
混凝土坝变形监测缺失数据处理新方法
2022-03-14 12:01黄成章顾冲时
水利水电科技进展 2022年2期
黄成章,顾冲时,何 菁
(1.河海大学水利水电学院,江苏 南京 210098; 2.南京市水利建筑工程检测中心有限公司,江苏 南京 210036)
混凝土坝运行过程中不仅受到各种荷载作用,还受到各种非荷载因素的影响。混凝土坝的服役安全性态是一个在多因素协同作用下的材料和结构互相影响的非线性动态演化过程,变形作为一个可以直观反映混凝土坝安全状态的综合效应量,是大坝结构性态发生趋势性变化乃至转异的一项重要指标[1],因此,对于混凝土坝变形的监测尤为重要。然而,由于大坝监测仪器发生故障或者大坝自动化监测系统不稳定等原因,可能导致部分监测点存在监测数据缺失的现象,会影响大坝安全监测及评价的效果[2],因此,研究在监测仪器故障情况下的不完整信息处理方法具有现实意义。目前较为常见的处理方法有加权平均法[3]、贝叶斯估计法[4]、卡尔曼滤波法[5]、递归加权最小平方法、极大似然估计法[6]等,但这些方法均以单个测点作为对象进行插值处理,忽略了测点所处位置及各测点之间的相互联系,影响了处理缺失数据的精度和有效性。
实际上,混凝土坝所有测点的变形序列既包含了时间维度上的变形信息,也包含了横截面维度上的变形信息,如果仅仅从单一的时间序列或者截面序列来分析大坝变形信息,会难以全面有效地了解大坝的整体变形状态。随着时空数据挖掘技术的不断进步[7-13],与时间或空间相关的模型得到进一步发展[14-16]。例如:顾冲时等[17]通过引入测点位置坐标作为大坝变形的影响因子,建立了大坝时空分布模型;李广春等[18]通过考虑各测点间的空间相关性,建立了重力坝变形时空自回归模型。
本文基于聚类和面板数据理论,提出了一种考虑时间和截面两种维度的混凝土坝变形监测缺失数据处理方法,旨在弥补传统方法未考虑测点间相关性和非荷载因素影响而带来的处理缺失数据精度不高的缺陷。
1 测点监测效应量相似性判据及其聚类
1.1 相似性判据
聚类的含义是按照一定的标准和指标将需要处理的数据集分成不同的组,称之为簇,经聚类后,同一个簇内的数据具有较大的相似性,而不同簇内的数据则具有较大的差异性,通过聚类使得在同一区域内的混凝土坝变形规律相似程度尽可能地“接近”,而不同区域之间的变形规律相似程度尽可能地“远离”。本文在分析混凝土坝变形监测值时以欧氏距离来[19]刻画这种相似性,以此来对测点进行分区。在对变形监测数据预处理时,设{δit|i=1,2,…,N;t=1,2,…,T}(N为混凝土坝监测点的总数,T为监测时期总数)为混凝土坝变形监测数据集,即监测时间序列,采用绝对距离和增速距离[20]刻画各监测点的测值相似性。绝对距离是指不同测点在整个监测时期距离的远近程度,增速距离是指不同测点的变形增量随时间变化的趋势差异,计算公式分别为
(1)
(2)
其中 Δδit=δit-δi(t-1)Δδjt=δjt-δj(t-1)
式中:dij1、dij2分别为测点i与测点j之间的绝对距离和增速距离;δit、δi(t-1)、δjt、δj(t-1)分别为t与t-1时刻测点i、j处的变形量;Δδit、Δδjt分别为t与t-1时刻测点i、j处变形量差值。
从式(2)可以看出,若测点i与测点j的变形值随时间呈现同向变化的趋势,且这种变化越协调,那么这两者也就越相似,dij2也就越小;反之则相似性较差,dij2越大,这也符合相似性度量的基本原则。为了能够更好地刻画各测点变形的相似性,构建测点i、j之间的综合距离dij3:
dij3=w1dij1+w2dij2
(3)
式中w1、w2分别为绝对距离和增速距离的权重,w1+w2=1。
在信息论中,熵是对不确定性的一种度量,信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性越大,熵也越大。本文基于熵权法来判断混凝土坝变形变化随机性及无序程度,进而用于判断反映变形变化特性的某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大,据此确定绝对距离和增速距离的权重。假设有m个评价对象,n个评价指标,xab为评价对象b(b=1,2,…,m)在评价指标a(a=1,2,…,n)下的评价值。本文以变形量的绝对距离和增速距离作为评价指标,测点两两间的距离作为评价对象。熵权法赋权步骤如下(由于各项指标的计量单位统一,故不需要进行指标的归一化处理):
步骤1计算评价指标a下评价对象b评价值占该指标评价值的比重pab:
(4)
步骤2计算评价指标a的熵值ea:
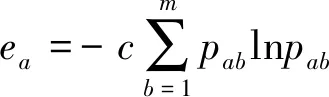
(5)
其中c=1/lnm
步骤3计算评价指标a的信息熵冗余度(差异)da:
da=1-ea
(6)
步骤4计算评价指标a的权重wa:
(7)
在n=2时,求得w1与w2代入式(3)即可得到不同测点之间的综合距离,由此构建所需的相似性判据。
1.2 监测效应量聚类
采用离差平方和法对混凝土坝变形各测点监测效应量进行聚类。假设将混凝土坝N个测点划分为k个区域,记为G1、G2、…、Gk,记Nl为Gl(l=1,2,…,k)类中测点的个数,Xil为Gl类中测点i(i=1,2,…,Nl)处的变形值,那么混凝土坝Gl区域在T个时期内各测点序列的离差平方和为
(8)
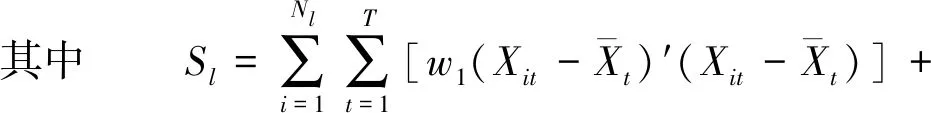
式中:Sl为Nl个测值的总离差平方和;S为k个区域总的离差平方和;Xit为t时刻测点i处变形值;Yit为Gl区域中t时刻测点i处变形相对增量。
通常情况下,要得到分区的最优解,需要选择使得S取得最小值的方案。在实际工程中,由于混凝土坝结构的复杂性,往往难以求得一个最优分区数。因此,本文假设在聚类过程中,共进行了p次合并,求得第l次与第p次合并的区域间距离之比Rl,即Rl=Dl/Dp,其中Dl、Dp分别为第l次与第p次合并的区域间距离。如果Rl与Rl+1相差较小,但Rl与Rl-1却相差较大,那么就可以将第l次合并后得到的区域间距离Dl作为变形分区的一个阈值,进而得到混凝土坝变形分区数量[21]。构建混凝土坝变形分区的步骤如下:
步骤1由式(1)、式(2)分别计算混凝土坝变形的绝对距离和增速距离。
步骤2采用熵权法计算两种距离的权重。
步骤3将计算得到的权重代入式(3)得到不同测点之间的综合距离以及各区域之间的距离矩阵D0。
步骤4初始将N个测点分为N个区域,区域个数k=N,令D1=D0。
步骤5计算区域间的距离矩阵Di-1,根据离差平方和最小准则,将综合距离最小的两个区域合并,组成一个新的区域。
步骤6计算新的区域与其他区域的综合距离,进而得到新的距离矩阵Di。,不断重复步骤5和步骤6,直到所有的测点全部被划分到相应区域为止。
步骤7根据阈值确定变形的最优分区数,得到混凝土坝变形最优分区数K。
步骤8利用谱系聚类树状图画出混凝土坝变形分区分布图。
为得到存在缺失数据的混凝土坝变形分区,根据坝体各部位随时间变化变形趋势的一致性,取各测点变形监测数据完整时间段的监测效应量进行聚类分区即可。
混凝土坝变形分区的具体流程见图1。
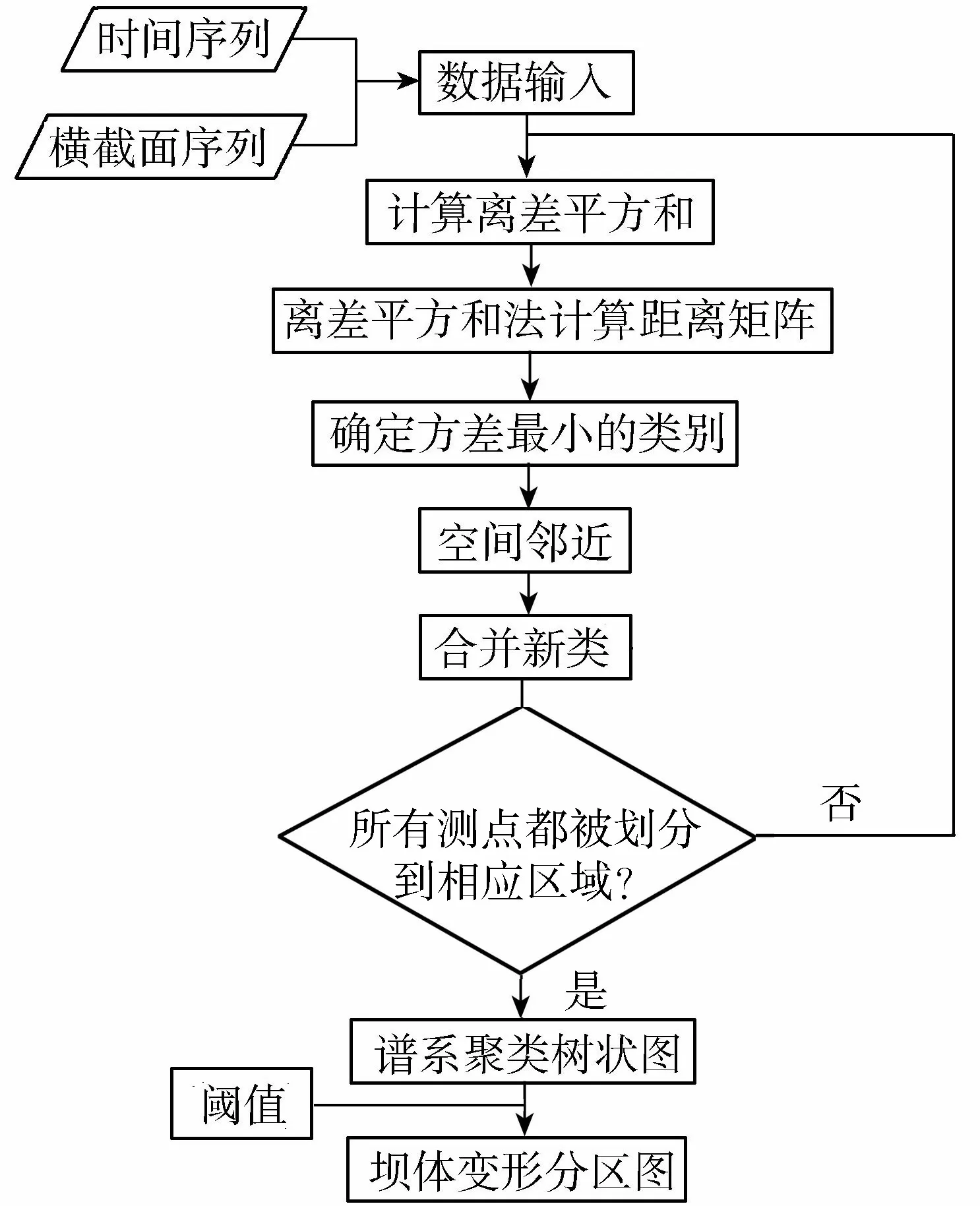
图1 混凝土坝变形分区流程
2 混凝土坝变形面板数据随机系数模型的建模方法
为了对混凝土坝变形监测缺失数据进行处理,需建立表征混凝土坝变形规律的分析模型,本文基于面板数据理论构建大坝变形变化规律分析模型。
2.1 面板数据随机系数模型的表达形式
面板数据随机系数模型的一般表达式为
(i=1,2,…,N;t=1,2,…,T)
(9)
式中:βi为随机系数;Yit为混凝土坝i个测点因变量变形面板数据序列;uit为均值为0、方差为σ2,并且满足独立同分布的随机误差成分;yit为测点i在t时刻的变形监测值;Xit为混凝土坝i个测点自变量变形面板数据序列。自变量Xit中的元素为xit,xit=(1,Ht,1,Ht,2,Ht,3,Ht,4,T1,t,T2,t,…,Tm,t,θt,lnθt)T,其中,Ht,1,Ht,2,Ht,3,Ht,4为变形监测数据的水压分量影响因素,T1,t、T2,t、…、Tm,t为温度分量影响因素,θt和lnθt均为时效分量影响因素。
由于混凝土坝在运行过程中会受到各种随机因素的影响(如约束条件、荷载作用、材料性质等),且不同部位的变形受到的影响存在较大差异,故模型中还应考虑这些因素对混凝土坝不同测点处所产生的异质性影响。由于这些影响因素无法明确地在模型自变量中表示,故采用特异效应量αi来代表这些个体特异效应。当βi被看作是随机系数时,假设βi=β+αi,将参数分解成两部分,一部分为固定常数,另一部分为混凝土坝不同测点变形的随机效应量。假定在不同横截面个体之间的协方差为零,对角线元素的乘积为对应的方差,且随机系数在不同的横截面个体之间的协方差也为零,则对于第i个横截面单元,可以得到Yi=Xiβi+ui。
对于随机系数回归模型,采用普通最小二乘法估计将会导致无法估计以及错误的统计结果,可采用广义最小二乘法(GLS)估计来解决上述问题[21],进而得到βi的渐进正态和有效估计量。
2.2 变形监测缺失数据处理步骤
实际工程中,混凝土坝变形监测中出现的数据缺失现象一般有两种情况:一是在某时间段存在一个或多个测点测值缺失,一是在某时间段全部测点测值缺失。对于这两种情况,均可采用前文聚类、建模方法对变形监测缺失数据进行处理。对于第一种情况的处理步骤如下:
步骤1利用监测数据完整的时间段部分(缺失数据之前或之后部分)的监测值,对混凝土坝各测点监测效应量进行聚类分区,使变形规律相似、对荷载具有同质响应的部位被归为一类,将传统的点分析方法转变为区域分析方法,在较大程度上避免仅仅考虑坝体局部变形而造成的偏误性判断。
步骤2对于同一区域内测点缺失数据之前部分以及之后部分分别建立面板数据随机系数模型,引入特异效应量αi来代表个体特异效应,以提高模型的可靠性和有效性。
步骤3基于缺失数据前后两部分数据建立的模型,分别得到各测点缺失部分数据的拟合值,取两拟合值的平均值对大坝变形监测缺失数据进行填补。
步骤4对比监测数据完整测点处对应缺失数据点时段的监测值与模型计算值,验证处理方法的准确性与有效性。
第二种情况处理步骤和第一种情况基本相同,仅步骤4改为:利用位于缺失数据之前或之后部分的连续完整时间段的监测值,人为删除部分监测值数据,重复步骤2、3,验证填补值的准确性与有效性。
2.3 评估指标
为衡量混凝土坝变形监测缺失数据填补的有效性,本文将处理后得到的残差与SL 601—2013《混凝土坝安全监测技术规范》中所规定的拱坝坝体径向位移量误差限值(±2 mm)进行比较,若在误差限值之内,则说明填补数据有效。
3 实例验证
某混凝土双曲拱坝坝顶高程1 885.0 m,建基面最低高程1 580.0 m,最大坝高305 m,拱冠梁顶厚16 m、底厚63 m,最大中心角93.12°,顶拱中心线弧长552.23 m,厚高比0.207,弧高比1.811,柔度系数7.99,坝体混凝土方量476万m3。以布设于大坝11号、13号、16号坝段,高程分别为1 885.00 m、1 829.25 m、1 778.25 m、1 730.25 m和1 664.25 m的15个正垂监测点为研究对象,变形监测序列为2017年12月24日至2018年12月31日的测值,测点编号见表1。

表1 混凝土坝变形测点编号
3.1 某时间段单个测点测值缺失处理及有效性分析
11号坝段PL11-3测点在2018年1月31日至3月22日变形监测数据缺失,采用本文方法对缺失数据进行处理。先对各测点变形监测量进行聚类分区,得到谱系聚类树状图。通过内部有效性指标的多次评估,经过试错迭代并结合最优分区阈值,确定混凝土坝变形分区的最佳区域数,最终将所有测点划分为三大类,如图2所示。经分析区域内的测点变形变化趋势及规律基本一致,可以描述坝体对应区域的总体变形特征。
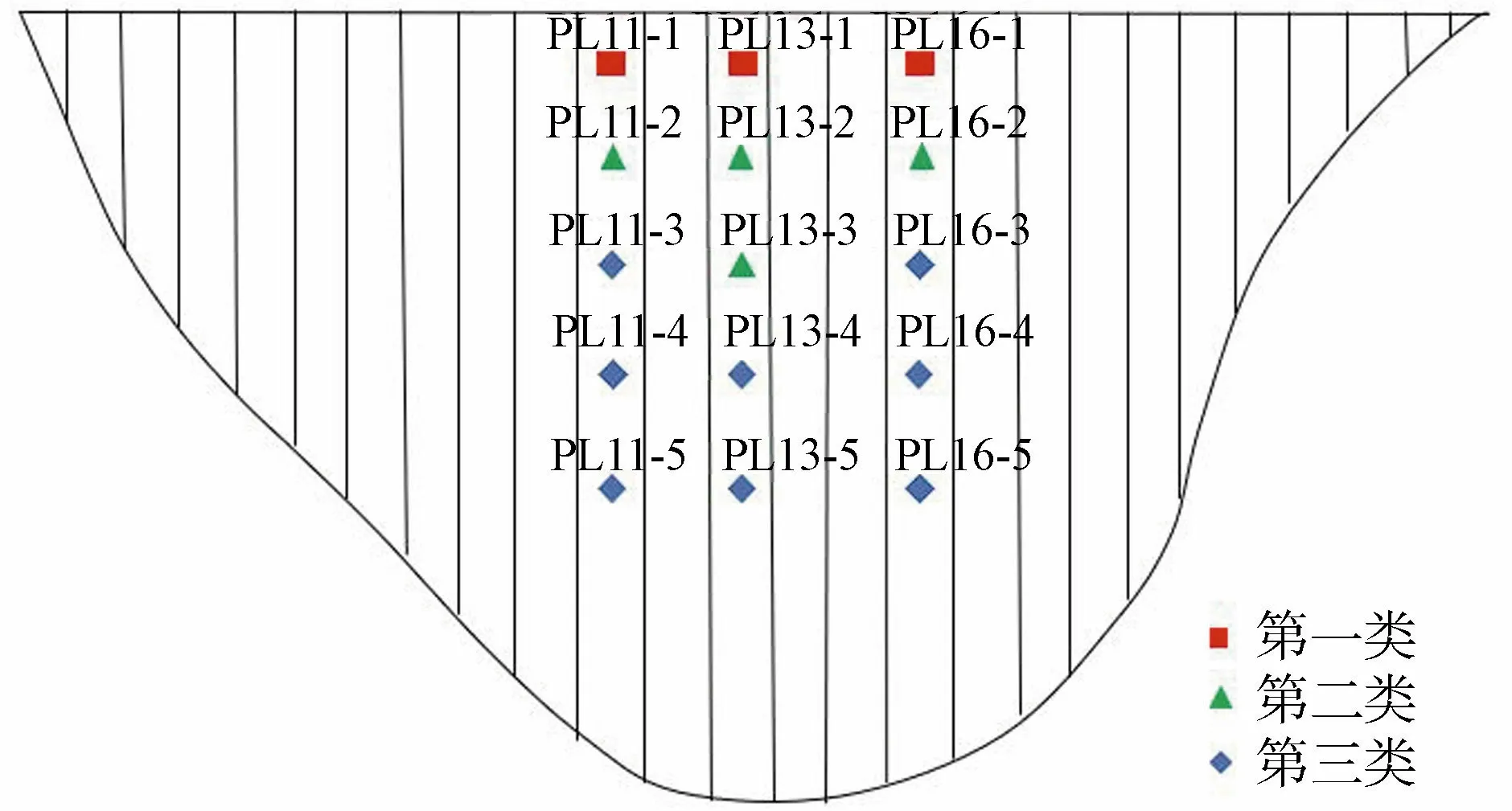
图2 混凝土坝变形分区分布
在PL11-3测点所处的区域(第三类)中,对缺失数据前后两个时间段各测点变形监测效应量采用面板数据随机系数模型进行建模分析,分别得到缺失数据的模型计算值,取其平均值作为最终缺失数据处理结果。
为了验证处理方法的有效性,基于所建立的面板数据随机系数模型,针对具有完整实测数据的测点PL13-5、PL16-5,计算得到对应测点PL11-3缺失数据时段处PL13-5与PL16-5两个测点处的变形值,其残差如图3所示,可以看出,填补数据残差绝对值均远小于2 mm,都在误差限值之内,可见填补数据具有较高的精度。同时将面板数据随机系数模型拟合值与三次样条插值作对比,结果见图4。由图4可见,面板数据随机系数模型拟合值具有更高的可靠性与有效性,面板数据随机系数模型对于缺失数据处理具有较好的效果,得到的测点PL11-3全时段监测值(含原缺失数据处理后得到的填补值)过程线见图5。

图3 测点PL13-5和PL16-5变形量残差

图4 测点PL13-5变形量过程线对比

图5 测点PL11-3全时段变形监测值过程线
3.2 某时间段全部测点测值缺失处理效果分析
为检验在某时间段全部测点测值缺失情况下本文方法的有效性,现假设所有测点2018年1月31日至3月22日变形监测数据全部缺失,通过对缺失数据之后时间段的监测数据进行处理来验证方法的有效性。首先对各测点变形监测效应量进行聚类分区,此处选取图2中PL11-3所在区域验证缺失数据处理的有效性;其次选择缺失数据之后部分(或之前部分)时间段的测点测值进行有效性检验。具体处理步骤如下:
步骤1假设2018年8月21日至10月10日变形监测数据缺失,利用对缺失数据前后两个时间段各个测点监测数据,分别建立面板数据随机系数模型,据此分别计算得到相应的模型计算值,取两部分对应缺失数据时段的模型计算值的平均值作为填补的变形监测值。
步骤 2计算得到各时间点的残差值,判断是否在误差限值(±2 mm)以内。
步骤 3对2018年1月31日至3月22日前后时间段的监测值分别进行建模分析,处理得到有效的变形监测数据填补值。
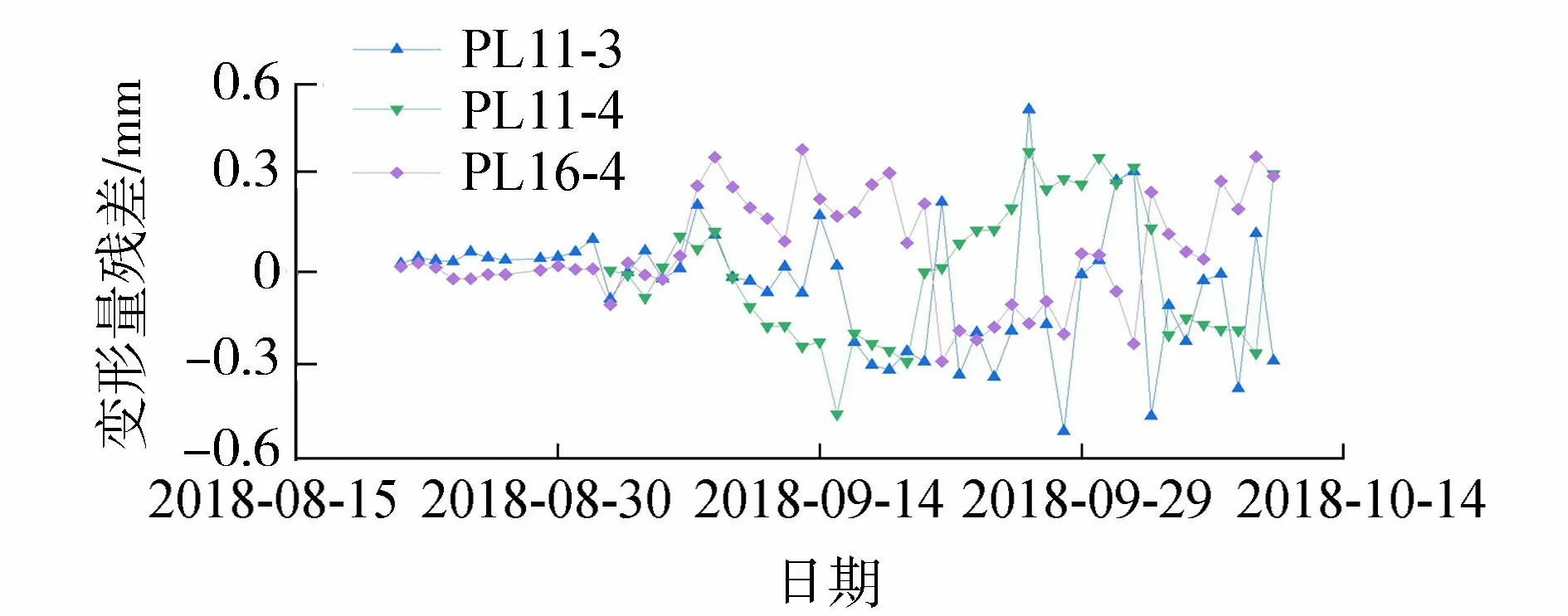
图6 典型测点变形量残差
图6为典型测点处变形量残差,可以看出填补数据均在误差限值之内,因此,在某时间段全部测点测值缺失的情况下,本文方法也具有较高的精度。
4 结 语
本文研究了混凝土坝变形各监测效应量相似性判据构建技术,给出了基于熵权法判别大坝变形相似性的指标及各指标的赋权方法,并依据监测数据离差平方和最小原理,提出了混凝土坝变形各测点监测效应量聚类方法。综合考虑同一聚类分区测点间变形监测效应量的相关性和非荷载因素的影响,提出了基于面板数据理论的混凝土坝变形监测缺失数据的处理方法,弥补了传统方法的不足,并通过工程实例验证了方法的有效性,可应用于混凝土坝变形监测缺失数据的处理。
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
制造技术与机床(2022年2期)2022-02-22
汽车实用技术(2021年10期)2021-06-04
世界科学技术-中医药现代化(2021年10期)2021-03-02
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
人间(2015年11期)2016-01-09
制导与引信(2015年1期)2015-04-20
