
基于跨域特征关联与聚类的无监督行人重识别
2022-03-12 05:56汪荣贵薛丽霞
计算机工程 2022年3期
汪荣贵,李 懂,杨 娟,薛丽霞
(合肥工业大学计算机与信息学院,合肥 230601)
0 概述
随着深度学习的发展,行人重识别已成为计算机视觉领域的研究热点,因其在行人行为分析[1]、行人追踪[2-4]等方面的广泛应用而备受关注。行人重识别技术与行人检测算法相结合,普遍适用于智能视频监控系统[5]。
行人重识别的研究面临行人姿态变化、图像分辨率低、行人遮挡姿态不完整以及由镜头切换导致行人视角转变、光照和背景变化等诸多挑战。由于拍摄场景的多样性,即使同一行人在不重叠视域的多摄像机或不同环境条件下表现的体貌特征也可能存在较大的差异,而不同行人可能因体型或衣着相似导致特征区分度低。此外,行人重识别数据获取难度较大,虽然通过目标检测方法[6]或基于深度学习的行人跟踪算法能够自动提取图像中的行人区域,但仍需人工标注行人身份ID。文献[7]根据已标注行人数据,采用生成对抗网络(Generative Adversarial Network,GAN)[8]快速生成行人样本,然而生成的图像分辨率较低,且模型性能提升有限。文献[9]提出结合行人外观和结构空间特征,通过GAN 生成高质量的图像样本,进一步提高模型性能。
虽然数据集规模的扩充能够提高行人重识别模型的准确率,在一定程度上解决数据集规模过小的问题,但是GAN 网络在训练过程中仍需标注大量样本。此外,不同行人重识别数据集在样本量和图像风格上存在较大差异,使得在一个数据集上训练的模型直接应用到未知数据时,会出现准确率显著下降的情况。针对该问题,无监督行人重识别方法[10-12]将无标注或仅部分标注的目标数据集加入到训练中,模型能够学习到目标数据集的样本特征,在一定程度上解决行人重识别的跨域问题。然而无监督行人重识别方法缺乏足够的标注信息,其与监督学习模型在准确率上存在较大差距。为进一步提升无监督行人重识别的准确度,文献[13]利用聚类方法将具有相似视觉特征的图像分配相同的伪标签,并用此方式获得的数据作为标注样本。文献[14]通过迭代选择聚类无标记的目标域以生成弱标签。文献[15]提出深度软多标签参考学习网络,将每张无标注行人图像与一组辅助参照样本进行对比,使得软多标签在不同视角相机下保持一致性。文献[16]提出一种基于软化相似度学习的无监督行人重识别框架,采用重新分配软标签分布的分类网络对约束平滑的相似图像进行学习。以上方法未能同时利用已有的标注数据来探索无标注数据内部特征关联。行人重识别域自适应的目标是利用有标记的源域与未标记的目标域学习一个具有较高泛化能力的行人重识别模型。当前主流方法多为减小源域和目标域之间的特征分布差异,而忽略了无标注目标域的域内变化。
以上行人重识别算法的无标注数据检索准确度低,为此,本文提出一种域自适应无监督行人重识别算法。利用跨域特征提取器(CSTE)挖掘不同行人重识别数据集间潜在的特征关联,在无任何标注信息的情况下,特征库从一个未知数据集中学习判别性特征,建立无标注目标域潜在的内部样本关联,从而提高行人重识别模型在无标注目标域的泛化能力。
1 域自适应无监督行人重识别网络结构
1.1 模型架构
源域和目标域分别代表已标注与无标注的行人重识别数据集,给定包括Ns张行人图像的源域数据集{Xs,Ys},每张行人图像标注有ID 信息;目标域数据集{Xt}包含Nt张行人图像,所有行人无ID标注信息,其中s、t 分别表示源域与目标域。本文将已标注源域与无标注的目标域行人样本加入训练,学习一个在目标域具有较强泛化能力的特征表示。
本文所提的域自适应无监督行人重识别模型架构如图1 所示。

图1 本文模型架构Fig.1 Framework of the proposed model
本文模型架构由ResNet-50 骨干网络、跨域特征提取器(CSTE)和存储目标域特征的特征库3 个模块构成。ResNet-50 作为模型骨干网络,初步提取输入图像特征。CSTE 通过学习源域与目标域行人的迁移不变性特征以挖掘不同行人重识别数据集间潜在的特征关联。特征库是利用无监督学习聚类算法从目标域中挖掘潜在的内部样本关联,以保存无标注目标域的样本特征。
模型的输入包括标注的源域行人数据集{Xs,Ys}与无标注的目标域行人数据集{Xt}。对于行人样本xi,ResNet-50 骨干网络提取中间卷积层Layer 3 与Layer 4 的特征,并 对Layer 4 卷积层的输出用全局平均池化(Global Average Pooling,GAP)提取2 048 维特征向量。模型训练过程分为有监督学习过程和无监督学习过程2 个阶段,主要包括:1)在ResNet-50 骨干网络的分类模块与CSTE 分类模块,应用ID 分类损失函数对输入的已标注源域样更新模型参数;2)对于无标注的目标数据集,CSTE 模块对ResNet-50 Layer 3 层的输出提取2 048 维的特征向量,并与ResNet-50 输出的同维向量相连,以得到4 096 维特征向量作为训练阶段目标域行人特征,并将其存入在训练过程中实时更新的特征库,同时依据特征库计算目标域损失Ltgt以更新网络模型。评估阶段是对所有目标域输入图像进行提取,得到4 096 维Eval 特征向量,并作为模型的输出,将计算得到各行人Eval 特征向量的余弦距离作为其相似度,对相似度进行排序并作为行人检索结果以评估模型性能。
1.1.1 跨域特征提取器
监督行人重识别算法无法利用无标注的目标域行人样本来更新模型参数,使得模型难以有效学习目标域的行人特征。本文所提CSTE 可以挖掘不同行人重识别数据集间潜在的特征关联。CSTE 提取输入的源域行人样本的特征向量,通过全连接分类层输出对应于源域行人ID 数维度的向量,使用分类损失函数对输入的源域图像更新模型参数。同时,CSTE 提取无标注的目标域行人样本的提取2 048 维特征向量,将其与ResNet-50 输出的同维向量相连并作为训练阶段目标域行人特征,并将该特征存储到特征库的对应位置。CSTE 结构如图2所示。

图2 跨域特征提取器结构Fig.2 CSTE structure
给定输入特征X∈RC×H×W,其中C表示输入特征通道数,H、W分别表示特征图高与宽,CSTE 模块提取流程主要有5 个步骤。
步骤1保持输入特征图X通道数C不变,并在宽和高两个方向上展开得到矩阵A=[C×N],AT=[N×C],如式(1)所示:

其中:n∈{1,2,…,H×W};w+h×W=n;N=H×W,即将二维特征图在宽和高两个维度上展开为特征向量,方便后续计算。
步骤2将Softmax 函数应用于矩阵A×AT与AT×A以更新参数,从图2 可以看出,通过上下两个通路提取通道与特征图宽和高两个方向对应的特征矩阵,如式(2)、式(3)所示:
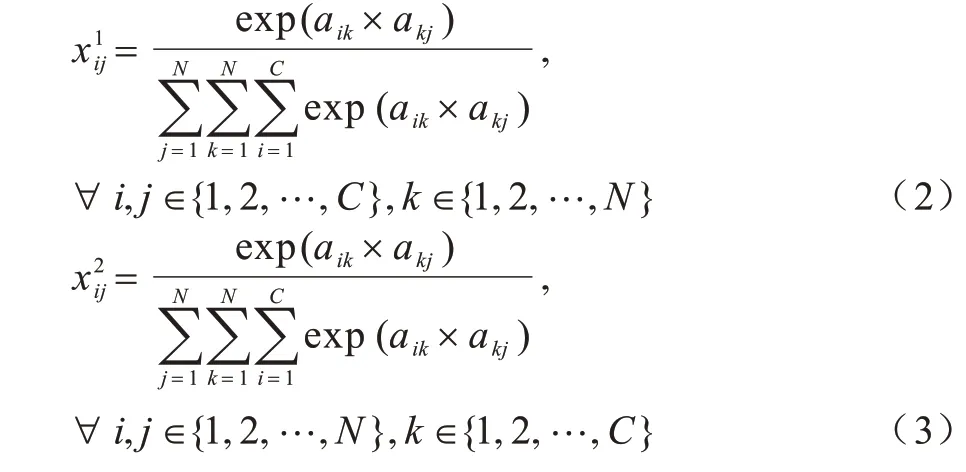
其中:aij为矩阵A的第i行、第j列元素。在步骤2 中分别提取了源域与目标域在通道与特征图方向的共性特征,并将其融合以挖掘两个数据域间潜在的特征关联。
步骤3将原始特征图A分别与第2 步得到的矩阵相乘,如式(4)、式(5)所示:

步骤4将步骤3 的输出恢复为原始输入特征图X的大小,如式(6)、式(7)所示:
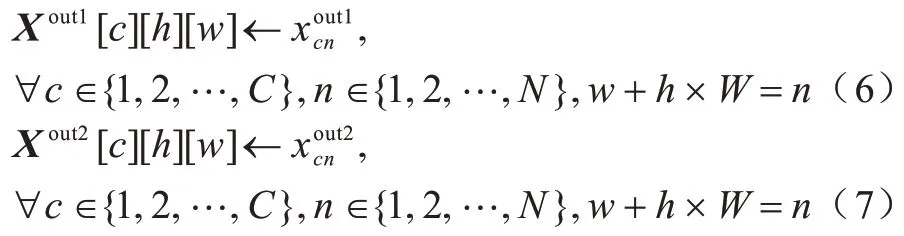
步骤5将Xout1与Xout2分别与原输入特征图X对应的元素相加,再经全局平均池化(GAP)得到2 个大小为1 024 的特征向量,最后将2 个向量直接相连作为CSTE 模块的最终输出,如式(8)所示:
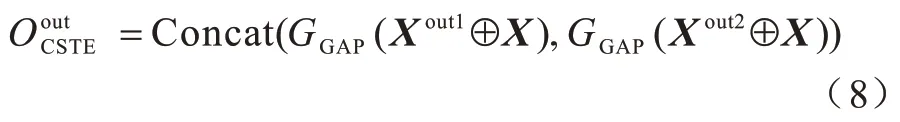
其中:⊕为特征按元素求和操作;GGAP为全局平均池化。在无监督学习设置下,将2 048 维的特征与ResNet-50 输出的同维向量相连接,作为目标域的样本特征并存储在特征库的相应位置。CSTE 利用ID 分类损失对源域行人样本进行监督学习。
1.1.2 特征库
为提高行人重识别算法在实际应用场景下的准确度,本文将无标注的目标域行人样本加入进行训练。由于有监督学习方法无法将分类损失函数应用于无标注数据中,本文提出FB 模块以存放目标域行人的特征向量,并在模型训练阶段实时更新特征库,在目标域中通过无监督学习聚类算法挖掘潜在的内部样本关联。本文定义特征库,其 中,索引i表示目标域第i个样本,Nt表示目标域样本总数,vi为维度D(4 096)的特征向量,分别对应于目标域各样本的实时特征。特征库初始化为,以表示模型提取目标域样本的特征向量,在模型训练过程中通过式(9)实时更新特征库:
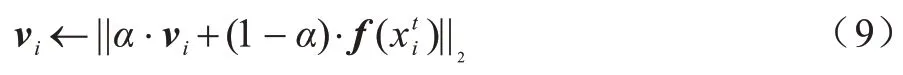
其中:|| ·||2为L2 正则化;参数α为控制特征库更新率,并随着模型轮回数的增加而减小,α越大表示当前阶段特征更新越缓慢。
在模型训练过程中,特征库存储所有目标域样本的特征向量,通过计算样本间特征余弦距离以搜索与目标域中具有相似特征的行人。定义为目标域所有行人余弦距离矩阵,如式(10)所示:

其中:Ε[i][j]∈[0,1];V[j]为特征库中图像的特征向量。若两个样本的余弦距离大于一定的阈值θ(0.5)时,则表示该样本对为同一行人,否则将其视为不同的ID。式(11)定义的Κ[i][j]表示输入图像和是否为同一行人。Κ[i][j]=1 表示输入样本与属于同一行人,相反Κ[i][j]=0 表示两个行人身份ID 不同。

本文利用无标注样本间的潜在特征关联选择目标域中特征相近的样本作为同一聚类,通过最小化目标域相似样本间的距离来拉近正样本对,定义如下损失函数,如式(12)所示:

其中:|| ·||为对所有元素求和;利用Softmax 函数计算行人xt身份ID 为i的概率,如式(13)所示:
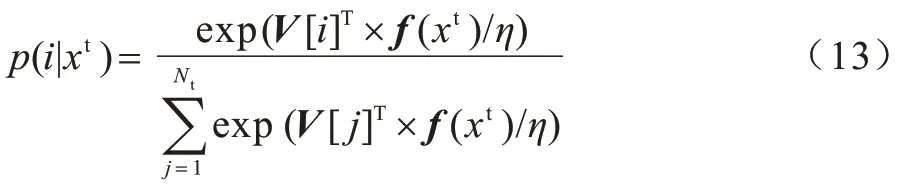
其中:η为Softmax 函数的温度参数,η越大则函数结果越平滑,反之越尖锐,本文取值为0.1;V[j]表示特征库第j列,即vj。
在训练过程中将目标域中所有样本视为不同的行人,Lpush损失函数使得不同行人之间的距离最大化,从而提高模型挖掘无标注样本潜在区别性特征的能力,如式(14)所示:

本文通过无监督学习挖掘目标域中的特征关联,设计Lpush和Lpull损失函数以拉近特征相似的正样本对,从而推远特征相差较大的负样本对。本文用Ltgt表示上述两个损失函数之和,如式(15)所示:

1.1.3 多损失函数学习
本文利用源域与目标域行人数据来更新模型,将训练过程分为监督和无监督2 个阶段。在监督学习阶段,本文采用分类交叉熵损失函数Lsrc更新ResNet-50 骨干网络,如式(16)所示:

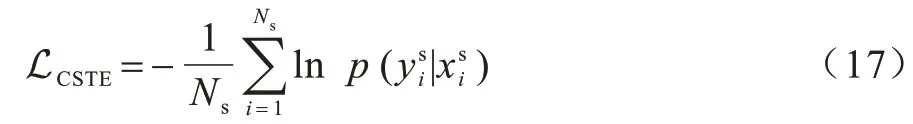
用于模型训练的总损失函数如式(18)所示:

其中:参数λ、β、ζ为控制上述3种损失函数的相对权重,在实验中分别设置为0.3、0.7、0.5。最小化LCSTE能够提高模型有效挖掘源域与目标域之间特征关联的能力。
2 实验结果分析
2.1 实验数据与评价准则
为验证所提算法的有效性,本文在行人重识别三大公开数据集Market-1501[17]、DukeMTMC-reID[2]与MSMT17[18]上进行实验,采用平均精度均值(mAP)[17]和累积匹配特性曲线(CMC)[19]作为算法性能的评估指标。Market-1501数据集包括在6个摄像头视角下的1 501个行人,其中751个行人的12 936幅图像用作训练,750个行人的19 732幅图像用于评估模型性能。DukeMTMC-reID作为DukeMTMC数据集的子集,包括在8个摄像头下采集的1 812个行人的16 522个样本,2 228幅检索图像。MSMT17数据集包括在12个室外和3个室内共15个摄像头采集的4 101个行人的126 441幅图像,是目前规模最大的行人重识别数据集。
2.2 实验环境
本文使用ImageNet 数据集[20]预训练ResNet-50模型[21]作为骨干网络。实验采用Linux 环境下开源Pytorch 框 架[22],在NVIDIA GeForce RTX 2080Ti GPU 上进行80 个轮回数,将所有输入的图像尺寸调整为256×128,并以0.5 的概率进行随机水平翻转和随机擦除[23],采用随机梯度下降(SGD)优化器[24],学习率为0.1,动量因子为0.9。
2.3 其他先进算法对比
近年来,其他先进跨域行人重识别算法主要有PTGAN[18]、CamStyle[25]、SPGAN[10]、MMFA[26]、TJ-AIDL[27]、HHL[28]、ECN[29]等,其 中PTGAN[18]、CamStyle[25]通过扩充样本提高模型的泛化能力,SPGAN[10]、MMFA[26]、TJ-AIDL[27]、HHL[28]与ECN[29]为域自适应无监督行人重识别算法。本文在三大公开行人重识别数据集上对本文算法与其他算法进行性能对比,以验证本文所提算法各模块在不同实验设置下的有效性。在Market-1501/DukeMTMC-reID数据集上不同算法的性能指标对比如表1 所示。当DukeMTMC-reID 为源域,Market-1501 为目标域时(DukeMTMC-reID to Market-1501),本文算法的mAP指标和Rank-1 指标相较于ECN 算法分别提高20.1 和8.9个百分点。当DukeMTMC-reID 为目标域,Market-1501为源域时(Market-1501 to DukeMTMC-reID),本文算法mAP 和Rank-1 指标相较于ECN 算法分别提高8.7 和6.8 个百分点。在Market-1501/DukeMTMC-reID 数据集,本文所提算法的CMC 与mAP 指标均优于近年来无监督行人重识别算法。

表1 在Market-1501 和DukeMTMC-reID 数据集上不同算法的性能指标对比Table 1 Performance indexs comparison among different algorithms on Market-1501 and DukeMTMC-reID datasets %
为进一步验证本文算法的有效性,表2 表示MSMT17 为目标域时不同算法的性能指标对比。当Market-1501 为源域时,相比ECN 算法,本文算法的Rank-1 和mAP 分别提高了6.1 和2.9 个百分点。当DukeMTMC-reID 为源域时,相比ECN 算法,本文算法的Rank-1 和mAP 指标分别提高4.5 和2.8 个百分点,说明本文算法在大规模行人重识别数据集具有通用性与适应性。

表2 在MSMT17 数据集上不同算法的性能指标对比Table 2 Performance indexs comparison among different algorithms on MSMT17 dataset %
本文模型经过80 个轮回数训练后的性能测试用时如表3 所示。实验数据集规模由小到大依次为:Market-1501、DukeMTMC-reID 与MSMT17。从表3 可以看出,模型训练和测试用时与数据集包括的图像数量成正相关。

表3 训练与测试各数据集时间对比Table 3 Comparison of training and testing time of each dataset
2.4 消融实验
在Market-1501/DukeMTMC-reID 数据集上,本文算法有无Ltgt的准确率对比如图3 所示。从图3 可以看出,模型在约70 个轮回数时出现收敛的情况。为验证本文算法中各模块的有效性,在本文算法中加入FB 模块和同时加入FB 和CSTE 模块的性能指标对比如表4所示。在以DukeMTMC-reID 作为源域的Market-1501数据集上,同时加入FB 和CSTE 模块相较于只加入FB模块算法的Rank-1 和mAP 分别提升了1.9 和2.6 个百分点,在以Market-1501 作为源域的DukeMTMC-reID数据集上,Rank-1和mAP分别提升1.9和2.3个百分点。因此,同时加入FB 和CSTE 模块能够高效地利用源域与目标域的特征属性,有助于提升算法提取行人特征的能力,从而提高算法的准确性。
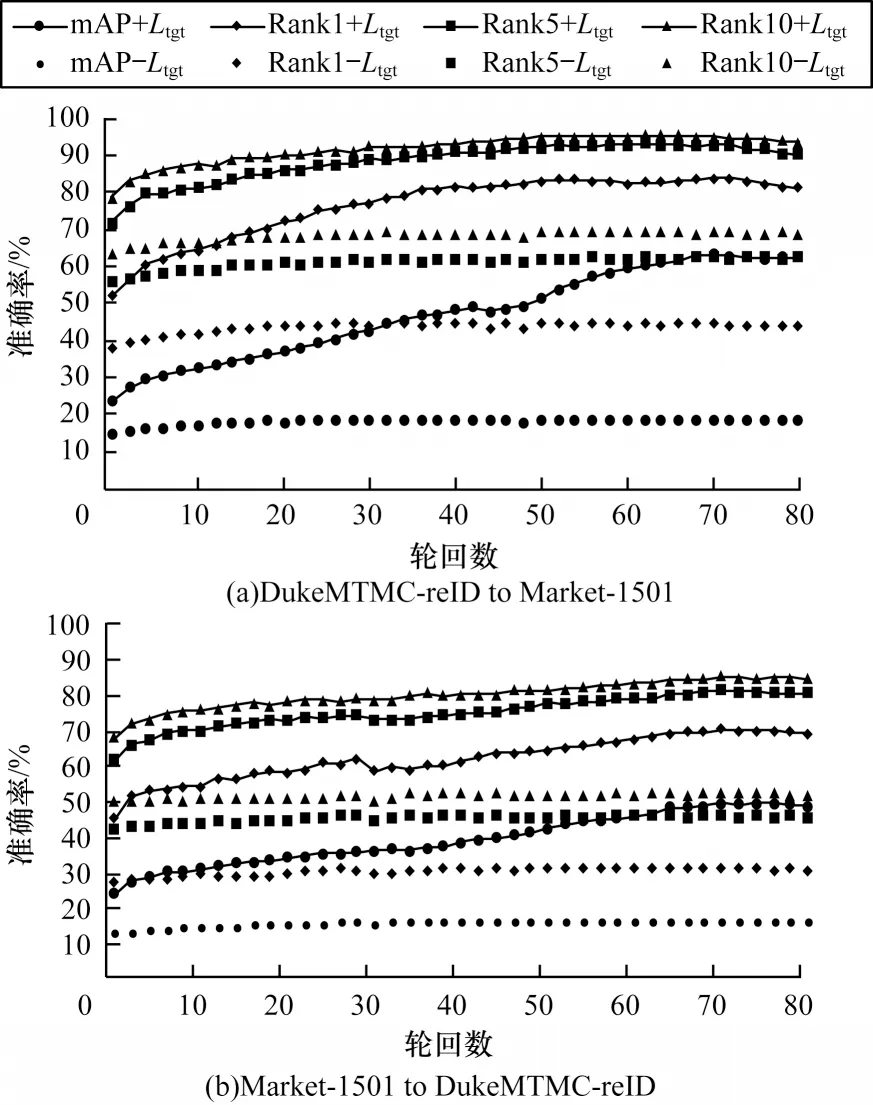
图3 本文算法有无Ltgt的准确率对比Fig.3 Accuracy comparison of the proposed algorithm with and without Ltgt

表4 本文算法有无CSTE/FB 模块的性能指标对比Table 4 Performance indexs comparison of the proposed algorithm with and without CSTE/FB modules %
图4 展示了在Market-1501 与DukeMTMC-reID数据集上本文算法有无FB/FB+CSTE 模块的部分行人检索结果,输出与查询图像最相似的10 张行人检索图片。图中空心矩形框包围的图像检索结果与查询图像属于不同的行人,即错误的检索结果。其他图像表示检索结果与查询图像属于同一行人,具有相同标签为正确的检索结果。从图4 可以看出,在Market-1501 与DukeMTMC-reID 数据集上引入CSTE 模块均能改进模型的检索效果。

图4 本文算法有无FB/(FB+CSTE)模块的部分行人检索结果Fig.4 Part of pedestrian search results of the proposed algorithm with and without FB/(FB+CSTE)modules
3 结束语
本文提出一种域自适应的无监督行人重识别算法,利用跨域特征提取器挖掘不同行人重识别数据集间潜在的特征关联关系,以提高算法在未知数据集上的泛化能力,同时通过特征库存储的无标注样本属性特征从未知数据集中学习判别性特征,建立目标域潜在的内部样本关联关系。实验结果表明,相比ECN、PTGAN 等算法,本文算法具有较强的可扩展性和识别性能,能够显著提高无监督跨域行人重识别的准确度。下一步将利用现有数据改进模型泛化能力,研究适用于多源域多目标域应用场景的行人重识别算法。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
意林(2021年5期)2021-04-18
计算机技术与发展(2020年11期)2020-12-04
数学大世界(2019年7期)2019-05-28
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
青年文学家(2015年29期)2016-05-09
中学数学研究(2008年11期)2008-01-05
