
普通话语句音强变化模式—基于SCS 和DBS 语料的分析
2022-05-11 07:31史晴琳冉启斌
智能计算机与应用 2022年2期
黄 玮, 于 爽, 史晴琳, 冉启斌
(1 南开大学 汉语言文化学院, 天津 300350; 2 天津职业技术师范大学 外国语学院, 天津 300222;3 天津天狮学院 外国语学院, 天津 301700; 4 南开大学 文学院, 天津 300071)
0 引 言
音高、音强和音长等语言要素,在语句中的情况与在音节中的情况往往有所不同。 学界对语句中音高的研究也比较充分。 文献[1-2]较早指出英语中具有音高下倾(pitch declination)现象;文献[3-4]的研究表明,在日语、约鲁巴语中也存在音高下倾的现象;文献[5]中曾对音高下倾做过系统的介绍;文献[6-8]的研究者指出,汉语句子也存在音高下倾和音高重置的语调特征。 而音强作为语音的4 要素之一,在汉语句子中是否具有与音高类似的下倾特征,是一个值得关注并探究的问题。 文献[9]中指出,音强为重音的感知提供了重要的声学依据。 但学界对音强的研究并不太多,往往被视为韵律或语调研究中较为次要的一个参考因素进行研究。 已有对音强的研究大多使用计算音量比的方式,如文献[10]中提出了语调格局的方法,使用计算音量比的方式,对广义语调的音强进行定量考察;文献[11-12]将音强作为焦点的韵律表现之一进行研究等等。 语句中的音强变化具有怎样的特点,是否具有一定的模式,是值得研究的问题。
本文基于“民族地区地方普通话语音调查及声学数据库建设”项目中的标准汉语句子(Standard Chinese Sentence,SCS)语料与中文标准女生音库(Data-Baker Sentence,DBS)语料两种句子录音材料,使用语音分析软件提取出每个句子100 个点位上的音强,对句子音强的整体变化模式、变化速率、最值等进行量化考察,以期促进对句子音强变化模式的认识。
1 语料与方法
1.1 SCS 语料与DBS 语料
SCS 语料的句子多为日常生活内容,其中包括陈述句40 个,疑问句38 个,感叹句和祈使句各11个,共100 句;单句音节数量最少7 个,最多32 个(均值14.39,标准差5.89)。 语料发音人均是来自北方方言区、普通话水平达到二级甲等以上的在校大学生,数量为5 男5 女,共10 人。 录音采集在安静的语音实验室中进行。 录音之前,发音人有充足的时间了解实验情况,熟悉语料和实验要求。 录音时,发音人根据句子语境,以日常语速和音量发音,以确保录音具有较高的自然度和真实度。 录音采用单声道录制,采样率为22 050 Hz,采样精度为16 bit。 各句子单独保存为一个声音文件,存储格式为WAV。 最终,SCS 语料成功采集10 位发音人读100个汉语句子的1 000 条录音文件。
DBS 语料包含1 万个汉语句子,是“标贝科技”开源公布的数据产品之一。 DBS 语料句子的内容涵盖各类新闻、小说、科技、娱乐、对话等领域。 其中包括陈述句9 154 个,疑问句550 个,感叹句233 个,祈使句63 个。 DBS 语料包含162 864 个音节,单句音节数量最少3 个,最多34 个(均值16.29,标准差5.39)。DBS 语料录音的采集在专业录音棚中使用专业录音设备和录音软件完成,录音采样率为48 KHz,采样精度为16 bit,采用单声道录制。 每个句子单独保存为一个声音文件,存储格式为WAV。DBS 语料的发音人均是女性,年龄在20 ~30 岁,普通话标准、声音清晰、语速适中。
SCS 语料与DBS 语料在句类比例、音节数量、录音质量和自然度等方面各有特点。 DBS 语料绝大部分是陈述句,其他3 种句类占比极小;而SCS 语料适当提高了疑问句、感叹句和祈使句的比例。 在句子音节数量上,DBS 语料比SCS 语料平均多近2 个音节,并且数量跨度比SCS 语料更大,句子长度更多样,且DBS 语料音节的标准差较SCS 语料小一些,内部数量的波动幅度更小,这得益于DBS 语料所含句子数量更庞大。 在录音质量上,DBS 语料的录音在采样率、录音环境和设备上都更为优质、专业,语料内容涉及领域更广泛。 但是,以录音的自然度来讲,DBS 语料在听感上较为机械,与日常会话语言差别较大;而SCS 语料更为自然,更能反映日常生活中的语言使用情况,并且将男性发音人也纳入其中,做到了性别上的平衡。 综合考虑以上情况,本文将以分析自然度更优的SCS 语料为主,以分析样本量更大的DBS 语料为辅。 在提取音强时,SCS 语料和DBS 语料所使用的方法和处理步骤有所不同。
1.2 音强提取
在进行音强数据提取之前,本文使用语音分析软件Praat 对SCS 语料进行了预处理。 首先,使用脚本自动插入句子标注层,并根据音强阈值,自动对齐句子层边界生成标注文件;然后,借助另一脚本,将句子文本插入到对应位置;最后,由有经验的标注者对标注边界进行逐句调整,以确保数据准确、有效。
由于DBS 句子数量庞大,本文使用脚本在Praat中自动生成句子边界以后,没有进行人工校对。 原因在于DBS 语料录音杂音极少,脚本自动标注的句子边界较为准确,足以满足DBS 语料作为辅助分析材料的条件。
音强数据的提取也是在Praat 中运行脚本完成的。 脚本对每个句子等比例提取100 个音强。 需要说明的是,由于SCS 语料的句子首尾边界由人工进行调整、核对,为保证数据的科学、客观,在进行数据分析时,将首点(1 号点)和末点(100 号点)的数据排除在外,即每个句子有效的点位是98 个。 提取出数据后,在Excel2019 和SPSS26.0 中进行数据处理和统计分析。
2 SCS 语料的音强变化模式
2.1 句中音强的下降与回升模式
下面首先报告SCS 语料的分析结果。 在Excel中,分别求出各发音人100 个句子中98 个点位上音强的均数,得到代表各发音人句子音强走势的数据。随后,为观察句子音强的走势,在Excel 中绘制出每位发音人的句子音强散点图。 从散点图看到,10 位发音人的句子音强走势均呈现为“峰-谷-峰”的双峰“M”形。 具体来说,在句子开始时,音强在一个较低的值,然后升高达到第一个峰,随后下降到某一值以后呈小幅的上下波动,波动将会持续一段时间。句子结束之前,音强会有一个较大幅度的回升,形成第二个峰值,最后句子结束时音强急促下降。 文献[13]中认为,句子的总体音强模式基本遵循从弱到强、再由强变弱的原则。 本文观察到的现象与之不同。 限于篇幅,本文仅列出F3 和M5 两位发音人的音强散点示意如图1 所示。
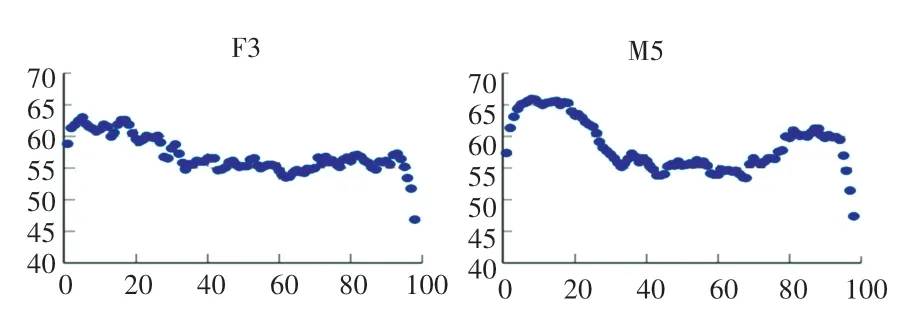
图1 SCS 语料音强散点示意图Fig.1 Scatterplot of SCS corpus sound intensity
10 位发音人的句子音强走势均呈现为“M”形,但在“峰”、“谷”之间的相对模式上各有不同。 例如,发音人M5 的“峰”与“谷”之间的差距较F3 更为明显。 总的来看,10 位发音人句子音强的变化模式存在共性。 将句子长度分为5 等分,前20%是句首音强上升段和第一个“峰”所在段,通常也是整个句子中出现音强最大值的阶段;20%~40%是第一个音强下降段(即“下降段”);40%~60%是“谷”,这一段中的音强呈小幅上下波动,具有稳态特征,可视为稳态段;60%~80%是第二个音强上升段(即“回升段”);最后的80%~100%是第二个“峰”,以及第二个音强下降段所在的阶段。 实际上这5 个阶段所对应的是句子语流的5 段时间,本文将其分别称做1、2、3、4 和5。 为了更清楚地描写句子音强的变化模式,从1、3 和5 中提取3 个音强参数进行分析。 在1 和5 中,分别提取出该段中的音强最大值1 和2;3 是音强稳态段,计算出该段中音强的均值。 由于10 位发音人的1 和2 可能出现在不同的位置,为便于比较,设定1 均出现在10的位置,2 出现在90的位置。的位置应该在3段中,但为便于计算,设定3 的起点(40处) 和末点(60处) 值均为,因而1、2 到之间的时间跨度均是句子总长的30。 利用1、2 和绘制出10 位发音人的音强下降与回升模式图,如图2 所示。
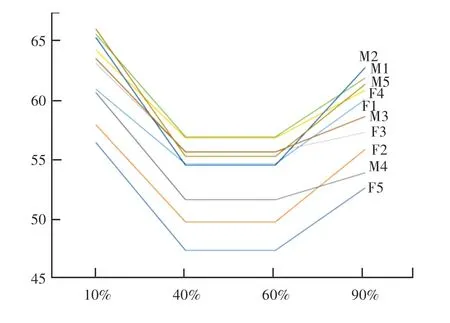
图2 SCS 语料10 位发音人句子音强的下降与回升模式Fig.2 Decline and recovery patterns of sentence intensity of 10 speakers in SCS corpus
由图2 可见,10 位发音人音强的下降、回升模式各有不同。 为量化这种音强的下降和回升模式,本文提出下降率和回升率两个参数进行分析。 音强下降率的计算公式是:1(1)30,音强回升率的计算公式是:2(2)30。1 和2代表下降的速率,其绝对值越大则速率越大。
表1 中分别列出了SCS 语料中10 位发音人音强的下降率、回升率及平均值。1 的最小值是-35.59,最大值是-20.81,均值是-28.22;2 的最小值是5.37,最大值是27.19,均值是15.49。 总体来看,汉语句子音强下降段的速率要大于回升段的速率,即句子在达到第一个峰值之后下降的速度大于由稳态段上升至第二个峰值的速度。 而且,从跨度来看,在10 位发音人之间,音强回升段的差异大于下降段的差异,即句子音强在达到第一个峰值之后较急促下降的情况,在发音人之间具有较高的一致性,而从稳态段上升到第二个峰值时人际差异较大,有的发音人较“急”(如2), 有的发音人则“不急”(如3)。 但是,尽管存在差异,还是有较明显的回升趋势。

表1 SCS 语料10 位发音人音强下降率与回升率Tab.1 Decline rate and recovery rate of sound intensity of 10 speakers in SCS corpus
2.2 句子音强变化模式的回归分析
上文主要介绍了汉语语句在句中的音强下降模式和回升模式,是将句首的上升和句末的下降两段排除在外的。 句首的上升段和句末的下降段在分析中的困难在于时间短,占比往往小于句子全长的10%,而且变化速率大。 该现象如图1 所示,首尾两段中相邻两个点位之间的间隔较大,正是由于变化速率较大,等距点位之间音强的差异较大。 因此,本文不再单独对句首段和句尾段进行分析,而是对整句做回归分析,以回归方程的形式对句子音强的变化模式进行数学表达。 回归分析是在统计软件SPSS26.0 中完成的,分为相关性分析、曲线估算和建立回归模型3 步。
在相关性分析中,将98 个点位() 按出现顺序(即句子语流的时间先后顺序)排列,将之与相应的音强进行相关性分析。 表2 中摘录了10 位发音人的斯皮尔曼(Spearman)相关分析结果。 可见,10位发音人的点位与音强之间都在0.01 水平相关性显著,并且均是负相关。 相关性最大的是4,最小的是2。 从相关性角度来讲,句子音强总体呈下倾趋势,音强随句子语流时间的前进而变小。

表2 SCS 语料音强与语流时间斯皮尔曼相关性Tab.2 Spearman correlation between sound intensity and flow time of SCS corpus
在满足点位与音强之间相关性显著的前提后,分别对10 位发音人的音强进行曲线估算。 根据曲线估算的结果,综合考虑、F 和显著性数值来看,10 位发音人的句子音强曲线与二次函数和三次函数拟合程度较高。 二者相比,三次函数在优度()上仅提升0.001 ~0.04 不等。 图3 是F3 和M5 两位发音人的二次函数和三次函数拟合曲线,可见二次函数和三次函数的拟合效果相差不大。 但二次函数在F 值上平均比三次函数大30 左右。 考虑到回归模型的简约性,适宜使用二次函数对10 位发音人的音强曲线进行拟合。
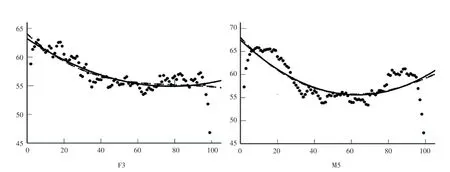
图3 F3 和MS 音强的二次函数(实线)和三次函数(点线)拟合曲线Fig.3 Fitting curve of quadratic function (solid line) and cubic function (dotted line) of sound intensity of F3 and MS
在选定二次函数作为回归曲线后,进一步求出10 位发音人的回归模型,模型参数见表3。 其中,表示非标准化系数,表示一次项,表示二次项,、值均在0001 水平上具有显著性。 二次函数中,二次项系数的正负决定曲线开口的朝向,系数为正则开口朝上;二次项系数的大小决定开口的大小,系数越大则开口越小,曲线越陡。代表模型的拟合优度,是回归分析的决定参数,用于表示自变量与因变量形成的散点与回归曲线的接近程度。 例如,F1句子音强曲线回归模型的等于0573,表明该回归模型能解释音强曲线中573的信息。 在10 位发言人句子音强的拟合优度中, 最大的是M3(753),最小的是M5(556),平均拟合优度为652。 总体来看,拟合情况在可接受的范围内。最终,根据系数和常数,可以得到音强曲线的回归模型。 例如F1 的音强曲线回归方程是:音强6081402090002。 限于篇幅,10 位发音人句子音强的回归方程不再逐个列出。
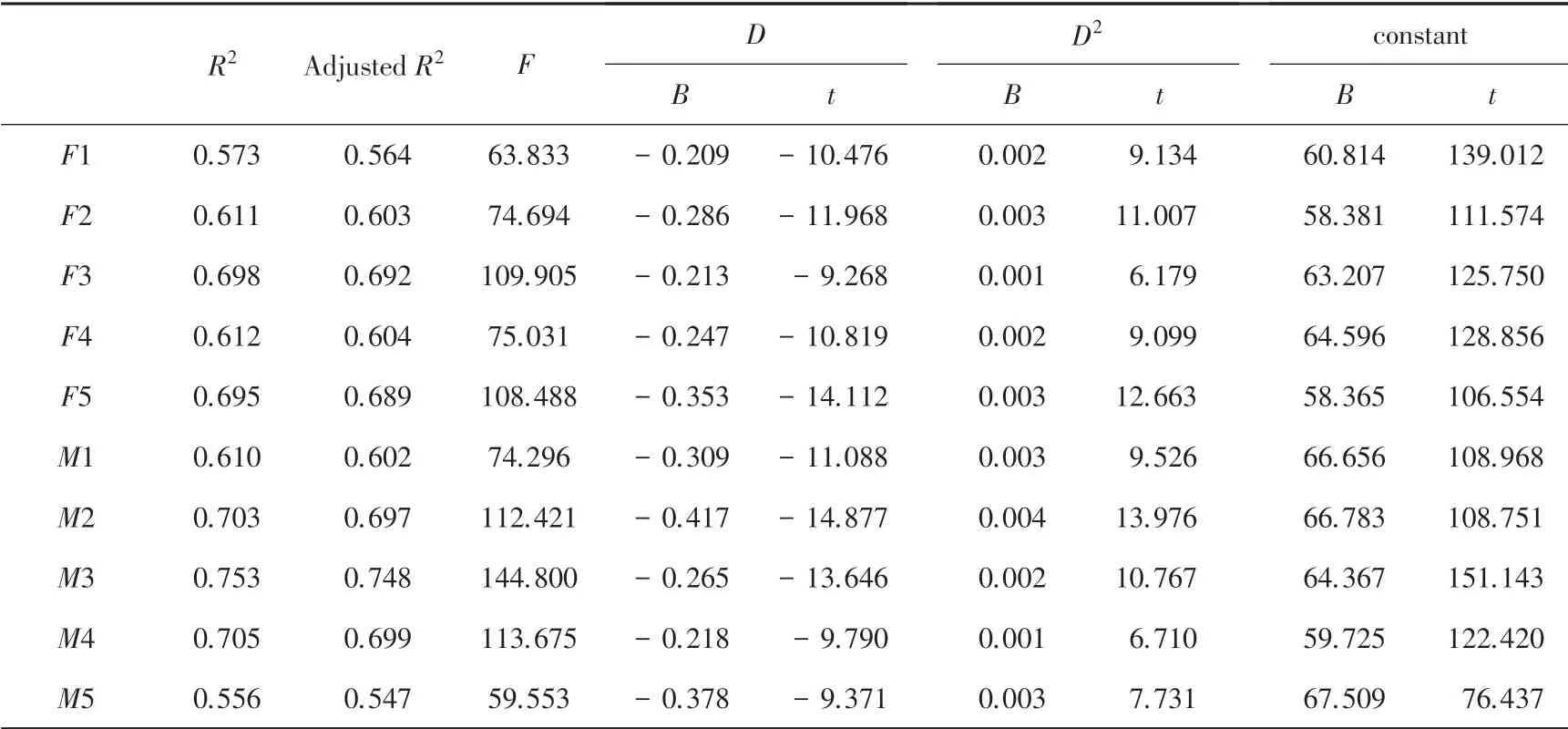
表3 SCS 语料10 位发音人回归模型摘录Tab.3 Excerpt of regression model of 10 speakers in SCS corpus
3 DBS 语料的音强变化模式
为便于比较,将SCS 语料中10 位发音人的音强数据合并后取均值,形成一组代表SCS 语料中10 人音强共性的音强数据,放在此处对比分析。
图4 左边为DBS 中10 000 句语料98 个点位的音强均值散点图,右边为SCS 语料1 千句语料98 个点位的音强均值散点图。 由图4 可见,由于DBS 语料句子数量庞大,散点分布较SCS 语料更为平滑;第一个峰值的位置更为明显且偏前,第二个峰值也非常明显且偏后。 DBS 语料在2 和4 阶段音强的下降和回升更为平缓,在3 阶段上语料的波动特征不如SCS 语料明显,且句中音强的最小值出现在50%左右。 此外,DBS 语料的音强较SCS 语料平均高出近10 dB(注意左右两图纵坐标标度不同),且非参数检验结果表明,这种差异在统计学上具有显著性(Mann-Whitney Test,0001)。
如图4 所示,前面句中音强的下降与回升模式仍然存在。 根据公式,计算出DBS 语料与SCS 语料的下降率(1) 与回升率(2),结果见表4。 可见,DBS 语料的1 和2 绝对值均大于SCS 语料,即DBS 语料句中的下降与回升速度均比SCS 语料大。
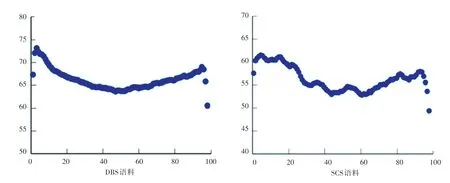
图4 DBS 语料与SCS 语料音强均值散点图Fig.4 Scatterplot of mean sound intensity of DBS corpus and SCS corpus

表4 DBS 语料与SCS 语料下降率与回升率Tab.4 Decline rate and recovery rate of DBS corpus and SCS corpus
DBS 语料与SCS 语料的点位与音强之间的斯皮尔曼相关性见表5。 二者都呈负相关关系。 DBS语料的点位与音强之间的相关系数绝对值比SCS语料小,甚至比最小的2 还要小(见表2)。 这说明DBS 语料的音强与句子语流时间的关系存在负相关,但是相关性比较弱。
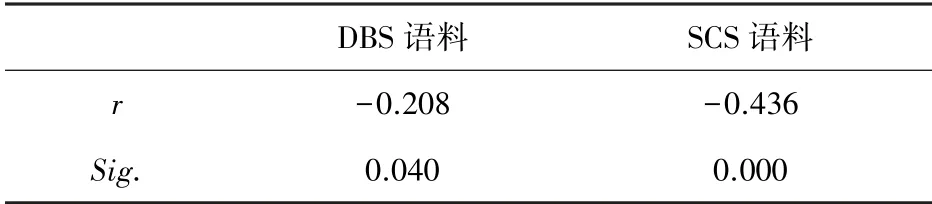
表5 DBS 语料与SCS 语料点位与音强之间斯皮尔曼相关性Tab.5 Spearman correlation between point position and sound intensity of DBS corpus and SCS corpus
综合考虑散点的分布情况以及曲线估算的结果,仍然选用二次函数对DBS 语料和SCS 语料进行曲线拟合。 回归模型参数摘录见表6。 DBS 语料的拟合优度达到74%,比SCS 语料高出4.2%左右,DBS 语料句子音强曲线较SCS 语料更接近二次函数。 此外,SCS 语料的优度也要比第3 节中10 人的平均拟合优度更高一些。

表6 DBS 语料与SCS 语料回归模型摘录Tab.6 Excerpt of regression model of DBS corpus and SCS corpus
4 讨 论
4.1 句子音强变化模式的共性与个性
本文对SCS 语料10 位发音人100 个普通话语句进行了重点分析,同时使用DBS 语料进行了辅助分析。 结果显示,汉语普通话句子音强变化模式存在一定共性。 首先,SCS 语料10 位发音人的句子音强模式均呈现为双峰“M”形,“峰”与“谷”之间有着明显的区别;两个“峰”之间的相对关系非常稳定,即第一个峰值总是大于第二个峰值。 DBS 语料同样符合以上特点,且散点分布更加平滑。 其次,本文通过对句中下降率与回升率的分析看到,下降率绝对值皆大于回升率绝对值,即句中的音强下降速度要大于回升速度。 此外,在句子音强曲线的拟合方面,汉语普通话句子音强能被二次函数较好拟合,SCS语料10 位发音人的拟合优度均在50%以上,其中8人在60%以上,有的甚至达到了75%以上;DBS 语料音强曲线拟合优度也高达74%。 值得注意的是,较大容量的DBS 语料不论是在句中下降率与回升率,还是在二次函数的拟合优度上,都比对10 位发音人音强均值分析得出的数据更加理想,即1 万句样本的DBS 语料要比1 千句的SCS 语料的分析结果更好。 由此可见,样本量越大则越能体现出句子音强模式的共性。
除共性外,句子音强在下降与回升模式以及整个音强曲线的回归模型上也具有一定的个体差异:
(1)在句中下降率与回升率上,虽然下降速度快于回升速度,但发音人之间的缓急程度不一;
(2)在T3 阶段不同发音人的音强均值也不同;
(3)10 人的二次函数拟合优度具有差异,有的发音人句子音强曲线更接近二次函数,而有的发音人的拟合情况则稍差。
以上现象表明,受发音人发音时的状态和日常说话的音量大小影响,句子音强变化模式具有一定的个体差异。 尽管如此,本文句子音强变化模式的共性大于个性。
4.2 双峰“M”形音强走势与呼吸特征
音强的变化与说话时气息的强弱有密切的关系,气息越强则声音强度越大,气息越弱则声音强度越小。 文献[14]中提出,言语时的呼吸已经超越了生理需求的层面,其随着言语任务的不同而受上位语言系统的调节。 本文提出的双峰“M”形音强走势,能从已有的关于言语呼吸机制的研究中得到印证。 文献[15]的研究表明,胸呼吸的主要作用是保证足够的气息量,腹呼吸的主要作用是控制气流持续释放,以获得连续的语音,句子的起始处对应一个胸呼吸和腹呼吸的重置。 通过观察文献[15]中报道的呼吸信号图可见,在发音之前有一个大幅的吸气动作,紧随其后的是一个较大速率的呼气信号,随后是较平缓的呼气信号(尤其是胸呼吸),在句末时胸呼吸和腹呼吸的信号都下降到最低值,为下一个呼吸重置做准备,且小句中的停顿处通常也会有较小的呼吸重置。 这与本文的双峰“M”形音强曲线相符,两个峰正好对应呼气信号速率较大的阶段,该阶段呼出气息较快,声音强度相应较大。
4.3 音强回升与自然焦点的后置
文献[16]中指出,汉语信息的编码往往遵循从旧到新的原则,越靠近句末,信息内容就越新。 文献[17]也认为,说话人有意让自己想突出的成分占据自然焦点即句末的位置,并举例说明了汉语尾焦点的特点。 文献[18]中引介了“线性增量”原则,说明在没有干扰因素的情况下,随着句子由左向右移动,句子成分负载的意义越来越重要。 可见,汉语句末是自然焦点的重要句法位置。 文献[12]的研究表明,从焦点词本身的音量凸显程度上看,句中、句首、句末3 种焦点位置上,信息焦点均明显大。 尽管其文献中所说的信息焦点与自然焦点在定义上有些不同,但焦点在音量上的凸显程度较高这一现象值得关注。 本文使用的语料都是单独的句子,句子焦点多是无标记的自然焦点,占据句尾的位置,这可能也是造成第二个音强峰值的原因。
4.4 实验句与日常语料的音强模式
文献[12]在讨论汉语信息焦点和对比焦点区分的语调证据时,使用了“李超每夜点炸鸡”等句子进行实验。 实验结果显示,音节的音强大小,随焦点位置的变化而变化(对照组没有明显变化)。 这与本文提出的双峰“M”形变化模式不同,除焦点确实起作用外,或有另外原因:
(1)因为文献中使用的句子较短,只有7 个音节,而本文中使用的SCS 语料音节数目平均在14 个以上,句子更长,句子音强变化模式更丰富;
(2)更为重要的是,文献中使用的实验句,与本文中的日常语句有较大区别。 本文的目的在于探究汉语普通话句子音强变化的普遍模式,发音人在录音时不知晓实验目的,完全根据语感和语境发音,这与具有专门目的的实验语料有着本质上的不同。
4.5 句子音节数与音强变化模式
本文中SCS 语料的句子音节数目由7 ~32 个不等,没有严格控制音节数或者进行分组分析,这和本文的研究目的有关。 汉语的日常会话中,句子总是有长有短,但一般长度到底是多少,目前还少有研究成果可以参考。 句子太短则体现不出句子音强的变化模式,句子太长则容易脱离实际,所以使用音节数量多样的语料是一个折中的选择。 本文使用的音强提取脚本是等距提取100 点的音强,不论句子音节数量多少,都是依据时间顺序提取100 个音强数据,这实际上对句子的时长做了归一化处理。 但是,在求出句子音强的普遍模式后,根据音节数目对汉语句子进行分类,再细致探究其音强变化模式,至少对确定出于专门目的而设计的实验句的音节上限,具有重要的参考意义。
此外,句子由音节组成,句子的音强也是由每个音节的音强组成的。 但句子整体的音强并非内部音节音强的简单加和。 音节的音强在句子里会受到句子音强变化模式的制约。 由此可以得到启示,出于专门目的的实验句不宜太长,否则难以摆脱句子音强变化模式的影响。
4.6 句类与音强变化模式
虽然句类也会对句子音强的变化模式产生一定的影响,但目前研究汉语口语中各句类占比情况的成果比较少见。 因此,本文统计了文献[19-21]研究中的语料数目。 这些语料都是短视频、广告、口语教材中的语料,可以作为汉语日常使用句类占比的参考。 统计结果显示,陈述句占45.2%,疑问句占13.6%,感叹句占23.3%,祈使句占18%。 两相对比,本文中陈述句、感叹句和祈使句的占比偏少,疑问句的占比偏高。 在SCS 语料中,陈述句、疑问句、感叹句和祈使句的占比分别为40%、38%、11%和11%,这个比例大致接近汉语日常使用的比例,基本满足本文探求句子音强普遍变化模式的条件。 此外,文献[11]的研究表明,音强受生理因素的影响,句子音强以词为界递减,但疑问句的音强整体大于陈述句,且句末音强有回升趋势。 本文中疑问句的占比偏高,可能会对研究结果产生一定的影响。 但应该看到,在DBS 语料中有91%以上是陈述句,然而不论是句中的下降率、回升率,还是二次函数的拟合优度都要比SCS 语料更高。 由此,疑问句音强有句末回升趋势未能影响本文对句子音强的分析结果,其他句类的音强也有句末回升趋势。 如要进一步明确句类对句子音强模式的影响,仍需做进一步的研究。 文献[23-24]的研究表明,不同情感在句子的音强模式上也有不同的表现。 由于本文语料在实验室中录制,发音人发音时情感稳定,因此未做情感方面的分析。
5 结束语
本文旨在探究汉语普通话句子音强变化的普遍模式。 通过分析较小样本的SCS 语料与较大样本的DBS 语料看到,普通话句子音强曲线呈双峰“M”形,音强最高点通常出现在句子长度的前20%,音强的次高点通常出现在80%~100%,音强在40%~60%阶段上下波动,具有稳态特征,而20%~40%和60%~80%段通常是音强的下降段和回升段。 通过计算句中音强的下降率和回升率看到,10 位发音人之间具有一定的个体差异,但下降速度总是大于回升速度。 此外,二次函数能够较好地对句子音强变化模式进行拟合,且样本量越大拟合优度越好。 至于句末音强回升的原因,可以从话语中的呼吸特征以及汉语句子自然焦点的后置等方面得到一定的解释,但深层次的原因还有待进一步研究。
猜你喜欢
考试与评价·七年级版(2020年6期)2020-11-02
电脑知识与技术(2019年23期)2019-11-03
快乐作文(1.2年级)(2019年9期)2019-09-10
安徽文学·下半月(2017年9期)2018-02-03
作文周刊·小学一年级版(2018年32期)2018-01-15
科学与财富(2016年30期)2017-03-31
小学生时代·大嘴英语(2015年12期)2016-01-07
小学生时代·大嘴英语(2014年11期)2014-12-04
小学生时代·大嘴英语(2014年1期)2014-02-28
教学与管理(理论版)(2009年9期)2009-11-04
