2 Comparison of AUC value and EER value表2 AUC 值与EER 值比较 (%)
上述3 种文献的方法分类效果在压缩后的Deepfakes数据集上表现不佳,而本文模型的ROC 曲线覆盖面积最大,AUC 值最大,等错误率最小,分类效果最好,说明使用ELA 处理和SRM 滤波提取的低层特征更有利于对抗图像压缩等后处理对分类器性能的影响。
3.3 模型大小与计算量比较实验
模型的复杂度用模型参数量、计算量和模型大小评价,使用这3 个指标将本文方法与其他方法对比,具体数值根据thop 计算[22]。从表3 可以看出,本文方法相比于其他方法网络结构简单、计算量最小,模型参数量和模型大小也非常小,说明本文方法简单、高效。
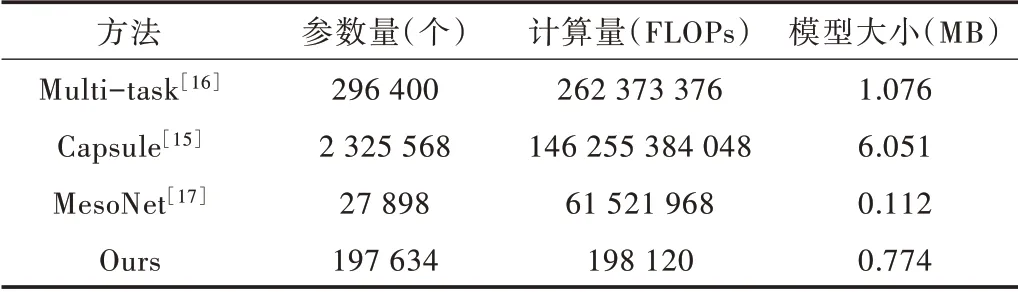
Table 3 Comparison of parameter calculation表3 参数量计算量比较
4 结语
近年来,基于深度学习技术的深度伪造发展迅速,在电影特效制作、虚拟角色创建等领域应用广泛。但恶意的深度伪造生成换脸图像,伪造内容通过网络快速传播,人们难以分辨真伪,对网络安全带来了巨大威胁。
研究深度伪造检测技术,防止恶意伪造内容造成的威胁成为热点。本文提出一个基于低层特征的方法检测伪造图像,该方法在分类器性能和效率上与最近几种热门的检测方法相比有一定优势,在面对压缩处理后的图像以及优化篡改边界的数据集时分类效果很好。但本文的方法以及现有的其他检测方法均依赖于特定的数据集和生成算法,泛化能力很弱,无法应对新的篡改方法,而且大多在单一场景下测试,检测算法不具有鲁棒性。后续工作不仅要专注于提高某个数据集的检测精度,鲁棒性和泛化问题也是研究重点。
猜你喜欢
数学年刊A辑(中文版)(2020年3期)2020-10-27
报刊荟萃(上)(2018年3期)2018-04-24
电子测试(2018年1期)2018-04-18
益寿宝典(2017年34期)2017-02-26
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
建筑工程技术与设计(2015年12期)2015-10-21
噪声与振动控制(2015年4期)2015-01-01
电测与仪表(2014年15期)2014-04-04
振动、测试与诊断(2014年4期)2014-03-01
