
基于多尺度特征校准的图像协调化方法
2022-04-21 02:10高陈强谢承娟李鹏程
电子与信息学报 2022年4期
高陈强 谢承娟 杨 烽 赵 悦 李鹏程
(重庆邮电大学通信与信息工程学院 重庆 400065)
(信号与信息处理重庆市重点实验室 重庆 400065)
1 引言
图像组合是把一幅图像的“兴趣内容”复制到另外一幅图像的指定区域,从而合成一幅新的图像。随着移动智能终端,移动互联网各种应用的发展,这一需求越来越明显。特别是,在机器学习领域,通过图像组合,可以低成本地产生大量带标签的训练数据,用于机器学习模型训练,从而减少人工标注。
通常情况下,用于图像组合的两幅图像存在成像差异,即复制的“兴趣内容”(前景区域)与嵌入的图像(背景区域)存在较大颜色、亮度等差异,这使得组合图像在视觉上不协调。因此,图像协调化是图像组合中必须且极其重要的一个环节,其目的是对编辑后的组合图像实现视觉一致性,即调整前景区域的外观使其和新的背景一致,从而让整幅图像在视觉上更加真实。
对于图像协调化任务,导致组合图像看起来不真实的主要原因是前景区域和背景区域的拍摄条件(例如,天气、季节、一天的时间)不同,从而使得前景和背景的颜色、光照等外观特征存在明显差异。
近年来,深度卷积神经网络(Deep Convolutional Neural Network, DCNN)因其强大的学习能力被广泛应用于各种计算机视觉任务,也有一些网络模型被设计用于解决图像协调化任务。一些方法利用额外的辅助网络提供语义信息,然后通过一个编解码网络输出协调化图像[1,2]。另一些方法基于组合图像前景与背景存在外观差异的特性,分别学习前景和背景特征,然后采用对抗训练的方式实现图像协调化[3,4]。这些方法都没有考虑相同拍摄条件下图像局部的亮度变化,使得图像整体的光照不协调。
对于相同条件下拍摄的自然图像,通常具有如下光照特性:不同局部区域的亮度、色度等特性由于入射光的投射角度以及不同物体的反射系数等因素的影响存在差异,但是亮度和色度的变化是连续的,相邻区域的亮度和色度差异微小。
基于以上分析,受Inception[5]和SKNet[6]中多尺度感受野的并行多分支结构的启发,本文设计了一个新的编解码网络实现图像协调化任务。首先,本文提出一个多尺度特征校准模块(Multi-scale Feature Calibration Module, MFCM)用于学习不同尺度的感受野之间细微的特征差异。然后,基于MFCM本文设计了一个编码器学习组合图像中前景与背景的外观差异和局部光照强度变化。最后通过解码器重构出协调化图像。具体地,MFCM首先利用多个不同尺度的卷积核对输入特征图多次提取特征,这相当于用多个具有互补感受野的滤波器探测原始图像,从而在多尺度上捕捉前景目标以及有用的上下文信息。由于不同组合图像前景目标尺度以及拍摄条件存在差异,为了充分有效地利用以不同感受野提取的特征信息,MFCM进一步通过一个通道注意力门自适应地对所有特征校准。
本文在iHarmony4数据集[4]上对所提方法进行了评估,实验结果表明本文方法能同时学习到组合图像前景与背景的外观差异和局部的光照强度变化,有助于图像协调化任务。与现有方法相比,本文方法能达到更好的性能。
2 相关工作
本节简要介绍已有的图像协调化方法以及其他相关的图像转换工作。
2.1 图像协调化相关方法
传统的图像协调化方法通过匹配颜色空间中的低水平外观统计信息[7]来调整前景区域和背景区域一致。近年来,基于深度学习的方法成为研究的热点。Zhu等人[8]深入开展了基于深度学习的图像真实性研究工作,设计了一个具有高容量的卷积神经网络(Convolutional Neural Networks, CNN)模型用于区分真实图像和自动生成的组合图像,并且通过优化模型预测的真实性分数来调整掩码区域的颜色。Tsai等人[1]首次尝试训练一个端到端的CNN模型用于图像协调化任务,提出的深度图像协调化(Deep Image Harmonization, DIH)模型采用一个具有跳跃连接(skip connection)的编解码结构,在解码器中加入一个额外的分支用于语义分割,利用语义信息辅助图像协调化过程。Sofiiuk等人[2]将一个预训练的语义分割网络和基于编解码的协调化网络联合训练,利用语义分割网络中提取的高层语义特征对编码器提取的特征进行补充。Cun等人[3]基于DIH网络在解码器中插入空间分离注意力模块用于分开学习前景和背景特征,除此之外,他们还加入对抗损失用于提高生成图像的真实性。Cong等人[4]将组合图像的前景和背景看作不同的域,将真实图像的前景和背景看作相同的域,以一个注意力增强的U-Net网络作为生成器,结合一个全局鉴别器和一个用于判定一幅图像中前景与背景是否属于相同域的域验证鉴别器,通过对抗训练的方式实现图像协调化。然而,这些方法只考虑了组合图像前景和背景之间的外观差异,没有考虑到相同拍摄条件下图像中局部的亮度变化差异。本文所提方法能够同时学习组合图像中前景与背景区域的外观差异和局部的亮度变化。
2.2 图像转换相关方法
图像协调化可以看作图像转换(image-to-image translation)任务[9,10]的一个特例,图像转换任务的目的是将图像从一个域转换到另一个域,例如图像超分重建[11,12]、图像修复[13,14]、图像风格迁移[15,16]等任务。Isola等人[9]提出逐像素转换型生成对抗网络(pixel-to-pixel Generative Adversarial Networks,pix2pix GAN)用于解决图像着色和图像重构问题,这个网络也可用于图像协调化任务。除此之外,Anokhin等人[17]将生成模型与一种新颖的上采样策略相结合用于模拟白天的光照变化,实现了在不同的光照下重新渲染相同的场景。He等人[18]利用图像之间语义上的密集对应提出一种算法实现具有相似语义结构的图像间的颜色转换。然而,这些方法要么只考虑了图像转换任务的普遍特性,要么只设计用于某一特定图像转换任务,不能很好地适用于图像协调化问题。
3 本文方法
图像协调化可以建模为一个监督学习问题,将组合图像和对应的前景掩码输入网络模型,网络通过学习调整前景的外观使其和背景一致,从而生成协调的具有真实感的图像。本文的协调化网络的主体是一个具有跳跃连接的编解码结构,如图1所示。本文利用MFCM构建编码器学习组合图像中前景与背景的外观差异和局部光照强度变化,然后通过解码器对编码器学习到的特征解码,重构出图像。最后将重构图像的前景与原始组合图像的背景组合得到最终的协调化图像。网络的实现细节将在3.2节进行详细介绍。
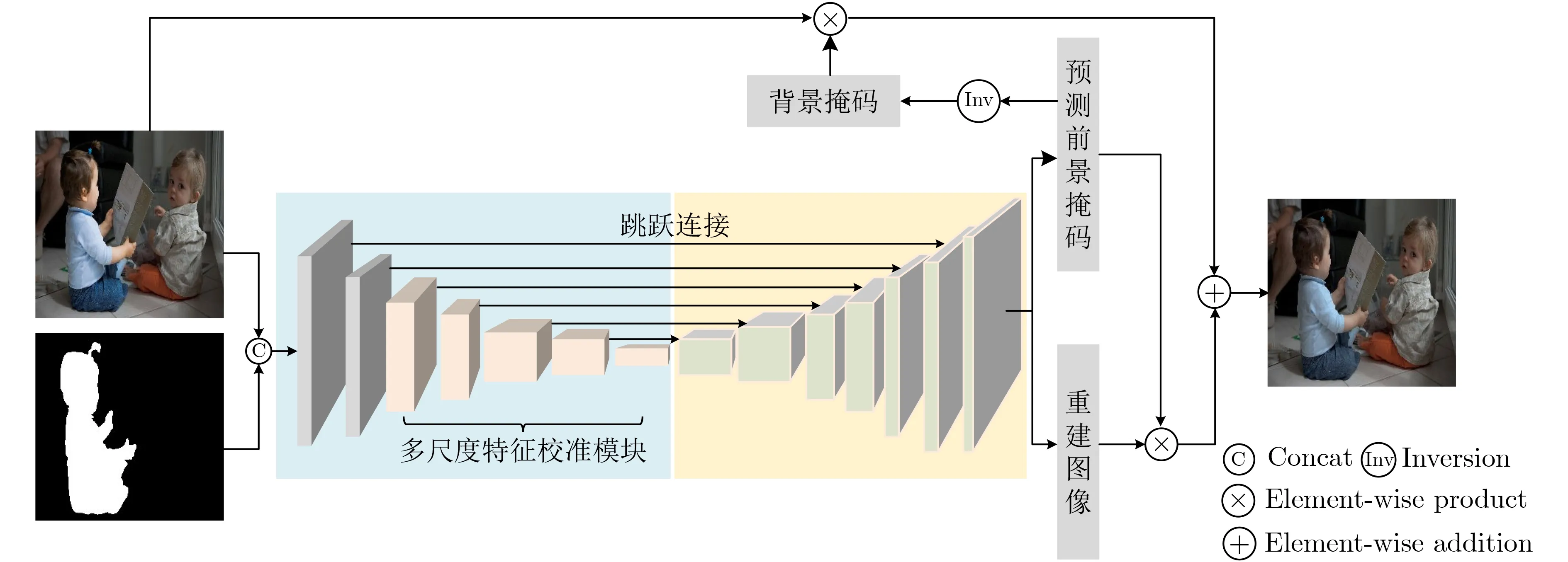
图1 本文的图像协调化网络结构图
3.1 多尺度特征校准模块(MFCM)
MFCM由两部分组成:首先,对任意的输入特征图X,通过多个并行的分支以不同的感受野提取特征,这一过程称为多尺度特征提取(Multi-scale Feature Extraction, MFE);然后,为了充分有效地利用所有分支提取的特征,通过一个通道注意力门控制携带不同尺度信息的多分支信息流,这一过程称为特征校准(Feature Calibration, FC)。MFCM网络结构如图2所示,本文的多尺度特征提取部分由两个分支组成,更多的分支可能会更有利于提升图像协调化效果。接下来详细介绍MFCM。
多尺度特征提取:对于输入特征图X,通过两个并行的分支分别提取特征,如图2中浅蓝色区域所示。本文采用3×3和5×5两种尺度的卷积核提取特征。为了控制模型的复杂度,每一个分支中加入1×1的卷积降低通道数。并行分支的每一个卷积层后接有归一化层和激活层。由于不同图像的颜色、光照等外观特征各不相同,将不同图像看作属于不同的域。为了学习到每一张图像的外观统计特征,归一化层选择实例归一化(Instance Normalization, IN)[19]而不是批归一化(Batch Normalization, BN)[20]。激活函数选择LeakyReLU。具体地,两个分支的处理过程如式(1)
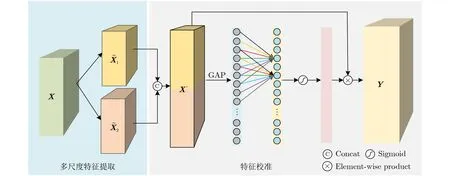
图2 多尺度特征校准模块网络结构


3.2 网络细节
本文的协调化网络结构中,编码器的前两层为带有激活函数的标准卷积层,后面接有5个连续的多尺度特征校准模块,如图1中浅粉色模块所示。整个编码器的结构如图1中蓝色区域所示。编码器中每一个网络层均以2为因子进行下采样。然后,解码器通过2为因子的反卷积层对编码器学习的特征上采样,直至恢复出输入图像的分辨率。解码器的每一个网络层都包含了反卷积层、归一化层和激活函数。整个协调化网络中归一化层和激活函数选择与MFCM一致。由于图像编码过程特征分辨率不断降低,不可避免会丢失一些信息,利用编码器的输出不可能完整地重构出图像。因此,在编码器的每一层和解码器对应分辨率的反卷积层中间加入跳跃连接。跳跃连接中编码器特征与解码器特征采用逐像素加和的方式融合。对于上采样得到的特征图,通过两个1×1的卷积层分别预测重构图像和前景掩码,并对预测的前景掩码逐像素取反得到背景掩码。最后利用预测的前景掩码提取出重构图像的前景区域,利用背景掩码提取出组合图像的背景区域,将重构图像的前景区域与组合图像的背景区域组合得到最终的输出图像。
3.3 损失函数
对于图像协调化任务,组合图像与真实图像之间仅在前景区域存在外观上的差异,为了准确地衡量前景区域的外观差异,本文选择前景归一化均方误差(Foreground Normalized Mean Square Error,FN-MSE)[2]作为损失函数指导网络训练,FN-MSE的表达式如式(7)
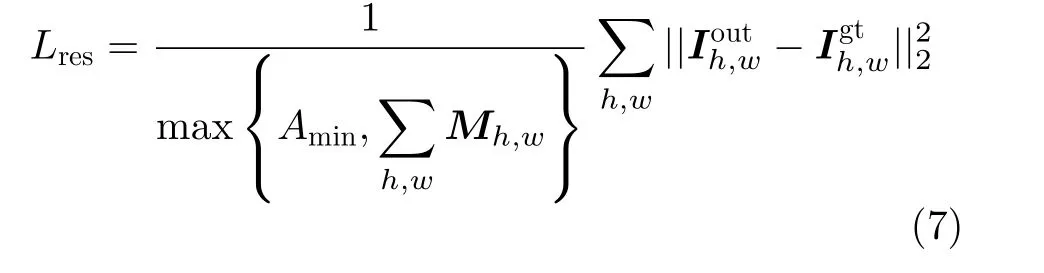
式中,M表示前景掩码,Iout表示网络输出图像,Igt表示对应的真实图像,Amin是一个超参,目的是避免前景区域太小导致损失函数训练不稳定。根据文献[2]中的设置,Amin=100。
式(7)中对输出图像前景区域与真实图像前景区域的L2范数进行归一化,近似为输出图像与真实图像前景区域的外观特征的统计差异。这样可以实现协调化效果较好的训练数据对应的损失较小,而协调化效果较差的训练数据对应的损失较大,由此使得网络能更加关注较难样本的学习。
4 实验结果与分析
4.1 数据集与评估指标
iHarmony4数据集[4]是图像协调化任务广泛使用的公开数据集,本文方法在该数据集上进行训练和测试。iHarmony4数据集由4个子数据集构成,分别是HCOCO, HFlickr, HAdobe5k和Hday2night,每一组数据对包含了组合图像和真实图像。
HCOCO是将Microsoft COCO[23]的训练集和测试集合并之后采用文献[1]中提出的方法合成的。HCOCO中组合图像由背景区域和前景区域组合得到,背景区域和前景区域都是从真实图像中提取出来的,但是前景区域的外观信息被修改过。前景区域的外观信息是从另一张图像中属于同一类别的前景转换得到的。HCOCO子数据集包含38545个训练数据对和4283个测试数据对。
HFlickr采用从Flickr1)https://www.flickr.com/explore中收集的4833张图像合成,每一张图像被手动分割出1个或2个前景区域,组合图像的合成过程和HCOCO相同。HFlickr子数据集包含7449个训练数据对和828个测试数据对。
HAdobe5k是基于MIT-Adobe5k数据集[24]合成的。MIT-Adobe5k数据集中共有5000张照片,每一张照片均被5个摄影师处理过,生成5种不同的风格。选择其中的4329张照片用于构建HAdobe5k数据集,对每张照片手动分割出一个前景区域。组合图像的背景区域从原始照片中提取得到,前景区域从5张编辑后的图像中提取得到。HAdobe5k子数据集包含19437个训练数据对和2160个测试数据对。
Hday2night基于Day2night数据集[25]合成,选择其中包含80个场景的106张图像用于构建Hday2night子数据集,对每张图像手动分割出1个前景区域。其中组合图像的构建过程与HAdobe5k相同,背景区域和前景区域从相同场景的不同照片中提取得到。Hday2night子数据集包含311个训练数据对和133个测试数据对。
本文采用均方误差(Mean Square Error, MSE)和峰值信噪比(Peak Signal to Noise Ratio, PSNR)作为模型性能的评价指标。其中,MSE值越小,代表模型的性能越好;PSNR值越大,代表模型的性能越好。
4.2 训练细节
在将图像输入网络之前,需要缩放到256×256的固定尺寸。为了提高模型训练的稳定性,将输入数据缩放到[0,1]范围并利用ImageNet数据集[26]的三原色(Red Green Blue, RGB)均值和标准差进行标准化处理。除此之外,本文还采取了水平翻转和随机大小裁剪的数据增强策略来提高模型的泛化能力。
本文的模型在PyTorch v1.1和CUDA v9.0的环境下训练,优化器选择Adam,对应的参数设置为β1=0.9,β2=0.999,ε=10−8。初始学习率设置为0.001。对于模型的训练和测试,将4个子数据集的训练集合并成一个完整的训练集训练模型,然后分别在4个子数据集和合并后的完整测试集上评估模型性能。
4.3 与已有方法对比结果
4.3.1 定量结果对比
表1给出了本文方法与现有图像协调化方法深度图像协调化(Deep Image Harmonization,DIH)[1]、空间分离注意力模块(Spatial-Separated Attention Module, S2AM)[3]、图像域验证网络(Domain Verification Networks, DoveNet)[4]和具有前景语义感知的图像协调化方法(Foreground-aware Semantic Representation for Image Harmonization, FSRIH)[2]的真实图像与协调化图像的MSE和PSNR分数。从表1的结果可以看出,本文方法除了Hday2night子数据集的PSNR分数与目前最优的方法相比略低一点,其他所有子数据集及整个iHarmony4数据集的评估结果都超过了已有方法,实现了最优的协调化结果。这表明本文方法能学习到组合图像局部的光照强度变化,从而能更好地学习到组合图像前景与背景的外观差异,有助于图像协调化任务。
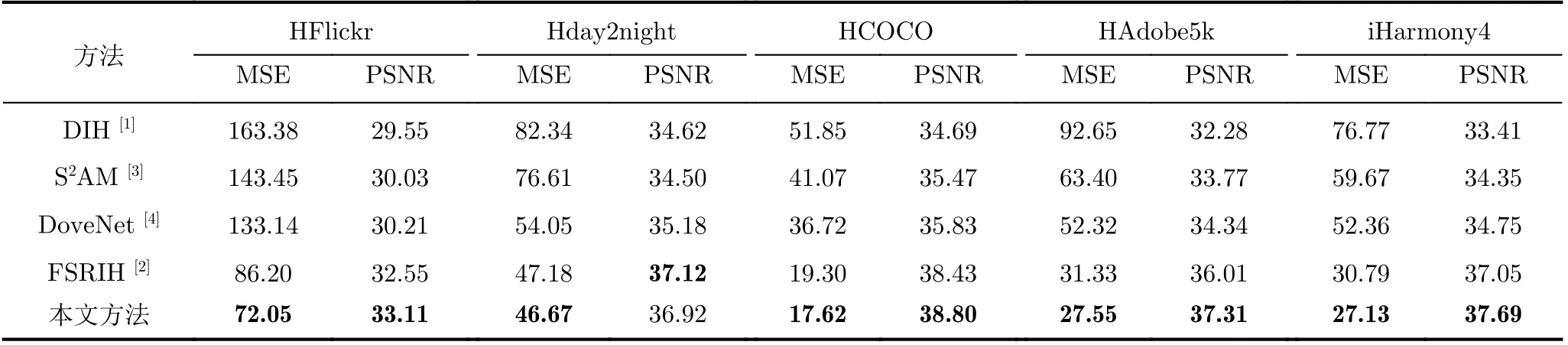
表1 不同方法在iHarmony4测试集上的性能对比
本文还通过仅对前景区域进行评估来研究前景区域的比例对模型性能的影响。根据文献[2]和文献[4]中的做法,将前景区域占整幅图像的比例划分为3个范围,分别是0~5%, 5%~15%和15%~100%,采用只对前景区域计算MSE,即fMSE(foreground MSE)进行评估。对前景区域的评估结果如表2所示。从表2的结果可以看出本文方法在具有不同前景区域比例的数据上都达到了最优的性能,特别是前景目标占整幅图像比例较大时模型性能提升较大。这验证了MFCM的鲁棒性,表明MFCM能在多尺度上捕捉前景目标及上下文信息,有助于学习到不同尺度前景目标与背景区域的外观差异和局部亮度变化。

表2 不同方法在iHarmony4测试集上不同前景区域比例的MSE和fMSE指标对比
4.3.2 定性结果对比
图3展示了组合图像、真实图像、已有的基于深度学习的协调化方法[2–4]以及本文方法生成的协调化图像。图中的红色虚线框标示了前景区域所在的位置,从图3中可以观察到本文的方法生成的协调化图像前景与背景的颜色、亮度等特性是一致的,图像整体的光照更加协调,这也验证了本文方法对图像协调化任务是有效的。

图3 不同方法在iHarmony4测试集上的定性对比
4.4 消融实验
为了验证MFCM中MFE与FC两部分的有效性,对应的消融实验结果如表3。“RF=3”和“RF=5”分别表示仅利用3×3和5×5大小的卷积核提取特征的模型性能,结果表明利用3×3大小的卷积核提取特征的模型性能更好。“MFE”代表仅采用MFE提取特征,其对应的结果优于“RF=3”和“RF=5”,这表明利用多个不同尺度的卷积核对输入特征图多次提取特征能学习到图像局部的亮度变化差异,有利于图像协调化任务。“MFE+FC”代表采用完整的MFCM提取特征,其结果优于“MFE”,这验证了网络自适应地校准特征能够更加充分利用多尺度特征,对图像协调化任务是有效的。

表3 多尺度特征校准模块不同组件的消融实验结果
表4评估了以不同的方式进行特征校准对模型性能的影响。具体地,表4评估了独立预测特征权重、利用邻域特征间的交互关系预测特征权重和利用全局特征间的交互关系预测特征权重的模型性能。从表4可以看出,利用邻域通道间的交互进行特征校准可以达到更优的效果。由于每一个卷积核可以被看作一个特征提取器,不同的特征之间存在一定的相关性,而各通道间独立地预测各自的权重没有考虑到通道间的相互关联,预测的权重不能准确地表示不同特征的相对重要性。由于特征校准是基于多尺度感受野的并行特征提取模块实现的,如果利用所有通道间的交互关系预测特征权重,以不同的感受野提取的特征之间可能存在相互干扰,预测得到的特征权重不准确。因此,对于多尺度特征提取模块,利用局部邻域通道间的交互关系预测通道权重会更合理。除此之外,表5是以不同的局部跨通道范围进行特征校准的实验结果,具体地,表5给出了k=3,k=5,k=7和k=9时模型的性能评估结果,实验表明,当k=7时模型性能最好。

表4 以不同的方式进行特征校准的实验结果

表5 以不同的跨通道范围进行特征校准的实验结果
5 结论
本文根据图像协调化任务的特性提出了一个新的多尺度特征校准模块,并基于此模块通过一个编码器学习组合图像中前景与背景的外观差异和局部亮度变化,然后通过解码器重构出图像,以此来实现图像协调化。通过在iHarmony4数据集上对协调化图像进行定性分析以及以MSE和PSNR作为模型性能的评估标准进行定量分析,验证了本文方法是有效的。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
中国外汇(2019年11期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
太空探索(2016年10期)2016-07-10
