
融合笔画特征的胶囊网络文本分类
2022-03-12 05:55李冉冉刘大明常高祥
计算机工程 2022年3期
李冉冉,刘大明,刘 正,常高祥
(上海电力大学计算机科学与技术学院,上海200090)
0 概述
文本分类是自然语言处理领域的一项基础任务,在问答系统、主题分类、信息检索、情感分析、搜索引擎等方面发挥重要的作用。传统文本分类方法大部分在向量空间模型的基础上实现,文献[1]提出一种基于TF-IDF 的改进文本分类方法,文献[2]提出使用支持向量机的分类方法,文献[3]提出一种特征加权的贝叶斯文本分类方法。但是,在使用传统特征提取方法表示短文本时存在数据稀疏与特征向量维度过高的问题。
随着深度学习技术的快速发展,越来越多的学者们将深度学习模型应用到自然语言处理中[4]。文献[5]通过构建神经网络语言模型训练词向量来获得文本的分布式特征。但是,其将词视为不可分割的原子表征,忽略了词的结构信息,这一不足引起了部分学者的注意,并对利用词的结构信息的方法进行了研究。文献[6-7]在学习过程中使用部首词典提取字词特征。文献[8]提出一种使用笔画n-gram提取汉字的笔画序列信息的方法,该方法可以训练得到含有汉字结构信息的词向量。深度学习技术在文本分类中也得到广泛应用,文献[9]利用卷积神经网络和预先训练的词向量对输入向量进行初始化,文献[10]通过使用循环神经网络(Recurrent Neural Network,RNN)来提取全局特征,文献[11]提出使用门控循环单元(Gated Recurrent Unit,GRU)和注意力机制进行文本分类,文献[12]提出胶囊网络并将其应用在文本分类任务中,减少了卷积神经网络(Convolutional Neural Network,CNN)在池化操作中的特征丢失问题。
本文提出一种结合GRU、注意力机制和胶囊网络的混合神经网络模型GRU-ATT-Capsule。使用GRU 提取2 种词向量的上下文特征,结合注意力机制对GRU提取的特征重新进行权重分配,对文本内容贡献较大的信息赋予较高的权重,并将重新计算得到的特征进行融合。利用胶囊网络进行局部特征提取,从而解决CNN 在池化过程中的特征丢失问题。
1 相关工作
1.1 中文词向量表示方式
传统词向量表示方式主要基于分布式假设,即上下文相似的词应具有相似的语义[13]。Word2Vec和Glove 是2 种具有代表性的词向量训练方式,由于高效性与有效性得到广泛应用[5,14]。
汉语词向量表示方式的研究在早期多数是参照英文词向量表示方式:先对中文进行分词,再在基于英文的方法上进行大规模语料的无监督训练。但是,该方式忽略了汉字本身的结构信息[15]。因此,汉语学者们针对用于汉语的词向量进行研究。文献[16]设计汉字和词向量联合学习模型,该模型利用汉字层次结构信息改进中文词向量的质量。文献[7]在学习过程中使用部首词典提取字词特征,实验结果表明在文本分类以及词相似度上均有所提升。文献[17]使用卷积自动编码器直接从图像中提取字符特征,以减少与生词相关的数据稀疏问题,实验结果显示利用字符结构特征进行增强会取得一定的效果。文献[8]首先对汉字的笔画特征进行建模,将词语分解为笔画序列,然后使用笔画n-gram 进行特征提取,在文本分类任务上相比于传统方法提升了1.9%的准确率。
1.2 基于胶囊网络的文本分类
文献[18]提出胶囊网络,其思想是使用胶囊来代替CNN 中的神经元,使模型可以学习对象之间的姿态信息与空间位置关系。文献[19]提出胶囊间的动态路由算法与胶囊网络结构,其在MNIST 数据集上达到了当时最先进的性能。
胶囊网络与CNN 的区别在于:1)使用胶囊(向量)代替神经元(标量);2)使用动态路由算法进行低层到高层的参数更新,而不是使用池化操作,从而避免信息丢失;3)使用压缩函数代替ReLU 激活函数。由于高层胶囊是由底层胶囊通过动态路由算法利用压缩函数计算得出,由多个向量神经元共同决定与整体的关系,因此使得胶囊网络可以学习到文本的局部与整体之间的关联信息。
文献[12]使用两个并行的卷积层进行特征提取,并且其中一个卷积层使用ELU 激活函数进行激活,然后将提取的特征按位置对应相乘,输入到胶囊网络,在精度和训练时间上均取得了较好的效果。
1.3 GRU 和注意力机制
文献[9]将CNN 应用于文本分类,其使用预先训练的词向量来初始化输入向量,首先在卷积层中利用多个不同尺度的卷积核进行特征提取,然后采用池化操作提取主要特征,最后使用softmax 分类器进行分类。文献[11]使用门控循环单元学习文本序列的上下文特征,并结合注意力机制为文本中的特征学习权重分布,相比基于LSTM 的方法在准确度上取得了2.2% 的提升。文献[20]提出一种结合CNN、双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)和注意力机制的文本分类方法,其首先使用CNN 提取局部短语特征,然后使用BiGRU 学习上下文特征,最后通过增加注意力机制对隐藏状态进行加权计算以完成特征权重的重新分配,相比基于attention-CNN 的方法与基于attention-LSTM 的方法在准确率与F1 值上均有所提升。
2 模型设计
本文提出一种GRU-ATT-Capsule 混合模型用于文本分类。该模型由文本表示、全局特征提取和胶囊网络分类等3 个模块组成,结构如图1 所示。
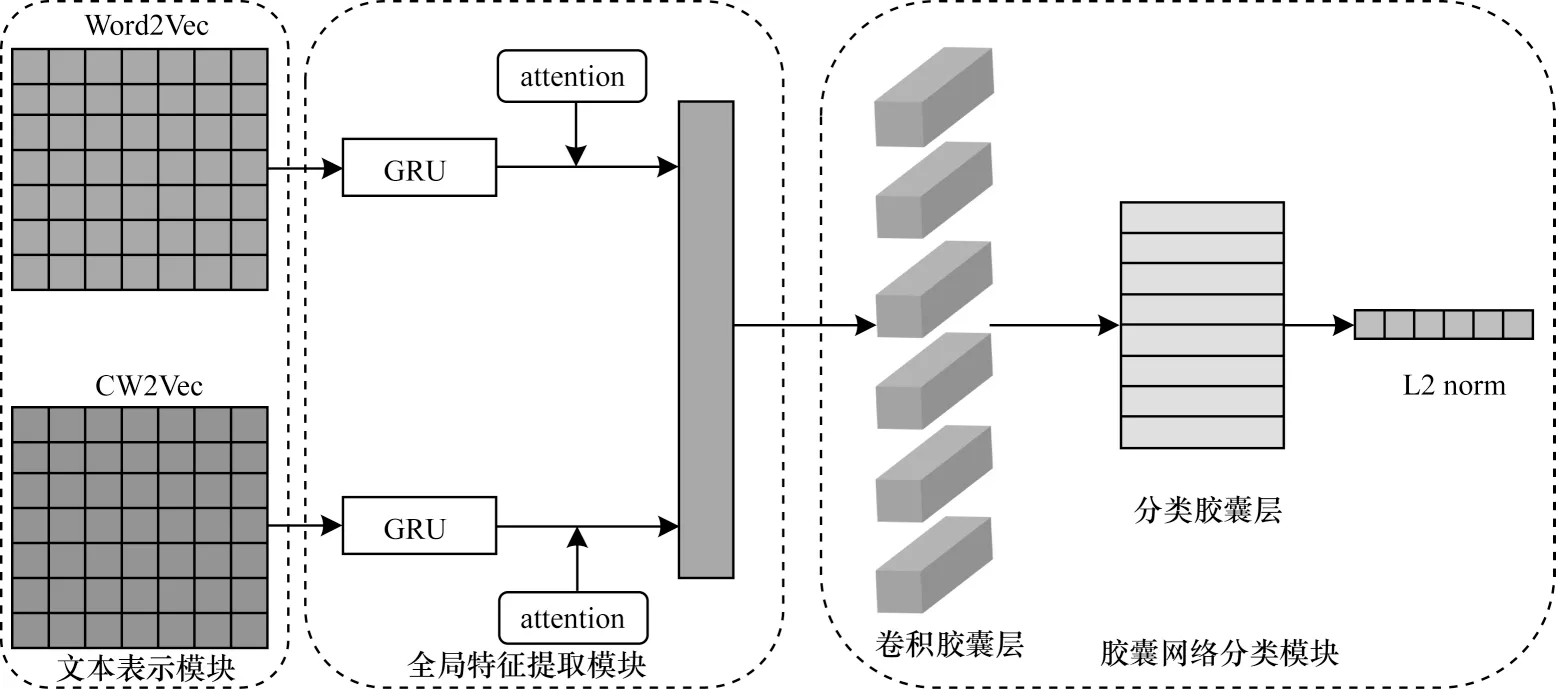
图1 GRU-ATT-Capsule 混合模型结构Fig.1 Structure of GRU-ATT-Capsule hybrid model
2.1 文本表示模块
将文本序列表示为计算机能够处理的形式,表示方法主要包括离散表示和分布式表示。离散表示将文本中的每个词用向量表示,向量的维度就是词表的大小,该方式构建简单,但是不能表示词与词之间的关系,忽略了词的上下文语义。分布式表示考虑了词的上下文语义信息并刻画了词与词之间的语义相似度,并且维度较低,主要包括Word2Vec、Glove 等常用的词向量表示。由于汉语的文字系统与英语为代表的字母语言存在不同,因此为了融合汉字结构特征,采用双通道输入策略,利用基于文献[8]的笔画n-gram 方法来提取每个字对应的笔画向量,然后使用Skip-gram 模型进行词向量训练获得CW2Vec。
假定文本序列包含n个词,将其One-hot 表示为xi=(x1,x2,…,xn),i∈(0,n)作为输入。首先,利用训练好的CW2Vec 模型获取的词向量作为词嵌入层a的权重,并随机初始化词嵌入层b的权重为,将输入xi分别与输入权重W1、W2进行运算,具体过程如式(1)所示:

2.2 全局特征提取模块
2.2.1 GRU
循环神经网络是一种专门用于处理序列数据的神经网络,通过网络中的循环结构记录数据的历史信息,即当前隐藏层单元的输出不仅与当前时刻的输入有关,还依赖上一时刻的输出。RNN 还可以处理变长序列。本文采用门控循环单元提取文本特征,它是LSTM 的一种变体,在结构上与LSTM 相似,不同点在于GRU 简化了LSTM 的门控结构。LSTM 网络由输入门、输出门、遗忘门和记忆单元来实现历史信息的更新和保留。GRU 将LSTM 中的输入门和遗忘门合并,称为更新门zt。此外,重置门为rt,记忆单元为ht。更新门控制当前时间步的信息中保留多少先前时刻的历史信息。重置门决定了当前时刻的输入与前一时间步的信息之间的依赖程度。这两个门控向量决定了哪些信息最终能作为GRU的输出并被保存,GRU 结构如图2 所示。

图2 GRU 结构Fig.2 Structure of GRU
GRU 单元在时刻t的更新过程如式(2)~式(5)所示:
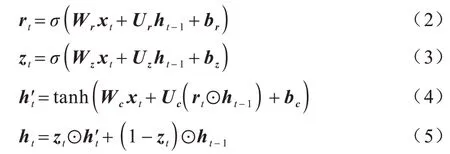
其中:xt为当前时刻的输入;ht-1为前一时刻GRU的输出;ht为当前时刻GRU 的输出;σ是sigmoid 激活函数;Wr、Wz、Wc、Ur、Uz、Uc为权重矩阵;br、bz、bc为偏置项;⊙表示向量间的点乘运算。
通过文本表示模块,长度为n的语句S可分别表示如下:

将文本表示Sa、Sb输入GRU 中获得上下文特征用于后续的注意力计算。
2.2.2 注意力机制
注意力机制是一种权重分配机制,对于重要的语义信息分配较多的注意力。在文本分类任务中,句子中不同的词对分类效果的影响是不同的,本文引入注意力机制识别文本中的重要信息。将GRU的隐藏层输出ht作为输入,得到:

其中:Wa为权重矩阵;ba为偏置;ui为hi的隐层表示;权重ai为经过softmax 函数得到的每个词的标准化权重,然后通过加权计算得到注意力机制的输出向量vi。
2.3 胶囊网络分类模块
CNN 的池化操作会丢失大量的特征信息使得文本特征大幅减少,其中神经元为标量。在胶囊网络中使用胶囊(即向量)来代替CNN 中的标量神经元。胶囊网络的输入输出向量表示为特定实体类别的属性,通过使用动态路由算法在训练过程中迭代调整低层胶囊与高层胶囊的权重cij,低层胶囊根据多次迭代后的权重通过压缩函数共同来决定某个高层胶囊表示,并将通过动态路由得到的所有高层胶囊进行拼接得到最终的高阶胶囊表示。
卷积胶囊层的输入为融合层的输出,输出作为分类胶囊层的输入。动态路由通过多次迭代路由来调整耦合系数cij确定合适的权重:

其中:i表示底层;j表示高层。
路由算法利用式(10)中的变换矩阵Wij将低层胶囊进行转换用于获得预测向量,通过式(11)获得来自底层胶囊的预测向量的加权和sj。为使胶囊的模长表示对应类别的分类概率,通过压缩函数式(12)进行归一化得到高层胶囊vj。利用式(13)计算高层胶囊vj与底层预测向量的点积,当低层预测向量与输出胶囊vj方向趋向一致时,增加对应的耦合系数cij。通过多次迭代路由算法对耦合系数进行调整得到修正后的高层胶囊νj。


3 实验与结果分析
3.1 实验环境
为验证GRU-ATT-Capsule 混合模型在文本分类中的效果,采用基于TensorFlow 的Keras 进行开发,编程语言为Python3.6。数据集被随机打乱。服务器配置如下:CPU 为Intel Core i5-8500 主频3.0 GHz,内存32 GB,硬盘1 TB,操作系统为Ubuntu16.04,GPU为GeForce RTX 2080 SUPER。
3.2 实验数据
为评估GRU-ATT-Capsule 混合模型的有效性,采用搜狗实验室的中文新闻数据集,该数据集包含419 715 条数据,可被标出类别的共有14 类,去掉4 类样本数不足的数据,保留其中的10 类作为分类文本分解。每类数据选择2 000 条文本,训练集、验证集和测试集的划分比例为8∶1∶1。数据集分布如表1所示。
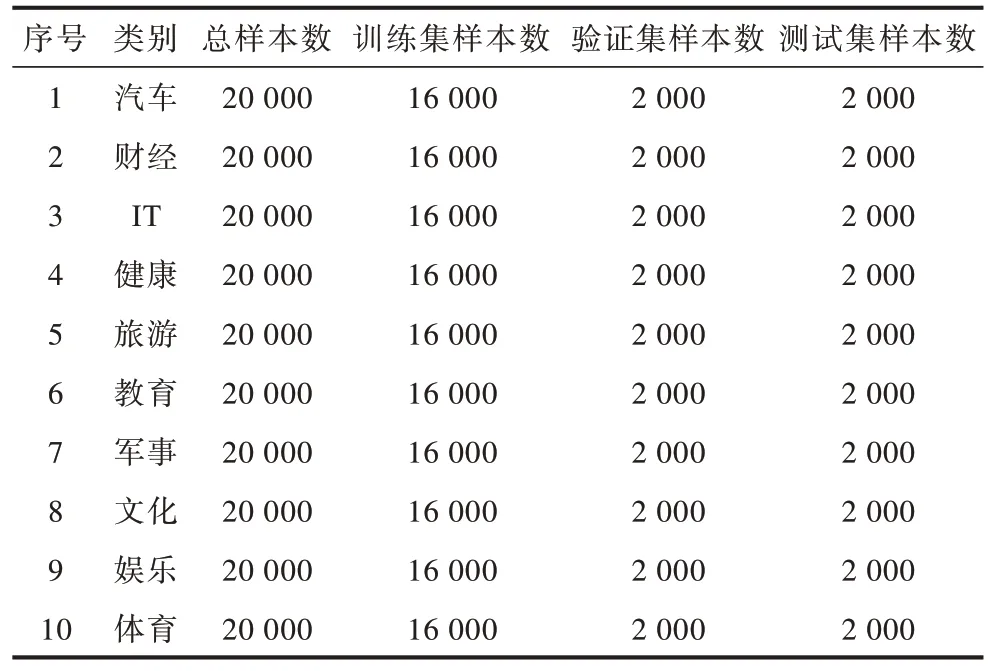
表1 数据集样本类别分布Table 1 Dataset sample category distribution
实验的预处理部分首先将文本数据进行转码,然后使用Jieba 分词工具对每条数据进行分词,再加上对应的标签。
3.3 评价指标与实验设置
实验采用准确率作为评价标准,准确率计算公式如下:

其中:TTP为真正例;TTN真负例;FFP为假正例;FFN为假负例。
使用搜狗语料SogouCA 训练CW2Vec 词向量作为第1 个通道的词向量。窗口n设置为5,词向量维度设置为200,最低词频设为10,用于过滤词频较低的词。在训练过程中,使用Adam 优化器,将学习率设置为0.001,并且在每个epoch 将学习率衰减0.99来降低学习率。GRU 单元数量设置为64。底层胶囊数量设置为6,文献[19]使用了1 152 个胶囊进行图像分类,之所以进行这种操作,是因为该方法生成的特征图包含的有效信息不足。高层胶囊数量设置为10,对应不同类别,胶囊的模长代表所属类别的概率。为验证GRU-ATT-Capsule 混合模型的有效性,将TextCNN 模型[9]和BiGRU-ATT 模型[11]作为基线进行对比分析。
3.4 结果分析
从训练集、验证集和测试集出发比较TextCNN、BiGRU-ATT 和GRU-ATT-Capsule 混合模型的文本分类效果,实验结果如表2 所示。

表2 3 种神经网络模型的分类准确率对比Table 2 Comparison of classification accuracy of three neural network models %
3 种模型的epoch 设置为40,在训练集上的准确率均达到98%以上,其中基于GRU-ATT-Capsule 混合模型的文本分类准确率最高,达到99.63%。在验证集上的分类准确率均达到82%以上,仍是基于GRU-ATT-Capsule 混合模型的文本分类准确率最高,达到89.25%。对于测试集,3 种模型在测试集上的分类准确率明显低于训练集和验证集,但是本文GRU-ATT-Capsule 混合模型的准确率仍为最高,达到87.55%。由此可见,在文本分类任务中,本文提出的GRU-ATT-Capsule 混合模型的分类效果要优于TextCNN 模型和BiGRU-ATT模型。
由于卷积神经网络的池化操作会导致特征信息丢失,因此采用动态路由机制的胶囊网络用于获得合适的权重,将低层胶囊的特征信息传递到高层胶囊中,从而更好地捕捉文本序列中的特征信息。为进一步证明本文融合的笔画特征对文本分类的有效性,设置模型对比实验进行分类性能验证。将GRUATT-Capsule 混合模型的输入分别设置如下:
1)Single:采用单通道输入,使用随机初始化的Word2Vec 词向量作为输入,在训练过程中通过模型的反向传播进行不断调整。
2)Dual:采用双通道输入,一个通道采用包含笔画特征的CW2Vec 词向量作为输入,另一个通道采用随机初始化的Word2Vec 词向量作为输入,在训练过程中可以通过模型的反向传播进行不断调整。
2 种输入方式下的GRU-ATT-Capsule 混合模型分类准确率对比结果如表3 所示。由表3 可知,本文提出的融合笔画特征的GRU-ATT-Capsule 混合模型在验证集和测试集上的分类准确率相比基于单通道输入的GRU-ATT-Capsule 混合模型分别提高了0.15和0.45 个百分点,由此说明本文所提出的融合笔画特征的GRU-ATT-Capsule 混合模型相比基于单通道输入的GRU-ATT-Capsule 混合模型能够提取包括汉字结构在内的更多的文本特征,从而提高文本分类效果。

表3 2 种输入方式下的GRU-ATT-Capsule 混合模型分类准确率对比Table 3 Comparison of classification accuracy of GRU-ATTCapsule hybrid model with two input modes %
4 结束语
本文提出一种融合笔画特征的胶囊网络文本分类方法。通过2种不同的词向量来表示文本内容,补充文本的汉字结构特征。使用GRU模型提取全局文本特征,在GRU 后引入注意力机制,并利用注意力机制对词的权重进行调整进一步提取文本序列中的关键信息。融合2种表示结果作为胶囊网络的输入,通过胶囊网络解决了卷积神经网络池化操作的信息丢失问题。实验结果证明了GRU-ATT-Capsule混合模型的有效性。后续将对GRU-ATT-Capsule混合模型的词向量融合方式进行改进,进一步提高文本分类准确率。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代装饰(2021年2期)2021-07-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
小学生优秀作文(低年级)(2020年4期)2020-07-24
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
