
基于改进边界框回归损失的YOLOv3 检测算法
2022-03-12 05:56沈记全陈相均翟海霞
计算机工程 2022年3期
沈记全,陈相均,翟海霞
(河南理工大学计算机科学与技术学院,河南焦作 454000)
0 概述
目标检测技术是很多计算机视觉任务的基础,如实例分割[1-3]、图像描述[4-5]、目标跟踪[6]等,并且在工业、安防、视频监控、人脸识别[7]、机器人视觉[8]、自动驾驶[9]等诸多领域有极大的研究价值和应用前景,受到了学者们的广泛关注。当前,目标检测的研究已取得较大进展,检测精度及速度在不断提高。但是,由于尺度变化、旋转、遮挡、光照以及物体的稠密度、角度等不同因素的影响,目标检测的精度仍有较大的提升空间。近年来,基于深度学习的目标检测成为研究热点,卷积神经网络可以快速、准确地从大量样本中学习更通用的特征,并且无需对样品进行预处理,避免了复杂的手工制作和设计。
基于深度学习的目标检测算法大致分为两阶段检测算法和单阶段检测算法两种:一种是包括R-CNN[10]、Fast R-CNN[11]、Faster R-CNN[12]和Pyramid Networks[13]的两阶段检测算法,被称为基于候选区域的目标检测算法,其将目标检测过程分解为候选区域提取、候选区域分类和候选区域坐标修正3 个步骤;另一种是包括SSD[14]、RetinaNet[15]和YOLO[16-18]系列的单阶段检测算法,被称为基于回归分析的目标检测算法,其将目标检测问题视为对目标位置和类别信息的回归分析问题,通过一个神经网络模型直接输出检测结果。尽管存在这些不同的检测框架,但无论对于单阶段算法还是两阶段算法,边界框回归都是预测矩形框以对目标对象进行定位的关键步骤。
现有的目标检测算法常用平均绝对误差(Mean Absolute Error,MAE)损失(又称L1 范数损失)、均方误差(Mean Square Error,MSE)损失(又称L2 范数损失)函数计算边界框位置坐标的回归损失,但是L1、L2 范数损失对边界框的尺度具有敏感性,尺度越小的边界框预测偏差对其影响越大,且卷积神经网络在评价边界框的回归效果时使用交并比(Intersection over Union,IoU)作为评价标准,而L1、L2 范数损失与IoU 之间的优化并非等价。文献[19]提出将IoU 作为边界框回归损失函数对检测模型进行优化,但是存在真值框与预测框无交集时优化效果不佳的情况。文献[20]提出一种通用的优化边界框的方式破折号GIoU,解决了在真值框和预测框无交集的情况下将IoU 作为边界框损失函数不能反映边界框之间的距离、以及函数梯度为零导致模型无法被优化等问题。文献[21]采用GIoU 损失对YOLOv2 模型损失函数进行改进,提高了模型对车身焊点的检测精度。文献[22]在YOLOv3 网络中引入空间金字塔池化单元,并采用GIoU 损失计算坐标损失,在不降低速度的情况下,提高了无人机对罂粟的检测效率。上述损失函数虽然总体上比传统边界框损失函数效果更好,但在某些情况下仍存在收敛效果不佳的问题。
本文提出边界框回归损失算法BR-IoU。将IoU作为边界框回归的损失项,加强损失函数的优化与IoU 之间的联系,并添加惩罚项加快真值框与预测框中心点之间的重叠速度,通过使预测框和真值框宽高比保持一致,提升边界框的回归收敛效果。
1 相关工作
1.1 IoU 与GIoU
交并比(IoU)也被称为Jaccard 系数,用于衡量两个边界框重叠面积的相对大小,是2D 和3D 目标检测中常用的评价标准。IoU 具有尺度不变性、非负性和对称性,不仅可以用来确定正负样本,而且还可以反映模型中预测框的检测效果。如图1 所示,A 和B 为2 个重叠的边界框,其Jaccard 系数公式如下:

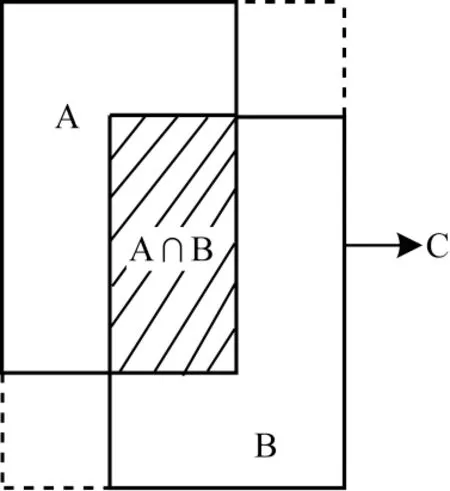
图1 矩形A、B 与最小封闭框CFig.1 Rectangle A,B and the smallest enclosed frame C
将IoU 作为边界框回归损失,其损失函数如下:

虽然IoU 作为评价标准具有优势,但是当边框无交集时将IoU 作为损失函数会导致无法反映两个边界框彼此之间的距离、损失函数梯度为零不能被优化等问题。如图2 所示,图2(a)场景预测框的位置相较于图2(b)场景离真实框更近,但是IoU 的值却都为0。

图2 边界框无交集时IoU 的比较Fig.2 IoU comparison when bounding boxes have no intersection
基于此,2019 年REZATOFGHI 等[20]提出的GIoU继承了IoU 具有的尺度不变性、非负性和对称性,同时克服了IoU 在边界框无交集情况下的不足。令图1 中包含A 和B 的最小封闭框为C,则GIoU 公式如下:

当A、B 两个边界框完全重叠时,IIoU(A,B)=1;当A、B 两个边界框无交集时,IIoU(A,B)=0。因此,IoU的取值区间为[0,1]。而GIoU 的取值区间具有对称性,即-1 ≤GGIoU(A,B)≤1,与IoU 相似:当两个边界框完全重叠,即|A ∪B|=|A ∩B|时,GGIoU(A,B)=1;当两个边界框无交集且距离无限大时,最小包围框C的面积趋近于无穷大,此时GGIoU(A,B)=-1。
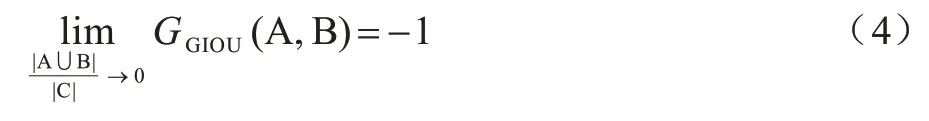
GIoU 取值区间的对称性使其比IoU 更能反映边界框的重叠和非重叠情况。本文将GIoU 作为边界框回归损失,其损失函数如下:

可以看出,边界框之间的GIoU 值越大,GGIoU_loss值越小,边界框的回归收敛效果越好。
1.2 YOLOv3 模型
YOLOv3 模型是具有代表性的单阶段目标检测算法,其通过缩放、填充将不同尺寸输入图像的大小调整为32 的倍数,再分成S×S个非重叠的网格,如图3 所示(S=7)。

图3 输入图像网格示意图Fig.3 Grid diagram of input image
每个网格负责检测中心点位置坐标落入该格的物体,网格中预设有3 个边界框和C个类别概率。在边界框预测的5 个分量x、y、w、h和置信度中,(x,y)坐标表示边界框的中心点相对于网格单元的位置,(w,h)坐标表示边界框的尺寸,置信度用来判断边界框中存在物体的概率。YOLOv3 通过对置信度设定阈值过滤掉低分的边界框,再对剩下的边界框使用非极大值抑制(Non-Maximum Supression,NMS)算法去除冗余边界框,得到预测结果,因此,YOLOv3每个网格有3×(5+C)个属性值。为了加强对小物体的检测性能,YOLOv3 借鉴了特征金字塔网络(Feature Pyramid Network,FPN)的思想,采用多尺度特征融合的方式,在不同特征层对不同大小的物体进行预测。同时,YOLOv3 通过上采样,自顶向下地融合底层的高分辨率信息和高层的高语义信息,提高了对不同尺度物体的检测精度,尤其增强了对小物体的检测精度。
YOLOv3 采用L2 范数计算边界框坐标的回归损失,L2 范数损失中不同尺寸边界框对其预测框坐标产生偏差的敏感度也不同。相对于大尺寸边界框,尺寸越小的边界框预测偏差对其IoU 的影响越大,因此,YOLOv3 在边界框位置损失部分乘以系数(2-tw×th)来缓解这一情况。为了实现多标签分类,YOLOv3 采用二元交叉熵函数取代softmax 函数计算边界框的类别损失。softmax 函数假设每个对象只属于一个类别,但是在一些复杂场景下,一个对象可能属于多个类别(例如女人和人),因此,在目标类别较复杂的数据集上,多标签分类的二元交叉熵函数能取得更好的预测结果。YOLOv3 网络模型的损失函数分为边界框坐标损失、置信度损失和分类损失。损失函数如式(6)所示:
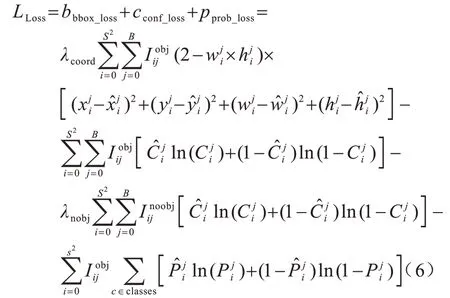

图4 YOLOv3 算法检测过程Fig.4 Detection process of YOLOv3 algorithm
2 BR-IoU 边界框回归损失算法
采用L2 范数边界框回归损失函数的YOLOv3检测算法通常会出现以下2 个问题:
1)如图5 所示,4 组边界框角点坐标距离的L2 范数损失值相等,但IoU 值却不同,这表明L2 范数损失不能准确地反映IoU 值的变化,与IoU 之间不具有强相关性。
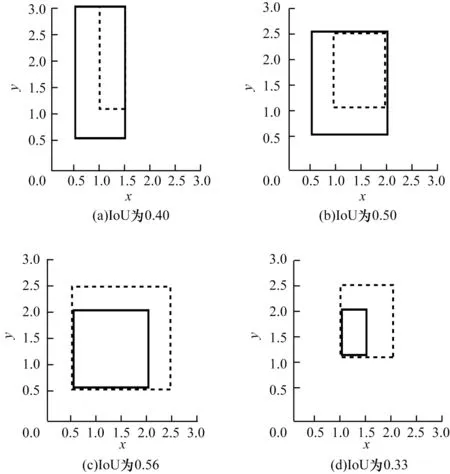
图5 L2 范数损失值相等时IoU 的变化Fig.5 Change of IoU when L2 norm loss values are equal
2)L2 范数损失具有尺度敏感性,在算法训练过程中,当两个边界框的IoU 值相同时,大尺寸边界框会产生更多的损失值使小尺寸边界框难以被优化,导致算法对小尺寸目标的检测效果不佳。
针对上述问题,本文提出BR-IoU 算法,为方便不同边界框损失算法的性能对比,将BR-IoU 算法分为BR-IoU-A 算法和BR-IoU-B 算法。
BR-IoU-A 算法将IoU 作为边界框回归的损失项,强化与IoU 之间的联系,并继承了IoU 的尺度不变性,使得不同尺度的边界框在回归过程中获得更均衡的损失优化权重。然后算法在IoU 损失项的基础上添加一个惩罚项,通过最小化预测框与真值框中心点围成矩形的面积,加快预测框中心点与真值框中心点的重叠速度。算法的惩罚项使边界框在任何情况下都存在梯度,在边界框无交集的情况下仍然能够反映边界框间的相对距离,为边界框的优化提供移动方向,如图6 所示,D 是真值框Bg的中心点bg和预测框B 的中心点b 围成的矩形框,Bc是真值框Bg与预测框B 的最小封闭框,w和h为D 的宽和高,wc和hc为Bc的宽和高,则BR-IoU-A 计算公式如下:

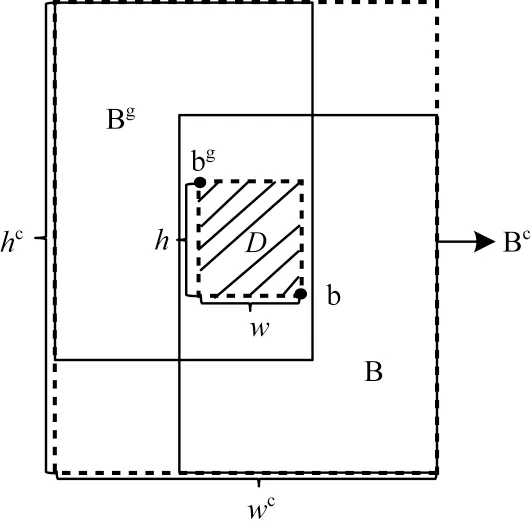
图6 BR-IoU-A 算法示意图Fig.6 Schematic diagram of BR-IoU-A algorithm
利用BR-IoU-A 算法计算边界框回归损失,损失函数如下:

BR-IoU-A 损失继承了IoU 和GIoU 损失的优良属性:1)BR-IoU-A 损失对边界框的尺度不敏感,具有尺度不变性;2)BR-IoU-A 损失在边界框无交集情况下仍然存在损失梯度,可以为边界框的优化提供移动方向;3)当两个边框完全重叠时,GGIoU=BBR-IoU-A=1,GGIoU_loss=BBR-IoU-A_loss=0;当两个边框距离无限远时,GGIoU=BBR-IoU-A=-1,GGIoU_loss=BBR-IoU-A_loss=2。但在某些情景下,如图7 所示(其中,实线框为真值框,虚线框为平面测框),真值框宽和高的值都为1,预测框宽和高的值为0.5。此时无论预测框与真值框的中心点间的距离如何变化,GIoU 与IoU 损失值都不变,由此可见,BR-IoUA 损失算法能很好地区分边界框之间的重叠情况。

图7 中心点间相对位置比较Fig.7 Comparison of relative positions between center points
图7(a)图像的检测效果优于图7(b)图像,BR-IoU-A 损失算法通过值的变化来反映这种情况。
算法BR-IoU-A 边界框回归损失算法


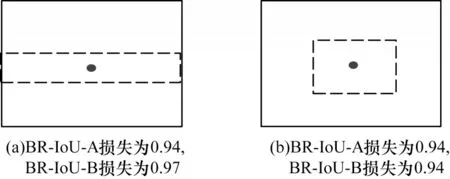
图8 预测框不同宽高比下的检测效果对比Fig.8 Comparison of detection effects under different aspect ratios of predicted bounding boxes
图8(a)预测框的宽高比值相较于图8(b)预测框更接近真实框,预测效果更好,但BR-IoU-A 值却相同。因此,本文在BR-IoU-A 的基础上,结合预测框与真值框之间宽高比的一致性提出BR-IoU-B 损失算法,计算公式如下:
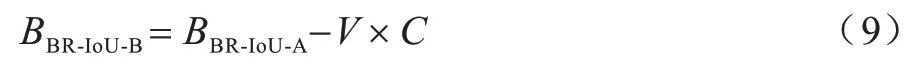
其中,参数V使预测框宽高比与真值框的保持一致,C是V的平衡参数,当两个边界框无交集或IoU 值较低时,使边界框之间的重叠因子在回归过程中获得较高优先级,从而加快边界框回归的收敛速度。

其中:wg、hg分别为真值框的宽和高;wp、hp分别为预测框的宽和高。综上,BR-IoU-B 损失函数如下:

使用BR-IoU 边界框回归损失算法对YOLOv3模型进行改进,改进后的损失函数如下:

3 实验结果与分析
本文实验模型基于Tensorflow1.13.1 框架,编程语言为python3.7,实验操作系统为Ubuntu16.04,GPU型号为NVIDIA Tesla P40,CUDA版本为10.0。为了验证BR-IoU算法的实际性能,将原始YOLOv3的边界框回归损失部分分别替换成GIoU 损失算法(简称G-YOLO)、BR-IoU-A 损失算法(简称BR-YOLO-A)、BR-IoU-B损失算法(简称BR-YOLO-B)。在PASCAL VOC 2007+2012 数据集和COCO 2014 数据集上进行模型评测和对比实验。
在算法训练过程中,为了增强模型性能,对数据集中的原始图像进行数据增强操作,通过图像随机裁剪、旋转、平移、颜色变化等方法,增加图像的多样性,使神经网络具有更强的泛化效果,提高模型鲁棒性。此外,为检测不同尺度图像中包含的不同尺度和形状的目标,在每个检测层中设定不同尺度的先验框与真实标签进行匹配。网络输入大小为416×416,模型参数更新方式为Adam,初始学习率为0.000 1,权重衰减设置为0.000 5。对于VOC 和COCO 数据集,模型加载预训练权重来完成初始化,令其他没有预训练权重的部分在训练过程中自适应微调参数,然后训练整个模型。为了在训练过程中使模型稳定,算法为模型训练设置两个轮次迭代的热身阶段。实验采用平均精度(Average Precision,AP)反映每一类目标的检测效果,平均精度是从准确率和召回率两个方面来衡量检测算法的准确性,可以直观地表现模型对单个类别的检测效果;采用平均精度均值(mean Average Precision,mAP)来衡量多类目标的平均检测精度,mAP 值越高,模型在全部类别中综合性能越高。
3.1 在PASCAL VOC 数据集上的对比实验
PASCAL VOC 2007+2012训练集共包含16 551张图像、40 058 个样本框,分为4 个大类和20 个小类。VOC 2007 测试集包含4 952 张图像、12 032 个样本框。PASCAL VOC 通过计算数据集IoU=0.5 时的mAP 对模型进行评价。该组实验在PASCAL VOC数据集上的训练迭代次数为100 轮,测试集上的mAP 及各类别目标的AP 检测结果如图9 和表1所示。
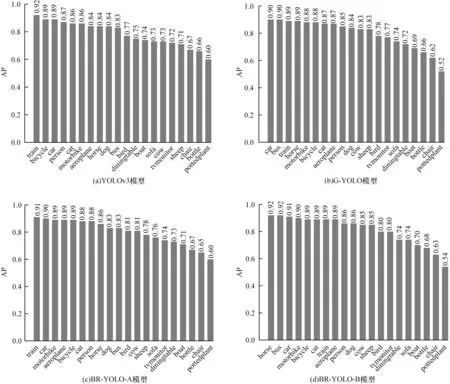
图9 PASCAL VOC 数据集上不同算法的AP 对比Fig.9 AP comparison of different algorithms on PASCAL VOC data set

表1 PASCAL VOC 数据集上不同算法的性能对比Table 1 Performance comparison of different algorithms on PASCAL VOC data set
实验结果表明,在不影响模型检测速度的情况下,BR-YOLO-B 算法的mAP 高出原YOLOv3 算 法2.54 个百分点,高出G-YOLO 算法1.51 个百分点。
3.2 在COCO 数据集上的对比实验
COCO 2014 训练集共包含82 783 张图像,分为80 个类别。从验证集中选取5 000 张图像作为测试集对模型进行评价。COCO 数据集将IoU 在[0.5∶0.95]区间内,步长为0.05 的10 个取值分别计算mAP 并取平均值作为检测模型的评价结果,相比VOC 数据集,COCO 数据集的多IoU 评价标准对检测算法的要求更高,更能反映检测算法的综合性能。该组实验在COCO 2014 数据集上的迭代次数为120 轮,实验结果如图10 和表2 所示。可以看出,后3 种模型相对YOLOv3 的检测效果均有所提高,这得益于BR-IoU-A 损失算法相比L2损失算法对不同尺度边界框的回归优化更均衡,并且与评价指标IoU 之间的优化更加密切,模型BR-YOLO-A 算法的mAP 对 比YOLOv3 提高了1.63 个百分点。此外,由于BR-IoU-B 算法进一步对预测框与真值框之间宽高比的一致性进行优化,因此BR-YOLO-B 算法的mAP 比YOLOv3 提高了2.07 个百分点。

图10 PASCAL VOC 数据集上的检测效果对比Fig.10 Comparison of detection effects on PASCAL VOC data set

表2 COCO 2014 数据集上不同算法的mAP 对比Table 2 mAP comparison of different algorithms on COCO 2014 data set %
表3 所示为4 种检测算法的空间与时间复杂度比较结果,其中时间复杂度为模型检测每张图像所需要的时间。由于模型的骨干网络都为Darknet53,因此4 种算法的网络参数数量基本相同,约为236×106。由表3 可以看出,相比YOLOv3算法,BR-YOLO-A 和BR-YOLO-B 算法检测速度更快。
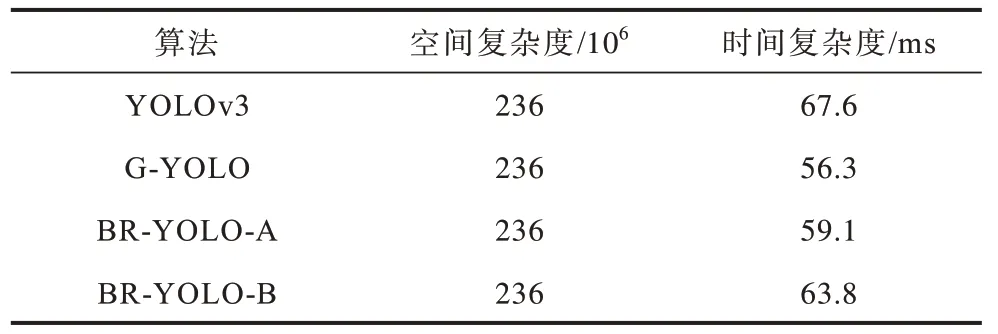
表3 不同算法的时空间复杂度对比Table 3 Time and space complexity comparison of different algorithms
4 结束语
针对YOLOv3 的L2 范数边界框回归损失函数对边界框的尺度敏感,以及与算法检测效果的评价标准IoU 之间相关性不强等问题,本文提出BR-IoU 算法,通过将IoU 作为损失项强化边界框回归与算法评估标准的相关性,最小化真值框和预测框中心点形成矩形的面积,同时提高预测框与真值框之间宽高比的一致性,以加强边界框的回归收敛性能。实验结果表明,BR-IoU能够有效提高YOLOv3 算法的检测精度和检测速度。下一步将结合本文算法设计思想对其他目标检测算法的边界框回归损失函数进行改进,在不影响检测速度的情况下达到更高的检测精度。
猜你喜欢
波谱学杂志(2022年1期)2022-03-15
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
安阳工学院学报(2020年4期)2020-09-11
锦绣·下旬刊(2019年3期)2019-09-10
现代交际(2018年14期)2018-11-01
中国校外教育(下旬)(2017年8期)2017-10-30
电子制作(2017年1期)2017-05-17
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
外语学刊(2009年3期)2009-06-04
