
基于EfficientDet 网络的细粒度吸烟行为识别
2022-03-12 05:56姚登峰江铭虎李凡姝
计算机工程 2022年3期
张 洋,姚登峰,,江铭虎,李凡姝
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.清华大学 人文学院 计算语言学实验室,北京 100084)
0 概述
吸烟行为是目前全世界难以解决的公共卫生问题,吸烟对健康的危害已是众所周知,其会间接或直接导致很多疾病的发生甚至出现生命危险[1]。近年来,我国人民出现肺癌、心血管疾病的几率随着吸烟率的增加而迅速上涨。然而,仅通过人为管理吸烟行为,难以实现控烟目标。
吸烟行为识别的研究起源于上个世纪,涌现了不同的吸烟行为检测方法,其中视频图像的吸烟行为检测是主流研究方向[2]。吸烟行为检测主要分为针对吸烟手势识别、香烟烟雾识别、香烟识别3 种,但这些方法都存在着一定不足。文献[3]设计一种将人体检测与嵌入式设备相结合的模型,其对户外的施工人员进行中距离吸烟检测。文献[4]结合吸烟行为手势与香烟目标本身特征,提出一种识别吸烟行为的检测模型,由于对吸烟行为手势的识别存在吸烟手势复杂、肤色多样、相机角度等问题,使得识别的手势具有差异,且易与吸烟行为类似的手势相混淆,因此仅使用吸烟手势来判断吸烟行为,误判率较大。文献[5]通过对获得香烟烟雾的HOG 特征以及纹理特征进行相关分析,再结合相关特征融合方法对香烟的烟雾进行识别。在香烟烟雾的检测过程中,因香烟的烟雾浓度较低且易扩散、烟雾边缘不够明显,导致香烟烟雾与室内的白色背景相融合,从而难以区分。此外,在室外受复杂背景干扰,香烟烟雾检测更加难以实现。针对识别香烟自身目标,文献[6]提出一种吸烟检测系统,利用Py Qt5 配置上位机界来调用训练过的改进YOLOv3 模型,并对吸烟行为进行检测。文献[7]基于YOLOv3-tiny 模型提出一种针对室内吸烟行为的检测算法。YOLOv3-tiny模型通过K-means 聚类算法得到整个香烟的预先目标框,在初始的YOLOv3-tiny 网络架构上引入一个细微的目标检测层,使得该模型能够满足实际场景的需求。文献[8]结合近红外监视摄像机与目标检测技术,提出一种新的吸烟行为检测方法。该方法利用基于深度学习的目标检测技术定位车辆前挡风玻璃和驾驶员的头部范围,通过执行双窗口异常检测局部区域并确定NIR 图像的高温白色热点,基于此确定驾驶员是否有吸烟行为。文献[9]通过检测人脸并将检测到的人脸图像作为烟支检测区域,从而大幅缩小了目标检测区域,并使用Faster RCNN 模型对香烟目标进行目标检测,以降低检测的误检率。文献[10]利用多个卷积神经网络任务算法级联并结合RET 级联回归的方式来实现迅速定位嘴部敏感区域,在此基础上,采用残差网络对ROI 内的目标进行检测和状态识别。文献[11]将检测到的人脸图像作为烟支检测区域,以缩小目标检测区域,并过滤掉与烟支相似的目标。以上算法都是直接对香烟进行检测,因香烟目标较小,其识别的准确性并不高,因此能否区分香烟与类烟物成为香烟识别的关键。
上述算法在一定程度上提升了吸烟行为的识别精度,但是其吸烟行为识别效果差。针对该问题,本文设计一种基于弱监督细粒度结构与改进EfficientDet网络的吸烟行为检测算法,用于识别实际场景中细微的香烟目标。通过EdgeBox 算法[12]对边缘进行筛选,形成候选区域块,将改进的EfficientDet 网络[13]作为细粒度两级注意力模型[14]的物体级筛选器,并在细粒度两级注意力模型的DomainNet网络结构中融入通道注意力机制[15],利用特征多尺度以及局部感受区域融合空间信息和通道信息,提取包含局部和全局信息的特征,进一步提升网络的识别精度。
1 网络架构
为快速而精准地区分香烟与类烟物,本文算法分为2 个模块:第1 个模块是特征边缘筛选,通过将收集到的图片进行有效的边缘筛选,以保存包含前景物体的候选区域,得到具有香烟目标和背景的像素块;第2 个模块是改进的弱监督细粒度网络模块,通过两级注意力模型与改进的EfficientDet 网络相融合,使其能快速筛选出候选区域,且具有更优的特征捕捉能力。其中细粒度模型主要分为2 个子模型:1)物体级模型,其通过对模型的预训练进行对象级图像分类,以滤除背景信息,保留包含待检目标的候选区域;2)局部级模型,其筛选出得分最高的像素块,最终通过检测结果获取吸烟特征,并判定是否存在吸烟行为。本文网络结构如图1 所示。

图1 本文网络结构Fig.1 Structure of the proposed network
1.1 特征边缘筛选
以w×h像素的图片作为模型的输入,利用边缘框的结构化边缘检测算子[16]提取图像边缘,并通过策略聚合得到的边缘段,并用非极大值抑制处理以得到稳定的目标边缘。
相似度的计算如式(1)所示:
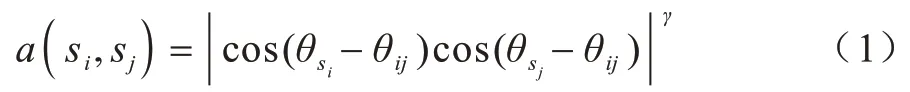
边缘段的权值如式(2)所示:
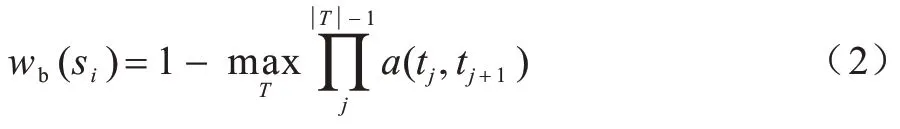
其中:T为由t1=Sj∈Sb到t||T=Si的路径;为滑动窗口的边界上与边缘段Si相似度最高的边缘段Sk。滑动窗口得分如式(3)所示:

其中:mi为边缘段的边缘强度;bw和bh分别为滑动窗口的宽和长;k为算法的平衡系数,以平衡不同窗口边缘段数量的差异。本文k取值为1.5。
特征边缘筛选过程通过上述公式得到每个滑动窗口的分数,设定阈值过滤最低值,则得到候选区域合集。
1.2 改进的弱监督细粒度网络模块
在细粒度分类领域中区分包含待检测物体的前景区域和检测物体,分为物体级筛选与分类和局部级选择与分类两个过程。图2 表示细粒度模型的识别流程。
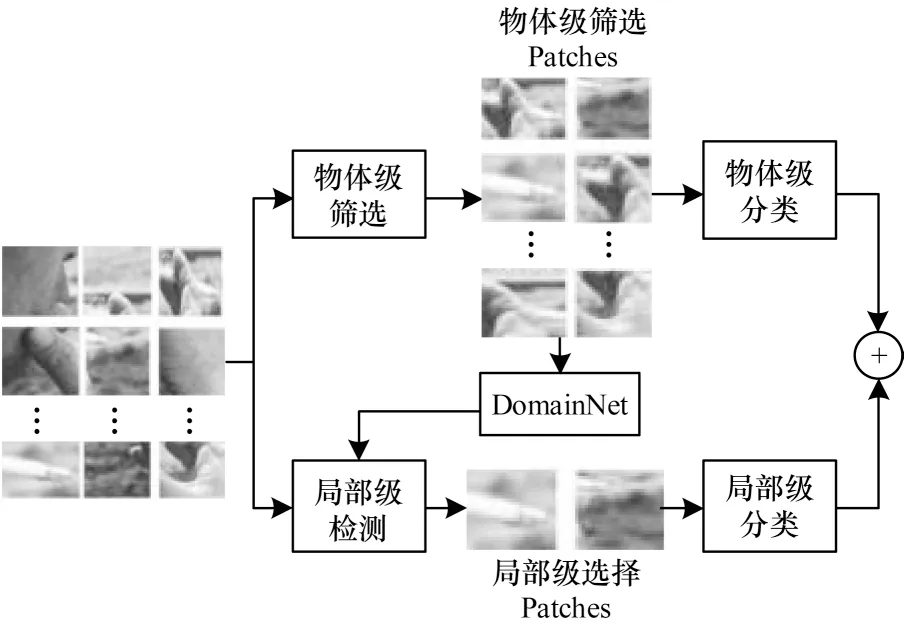
图2 细粒度模型的识别流程Fig.2 Recognition procedure of fine-grained model
1.2.1 物体级筛选及分类
物体级筛选器使用EfficientDet-D0 网络,对其在自建数据集上进行预训练处理,并在候选区域内进行背景噪声滤除,目的是删除与对象无关的嘈杂音色。原算法虽然能够滤除噪声,但其在分类预训练时使用的模型参数限制了位置回归准确率的提高。噪声的来源一般为环境、人物等未包含类烟物的候选区域,由于本文改进算法和原算法都使用特征金字塔网络(Feature Pyramid Network,FPN)等结构,区分纯背景与类烟物的准确率能达到98%以上,因此噪声的滤除效果远优于卷积神经网络(Convolutional Neural Network,CNN)。本文算法通过改进特征边缘筛选,以保证在深层特征图中依然可以提取香烟位置信息,由于特征边缘筛选通过EdgeBox算法获得众多的候选区域以及高召回率,并且检测网络结合局部级的注意力特性,能够完整地保留图像中的目标信息。因此,物体级筛选器能够有效地筛选出与香烟类别相近的候选区域和背景候选区域。EfficientDet-D0 网络由3 个部分构成:第1 个部分是基于EfficientNet-B0 结构的骨干网络;第2 个部分是模型的特征提取结构BiFPN,其作用是通过将骨干网络EfficientNet-B0 结构中3~7 层的输出特征不断地做自顶向下和自底向上的特征融合;第3 个部分是分类和检测框的预测网络。改进的EfficientDet网络结构如图3 所示。
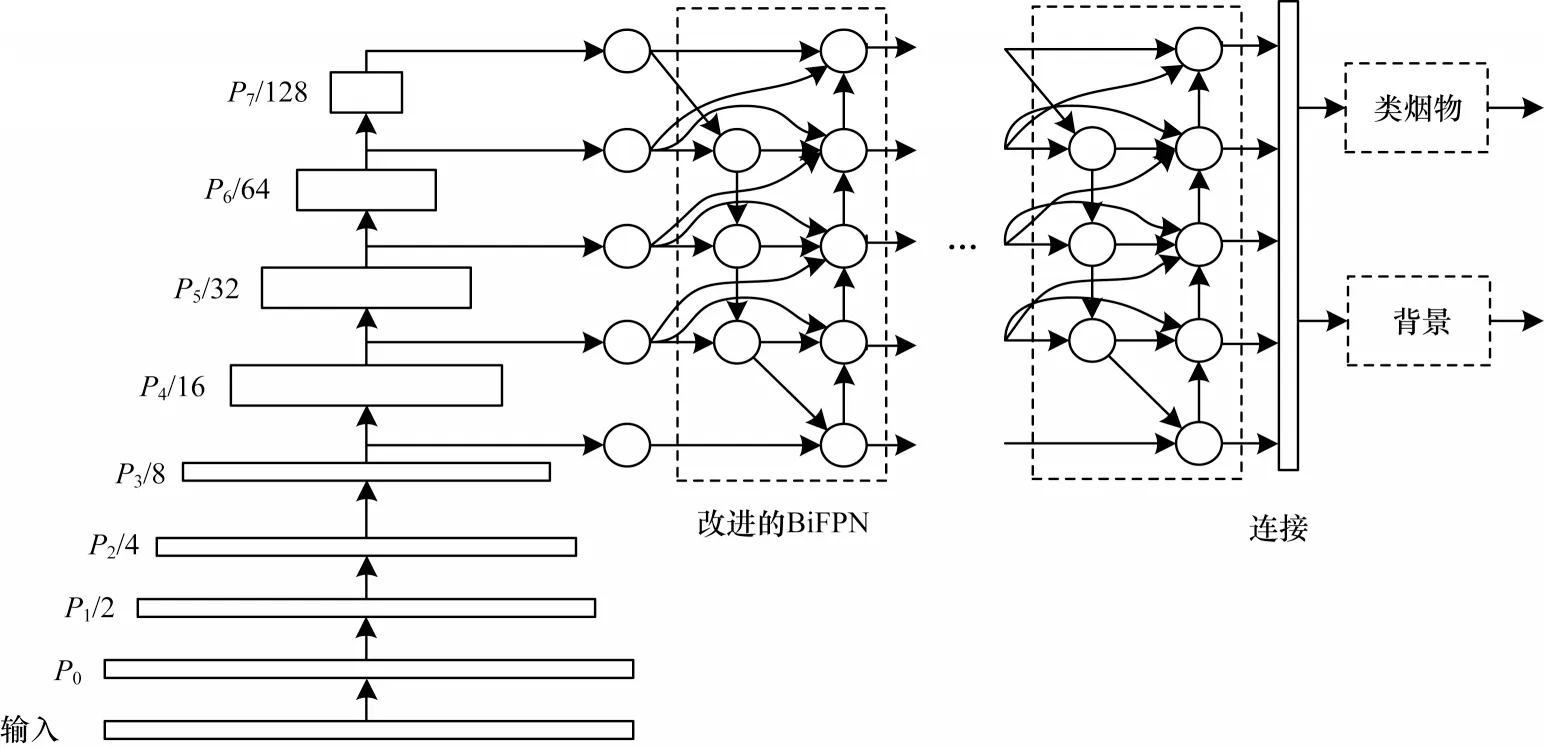
图3 改进的EfficientDet 网络结构Fig.3 Structure of improved EfficientDet network
在实际场景中,本文采集的吸烟图像中香烟目标的相对尺寸为小于0.05 的细小目标对象(相对图像的宽高),从而丢失了较多的空间信息,这种像素级特征的感受野不够大,且物体存在多尺度问题,使得普通的特征提取方式效果较差。为提高特征提取网络的提取能力,本文利用上下不同层级的语义关系和位置信息,增加浅层特征的语义信息,在特征提取时特征提取网络具有足够的上下文信息,同时也包括目标的细节信息。因此,本文在BiFPN 中增加了跨级的数据流,将下层节点特征融合到上层节点进行共同学习,其结构如图4 所示。

图4 特征融合网络结构Fig.4 Structure of feature fusion network
本文利用双向路径(自顶向下和自底向上)进行特征融合,将融合得到的全局特征与原始特征图连接起来,这种改进方法的目的是同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征使学习权重自动加权融合到输入特征,实现多层次、多节点融合学习。该过程称为融合目标的细节特征(浅层特征)和全局特征(深层特征也是上下文语义信息)的过程,由此得到最后的物体上下文特征表示。图4 中Pi表示主干网络中分辨率为输入图像(1/2i)的特征图,从图4 可以看出,高语义特征经过上采样后,其长、宽与对应的浅层特征相同,而改进增加的BiFPN 跨级数据流通道是固定的,因此需要对底层特征进行卷积,使得底层特征输出的通道数与BiFPN 跨级数据流通道相同,然后对两者进行横向连接,得到最终特征图。BiFPN 能够充分利用不同层级的特征图信息,且收集不同尺度的语义信息并对其进行融合,以实现提取细微特征,这种方式得到的不同尺度的信息比全局池化所得的全局信息更具代表性。与特征未融合方法相比,检测到包含香烟目标区域的精确度提升1.4%以上,而计算量仅增加0.25%。主要原因是在未融合之前,特征未融合方法未考虑到各级特征对融合后特征的共享度问题,即之前模型认为各级特征的贡献度相同,而本文考虑到香烟目标的尺寸下降,导致它们分辨率不同。因此,不同香烟目标的分辨率对融合后特征的贡献度不同,在特征融合阶段引入了权重,同时通过双向融合将上下不同层级的语义关系和位置信息进行整合,将上采样后的高语义特征与浅层的定位细节特征进行融合,以达到对多个维度同时放大的目的。
改进的特征融合网络结构BiFPN 通过将双向的跨尺度连接与快速的归一化相融合,并对图像特征进行提取,即将EfficientNet-B0 骨干网络中3~7 层的输出特征结果不断地将自顶向下和自底向上的特征进行融合。图5 所示为单个BiFPN 的流程。

图5 BiFPN 流程Fig.5 BiFPN procedure
对BiFPN 的每层输出进行分析。特征融合网络结构如式(4)所示:


整个特征提取网络是自底向上的前向传播过程,随着下采样次数不断地增加,获得的语义信息随之增多,但位置信息不断减少。虽然更深层次的特征图具有较多的语义信息,但其分辨率较低,原始图像中32×32 像素的物体经过5 次下采样后大小仅1×1 像素,因此更深层次的特征图对小尺寸目标进行检测,其精确度较低。改进的EfficienDet 网络在特征提取过程中充分利用不同层级的特征图信息,并增加前一层级的位置信息,使得在实际场景中香烟目标的检测结果较优。改进的EfficienDet 网络利用FocalLoss 解决正负样本不均匀的问题,由于网络内部具有较多的depthwise conv,因此通过将结果缓存在内存中以及逐点卷积完成后释放内存这2 个步骤,使得EfficienDet 网络准确性优于未改进前的EfficienDet 网络,且FLOPS 和参数量减少一个数量级。本文通过不固定BN 层来进一步提高检测性能,与EfficienDet 网络相比,改进的网络增加了参数量,并且对收敛的速度影响甚微。
1.2.2 局部级检测及分类
局部级模型通过选择其第4 个卷积层融合通道注意力机制,并将物体级筛选出的候选区域聚类成2 类,同时利用聚类方式形成2 个部分检测器。在检测器进行聚类并选择输入的候选区域过程中主要分为4 个步骤:1)修改并整合输入的图片尺寸;2)通过一次前向的传递得到筛选器的激活分数;3)将相同类别筛选器的激活分数相加;4)在每个选择器的相同类别中选择获得分数最高的候选区域,并把这块当作重要块。改进的模型具有更强的特征捕捉能力,在实际场景中能够改进类烟物与香烟的区分效果。局部级检测模型结构如图6 所示。
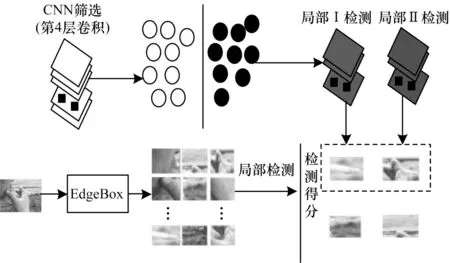
图6 局部级检测模型结构Fig.6 Structure of local level detection model
改进的DomainNet 融合了注意力机制,利用通道注意力卷积块(AC-Block)替换原模型的所有卷积层,学习各个通道间关系以得到不同通道的权重,最后乘以原来的特征图得到最终特征。该方法使模型关注信息量最大的通道特征,而抑制不重要的通道特征。该方法主要分为:1)Squeeze 操作,其通过对特征进行全局平均池化来实现;2)Excitation 操作,池化输出的1×1×C数据经过两级全连接,使用sigmoid 函数将值限制在[0,1]范围内,并将得到的值分别乘到C个通道上,作为下级的输入数据。AC-Block 卷积块结构如图7所示。
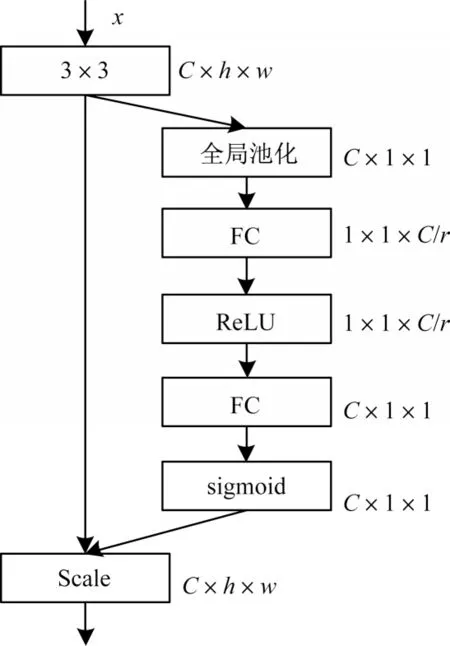
图7 AC-Block 结构Fig.7 AC-Block structure
由于物体级和局部级接受的块不同,因此其功能和优势各不同。物体级筛选器为局部级检测器提供了选择的候选区域并进行前馈,为获得图像的预测标签,通过计算所有候选区域输出的平均分类分布以得到平均的预测标签。局部级分类器仅对包含判别力的局部特征进行处理。尽管有的块被两个分类器同时使用,但是它们代表不同的特征,能够潜在的互补。从图6 可以看出,在局部检测后得到的两组区域,一组是香烟目标,另一组是背景噪声。
物体级选择器选择关注整个对象的多个视图,这些候选区域驱动了细粒度的局部级模块——局部级检测器。局部级检测器通过选择并处理包含区分特征和局部特征的候选区域,使Alex 网络的第4 层卷积层形成2 个聚类检测器,以生成候选区域块的激活分数。此外,物体级选择器通过对香烟目标进行定位,以完成前述算法的物体与局部区域检测工作。局部级检测器对检测到的香烟目标位置进行特征提取。通过物体级选择器和局部级检测器相互协调,完成了对细粒度香烟目标分类过程中物体、局部区域的检测与特征提取工作。以往文献是将卷积网络作为特征提取器,并未从整体上考虑效果,然而本文从整体上使用全局和局部信息对细粒度级别进行分类,在不借助数据集部分标注的情况下,完全依赖于物体级别和局部级别信息,具有较优的局部信息捕捉能力。最后,本文将2 种注意力集中方法的预测结果进行合并,以结合两者的优势。即使2 个分类器都接受了某些候选区域,但这些候选区域的特征在每个分类中都有不同的表示形式,但具有互补的信息。
本文将两个模型的结果相结合,通过最终的分值来判定是香烟目标还是类烟物,如式(7)所示:
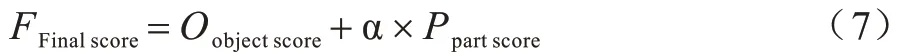
其中:Oobjectscore为多个patch 的均值;Ppartscore为局部分类产生的决策值;α为通过实验确定取值,在本文中,经过实验论证α过小会导致物体级分类影响过大,使得模型泛化能力差,难以区分香烟目标与类烟物,而α 过大则会导致局部检测器权值过高,整个模型呈现过拟合状态,所以将其设置为0.5。
2 实验环境与数据集
本文实验的平台系统是Ubuntu 18.04,图形处理单元(GPU)是NVIDIA GTX 1080Ti,主要为python3.7+numpy1.18.1+torchvision0.5.0+pytorch1.4.0+pycocotools+opencv3.4.2,优化器为Adam,其中衰减系数分别为0.9和0.999。模型训练输入图像的像素为512×512,batch_size 都为12,模型迭代次数设为300,学习率设置为10-4。
本文算法虽然属于弱监督吸烟行为识别,所需的样本无需目标级别的标注,但无论是在前期的特征分析还是之后的实验论证都需要数据集支撑,由于吸烟行为识别的研究还不太成熟,没有类似于其他动作识别的标准数据集。为此,本文构建了吸烟行为检测数据集BUU-Smoke,并在该数据集上进行测试。BUU-Smoke 数据集(19 816 张图片)是一个具有挑战性的吸烟动作检测数据集。本文数据集在办公楼下、街边等5 个摄像头下采集数据,拍摄于白天,光照条件良好,数据集像素主要为512×512 和640×640,其中包含4 881 张通过网上获得、视频截图的影视图片以及14 935 张包含生活、工作、街头等场景采集的真实图像数据,实景采集的每张图中至少有3 人存在吸烟行为。其中包括吸烟数据、手拿类烟物数据以及正常无目标数据片段,为确保数据与实际场景符合,数据集的比例根据统计的中国30%的吸烟率[17]来设计,吸烟∶非吸烟比例为3∶7,其非吸烟数据中,手拿类烟物与正常无目标的比例也为3∶7,为确保检测算法的适用性,数据片段的背景涉及到各个生活场景。由于数据采集的环境不同,光照明暗以及设备的性能优劣等,手动采集的数据存在对比度低、有噪声等缺点。本文在模型训练前,对数据集进行了图像增强、灰度取值范围相同、大小归一化等预处理。数据集样例如图8 所示。基线方法在此数据集上的效果只有15.5%,表明本数据集具有一定的研究意义和学术价值。

图8 数据集样例Fig.8 Sample data set
3 实验结果与分析
本文通过对比实验和消融实验对算法的性能进行评估和分析,
3.1 评价指标
本文实验采用损失函数(Loss)、时间度、准确率(P)、召回率(R)和mmAP值作为主要评价指标,如式(8)所示:

其中:TTP表示对象为正例,识别为正例;FFP表示对象为负例,识别为正例;FFN表示对象为正例,识别为负例;QR为测试集个数;AAP为平均精度。
3.2 对比实验1
为评估本文算法在吸烟行为检测中的性能,本文在香烟烟雾识别、吸烟手势识别、香烟识别这3 种主要的吸烟行为识别方式中,分别选取最具代表性的算法进行对比。为保证结果公平,所选取的算法均在本实验平台进行重新训练,除本文算法以外,其他算法均采用有预训练模型的迁移学习进行训练。为模拟真实吸烟场景,以保证实验的可靠性,本文共进行10 次测验,根据文献[17]中研究的3∶7 的吸烟人数选取每次测验数据量,随机选取70 个非吸烟场景,30 个类似吸烟场景,其中类似吸烟场景包括25 个真实吸烟场景和5 个手拿类烟物场景,最终评判结果取每次测验结果的平均值。
在BUU-Smoke 数据集上对不同模型的性能指标进行对比,从表1 可以看出,整个10 次测试实验数据,文献[4]、文献[5]和文献[8]模型的mmAP相对最低,都在83%以下,但其误检率达到12%以上,且测试结果不稳定。文献[7]、文献[10]和文献[11]模型的时间消耗均较短,误检率均在10%及以下,而且在所有算法中文献[10]的召回率最优,表明文献[10]在检测吸烟行为上的性能较优,但是模型mmAP仅在88%左右。文献[9]采用多模型级联检测来解决单特征检测准确率低的问题,因此其mmAP达到91.6%,但是文献[9]采用的模型参数较大,在所有算法中时间度上的表现最差,且误检率也不是很理想,难以在实际场景中有好的表现。与其他算法相比,本文模型在检测过程中的mmAP和误检率均性能较优,其值分别为93.1%和3.6%,时间度和召回率方面虽然不是最优,但接近于最优算法的指标。因此,本文模型能够有效地识别吸烟行为,具有较优的精确度和鲁棒性。

表1 在BUU-Smoke 数据集上不同算法的指标对比Table 1 Indexs comparison among different algorithms on BUU-Smoke data set
不同算法的loss 值对比如图9 所示,从图9 可以看出,相比其他算法,本文算法的loss 不论是收敛值还是曲线平滑程度都具有明显的优势。

图9 不同算法的loss 值对比Fig.9 Comparison of loss values among different algorithms
3.3 对比实验2
对比实验Ⅰ评估了算法在吸烟行为识别的性能,与其他吸烟算法相比,本文算法具有较优的准确度和误检率。由于本文研究还涉及细粒度方向,对比实验Ⅱ主要评估算法分辨类烟物与香烟的性能,采用测试集数据总数为100 张,其中香烟目标场景与类烟物场景比例为1∶1。细粒度与粗粒度算法的实验结果对比如表2 所示。本文分别选取粗粒度与细粒度最具代表性的算法与本文所提算法进行对比,选 取Faster RCNN[18]、SSD[19]、RetinaNet[20]、EfficientDet-D4[13]作为粗粒度算法,选取MAMC[21]、MVC[22]、DFL-CNN[23]作为细粒度算法,所有算法均采用预训练模型的迁移学习进行训练,由于本文实验受硬件性能限制,即使将训练过程中的批大小降为最小的1,硬件性能仍然达不到训练EfficientDet系列的最优算法D7 的程度,所以采用EfficienDet-D4 进行对比实验。

表2 粗粒度与细粒度算法的实验结果对比Table 2 Experimental results comparison of coarse-grained and fine-grained algorithms
从表2 可以看出,Faster-RCNN 和SSD 两个算法主要是评估特征金字塔网络中受语义多尺度特征的影响。EfficientDet 作为目前性能较优的目标检测器,其D4 模型的mmAP为89.8%,虽然在粗粒度的模型中效果最好,但是相较于细粒度模型较差。主要原因可能是批大小只有1,在训练过程中损失值下降不平滑且波动性大,而难以收敛。从综合结果分析可知,粗粒度模型的准确度相较于细粒度较低,说明在识别类烟物与香烟目标时,使用细粒度的模型能够识别并提取更细微的特征。虽然文献[21-23]的模型准确度高于其他模型,但由于数据集的针对性,本文算法在这次试验中mmAP达到93.9%,高于其他算法2.7%以上,并且本文算法在时间度上明显快于这3 类细粒度算法。因此,本文算法在粗、细粒度的模型对比实验中表现优异,具有较优的准确性与实时性。
3.4 消融实验
本文设置了一组消融实验,以全面评估本文所提算法的性能,将算法进行部分剥离,从而评判模型部分的缺失对整体效果的影响。
消融实验描述如表3 所示,本文消融实验分为5 个部分:1)算法1 仅使用网络中的目标检测网络EfficientDet-D0;2)算法2 仅使用细粒度两级注意力模型;3)算法3 使用整个网络,但是将候选区域提取算法进行替换;4)算法4 是去除模型中添加的通道注意力卷积块(AC-Block);5)本文算法。

表3 消融实验描述Table 3 Description of ablation experiment
消融实验结果如表4 所示,仅使用粗粒度或者细粒度模型的算法1 和算法2 的mmAP较低,本文算法相较于算法2 提高了3.3 个百分点。从实验1 可知,细粒度两级注意力模块对mmAP影响最大,说明在吸烟行为上细粒度网络比粗粒度网络的识别性能更优。本文对比5 个模型在速度上的差异,细粒度网络模型由于参数多,速度较慢,而本文的算法虽然速度并不是最快的,但是经过缩减参数等轻量化设计,具有较好的实时性。实验3、4 的对比也验证了通道注意力机制能够提高准确度。本次消融实验深度剖析了算法内部结构对性能的影响,说明本文模型设计的合理性。

表4 消融实验结果Table 4 Results of ablation experiment
4 结束语
本文提出一种基于弱监督细粒度结构与改进EfficientDet 网络的吸烟行为检测算法,用于解决真实场景下吸烟行为识别过程中目标细小检测效果差的问题。通过改进EfficientDet 网络中的BiFPN 结构,将下层节点特征融合到上层节点并共同学习,利用上下不同层级的语义关系和位置信息增加跨级的数据流,实现多层次、多节点的融合学习。此外,在DomainNet 网络结构中融入基于通道注意力机制的卷积块(AC-Block),使模型提取到信息量最大的通道特征。实验结果表明,本文算法的吸烟行为识别准确率为93.1%,并具有较优的鲁棒性和泛化能力。后续将扩展识别场景,使模型优化为具有普适性的复杂动作识别架构,以适应更复杂的场景。
猜你喜欢
红外技术(2022年11期)2022-11-25
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
文史博览(2020年1期)2020-11-30
爱你(2020年22期)2020-11-19
安阳工学院学报(2020年2期)2020-06-05
文史博览·文史(2020年1期)2020-03-12
当代陕西(2019年10期)2019-06-03
小猕猴学习画刊(2018年10期)2018-11-23
现代电子技术(2018年1期)2018-01-20
