
两种机器学习方法在重庆夏季旱涝预测中的应用
2022-06-01 04:11董新宁向波周杰李永华曾春芬
气象科学 2022年1期
董新宁 向波 周杰 李永华 曾春芬
(1 重庆市气候中心,重庆 401147;2 重庆师范大学地理与旅游学院,重庆 401331)
引 言
夏季旱涝是最受关注的气象灾害之一,国内外许多气象专家、学者围绕“气候系统”各成员的变化及其相互作用对夏季旱涝的影响做了大量有意义的研究工作。谭桂容等[1]、谢坤等[2]、史印山等[3]对华北夏季环流、旱涝特征及水汽输送特征进行了分析。关于重庆及其周边地区的夏季旱涝变化特征及其成因、预测方法也有一些研究。李永华等[4-6]、刘德等[7]等分析了西南地区东部夏季降水及旱涝的变化特征,指出其具有明显的年际和年代际变化特征。周毅等[8]对三峡库区夏季降水基本气候特征进行了研究。结果表明:三峡库区夏季降水一致性较好,旱年出现的频率明显高于涝年,三峡库区夏季降水存在明显的年代际变化特征。马振锋[9]从业务预报角度,对影响西南地区夏季降水的主要物理因子,如高原因子、西风带系统、副热带高压等因素进行了分析,在此基础上建立了具有一定物理基础的夏季降水预测模型,在近年来汛期降水预测中取得了较好的效果。张强等[10]对SST指数与长江上游旱涝灾害相关分析表明,El Nio事件的发生使长江上游发生旱灾机率增大,而La Nia事件的发生则使长江上游发生涝灾的机率增大。刘德等[11]对重庆地区夏季旱涝的欧亚环流特征进行了分析,建立了利用前期冬季关键区环流指数预报重庆夏季降水的概念模型。
近年来人工智能技术也开始应用于强对流天气预报和气候预测等大气科学领域。机器学习在强对流天气预报方面的应用相对比较多:2017年深圳市气象局和阿里巴巴联合承办了以“智慧城市,智慧型国家”为主题的CIKM数据科学竞赛,主要是利用雷达图像进行了短时降水预报;修媛媛等[12]用机器学习中有监督学习模型支持向量机SVM来进行强对流天气的识别和预报,提高了强对流天气识别的准确度。孙全德等[13]基于机器学习的数值天气预报风速订正研究,显示了机器学习方法在改善局地精准气象预报方面的潜力。李文娟等[14]进行了基于数值预报和随机森林算法的强对流天气分类预报技术研究,研究表明,随机森林算法筛选的因子物理意义较为明确。和主观预报经验基本相符,模型准确率高,可用于日常业务。在气候领域,在过去几年,研究人员已经利用人工智能系统帮助他们排列气候模型[15],在现实和模拟气候数据中发现飓风以及其他极端天气事件,从而找到新的气候模式。Rasp,et al[16]基于机器学习所做的对流参数化新方法,在装置中训练深度神经网络,使其在一个明确代表云层的模拟中进行学习,该算法称为“云脑”(CBRAIN),这种新方法能够有效地预测对气候模拟至关重要的云层变暖、湿润以及散热等特征。此外,McGinnis, et al[17]研究了一种新的气候模型偏差校正分布映射技术。Greene, et al[18]结合GLM-NHMM方法,提出了基于站网日降水量预测的的降尺度贝叶斯方法,方法具备相当大的灵活性。
上述的研究尤其是预测研究基本上考虑的都是单一系统或者物理因子对重庆及周边地区旱涝的影响,单一因子作用在极端异常年份可能较为显著,当因子处于正常状态时,预测往往失效。实际上,由于气候系统的非线性和混沌性,影响旱涝预测的因素必定是诸多海温(ENSO、黑潮等)、高原积雪、陆面温度、火山活动、天文因子、季风、副高、阻高、高原大地形等综合作用的结果。如果能够通过大数据的梳理统计、分析处理、机器学习等方法手段,在导致旱涝变化的这些众多因子中,分析这些因子的协同作用,分辨出哪些因子是优秀预报因子,以及在不同的区域这些优秀因子所占的权重,即这些因子究竟能提供多大程度的预报信息,那么旱涝预测将变为可能而且可信。决策树模型作为机器学习算法的优秀代表,它采用递归分割技术,将数据空间不断划分为不同子集,进而探测出数据的潜在结构、重要模式和关系。与传统的参数统计方法相比,决策树模型无需提前对自变量和因变量的关系进行假设,且能有效克服自变量的多重共线性。目前,决策树和随机森林算法在气象上的应用越来越广泛。史达伟等[19]利用决策树算法对道路结冰灾害建立了较为准确的分类与预测模型;秦鹏程等[20]基于决策树和随机森林模型的湖北油菜产量限制因子分析也取得良好的应用。本文从实际预测业务出发,针对重庆区域平均的夏季降水,采用决策树分类方法建立多因子协同影响的旱涝预测模型,并在决策树建模的基础上采用随机森林进行集成预测试验并检验评估其预测效果。
1 资料和方法
1.1 资料
本文采用的气象资料通过中国气象局CIMISS气象数据统一服务接口(MUSIC:Meteorological Unified Service Interface Community)取得。决策树研究时采用重庆市34个国家气象观测站(图1)的区域平均降水量进行研究,随机森林对34个国家气象观测站的降水量进行分析。
本文环流指数来自中国气象局业务气象内网(http:∥10.1.64.154/portal/web-link.index?inid=1001),包括大气环流指数88项、海温指数26项及其他指数16项,合计130项。本文中使用的海温指数包括26项海温指数以及16项其他指数中的多变量ENSO指数、北太平洋年代际振荡指数、大西洋经向模海温指数、准两年振荡指数、赤道太平洋130°E~80°W范围次表层海温指数、赤道太平洋160°E~80°W范围次表层海温指数、赤道太平洋次表层海温指数、大西洋海温三极子指数。对指数序列先进行标准化再参与建立模型,以消除指数单位带来的权重影响。基于季节预报的可预测性,本文在建立预测模型时倾向于选取海温指数,主要是由于海温是季节大气环流的稳定外强迫,同时它们又具有较明确物理影响机制[21-31]。
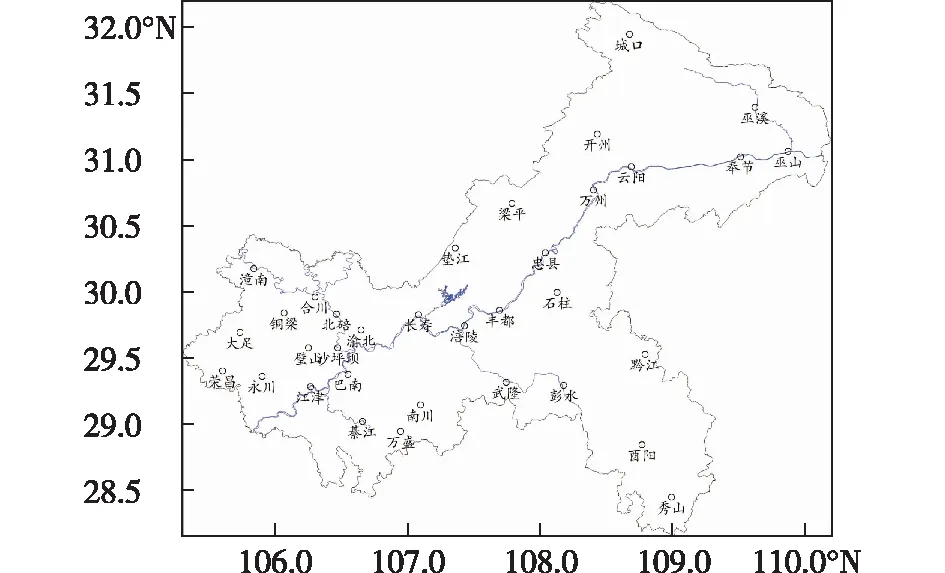
图1 重庆地区34个国家气象观测站分布Fig.1 Distribution of 34 national meteorologicalstations in Chongqing
1.2 方法
本文所采用的机器学习算法包括决策树(史达伟等[19],秦鹏程等[20],王伟等[32])、随机森林(Breiman[33];吴晶等[34],徐彬仁等[35])。评估方法为一致率评分、趋势异常综合评分和相关系数(刘一鸣等[36],白慧等[37])。 文中建模时段为1961—2010年,独立检验评估时段为2011—2018年。
1.2.1 决策树
决策树是归纳学习和数据挖掘的重要方法,通常用来形成分类器和预测模型。杨学兵等[38]介绍了决策树基本概念及常用算法。假设给定数据集D={(x_1,y_1 ),(x_2,y_2 ),…,(x_n,y_n)},其中x_i=[([x_i]^((1) ),[x_i]^((2) ),…,[x_i]^((n) ))]^T为输入变量(即环流指数),n为特征个数(文中夏季模型为130,冬季模型为34),y_i∈{1,2,…,K}为类别型响应变量(即降水多少),i=1,2,…,N,N为样本容量(取1961—2018年,计58 a)。其中,1961—2010年为训练数据集、完成模型训练,2011—2018年为独立测试数据集、进行独立检验评估。决策树学习的目标是根据给定的训练集构建一个决策树模型,使它能够对实例进行正确的分类。本文决策树生成采用的是Quinlan[39]的C4.5算法。由于每个站都可以使用决策树方法进行应用,但是这样会造成过多的分支,后期分析时有太多干扰的“噪声”。一个区域的平均降水量虽然无法描述每个测站的细微差异性,但是在季节尺度上,区域平均降水量完全可以代表该地区的降水情况,特别是小区域(例如:重庆区域)的代表性则更好。因此,本文使用决策树方法时,采用重庆区域平均降水量作为研究分析对象。
1.2.2 随机森林
随机森林(Random Forest,RF)是一种多功能的机器学习算法,由美国加州大学伯克利分校统计学教授Breiman[33]首次提出。它的基本组成是Breiman发明的分类和回归树(Classification and Regression tree,CART),对比神经网络等机器学习算法,这种通过反复二分数据进行分类和回归的算法有效降低了计算量,而随机森林正是对这些分类树的组合和再汇总。随机森林在计算量没有显著提高的前提下提高了估算精度,而且它对缺失值和多元共线性不敏感,可以估算多达几千个解释变量,被誉为当前最好的算法之一(Iverson, et al[40])。
随机森林采用Bagging的方法组合决策树,即利用Bootstrap重抽样方法(自举法)从原始样本中抽取N个样本进行决策树的建模,一般情况下,随机森林会随机生成几百至几千个决策树,森林中的每棵树都是独立的,然后选择重复程度最高的树作为最终的结果。由于不需要考虑变量的分布条件、交互作用、非线性作用,甚至缺失值等约束,因此,虽然随机森林的结构复杂,但却表现稳健,容易使用。
随机森林的具体构造过程如下:
(1)如果训练集大小为N(本文取值为50,即1961—2010年),对于每棵树而言,随机且有放回地从训练集中抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
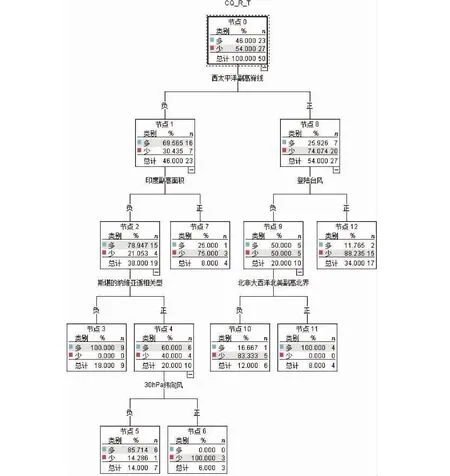
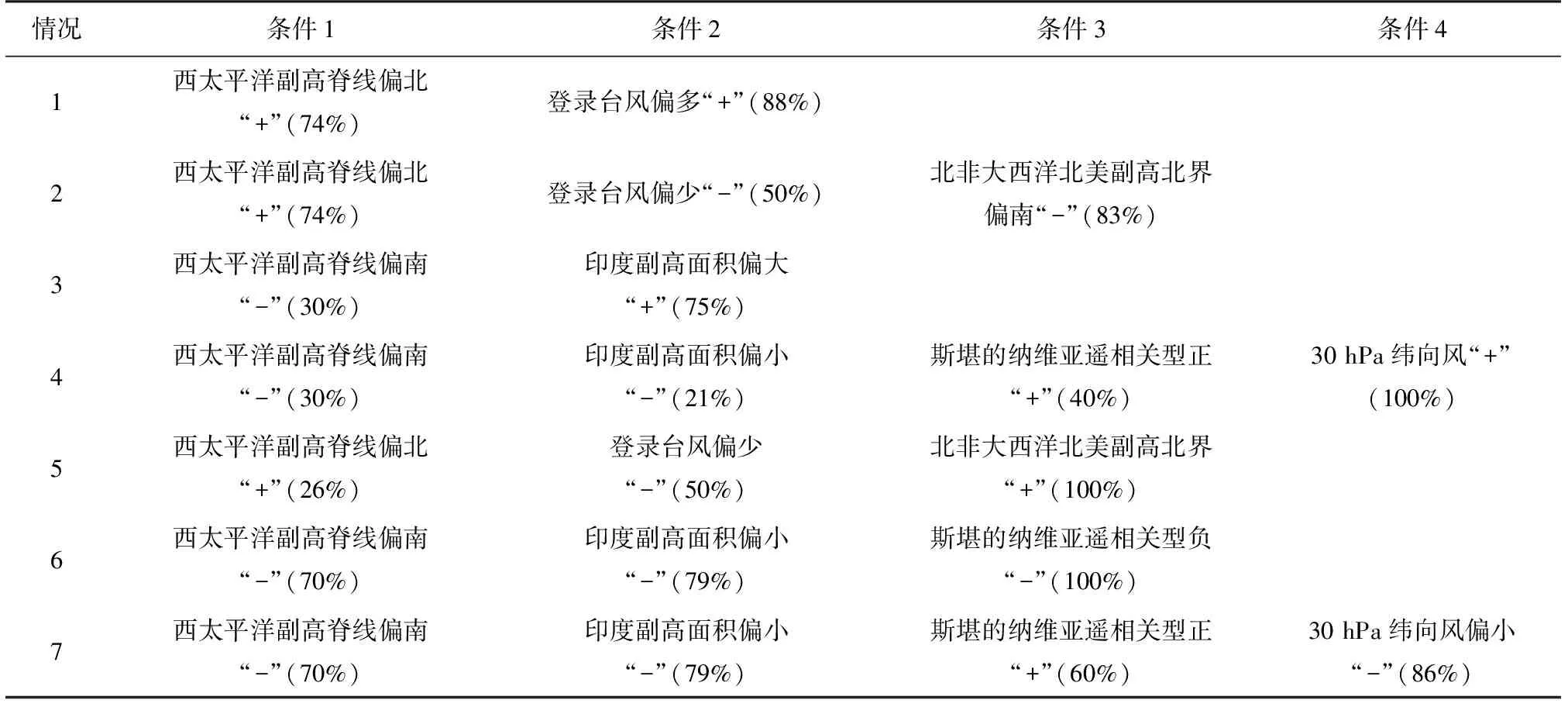
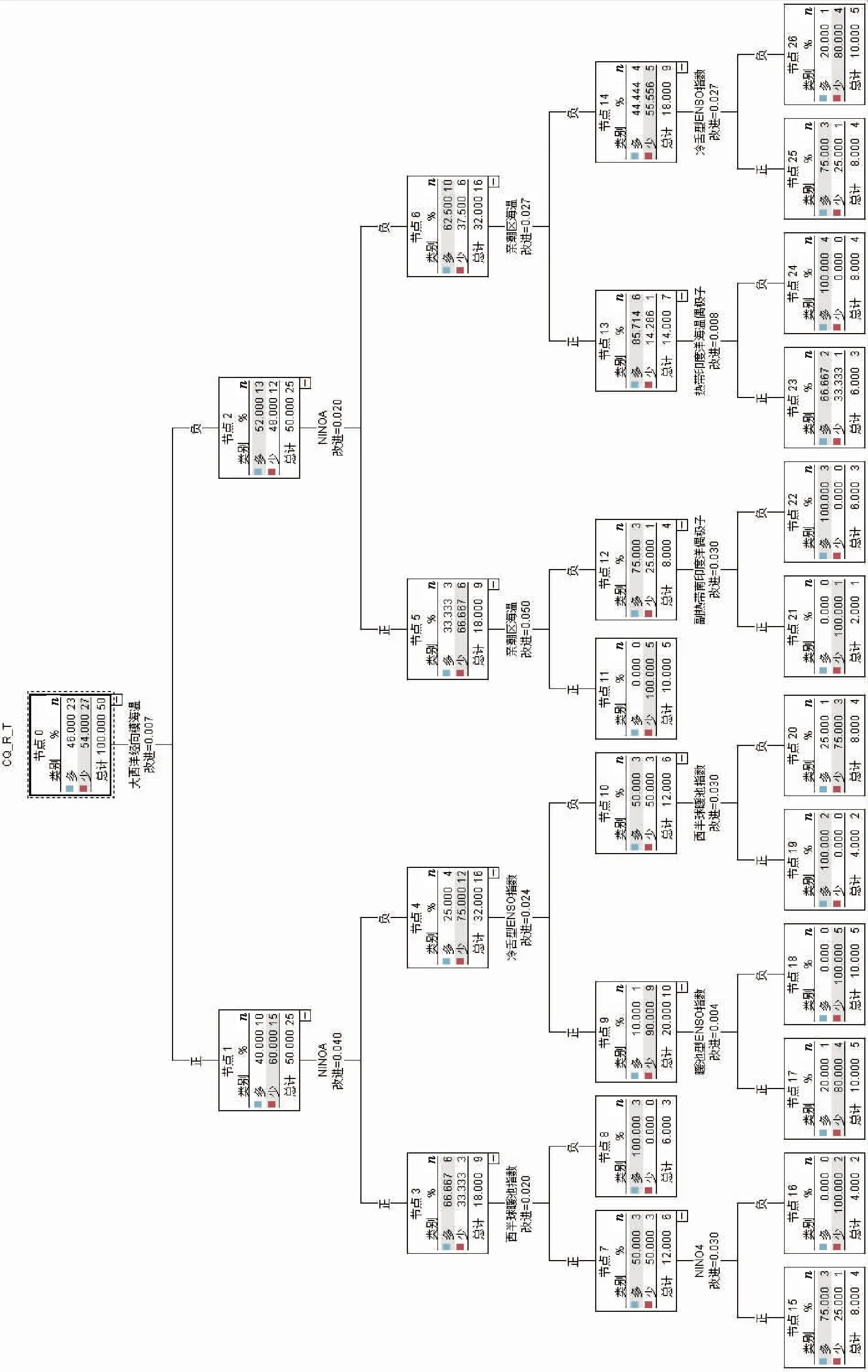
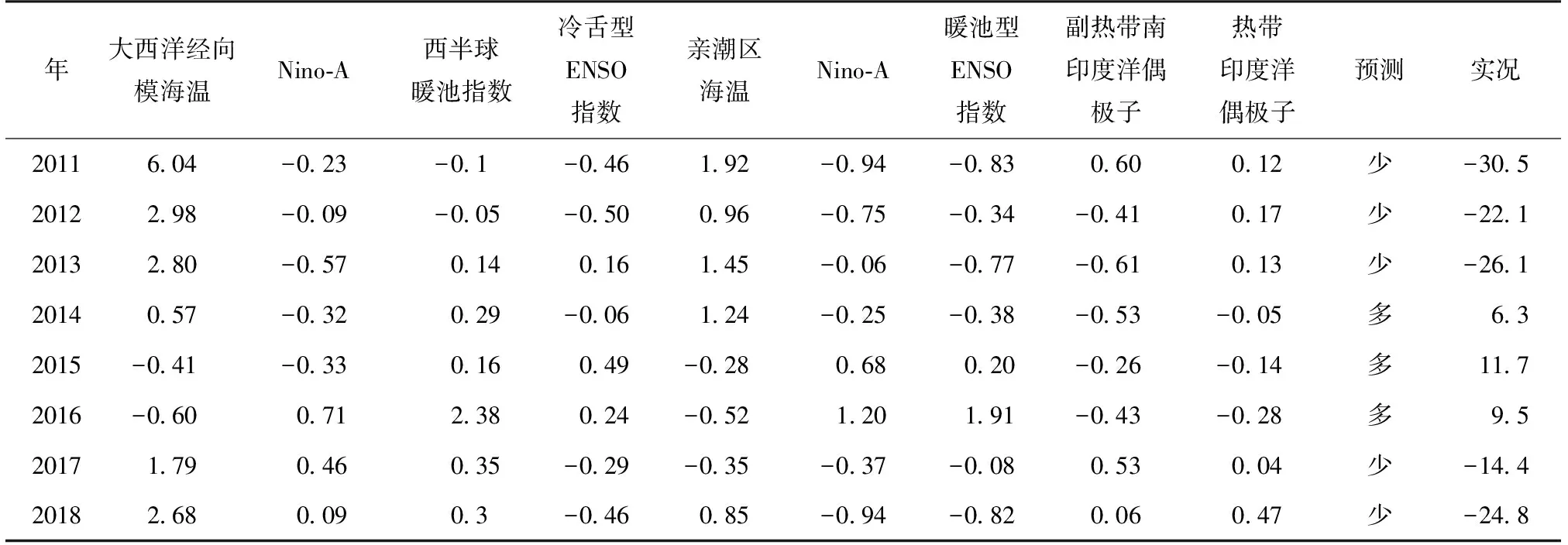
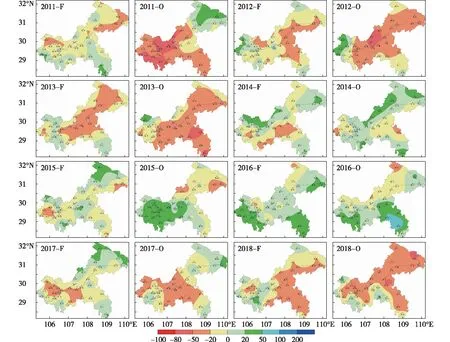
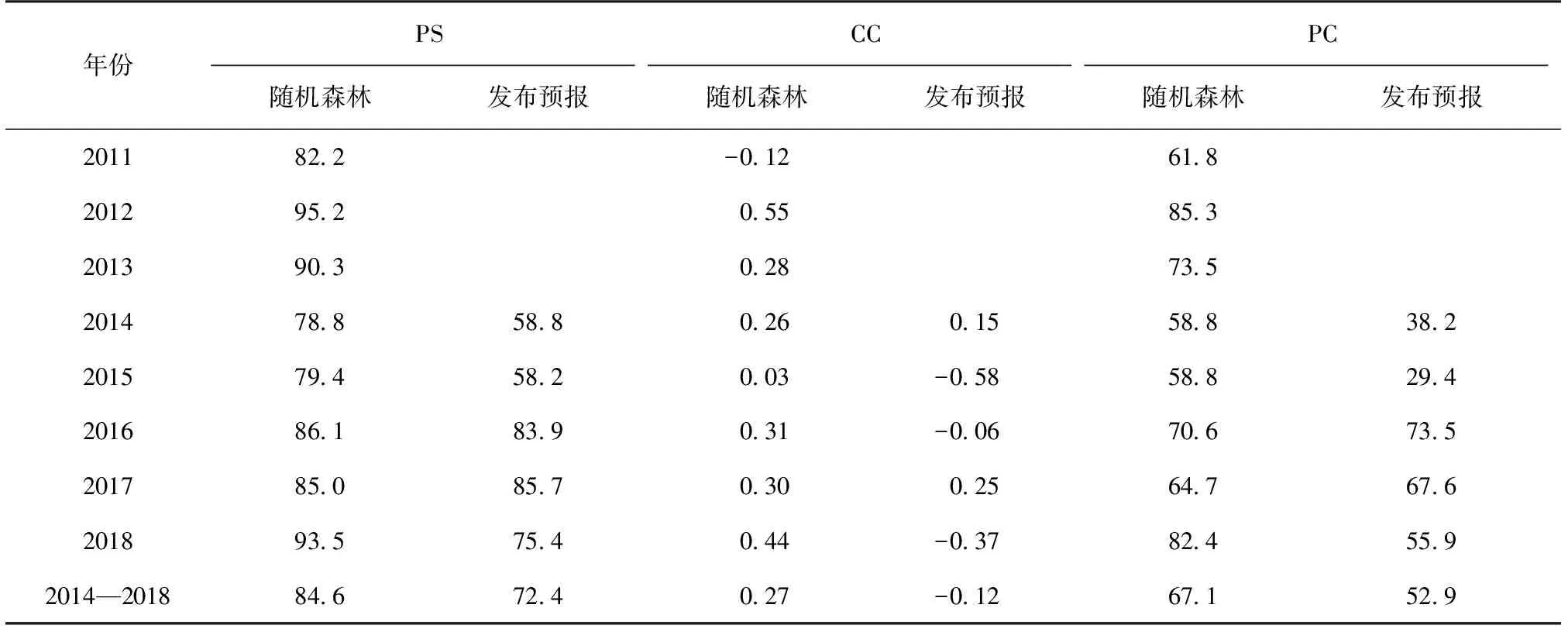
(2)如果每个样本的特征维度为M,指定一个常数m< (3)每棵树都尽最大程度的生长,并且没有剪枝过程; (4)按照步骤(1)—(3)建立大量的决策树,这样就构成了随机森林,分类结果按树分类器的投票多少而定。 构建随机森林的过程中有两个参数需要使用者视具体情况而设置,大多数情况下,模型的默认参数即可得出最优模拟结果,无需进行调整。随机森林中的“随机”就是指的这里的两个随机性参数。这两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好的抗噪能力。因此本文所建立的估算降水的随机森林模型均使用默认的参数。 1.2.3 检验方法 本文选用中国气象局气候预测质量评定中常用的一致率评分(Prediction Consistency, PC)、趋势异常综合评分(Prediction Score,PS)和相关系数(CC)3种指标,检验随机森林对重庆夏季降水的预测回报结果,进行定量评估分析。 (1)一致率评分(PC)以预测和实况的距平符号是否一致为判断依据,采用逐站进行评判。定义如下: (1) 式中:N0为气候趋势预测正确的站数;N为实际参加评估站数。 (2)趋势异常综合评分(PS)检验方法是针对气候趋势预测和异常级预测结果设不同权重来综合进行检验评分的方法。其检验评分比较直观,在趋势预测正确得分的基础上,仍可获得异常预测正确分,相当于对预测异常给予鼓励,其预测评分能相对反映气候预测能力和水平。 趋势预测即为预测对象距平/距平百分率正负符号的预测。当预测与实况的符号相同(0代表正)时,表示趋势预测正确。异常级预测是指对降水距平百分率超过(包含)±20%,气温距平超过(包含)±1℃的预测。 PS检验方法的计算公式: , (2) 其中:N0为气候趋势预测正确的站数;N1为一级异常预测正确的站数;N2为二级异常预测正确的站数;N为实际参加评估站数;M为没有预报二级异常而实况出现降水距平百分率≥100%或等于-100%、气温距平≥3 ℃或≤-3 ℃的站数;a、b和c分别为气候趋势项、一级异常项和二级异常项的权重系数,本办法分别取a=1,b=2,c=4。 (3)相关系数检验方法(CC)对气候趋势预测产品的相关性进行检验,其表征了预报场和实况场的相关程度,其相关系数的大小能表征预报场与实况场的高低中心的对应好坏,一定程度上反映了预测结果的准确率和预测方法的好坏,是国际通行的预测评估方法之一。对降水、气温的预测检验评估主要使用降水距平百分率和平均气温距平计算其相关系数。 具体计算方法: (3) 文中的发布预报是指重庆市气候中心参与中国气象局气候预测质量考核的预报。 考虑夏季同期的物理因子情况,使用IBM SPSS Modeler 18.0,并采用CART算法(下同)建模(图3),从模型看出,对重庆夏季降水影响较大的环流指数包含西太平洋副高脊线、登录台风、亲潮区海温、北非大西洋北美副高北界、大西洋欧洲区极涡强度、印度副高面积和30 hPa纬向风,上述多因子如何协同影响重庆夏季降水如图2。 基于CART算法的重庆夏季降水趋势与同期环流指数模型的组合情况如表1,降水偏少的因子组合有情况1~4,降水偏多的因子组合有情况5~7,“+”和“-”分别表示条件中指数的正负距平,括号中的百分位数是偏少(多)的概率。 利用2011—2018年的同期指数来预测重庆夏季降水的多寡,并与观测实况进行对比,结果如表2所示。 图2 基于CART算法的重庆夏季降水趋势与夏季环流指数间的关系(类别多、少表示偏多、偏少;%数字表示偏多、偏少的概率;n数字表示偏多或偏少的年份数;指数名称为该节点所采用的指数。下同)Fig.2 An analytic diagram of the relationship between precipitation trend and circulation index in summer in Chongqing based on CART algorithm(Type “more” or “less” means more or less precipitation in Chonging; value with % indicates the probability of more or less;n means the number of years with more or less; the index is the adopted one by the node, the same below) 表1 基于CART算法的重庆夏季降水趋势与同期环流指数模型的组合情况Table 1 The combination of summer precipitation trend and circulation index model based on CART algorithm in Chongqing 如果预测只考虑单因子作用,西太平洋副热带高压(简称西太副高)脊线偏北(南)一般对应重庆夏季降水偏少(多),仅以此预测,2011、2012、2015和2018年西太副高脊线偏北对应降水偏少,2015年结果不吻合;2013、2014、2016和2017年西太平洋副高脊线偏南对应降水偏多,实际上只有2014年和2017年偏多。合计预测准确率为62.5%(5/8)。由此可以看到考虑多个因子共同作用的预测准确率高于仅考虑单因子的预测准确率。 考虑多因子协同作用时,即使西太副高偏南,也可能出现降水偏少的情况,如情况(3)。在实际预测中2011和2012年完全符合情况(1),降水距平百分率分别为-30.5%和-22.1%,显著偏少。2013年的降水距平百分率为-26.1%,结果与情况(3)一致,如果仅满足情况(3)的前2个条件,降水偏少的概率仅为50%,2013年30 hPa纬向风显著偏大,使降水偏少的概率增加到100%。同样,在多因子协同预测时,无论西太平洋副高脊线偏北或偏南都可能出现降水偏多的情况,如情况(5)和情况(6)所示。2014年的环流指数与情况(6)的结果一致,降水偏多的概率为100%,实际降水距平百分率为6.3%,正常偏多。2015年的环流指数与情况(5)的结果一致,降水偏多的概率为100%,实际降水距平百分率11.7%。2016年的环流指数与情况(3)一致,预测降水偏少,但实际情况是降水偏多9.5%。2016年是典型的El Nio年,太平洋海温异常导致大气系统的异常可能是2016年预测模型失效的可能原因。 图3 基于CART算法的重庆夏季降水趋势与前冬海温指数间的关系Fig.3 Relationship between precipitation trend in summer and SST index in pre-winter based on CART algorithm in Chongqing 表2 2011—2018年不同环流指数距平值、降水预测值与实况对比Table 2 Different circulation index anomaly, precipitation prediction value and observation from 2011 to 2018 表3 基于CART算法的重庆夏季降水趋势与前冬海温指数模型的组合情况Table 3 The combination of summer precipitation trend and pre-winter SST model based on CART algorithm in Chongqing 从2011—2018年的预测效果检验来看,多因子协同作用的预测准确率达到87.5%,较考虑单一因子提高25%。鉴于同期因子的分析更多应用于诊断分析,而从预测的实际情况考虑,同前面的方法,选取前冬海温指数建模(图3)用于预测业务。 基于CART算法的重庆夏季降水趋势与冬海温指数模型的组合情况如表3,模型中,降水偏少、偏多的情况各有6种。 利用2011—2018年重庆夏季降水观测实况对模型进行检验,结果如表4所示。模型中如果考虑相关性最高的大西洋经向模海温,偏高则重庆地区降水偏少,偏低则重庆地区降水偏多。除2014年外,其余年份趋势预测正确。若考虑不同的组合情况,2011—2014年大西洋经向模海温偏高、Nino-A偏低, 表4 2011—2018年基于前冬海温指数决策树模型预测重庆夏季降水效果检验表Table 4 Test table for predicting summer precipitation effect from 2011 to 2018 based on the pre-winter SST index decision tree model in Chongqing 图4 基于随机森林的重庆夏季降水预测及观测实况分布图:F表示预测;O表示观测实况Fig.4 Forecast and observation distribution of summer precipitation in Chongqing based on random forest: F means forcasting and O for observation 2013年冷舌型ENSO指数偏小,与情况(1)一致,预测降水偏少,其余3 a的不同在于西半球暖池指数的差异,2011、2012年与情况(2)一致,预测降水偏少,2014年与情况(7)一致,预测降水偏多。2015、2016年海温指数的信号和情况(10)一致,预测降水偏多。2017、2018年则与情况(3)吻合,预测降水偏少。从检验来看,考虑多因子协同的情况下,2011—2018年8 a降水趋势预测均正确,相对只考虑单一因子的情况下提高12.5%。 以上考虑采用决策树方法考虑多因子协同作用时,对重庆夏季旱涝建模预测,虽然无法实现定量化的预测,但试验表明无论采用前期还是同期因子进行预测诊断分析,都比考虑单一指数有明显的预测提升。这也表明,“气候系统”作为一个复杂的系统,是多重因子、多个系统相互影响共同作用的结果,在预测过程中,我们不但需要分别分析系统中各个部分的特征与循环,也必须研究整个系统的集成行为及各分系统的相互作用。这个过程需要对海洋、大气等大量的资料以及各种模式预测资料进行统计分析,以期得到影响本地气候的关键性因子、不同环流场的关键性区域、以及指数和环流影响本地的关键性时段。在气候系统变化的物理过程和研究尚存在许多的“盲点”的情况下,目前的预测方法还不能充分利用这些庞大的数据资源,仅能使用其中的一小部分,可能对大的气候系统是重要因子,而对于局地的气候特征而言,却不一定是关键性因子,这就难免存在预测分析中“取轻略重”的情况,从而导致预测中不确定性增加而预测准确率下降的情况。因此,借助决策树等机器学习技术,充分从浩瀚的数据中挖掘出全面而又有价值的信息,藉此找到影响本地气候的主要系统和协同影响机制,对提高本地的气候预测准确率有极大作用。 在实际的预测业务中,不只需要对区域的整体趋势进行预测,需要对空间分布型进行分析,对旱涝中心及发生部位等进行预测。因此在上一节对全市平均建模的基础上,本节针对重庆34个国家气象观测站采用随机森林进行预测,在环流指数的选取上,由于实际的夏季预测发布时间在3月,此时所能获取的环流因子只能到2月,因此本文采用随机森林进行预测时,只采用前期冬季的海温指数建模,过程中不考虑变量的分布条件、交互作用、非线性作用,甚至缺失值等约束条件。图5是2011—2018年历年随机森林降水预测分布以及实况降水距平率分布图。 表5 2011—2018年随机森林夏季降水与业务发布预报对比表Table 5 Comparison of random forest summer precipitation and operational forecast from 2011 to 2018 从图5可以看出,2011—2018年重庆市夏季降水没有出现一致性偏多或者偏少,均为空间分布有差异的情况,这也为预测增加了难度,对比预测与实况,8 a的总体趋势预测均较为准确,仅2011年和2015年空间分布略有差异外,其余年份在区域预测上都相对准确。由于预测采用二分趋势预测,不能精细化的异常预测,所以在检验中预测结果分别以20%和-20%采用PS、CC和PC检验方法进行检验。检验结果如表5。 2014年以前,发布预报仅有6个代表站的质量评分,2014年预测业务调整后,重庆34个站均参与发布预报质量评分,因此发布预报质量的开始年份为2014年。从表5可以看出,随机森林预测得分较高且较为稳定,2014—2018年平均PS、CC和PC评分分别是84.6、0.27和67.1,相比于发布预报的72.4、-0.12和52.9,均有明显提高,从历年对比看,PS和PC评分较为一致,2016、2017年与发布预报大致相当,其余年份都比发布预报偏高20分左右。对于表征预报场和实况场的相关程度的CC评分更是明显优于发布预报,并且除2015年外,均超过95%的显著性检验,反观发布预报,CC评分多为负,这说明预测分型上还有待提高。 通过对影响重庆夏季旱涝的降水异常预测建立基于多因子的决策树模型,并进行随机森林集成及检验。主要结论如下: (1)影响重庆夏季降水的同期环流指数中,西太平洋副高脊线是非常重要的影响因子,如果只考虑该因子进行降水异常趋势预测,2011—2018年中共有5 a预测准确,考虑印度副高面积和登录台风的共同影响,则8a趋势均可预测准确,趋势一致率提高37.5%;考虑前冬多个海温因子共同作用的情况时,8 a降水异常趋势预测均正确,比只考虑大西洋经向模海温单因子的情况提高12.5%。这表明季节降水异常预测中,需要分析系统中各个部分的特征与关系,也必须研究多个部分的相互作用。采用决策树进行多因子协同影响模型能有效提高预测准确率,在气候系统机理分析等研究方面也有应用前景。 (2)用随机森林模型预测重庆2014—2018年的夏季降水异常趋势,PS、CC和PC评分均高于发布预报质量,且质量较为稳定。结果表明,实际夏季降水异常预测业务中采用随机森林模型是可行的。大多数情况下,模型的默认参数即可给出最优模拟结果,无需进行繁琐的参数调整。 本文在利用决策树和随机森林对重庆夏季降水进行预测建模时,虽然模型预测效果较好,但现阶段仍处于定性预测阶段,还没有开展定量的预测建模研究。作者将在后续的研究和业务中增加对多因子协同、多系统融合以及多模式集合技术的研发,并对重庆地区夏季旱涝的多种影响因素作进一步的分析,从而为提高该区域旱涝短期气候预测水平提供更多的依据和线索。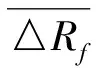
2 夏季旱涝预测试验结果与分析
2.1 决策树模型检验


2.2 随机森林模型在夏季的预测试验
3 结论
猜你喜欢
环球人文地理(2022年8期)2022-09-21
成都信息工程大学学报(2021年4期)2021-11-22
意林·全彩Color(2019年11期)2019-12-30
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年16期)2018-09-26
城市地理(2016年12期)2017-11-03
今日重庆(2017年5期)2017-07-05
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
