
基于惩罚绝对偏差的函数型部分线性模型稳健变量选择
2022-04-19 10:30赵培信黄海霞
四川文理学院学报 2022年2期
吴 昊,赵培信*,2,黄海霞
(1.重庆工商大学 数学与统计学院;2.经济社会应用统计重庆市重点实验室,重庆 南岸 400067)
0 引 言
随着科学技术的发展和数据采集技术的提高,在生物医学、环境工程等领域常常出现以函数曲线形式的函数型数据.关于函数型数据的统计推断越来越受到关注,并且已有大量文献进行研究.Yao等[1]研究了函数型线性模型的估计方法,Müller和Stadtmüller[2]研究了函数型广义线性模型的估计问题,Sentürk和Müller[3]研究了函数型变系数模型的估计问题.关于函数型部分线性模型的统计推断问题,Shin[4]对模型的参数提出了一种估计方法,Lu等[5]则推广了文献[4]的估计方法,并提出了一种分位数回归方法.另外,Kong等[6]则利用惩罚最小二乘方法研究了函数型部分线性模型的变量选择问题.
注意到在统计建模过程中,如果忽略某些重要变量或者引入过多的冗余变量都会导致估计和预测的精度下降,因此变量选择问题是统计建模过程的一个重要组成部分.尽管Kong等[6]研究了函数型部分线性模型的变量选择问题,但其所用的惩罚最小二乘方法对异常点较敏感,各别异常值则会带来较大的估计偏差,从而影响变量选择的精度.为此,本文对函数型部分线性模型的变量选择问题,提出了一种基于惩罚绝对偏差的变量选择方法,并且模拟结果表明该方法具有较好的稳健性.
1 基于惩罚绝对偏差的变量选择过程
记X(t)为来自半度量函数型空间(H,d)的函数型协变量,Z=(Z1,…,Zp)T为来自p维欧氏空间Rp的p维协变量,Y为对应的响应变量,那么函数型部分线性模型具有如下结构:
(1)
其中β=(β1,...,βp)T为未知参数向量,m(·)表示H→R的一个光滑算子,ε为模型误差,且满足E(ε|Z,X(t))=0.对模型(1)两边在给定X(t)的条件下取条件期望得:
E(Y|X(t))=E(Z|X(t))Tβ+m(X(t))
(2)
结合(1)和(2)式可得
Y-E(Y|X(t))=(Z-E(Z|X(t)))Tβ+ε
(3)
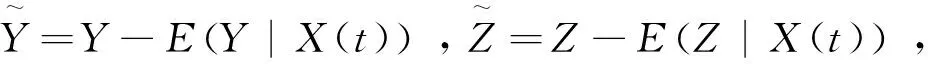
(4)

其中K(·)是核函数,h是带宽,d(·,·)表示半度量空间?上的半度量距离.进而E(Y|X(t))和E(Z|X(t))的非参数核估计可定义为
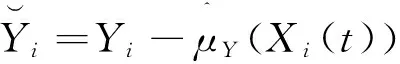
(5)

(6)
注意到目标函数Q(β)关于β在0点不可导,经典的梯度方法不能用于目标函数Q(β)的求解.为此,接下来我们讨论最小化目标函数Q(β)的计算方法.结合Zou和Li[10]提出的线性逼近方法,(6)式中的惩罚函数pλ(|βk|)可以渐近表示为
(7)
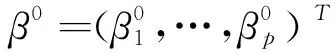
(8)
其中ξk=(0,…,1,…0)T为第k个元素为1,其他元素均为0的p维单位向量.那么(8)式可写为
(9)
注意到(9)式为经典的最小一乘估计目标函数,因此可以通过已有的统计软件(如R软件、SPSS软件等)进行求解.另外在求解(9)式的过程中,调整参数λ需要指定,并且参数向量β需要给出一个初始估计.首先我们可以通过最小化如下不带惩罚项的绝对偏差目标函数来得到β的一个初始估计
(10)
另外类似Wang等[11],本文通过最小化如下BIC准则函数来得到λ的估计.

2 数值模拟研究
为实施模拟,我们从如下模型产生数据
(11)
其中β=(2,1,0.5,0,…,0)T为10维参数向量,对应的协变量Zk~N(1,1.5),k=1,…,10.由β的前三个元素非零,其他元素均为零可知Z1,Z2和Z3为三个重要的协变量,而Z4,…,Z10均为不重要的协变量.非参数算子m(x(t))取为
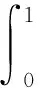
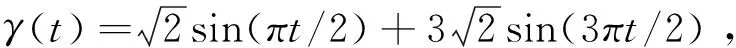
关于重要协变量的变量选择模拟结果见表1和表2,其中“C”表示基于1000次重复实验把真实不重要协变量正确估计为不重要协变变量的平均个数,“I”表示基于1000次重复实验把真正重要协变变量错误估计为不重要协变量的平均个数.另外,表1和表2还给出了选择重要协变量的错误选择率(FSR),其定义为FSR=IN/TN,其中IN表示基于1000次重复实验把不重要协变量估计为重要协变量的平均个数,TN表示基于1000次重复实验所有选择为重要协变量的平均个数.由表1和表2,我们可以得到如下结论:
(1)随着样本量n的增加,基于三种惩罚方法的重要协变量错误识别率均逐渐趋于0,并且对不重要协变量的识别也逐渐趋于不重要协变量的实际个数7.这表明本文提出的重要协变量的选择方法是行之有效的.
(2)对任意给定的样本量n,在不同异常值数量下的模拟结果是类似的,即异常值对模拟结果没有明显的影响.这表明本文提出的变量选择方法具有较好的稳健性.
(3)当样本量较小时,基于Adaptive- Lasso和SCAD给出的模拟结果优于基于Lasso给出的模拟结果.但当样本量增大时,基于三种惩罚方法给出的模拟结果是类似的.

表1 异常值占5%时,基于不同惩罚函数的变量选择模拟结果

表2 异常值占10%时,基于不同惩罚函数的变量选择模拟结果
接下来我们给出关于模型参数β估计精度的模拟结果.注意到在任意给定的样本量下,基于不同的惩罚函数识别重要协变量的模拟结果是类似的.因此在接下来的模拟过程中,我们用Lasso惩罚选择重要协变量.另外作为比较,我们还给出了关于β的惩罚最小二乘估计模拟结果,即通过最小化如下带惩罚项的最小二乘目标函数QLS(β)来得到β的估计.

图1 异常值占5%时,模型参数β估计量GMSE的箱线图
基于1000次重复实验,图1和图2给出了GMSE在各种样本量情况下的箱线图(Box-plot),其中LAD表示本文提出的基于惩罚绝对偏差估计方法所给出的模拟结果,LS表示基于惩罚最小二乘估计方法所给出的模拟结果.由图1和图2可以看出,随着样本量的增加,基于本文提出的方法所给出的GMSE逐渐减小,而基于惩罚最小二乘估计方法给出的GMSE即使n增加时仍相对较大.这就表明本文提出的惩罚绝对偏差的估计过程可以有效地消除异常点的影响,从而对模型参数的估计具有相对较高的精度.另外,我们还可以看出对任意给定的样本量n,在不同异常值数量下,基于本文提出方法的模拟结果是类似的.这表明本文提出的估计方法对模型参数的估计具有较好的稳健性.
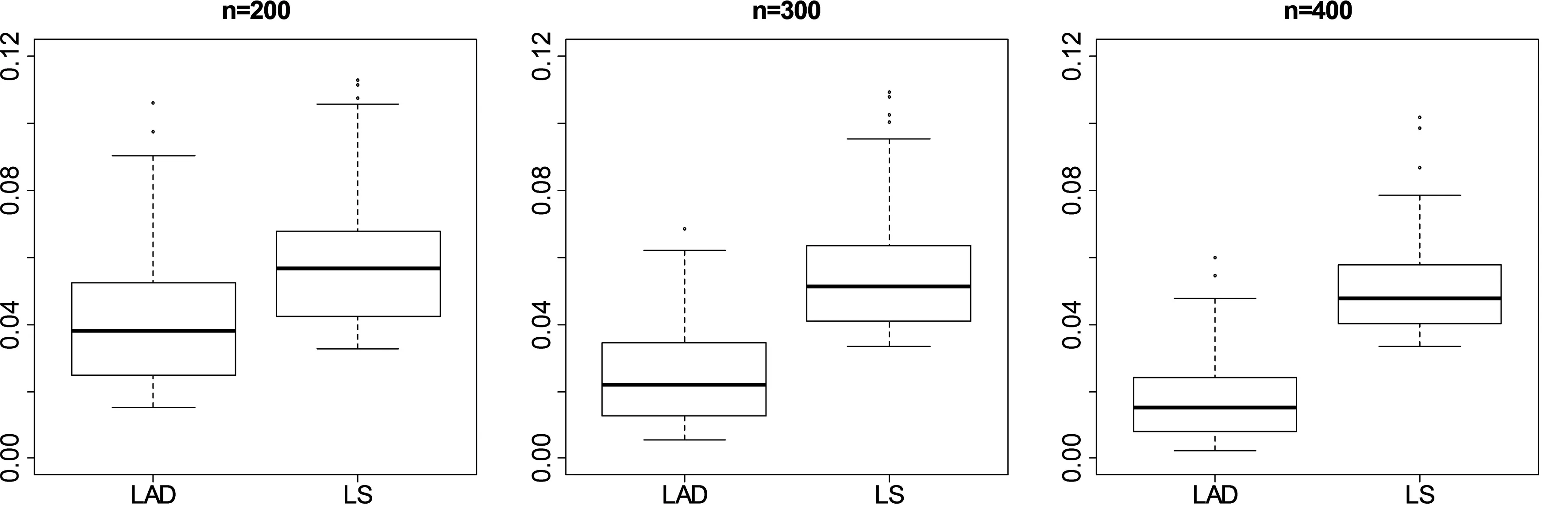
图2 异常值占10%时,模型参数β估计量GMSE的箱线图
猜你喜欢
数学物理学报(2022年4期)2022-08-22
内蒙古统计(2021年4期)2021-12-06
中学生数理化·高一版(2021年2期)2021-03-19
小读者(2020年2期)2020-03-12
阅读(快乐英语高年级)(2019年11期)2019-09-10
中国卫生统计(2019年3期)2019-07-10
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
趣味(语文)(2018年1期)2018-05-25
学苑创造·A版(2015年6期)2015-07-01
遥测遥控(2015年2期)2015-04-23
