
基于文本分类技术的煤矿违章行为统计方法研究
2022-04-21 13:12栗婧张志珍杜璇王真刘紫薇辛艳丽
矿业科学学报 2022年3期
栗婧张志珍杜璇王真刘紫薇辛艳丽
1.中国矿业大学(北京) 应急管理与安全工程学院,北京 100083;2.武警特种警察学院情报侦察系,北京 100100
煤矿作为高危行业,安全工作不容忽视。近年来,国家对煤矿安全生产的重视程度提高,事故发生总量呈下降的趋势(图1),但煤矿一般事故频发,重特大事故时有发生,给我国经济和社会带来了巨大的损失[1],煤矿安全形势依然严峻[2]。因此,指导煤矿安全生产、预防事故发生,依然是安全研究亟待解决的问题。
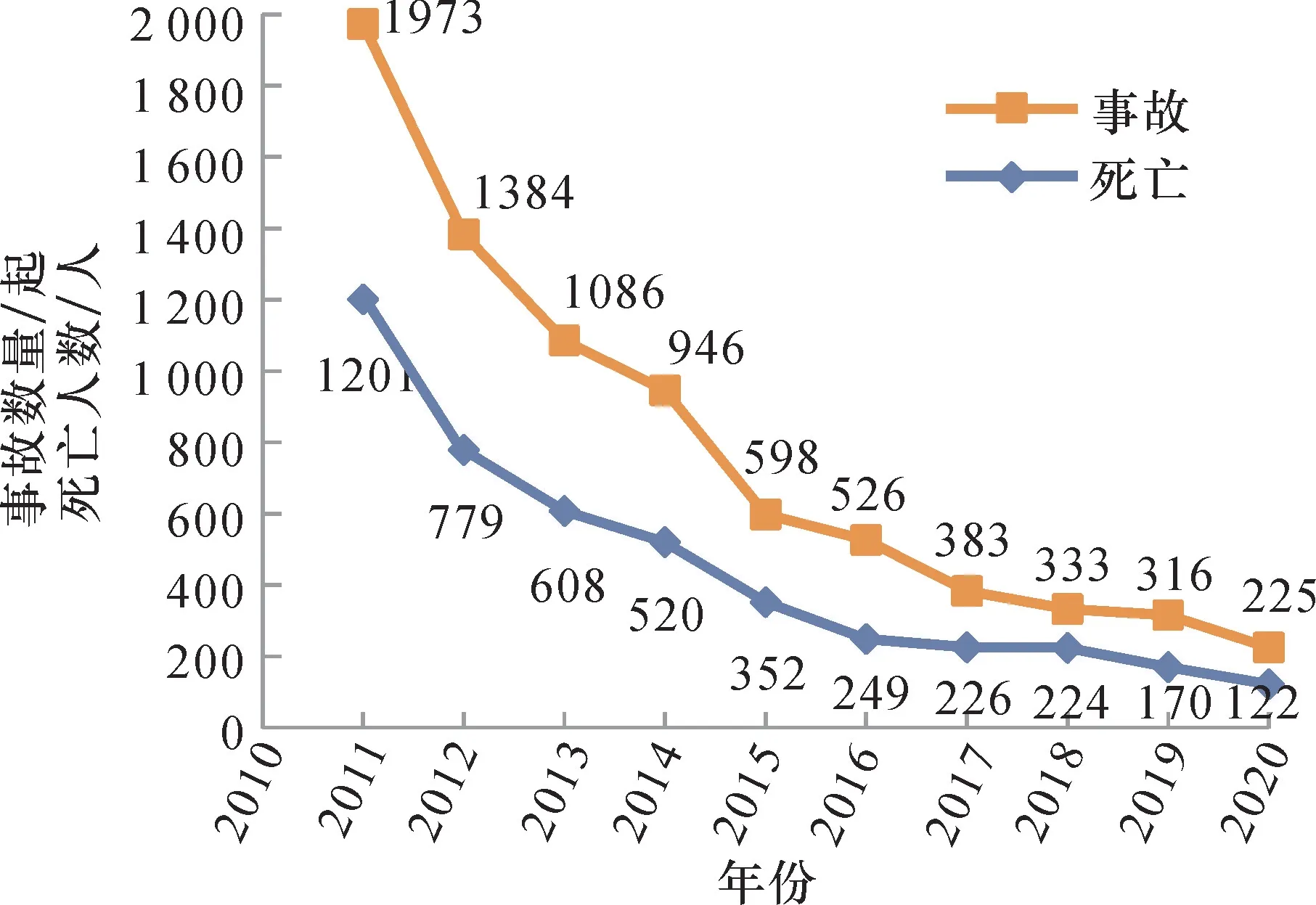
图1 煤矿安全生产发展趋势Fig.1 The development trend of coal mine safety production
已有研究表明,超过80% 的煤矿事故是由人的不安全行为造成的,主要表现为违章行为[3]。目前针对煤矿安全事故的研究,大都是基于全国重特大事故案例,而针对特定煤矿违章行为进行统计分析的较少。同时,我国各大煤矿企业累积了大量的违章信息,此类信息具有数据总量大、记录不规范、特征不明显、类别不具体、人工简单统计、数据应用率不高的特点。海因里希法则指出,当一定量的违章和隐患出现时,事故必然发生。因此,如何科学地统计日常违章行为、有效地分析违章数据,并为安全生产进行及时、高效的指导,是研究的重点问题。
近年来,文本分类技术逐渐成为研究热点。在人工智能的背景下,基于自然语言处理(Natural Language Processing,NPL)的文本分类技术对现有的杂乱数据进行结构化处理、分类型展示、动态性分析,能够提升信息处理的效率与准确率,其较强的应用性也得到了验证。崔敏[4]构造了一种融合深层注意力机制的双层双向长短时记忆网络的深度学习模型,加强了文本分析在电力系统故障方面的应用。秦欢等[5]基于改进的隐式马尔科夫算法制定了非结构化数据的结构化表达规则,形成了一份电网企业国网系统运检专业领域的数据词典库。黄亚春[6]基于自然语言处理的相关技术构建了分类效果最优的卷积神经网络(Convolutional Neural Networks,CNN)模型,加速建筑行业的文本自动分类技术的发展。鲁博仁[7]提出了一种面向铁路安全监督文本的字符级特征提取方法(Character Level-Word2Vec,CLW2V)和基于CLW2V 的铁路安全监督文本分类方法,实现铁路安全监督文本的多类别分类应用。田继存[8]提出了一种基于局部文档频率的文本分类方法(Text Categorization Based on Local Document Frequency,TCBLDF),并将其应用于民航安全自愿报告(Aviation Safety Reporting System,ASRS)数据。可见,现有的研究主要从优化文本分类模型的角度在电力、铁路、建筑、民航等领域展开,但在煤矿安全管理领域研究较少。
本文基于NPL 文本分类技术搭建适用于煤矿领域违章行为的文本数据分类器,结合事故致因“2-4”模型和某矿违章信息,创建分类规则,建立数据文本分类可视化平台,实现违章数据的导入、文本分类、信息统计及多因素分析等功能。通过对煤矿违章信息分类统计,煤矿企业可实现快速实时统计、挖掘数据深层含义、预测安全事故发生,为开展安全培训、落实安全教育、指导煤矿安全生产提供准确的切入点和有力的数据支撑。
1 违章数据分类规则
对复杂问题进行分类时,运用MECE(Mutually Exclusive Collectively Exhaustive)原则分类可以做到不重不漏,MECE 原则来自于麦肯锡咨询公司,中文含义是“相互独立、完全穷尽”。本文通过4 个步骤来运用MECE 原则。
(1) 确定范围。根据某矿违章记录文本,尽可能穷尽收集该矿的违章情况。基于事故致因“2-4”模型理论中对不安全动作的定义及分类方法[9],借鉴其他学者[10-12]利用该理论进行不安全动作分类经验,结合煤矿事故特征,排除掉不违章的不安全动作,对违章的不安全动作(违章行为)进行了划分,将违章行为划分为违章操作、违章行动、违章指挥3 类。违章操作是指违反煤矿生产相关法律、法规、规章和操作规程,具有操作主体、操作对象、操作过程的行为。违章行动是指没有操作对象的行为,或有操作对象但不以工作为目的的行为。违章指挥是指操作主体为管理员或同级工作者,以命令或安排其他人进行违章操作的行为。
(2) 寻找符合的切入点。以《企业职工伤亡事故分类标准》(GB 6441—1986)规定的13 种“不安全行为”为基础划分出10 种违章子类(不安全姿势及位置;不按规定对机器维修检查;不正确警戒、预警或使用信号;使用不安全物品代替专业工具工作;不按规定使用安全防护装置使其失效;未对易燃、易爆及其他物品妥善保护;作业前未排查设备环境隐患;违反劳动纪律分散注意力;冒险进入危险场所;未佩戴/错误佩戴安全装备),并将其一一对应到3 个违章大类中。
(3) 考虑是否需要细分和补充。通过对该矿违章情况分析发现,违章文本的记录均是以《某矿安全生产管理守则》(以下简称“守则”)为依据,且现有的10 种违章子类与实际情况存在差异,需要进一步细化和补充。首先,根据安全管理“三违”(违规作业、违章指挥、违反劳动纪律)中对违章指挥的规定,增加了管理人员的违规组织作业、不合理人员安排以及未有效管控等违章指挥行为。其次,根据守则及具体违章信息记录补充了无证上岗、手指口述不合格、违反标准程序作业、危险气体监测设备使用不当、无人看护作业、安全培训不到位、不安全移动、违反休息规定、违反生产秩序、记录填写不当等违章行为。
(4) 确认是否有遗漏或重复。对上述所有违章子类具体内容、定义适度调整,确保每个子类均包含了1 种或几种具有共同特征的具体违章行为,覆盖范围全面,且彼此之间独立。最终将其划分为23 种违章子类(表1)。

表1 违章分类Table 1 Classification of violations
2 违章文本分类器
文本分类是基于特定文本信息及规则对信息与某一或某些主题对应关系的划分[13]。它是NLP领域中一项具有挑战性的任务,在情感分类、自动问答、舆情分析等领域具有广泛的应用。违章文本分类器处理非结构化数据文本,其文本分类流程主要包含文本预处理、构建空间向量、特征值选取、相似度计算等步骤,如图2所示。
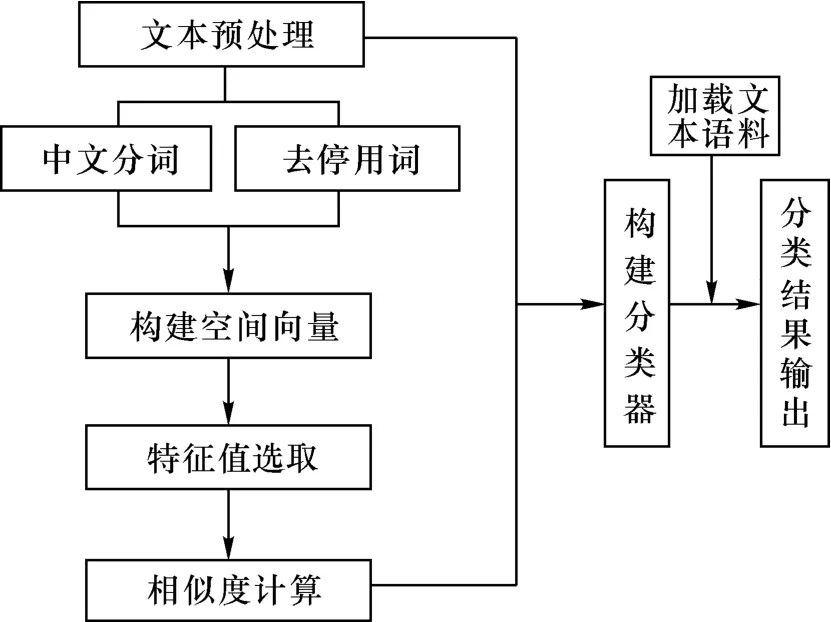
图2 文本分类流程Fig.2 Text classification process
2.1 文本预处理
文本预处理的目的是剔除文本中所有与分类任务无关的内容,并根据需要实现同义词替换功能,将文本转化为由其包含的基本语义单位组成的表列。其首要工作是分词,分词质量的好坏直接影响分类结果。根据煤矿企业的特点,初步选择了两种分词工具:ICTCLAS 分析系统和基于Python 开发的Jieba 分词器。进一步比较发现,Jieba 分词虽然效果上不如ICTCLAS,但在Python 编写上模型简单、代码清晰、扩展性好,可自定义词库的设计和添加功能,且能够根据需要进行优化和改进,有改进的想法就能够编写代码进行修改,从而提高专业领域文本处理结果的准确性与有效性[14-15],因此分词工具最终选用Jieba 分词器。使用Jieba 分词工具自带的自定义词库功能对分词标准进行优化,建立“违章词典.txt” 及去停用词文件“stopword.txt”。
2.2 构建向量空间模型
为了便于计算机识别,需将文本预处理结果转换为向量空间模型(Vector Space Model,VSM)[16],通过空间向量对文本信息进行描述,以便于后期对违章记录与所定义违章子类之间进行相似度计算及特征向量计算。具体步骤如下:
(1) 与违章记录有关的统计结果记为文档集合C。该文档集合是TF-IDF(Term Frequency-Inverse Document Frequency) 算法实现的基础语料库。
(2) 以统计记录与违章形式文本为对象完成中文分词处理,对其中的语气词、连接词、标点符号等元素进行去除和简化,获得词项结果,并用词项集的形式对上述文本的特征内涵进行表述。
2.3 特征值选取
特征值选择是指从特征全集中选取一部分对于分类有贡献的特征子集。本研究采用TF-IDF算法对文本特征值进行筛选。TF-IDF 能够对词语在文档数据集内的重要性进行分析和评价,具体构成要素为TF 与IDF 两部分,用ti表示词项集合中第i个词项,则其对应的词频TF 用tfi,j表示,第i个词项ti的IDF值用idfi表示,TF-IDF 用tfidfi,j表示,其计算公式如下:

式中,tfi,j为词项ti在文档j中的词频;ni,j为词项ti在文档j中出现的次数;mk,j为文档j中第k个词项;∑kmk,j为文档j中所有词项出现的次数总和;idfi为词项ti逆文本频率;|D|为语料库中的文档总数;为包含词语ti的文档数量;tfidfi,j为所求的词项ti在文档j中的权重。
借助TF-IDF 模型计算词项对应的权重值,以此为依据可完成词项排序处理。根据排序结果与选取标准确定关键词,所有的关键词用关键词词典D进行表示,为违章记录关键词和违章类型的并集;而关键词的数量将作为对应空间向量模型的维度数,这个特定维度的向量模型就将作为违章统计记录文本、违章形式文本的抽象空间表达。
进一步分析发现,当违章记录文本和违章类型文本中都包含“指挥”这一关键词时,根据TF-IDF计算公式,“指挥”的权重就会变得很小。尤其是当违章文本与违章类型文本长度不一样时,在截取若干关键词的过程中,很可能把权重小的“指挥”一词剔除掉。而“指挥”一词又是违章类型判定的关键动作,没有“指挥”一词,违章的描述就变得不完整了,缺少了“指挥”这个动作描述,最终会降低文本相似度的匹配效果。因此,本文对上述过程中的词典D进行了重新设计,新的词典D由违章形式文本中的关键词组成。利用中文分词对违章形式文本进行分词操作,分词得到的M′个词项全部作为违章形式文本关键词进行保留。在向量空间中,M′个关键词组成M′维向量,并以此建立新的词典D′,并构建空间向量(表2)。

表2 词典D′构建空间向量模型Table 2 Dictionary D′ to build a spatial vector model
2.4 相似度计算
通过相似度分析技术判断相似度水平,从而确定违章行为的具体分布情况与分布特征。余弦相似度是通过向量之间的夹角来衡量向量相似性。基于TF-IDF 模型可确定文本特征值对应的空间向量,以该向量为基础对其与预设分类向量之间的夹角进行分析。任意两个文档D1和D2之间的相似性系数Sim(D1,D2)指的是两个文档内容的相关程度。如图3可知,在向量夹角很小时,可认为其表现出较为显著的相似性特征;当夹角为0 时,两个向量将完全相同。设文档D1和D2表示VSM中的两个向量:
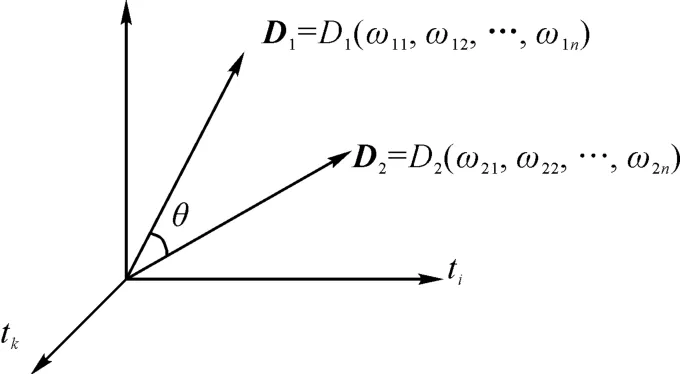
图3 文本空间向量模型Fig.3 Text space vector model

根据夹角的取值结果,确定违章文本和预设分类之间的相似度水平,完成对违章类别的划分。其计算公式为

式中,cosθ代表xi,yi文本的相似度。
以煤矿登高作业为例,设违章形式1 和2 所对应的关键词词典分别为
M1=(工作面,登高,作业,无人,扶梯)
M2=(工作面,登高,作业,未系,安全带)
如果以X=“登高作业无人扶梯”为具体的违章记录结果,则该违章文本所对应的两个违章词典空间向量可分别表示为

2.5 分类结果检验
随机抽取278 条(2% )违章信息同时进行机器分类与人工分类,利用SPSS 软件相关性分析机器分类与人工分类相关关系的密切程度。分类数据见表3。计算Pearson 相关系数,选择【分析】—【相关】—【双变量】,得到双变量对话框,将“机器分类”与“人工统计”选入“变量(V)”框中得到相关性表格。易知,两变量的线性关联显著性(双侧)值为0.000,小于0.10,且在显著性水平0.01下的皮尔森相关性系数为0.986,说明机器分类的结果可信度较强。

表3 机器分类与人工分类结果Table 3 Machine classification and artificial classification results
3 违章文本分类可视化平台搭建
以第2 章搭建的文本分类器为技术基础,后端使用Python 开发工具完成对违章文本的分类处理,并为前端提供数据调用接口。前端使用Vue框架,在Window 上搭建后端文本处理结果及统计分析的可视化展示平台。文本原始数据是由某矿企业安全检查部门给出的每日总计违章统计表格,近3年共1 095 张,以某年4月5日为例(图4),利用pandas 对原始数据进行抽取[17],并将抽取后的结果统一归类至设定好的新表格中。该平台实现了数据导入、文本分类、信息统计、多因素分类统计等多项功能。本文主要针对文本分类实验结果进行展示及分析,将某矿近3年的13 935 条违章记录加载至分类平台,完成自动分类后部分结果如图5所示。

图4 某年4月5日违章记录表Fig.4 Record of violations on April 5

图5 煤矿违章行为文本分类可视化平台Fig.5 Visual platform for text classification of coal mine violations
3.1 违章分类结果展示及统计分析
对3 种违章大类、23 种违章小类发生的频次及各违章大类的违章次数占总违章次数的比率分析可知,违章操作类违章共有8 898 起,在3 类违章中频次最高,占总违章次数的64% ;违章行动类共4 453 起,在总违章次数中占比32% ;违章指挥类共584 起。按照各违章大类中违章子类发生的次数由高到低进行排序(图6),违章操作中排名较为靠前的分别是A6 “违反标准程序作业”、A7“不按规定使用安全防护装置”、A5 “手指口述不合格”3 类;违章行动中发生次数较多的是B4 “违反休息规定”、B6 “未佩戴/错误佩戴安全装备”;违章指挥中主要的违章子类是C1 “安全培训不到位”、C2 “不合理的人员安排”。

图6 违章类别频次Fig.6 Frequency chart of violation categories
其主要原因分析如下:
违章操作主要是认知和应对环节出现问题[18]。煤矿井下生产工艺复杂,设备种类繁多,涉及大量繁杂的标准化生产操作过程。员工安全操作规程掌握不足、对危险的预判能力不足、不进行或错误进行安全防护以及企业未落实煤矿标准化生产、未健全标准化体系、安全培训缺失等,均会造成违章操作的产生。
违章行动是一种个人行为的失当[19]。违章行动主要受个人态度、主观规范、直觉行为控制[20],也受周围员工潜移默化的影响,具有强烈的主观能动性。员工消极、低迷的工作态度以及企业排班作业制度存在问题,均会增加违章行动的发生。
违章指挥是指管理决策环节出现的差错,主要受管理层行为人个体素质所影响。行为的主体责任大,行为的影响意义重要,危害性完全不亚于另外两种违章类别,但是由于管理层的人员基数远远小于普通员工,因此违章数量是最小的。企业现场指挥人员个人能力不足、同级作业人员盲目指挥、企业培训不合理等均会导致违章指挥的出现。
3.2 违章子类频次分类分析
为了对违章行为进行精准预防,需要对违章子类发生频次及其在所属的违章大类中的占比(以下简称“占比”)进行分析。基于SPSS 软件的K-均值聚类(K-means)分析违章子类发生频次的聚类[21],将各违章子类划分为高频、中频、低频违章子类。
以违章操作的12 种子类为例,将违章操作子类代码及对应的频次导入SPSS 数据编辑器,选择【分析】-【分类】-【K-平均值聚类分析】,“频次”设为变量,“违章操作子类”设为标注个案,聚类数选择3,方法选择“迭代与分类”,“保存”中勾选“聚类成员”与“与聚类中心的距离”,“选项”中勾选“每个个案的聚类信息”,点“确定”,即可得到聚类之后的3 类数据信息(表4)。
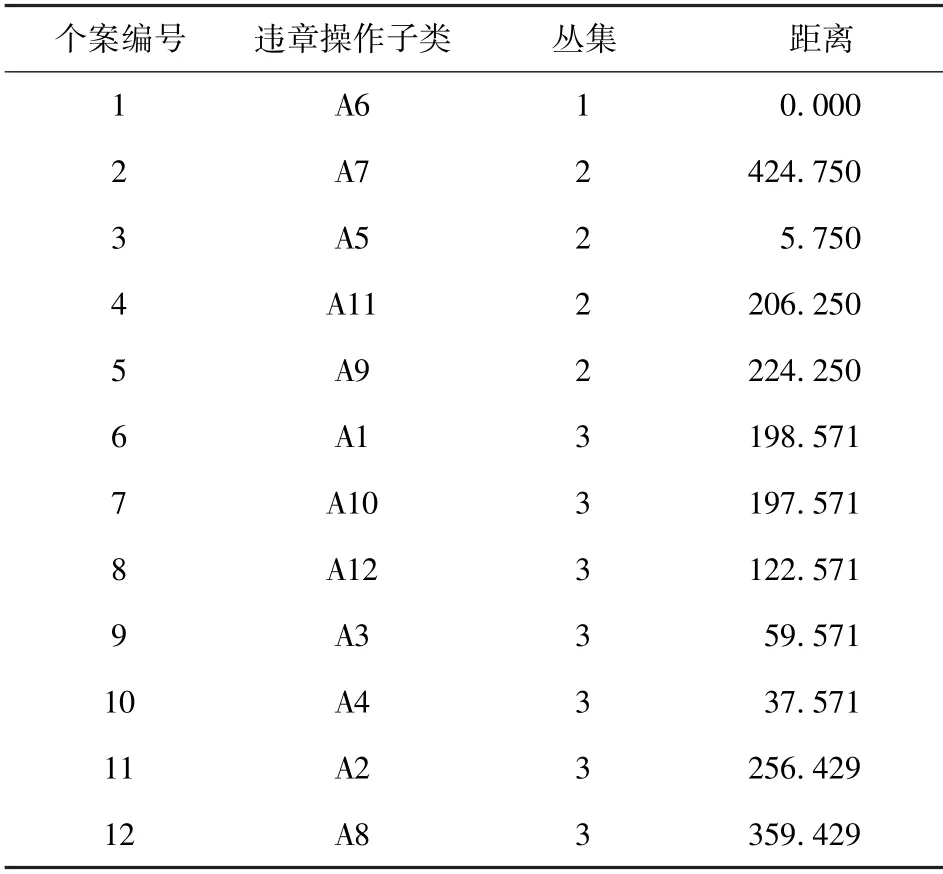
表4 违章操作子类K-平均值聚类分析结果Table 4 K-mean clustering analysis results of illegal operation
同理,将违章行动和违章指挥进行聚类之后,将丛集1 认定为高频违章子类、丛集2 认定为中频违章子类、丛集3 认定为低频违章子类,如图7与表5所示。

表5 违章子类频次分类分析Table 5 Frequency classification and analysis of illegal subcategories

图7 违章子类占比Fig.7 Chart of violation of the subclass
分析统计结果可得,“违反标准程序作业”2 227 起,占比25.03%,为高频违章操作;“不按规定使用安全防护装置”1 383 起,“手指口述不合格”964 起,“无人看护作业”752 起,“未使用/错误使用危险源检测设备”734 起,总占比43.07%,为中频违章操作;其余违章操作发生的频数(起)均小于605,总占比31.9%,记为低频违章操作。“违反休息规定”1 702 起,占比38.22%,记为高频违章行动;“未佩戴/错误佩戴安全装备”1 424 起,占比31.98%,记为中频违章行动;“违反劳动纪律、不安全移动、无证上岗/证件不符合规定、违规进入危险场所、破坏生产管理秩序”分别为628 起、405起、143 起、105 起、46 起,总占比为29.79%,记为低频违章行动。“安全培训不到位”267 起,占比45.72% 记为高频违章指挥;“不合理的人员安排”196 起,占比为33.56%,记为中频违章指挥;“违规组织作业、未有效对井下作业秩序进行管控”为60起左右,总占比为20.72%,记为低频违章指挥。总的来说,违章操作呈现总体频次基数大、违章子类多的特点;违章行动的高、中频违章子类种类少、占比高,低频违章子类种类较多;违章指挥由于基数少,违章子类频次均较低,但高、中频违章子类占比极高。
企业违章行为管控措施要根据不同违章类别的不同特点来制定。对违章子类占比数据进行深入分析可知,高频违章类别需要企业高度重视,立即采取措施予以整改,如通过优化安全生产管理信息系统[22]、完善作业程序标准化规范员工操作行为,通过制定实施针对性的整改措施减少高频违章行为的发生,通过定期检查整改执行进度严控整改措施的效果,通过严格开展安全检查人员的绩效考核规范违章行为监督工作等。中、低频违章类别是发展成为高频违章类别的潜在因素,不容忽视,企业要定期组织技能培训,对不安全行为组织干预[23],帮助员工自觉养成按章操作的习惯。此外,要增加安全融入企业管理的程度,强化企业安全文化建设,从而达到从根本控制企业生产风险的效果。
4 结 论
本文采用自然语言文本分类技术搭建了适用于煤矿的违章文本分类器与煤矿违章行为分类可视化平台,选取某矿违章数据进行了智能分类和统计,得到如下结论:
(1) 本文基于“2-4”模型将煤矿违章划分为3大类23 小类。利用文本分类技术,结合违章数据特点构建完成了煤矿违章行为文本数据自动化分类器,其流程为:Jieba 分词器文本预处理→向量空间模型构建→TF-IDF 筛选文本特征值→相似度水平计算。
(2) 在文本分类器的基础上,利用Vue 框架开发了煤矿违章分类可视化软件平台,利用Python环境实现了对违章数据的自动化分类及数据调用,使平台具有违章数据导入、违章信息文本分类、违章多因素分类统计等多项功能,极大地提升数据分析的速度和准确度。
(3) 违章数据分析结果显示,3 类违章中违章操作类频次最高,占违章总数的64%,其次为违章行动与违章指挥,分别占32% 和4%。进一步对违章子类分析可知,其中违章操作含1 种高频、4 种中频、7 种低频子类,高频操作占比25.03%,为“违反标准程序作业”;违章行动含1 种高频、1 种中频、5 种低频子类,高频违章行动占比38.22%,为“违反休息规定”;违章指挥含1 种高频、1 种中频子类、2 种低频子类,高频违章指挥占比45.72%,为“安全培训不到位”。
本文立足于某煤矿近3年违章数据建立煤矿违章行为分类平台,其违章分类方法及依据违章词典的向量空间模型较适用于该煤矿,但在其他煤矿的适用性缺乏验证,且该分类器准确率有待进一步提升,智能化水平也有待提高。同时,应开展违章行为统计方法及可视化平台在其他煤矿的适用性验证,分析全国煤矿的违章数据,以期建立一个普遍适用于煤矿专业领域的自然语言文本分类模型。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电子乐园·上旬刊(2022年5期)2022-04-09
作文·初中版(2021年12期)2021-09-15
汽车与驾驶维修(汽车版)(2020年6期)2020-07-24
知识文库(2018年2期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
中外文摘(2016年4期)2016-03-17
三联生活周刊(2015年52期)2015-12-25
新高考·高二数学(2015年11期)2015-12-23
