
DHSSA优化的K均值互补迭代车型信息数据聚类*
2022-06-08 02:08李文龙王会峰
汽车工程 2022年5期
黄 鹤,李文龙,杨 澜,王会峰,王 飚,茹 锋
(1. 长安大学,西安 710064;2. 西安市智慧高速公路信息融合与控制重点实验室,西安 710064)
前言
聚类分析是统计学习领域的常用方法,可以根据不同对象数据之间的内在特征,将相似度较大的数据样本划分到同一簇,已经应用于许多领域,诸如车辆数据、车辆检测、车辆轨迹等等。K-means 聚类(KMC)是使用最广泛的聚类算法之一,具有速度快、效果好、思想简单的特点。但是在实际的车型数据聚类过程中会因为初始点选取不当而导致误差较大。K-means++、山峰聚类等在一定程度上解决了KMC 初始化方面的缺陷,但优化路径过于简单,存在受异常点影响大、算法早熟的问题。近年来利用群智能优化算法来寻找聚类中心,解决早熟问题成为研究热点,广受研究学者的关注。文献[11]中将人工蜂群算法与KMC 杂交迭代,解决了早熟的问题,验证了群智能改进KMC 的有效性,但是利用改进蜂群算法来改进KMC 处理高维数据集,存在能力不足和迭代速度慢的问题;文献[12]中利用萤火虫算法优化KMC 的中心初始化问题,克服了初始聚类中心难选取和噪声点的影响,但不适合处理大数据集;文献[13]中设计了一种准确率较高的IFOA-K-means 算法,增强了横向探索能力,但忽略了纵向的挖掘能力;文献[14]中将改进飞蛾扑火算法与KMC 算法交叉迭代实现聚类,优化寻优结果,但飞蛾的更新机制使得算法的耗时较长。麻雀搜索算法(sparrow search algorithm,SSA)是2020 年 由Xue等提出的一种新的群智能优化算法,SSA 模拟了麻雀觅食的过程,具有收敛速度快,适应性强,模型易修改等特点,适合用于优化聚类。因此,本文设计了一种基于扰动因子-领头雀的SSA 优化方法(DHSSA),与KMC 算法互补迭代,有效提高了车型数据的聚类精度和迭代速度。
1 KMC和SSA算法特点
1.1 KMC算法
KMC 可以按照不同类别将数据集划分成多个子集,具体步骤如下:
(1)从个数据中随机选取个对象作为初始聚类中心C(1≤≤);
(2)计算每个数据到各个初始聚类中心的欧式距离,根据距离最小原则重新分类数据;
(3)计算聚类簇的各个维度平均值,得到新的中心。
重复步骤(2)和(3),直到聚类中心不再发生改变或聚类中心发生偏移的距离均小于设定阈值,输出该数据集的聚类中心。从聚类过程可以看出,初始聚类中心选择不当,会陷入局部最优。聚类中心C的计算公式如式(1)所示:

式中n为第个聚类簇样本个数,=1,2...,,为聚类中心个数。聚类中心C与样本数据X的欧式距离计算式如式(2)所示:
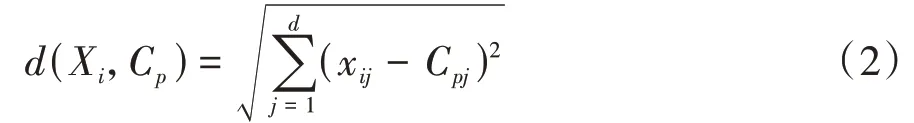
式中=1,2,…,表示数据维度。
因此,KMC 的初始化具有随机性,每次处理车型数据聚类过程中结果相差较大,容易由于中心选择不当而陷入局部极值,还可能会将离群值误作为初始中心;同时,根据均值选取中心的更新过程会导致KMC易受孤立点的影响。
1.2 SSA算法
(1)初始化
SSA中麻雀种群分为觅食发现者、抢食物的加入者和作为侦察的警戒者3 种。前两者角色可以互换,而一定比例的侦察警戒者,一有危险便飞向别处。麻雀种群在维空间内只麻雀的位置矩阵表示如下:
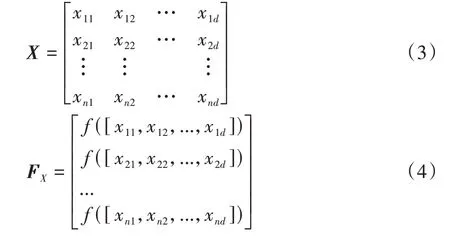
式中:x为维空间内第只麻雀的位置;矩阵F表示麻雀的适应度值。
(2)麻雀位置更新机制
更新机制主要可分为发现者的觅食过程、加入者的抢食过程和警戒者的检测过程。
a. 觅食过程:迭代寻优过程中,麻雀种群中的发现者负责觅食和指导整个种群移动,发现者位置更新如下:
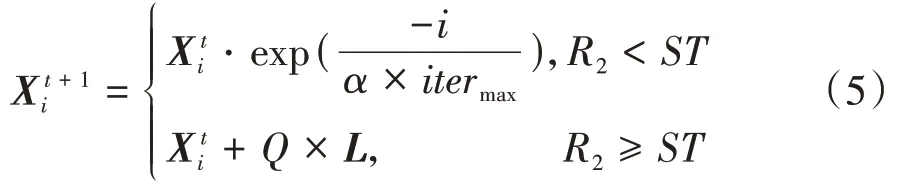
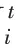
可以看出,当<时,发现者的每一维都在缩小,这对求解测试函数非常有效,但对于大多数求解非0的实际应用反而降低了搜索能力。
b. 抢食过程:加入者为除去发现者适应度较差的一些个体,设计位置更新公式为

c. 检测过程:在麻雀种群随机选取20%的个体作为警戒者,则这些个体对全体的影响程度用式(8)表示。

2 扰动因子-领头雀SSA优化策略
综合SSA 发现者、加入者和警戒者的更新方式可知,SSA 中的麻雀位置更新具有向原点收敛的趋势,这对于求解非原点问题存在一定局限性,而聚类中心一般不取0 值。同时,由于SSA 的收敛方式是跳跃式的,容易陷入局部最优。因此,寻找聚类中心前必须对SSA作进一步改进。
2.1 自适应领头雀引导
由更新式(5)可知,发现者的位置更新是在父代的基础上寻优,跟随父代更新会导致寻优速度减慢,增加聚类迭代时间。而通过作者的研究,自然界中的麻雀群在觅食中通常都会由一个最强壮、基因最优秀的个体充当领头雀。鉴于此,设计了一种自适应领头雀引导策略来完善SSA 算法,使得迭代更新不仅受父代的影响,还受到领头雀的影响。加入领头雀引导在前期会不利于种群全局探索能力的提升。为同时增加算法的前期全局探索和后期局部寻优能力,在上述最优个体(领头雀)引导策略的基础上添加自适应权重,这里新的发现者更新公式修改为

式中和分别为最大和最小值,取1 和0.01。系数随着迭代次数的增加变化曲线如图1所示。
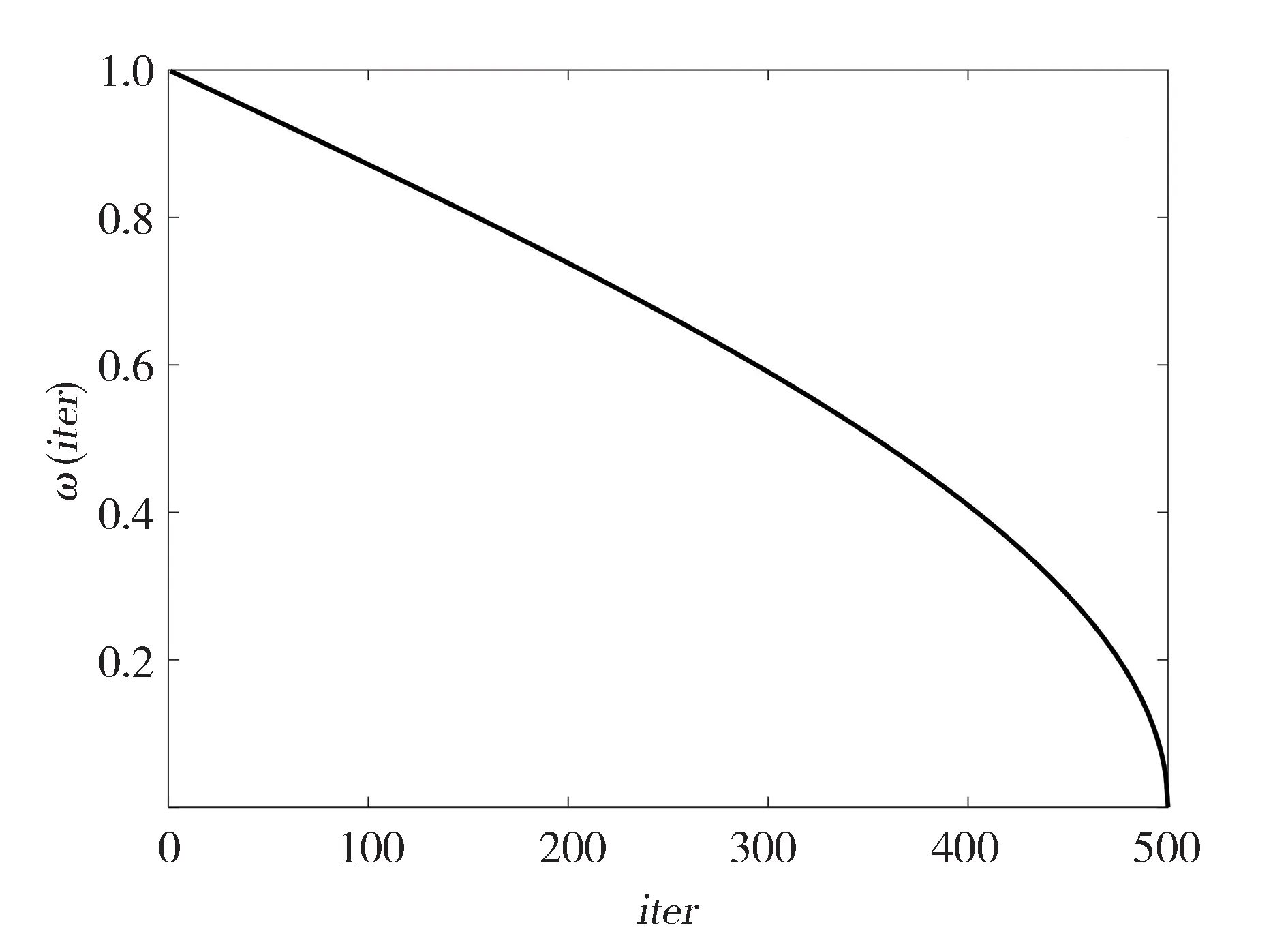
图1 ω系数变化曲线图
随的变化规律在前中期设计为缓慢减小,使得发现者的更新受父代的影响较大,降低算法早熟的可能性;而后期减小迅速,受领头雀的影响较大,由此提高算法精度,加快聚类迭代的完成。
2.2 扰动因子
麻雀发现者的位置更新存在收敛于0 的趋势,而加入者和警戒者的收敛趋于最优解,这导致了SSA 寻找聚类中心时易收敛于0,但是聚类中心的值一般不为0。针对这一问题,一般采用变异操作加强全局搜索能力,最常用的是高斯和柯西算子。而在SSA 寻找聚类中心的过程中为增加种群多样性,采用分布扰动因子对麻雀个体变异,根据参数自由度的大小表现不同,在自由度较小时表现为柯西分布,在自由度较大时表现为高斯分布。将分布的自由度参数设为麻雀搜索算法迭代次数,前期表现为柯西分布,随着迭代次数的增加,后期表现高斯分布,加强局部探索能力。通过扰动得到的位置既有利于增加种群多样性,即寻得聚类中心的可能性增加,又可以增加聚类的迭代速度。分布效果如图2所示,随着自由度参数的增大,的大概率取值范围越来越小。
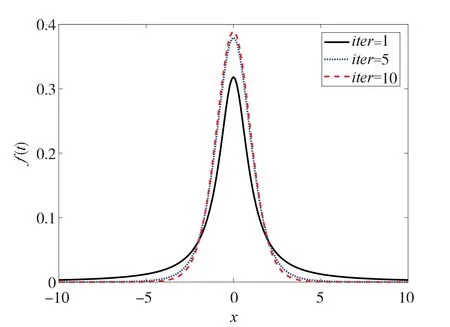
图2 t分布概率密度图
扰动种群的计算公式为
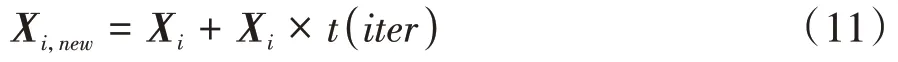
式中:为当前迭代次数;()为自由度参数为的分布。采用扰动因子求取新解之后,根据贪婪原则更新得到的新种群如式(12)所示。
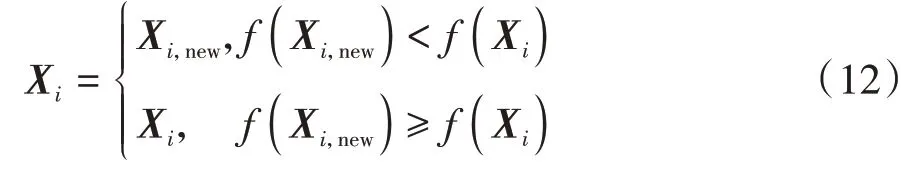
式中:(X)为X的适应度;(X)为X的适应度。
DHSSA优化策略具体流程如下:
(1)确定麻雀种群的数量以及维度,计算种群适应度并排序选出最优和最差个体;
(2)开始迭代更新;
(3)发现者根据头雀策略更新坐标位置,加入者和警戒者利用SSA更新位置;
(4)利用扰动因子增加种群多样性,根据贪婪原则决定是否替换原种群个体;
(5)判断最优适应度是否小于迭代上次最优适应度,小于时就替换最优个体,否则继续;
(6)判断是否达到最大迭代次数,是则输出最优个体,否则跳回(3)。
2.3 优化策略的测试
为了验证算法的性能,DHSSA 与SSA、SOA、HHO进行比较,测试函数如表1 所示。测试中,对于各个测试函数每种算法运行30 次,得到均值和标准差如表2 所示,适应度收敛曲线如图3 所示。设置种群的规模为50,迭代次数为500。

表1 测试函数
表2和图3数据表明,本文算法在求解各个函数时都表现出了优异的性能。精度方面,对于函数F1,DHSSA>SSA>SOA>HHO;对于函数F2 和F4,DHSSA>SSA>HHO>SOA;对于函数F3,DHSSA>HHO>SSA>SOA;对于函数F5,DHSSA>SOA=HHO>SSA。而对于函数F6,几种算法精度相同,收敛速度方面DHSSA>SSA>SOA>HHO。通过6 种测试函数验证了本文算法在总体上表现出较优的性能,可以改善SSA的全局寻优能力。
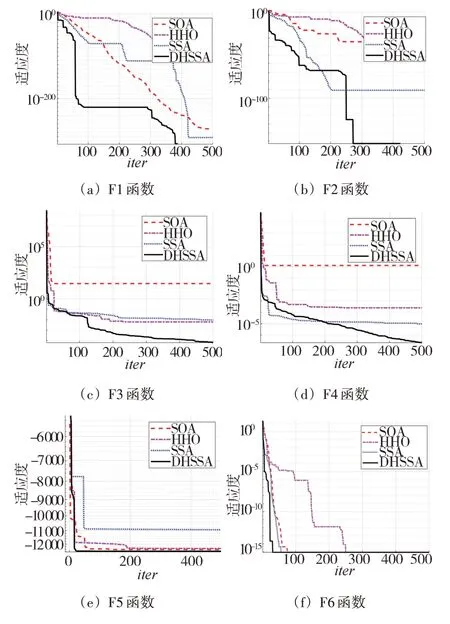
图3 函数收敛曲线
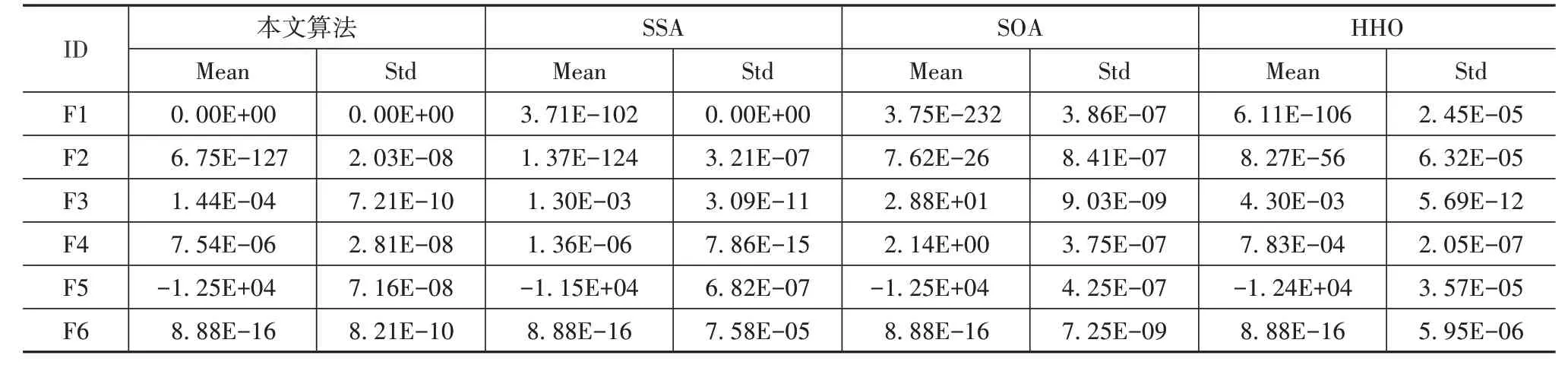
表2 算法测试结果比较
3 DHSSA与KMC的互补迭代
3.1 适应度函数选择
适应度函数决定了优化麻雀群体进化的方向,直接影响种群算法的优化效果和解的质量,且是DHSSA 与KMC 算法的唯一接口。KMC 以每个类别中个体到中心的距离和或个体总数为适应度函数,距离或点个数相等时,会存在辨识能力不足而影响更新的问题。利用DHSSA 优化聚类中心,结合距离和个数,采用如下适应度函数:
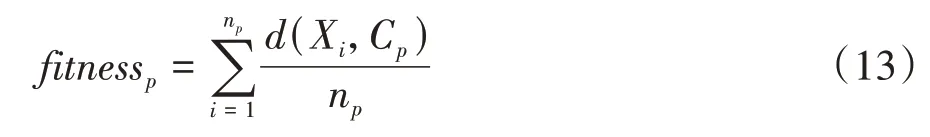
式中:脚标表示种群的类别数;(X,C)表示第类内的对象到该类的聚类中心点的距离和;n为第类中的种群数量。从适应度函数可以看出,当前聚类结果的适应度不仅与每个类别所有样本点到该簇聚类中心的距离有关,也与该类样本数有关,反映的是该簇所有样本点到聚类中心欧式距离的均值大小。均值越小,适应度越小,代表样本点距离中心更近,该簇样本更多。
3.2 筛选最大最小距离积初始化
利用最大最小距离积方法(maximum and minimum distance product,MMP)选取KMC 的初始中心,可以使得其代价有所减小,但选择的第一个初始中心具有随机性,有可能会把异常点计算为中心。同时,最大最小距离积法在计算的过程中,不考虑样本数据之间相互影响和密集程度的问题,计算出的两个中心点或者更多点可能出现在同一个簇中,尤其对于处理车型信息数据集这样的高维数据集,初始化聚类中心的能力明显不足。因此,针对上述问题,本文设计了一种筛选最大最小距离积法(screening maximum and minimum distance product,SMMP),计算所有点之间的距离,建立距离矩阵,然后求出该样本中离所有点的距离和最小的点作为第一个中心点,避免第一个中心的盲目选择问题。每个数据集分为类,说明有个簇。为了解决多个中心出现在一个簇中的问题,建立一个数值全为-1 的标记矩阵,每选出一个中心,将距离中心的前/个点归于对应的中心,并且在矩阵中标记出来,之后计算的中心只会在矩阵中标记为-1 的元素中得到。这样计算得到的中心大概率不会落在同一个簇中。SMMP 初始化算法可以有效减小车型信息数据之间相互影响和密集程度。
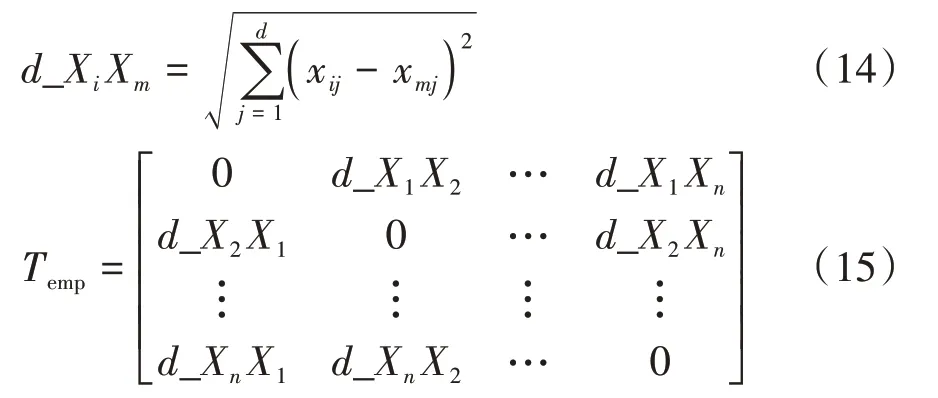
式中_XX表示第个元素到第个元素的距离,、=1,2,…,。对求取每行元素的距离和,即可得到第一个中心。
初始化步骤如下:
(1)计算数据集Data 中所有点之间的距离,建立,从中选取离所有点距离和最短的点作为第一个初始中心点,加入集合中,新建×1 的数值全为-1 的标记矩阵,在中标记周围距离大小为前/的点为1;
(2)选取距离最大且在中标记为-1 的元素为;
(3)将加入集合中,在中标记周围距离大小为前的点为2;
(4)分别统计Data 中标记为-1的元素到中各个元素的距离,并存入临时距离矩阵中;
(5)找出Data中标记为-1的元素对应中的最大距离和最小距离值,求其乘积,并将最大乘积值对应的元素作为中心C(1≤≤),加入集合中,在中标记C周围距离大小为前的点为。若中元素个数小于,转到步骤(4);若中元素个数大于,则初始中心选取结束,输出包含个初始点集合,得到初始中心。
通过以上步骤得到的初始聚类中心,可避免随机初始化引起的初始误差过大,有效减少了聚类耗时。选取Aggregation 数据集进行初始化,图4为3种初始化方法寻找聚类中心的对比结果,图5 为优化KMC更新曲线。
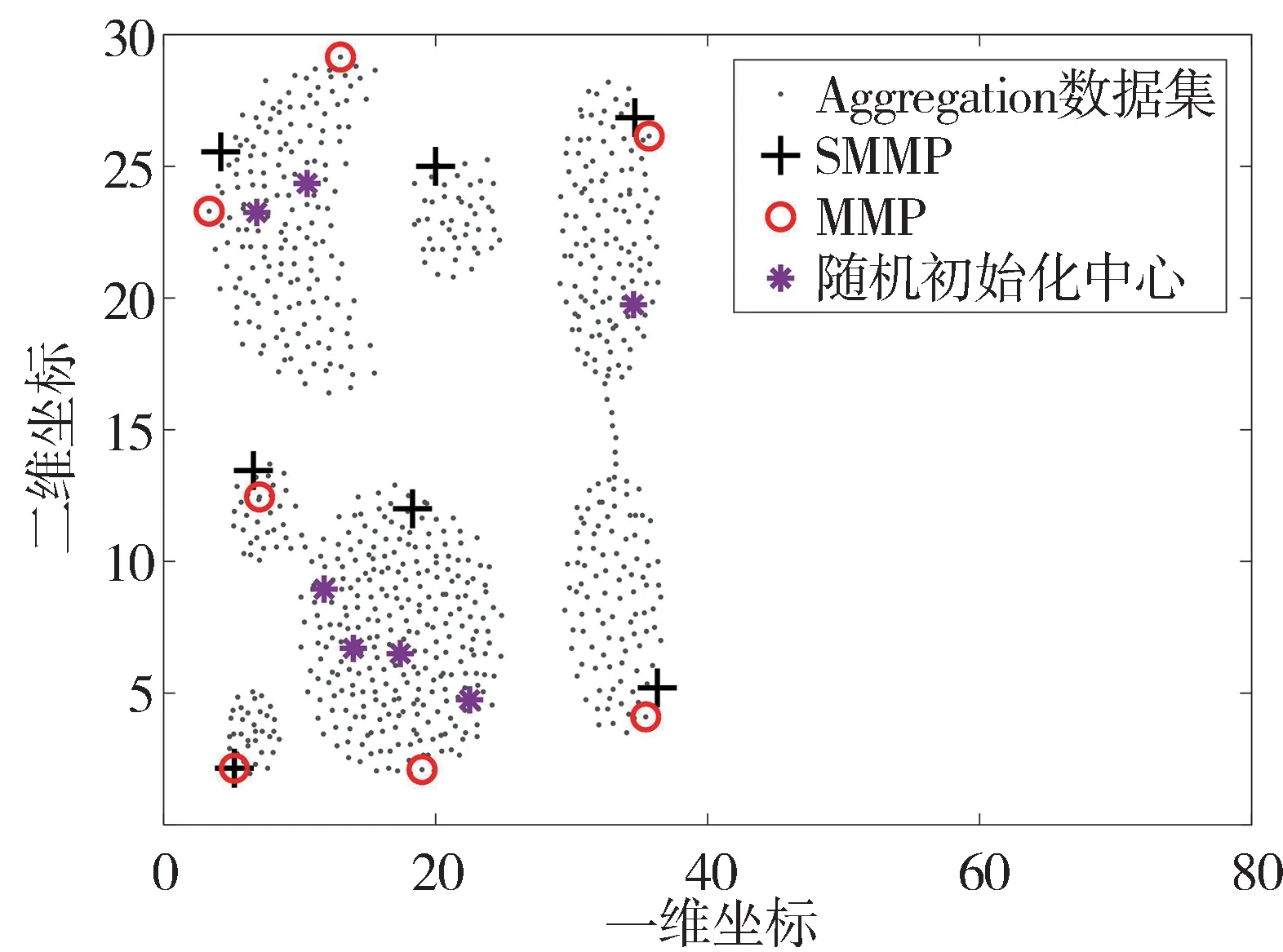
图4 Aggregation数据集初始化对比

图5 Aggregation数据集KMC聚类曲线
图4 中,*为在Aggregation 数据集上随机选取的聚类中心,初始化中心分布不规律,且大概率多中心落在同一个簇中;圆圈代表MMP 初始化得到的聚类中心,在左上角的簇中有两个聚类中心;+代表SMMP 得到的初始化中心,每个中心均匀的分布在相应的簇中。由图5 可以看出,SMMP 的初始化与MMP 和随机初始化(random init)相比其迭代速度更快,最优适应度更小。
3.3 DHSSA与KMC的互补迭代
KMC 通过求各个维度均值获得新聚类中心,更新方法过于简单,容易受异常点影响,陷入局部最优,导致优化精度过低。本文利用DHSSA 寻找聚类中心,实现与KMC 的互补迭代,扩大寻优范围,避免陷入局部最优的同时提高搜索精度,流程如图6所示。
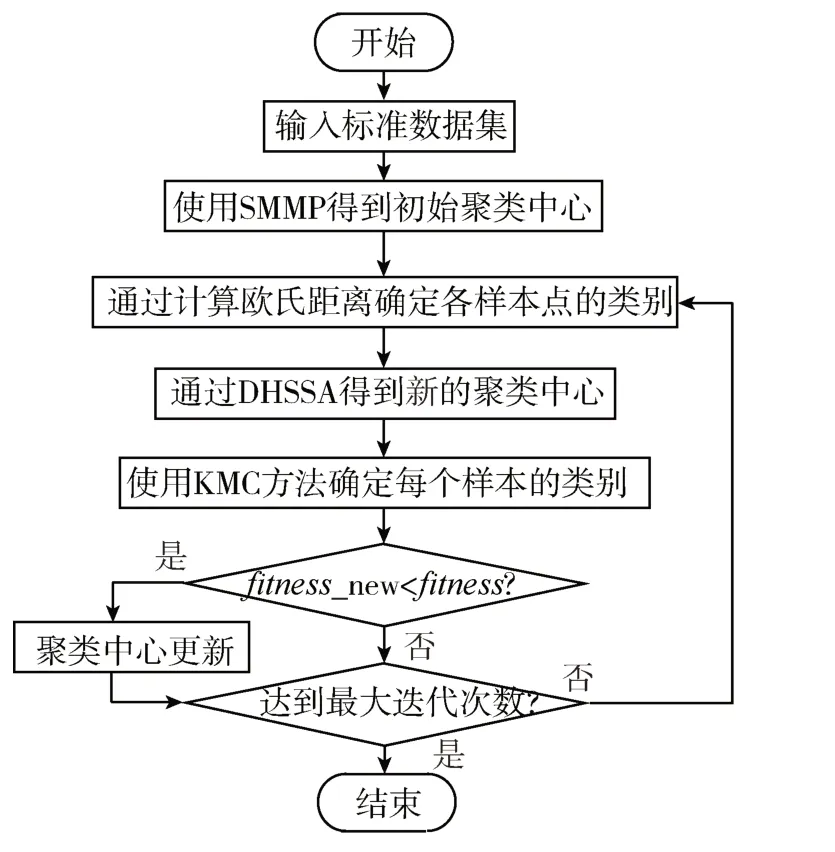
图6 方法流程图
基本步骤如下:
(1)输入数据集Data,根据其类别的个数确定数据集中类的个数;
(2)利用SMMP初始化中心点;
(3)计算Data 中的每个样本点到各个聚类中心的欧式距离,按数值大小进行排序,将样本点所属类别归于最小欧式距离的聚类中心;
(4)在每个类别的麻雀种群中通过DHSSA 进行寻优操作,得到新的聚类中心;
(5)使用KMC 确定每个样本的类别,计算由新中心聚类得到的新类别的适应度_new,若其适应度优于上次迭代的聚类中心,则用新的聚类中心取代。判断当前迭代是否达到结束条件,若未达到结束条件则执行步骤(4),使得DHSSA 与KMC 互补迭代,否则循环结束,输出寻优结果结束程序。
3.4 轮廓系数(silhouette index,SI)
轮廓系数具有相对较好的评价能力,被广泛使用,它反映了聚类数据集的类内紧密程度和类间的区分程度,本文使用SI 指标验证各聚类算法的聚类效果。
假设有一个数据集被划分成了个类,X是其中的一个样本数据,X的SI指标为
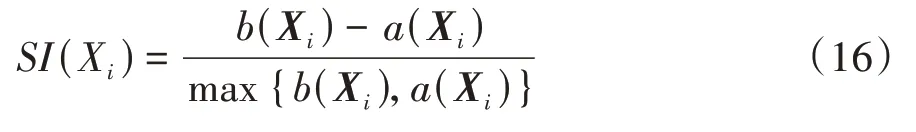
式中(X)为样本x与其所属中心C(1≤≤)中的其他样本的平均相似度。令(X,C)为样本x到其他中心C(1≤≤)的所有样本的平均相似度,则(X)=min{(X,C)}。(X)和(X)的计算公式为
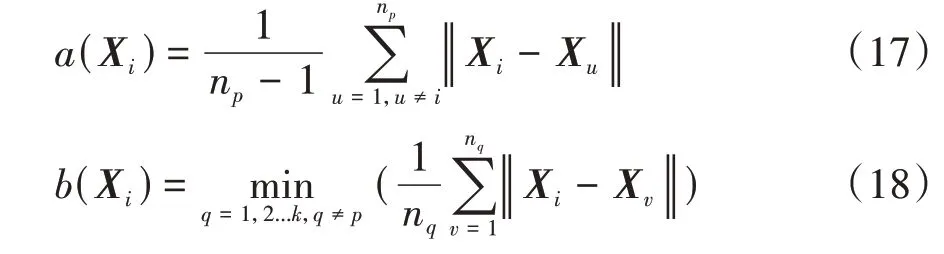
式中:n为X所属类的数量;X为X所属类C的其他样本。
由(X)可以计算得到一个类C的所有样本的平均值(C),进而计算得到一个数据集所有样本的值,值可以反映聚类结果的好坏,指标值越大,代表类别之间分离程度越大,类内紧密程度越高。
4 实验结果分析与应用
4.1 算法性能评价
硬件平台为Intel Core i5-7300HQ CPU 2.60GHz、8GB 内存的计算机,计算软件为Matlab R2017b。为了评价效果,将DHSSA-KMC 与SSA-KMC、IMFOKMC、KMC++、KMC 在公共数据集Wine、Ionosphere、Aggregation、Vowel、Glass、Ecoli 上验证。其中,Wine、Ionosphere 为高维少分类数据集,Aggregation、Vowel为低维多分类数据集,Glass、Ecoli 为高维多分类数据集。最大迭代次数都设置为50 次,在上述5 种聚类方法中,KMC++采取算法本身初始化方法,其余算法的初始化皆使用本文的初始化算法。各数据集的主要特征如表3 所示,各聚类算法处理各数据集的适应度收敛曲线如图7所示。
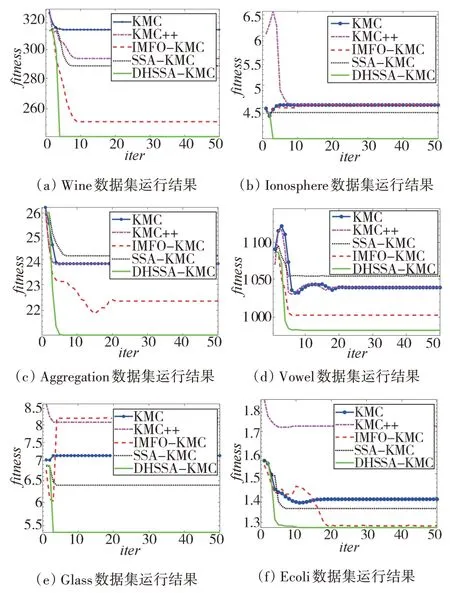
图7 不同算法在6种数据集上的运行结果
表3 标准数据集特征
由图7可以看出,DHSSA-KMC在聚类精度和收敛速度方面都优于其他4 种算法。在数据集Wine的测试中,DHSSA-KMC 的适应度<IMFO- KMC<SSA-KMC<KMC++<KMC;在数据集Ionosphere 的测试 中,DHSSA-KMC 的 适 应 度<SSA-KMC<IMFOKMC=KMC++=KMC;在数据集Aggregation 和Vowel测 试 中,DHSSA-KMC 的 适 应 度<IMFO-KMC<KMC++=KMC <SSA-KMC;在数据集Glass 测试上,DHSSA-KMC 的适应度<SSA-KMC<KMC <KMC++<IMFO-KMC;在数据集Ecoli测试中,DHSSA-KMC 的适应度<IMFO-KMC<SSA-KMC <KMC<KMC++。
由图7曲线还可以看出:在Ionosphere、Aggregation、Vowel数据集上,KMC和KMC++的适应度曲线重合,证明SMMP 初始化方法和KMC++的初始化方法效果相同;在Glass、Ecoli 数据集上,KMC 在初始和聚类完成的适应度均优于KMC++,说明在处理复杂数据上SMMP初始化方法优于KMC++的初始化方法。
采用Acc、ARI、NMI 3种评价指标对不同聚类算法进行评估。其中,Acc 表示聚类准确率,ARI 衡量两个数据分布的吻合程度,NMI 表示两组数据之间的关联程度。3 个指标的范围都为[0,1],值越大表示结果越好。对Wine、Aggregation、Ecoli 数据集的实验结果如表4所示。
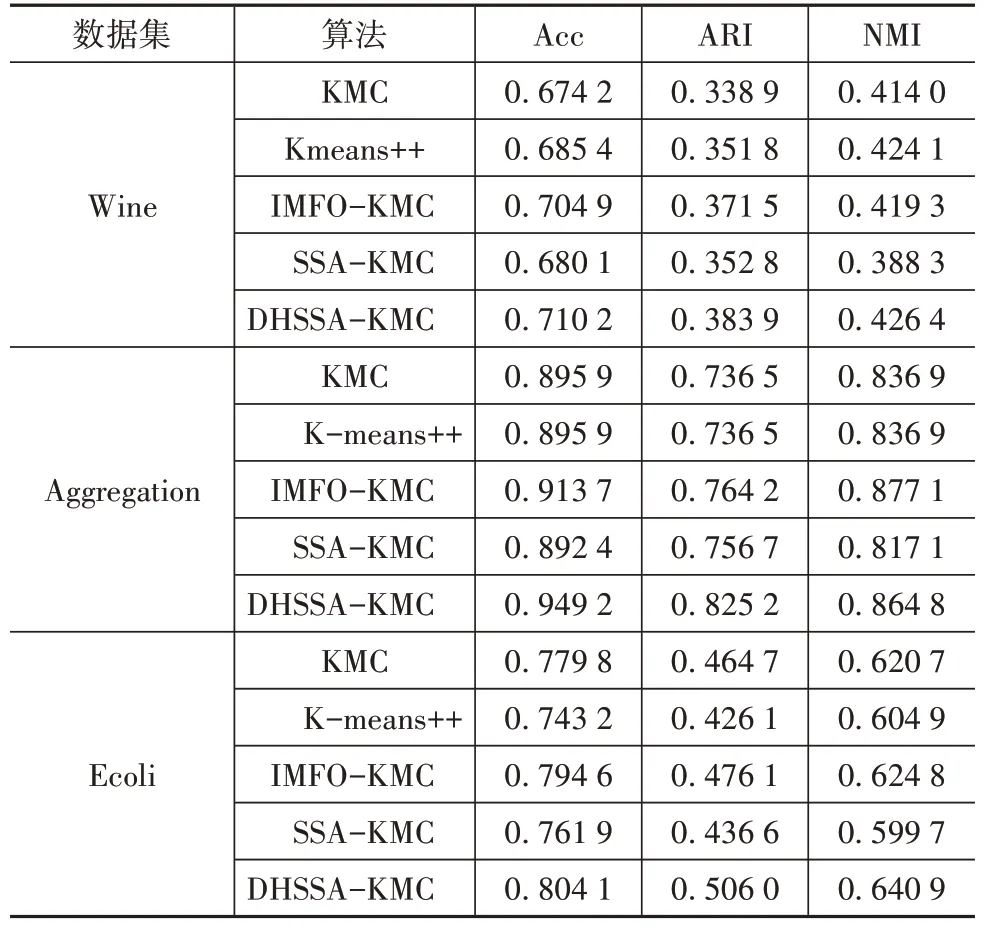
表4 不同算法对3个数据集的实验结果
表4中的评价数据是由50次独立实验数据求均值得到的,在Wine 中,本文算法的Acc 与其它算法相比提高了0.53%~3.6%,ARI提高了1.24%~3.21%,NMI 提高了0.23%~3.81%;在Aggregation 中,本文算法的Acc 相对其它算法提高了3.55%~5.33%,ARI提高了6.1%~8.87%,NMI低于IMFO-KMC1.23%,与其它算法相比提高了2.79%~4.77%。在Ecoli中,本文算法的Acc 与其它算法相比提高了3.55%~5.33%,ARI提高了2.99%~7.99%,NMI提高了1.61%~4.12%。因此,DHSSA-KMC聚类效果指标更优。
表5 所示为用各聚类算法处理Wine、Aggregation、Ecoli数据集计算指标的结果。
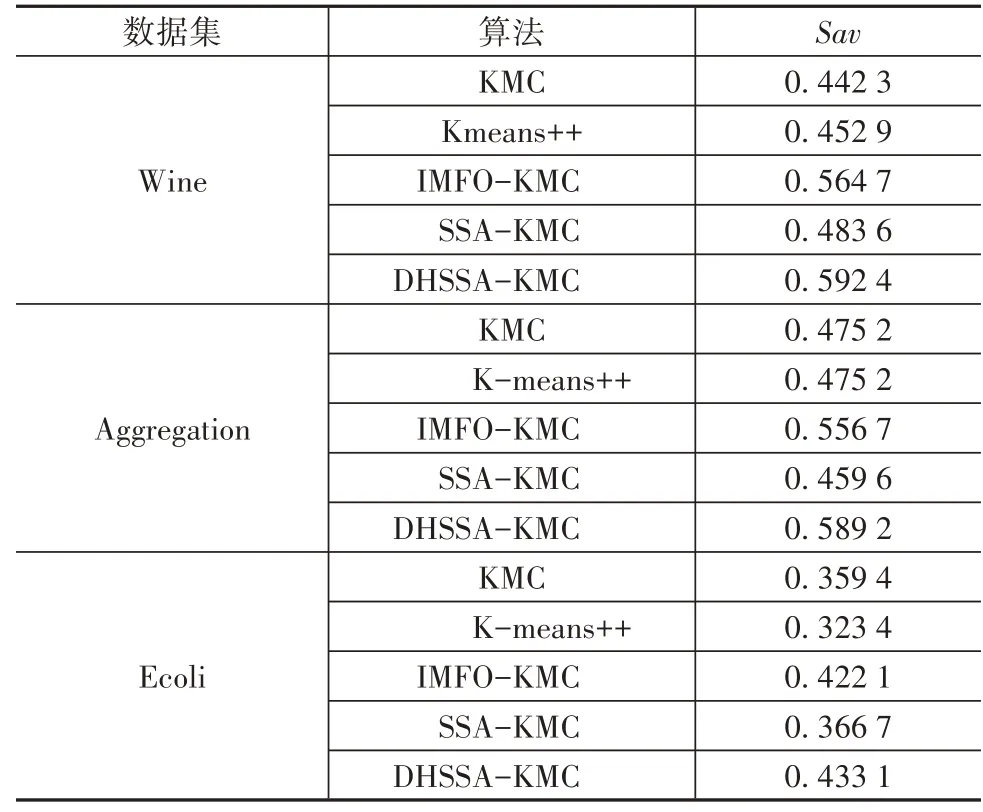
表5 3个数据集的SI指标
由表5 中指标可以看出,在Wine 上,本文算法相对其它算法提高了2.77%~15.01%,在Aggregation 上,本文算法相对其它算法提高了3.25%~12.96%,在Ecoli上,本文算法相对其它算法提高了1.1%~6.37%。在3 个数据集上,本文算法的Sav 值最大,表示类别之间分离程度最大,类内紧密程度最高。
聚类的迭代融合群体智能算法的迭代,能提高聚类精度,但会增加耗时。当最大迭代次数仍设为50时,各算法优化聚类的时间代价如表6所示。
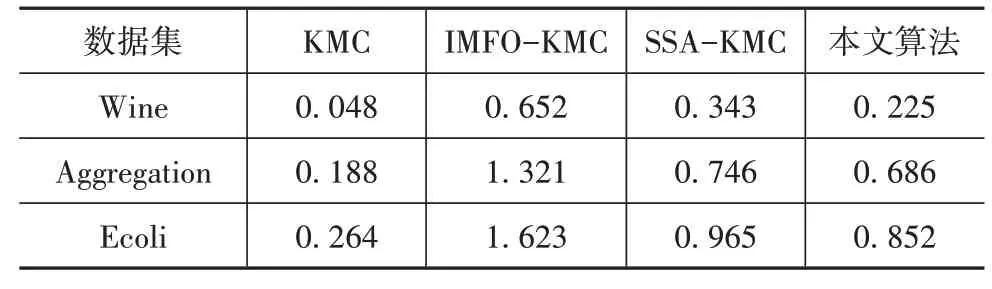
表6 不同算法对3个数据集的时间代价 s
从表6中可以看出,在Wine、Aggregation 和Ecoli中,本文算法分别比IMFO-KMC 降低了0.427、0.635 和0.771 s,比SSA-KMC 降低了0.118、0.060和0.113 s,比经典的KMC 提高了0.177、0.498 和0.588 s。综合来看,本文算法相对于经典KMC 的迭代耗时略高,相对于IMFO-KMC 和SSA-KMC 有所减小。这是因为IMFO-KMC 受限于飞蛾的更新机制,收敛速度提高有限,而本文算法继承了SSA 位置更新更快的优点,并且提高了全局寻优的能力,能够在保证精度的同时减少迭代时间。
4.2 车型信息数据聚类分析
实验选取具有代表性的阿里云公开的汽车聚类数据集,数据为205款车的26个字段,主要包括汽车 的id(car_ID)、风 险 等 级(symbolling)、车 型(CarName)、燃油(fueltype)、最大转速(peakrpm)、城市里程(citympg)、高速里程(highwaympg)、价格(price)等参数。聚类的目的是针对指定的车型,通过数据聚类分析可以找到其同类车型即竞品车型。原数据集存在非数值型数据,需要将非数值字段转化为数值,操作方式为独热编码。转换后的数据特征前5 列如表7 所示。对于汽车数据集的分类数量可以通过肘部原则来选择,本文选择=5,对于汽车数据集的聚类迭代曲线如图8 所示,对于汽车数据集的聚类Silhouette指标如表8所示。
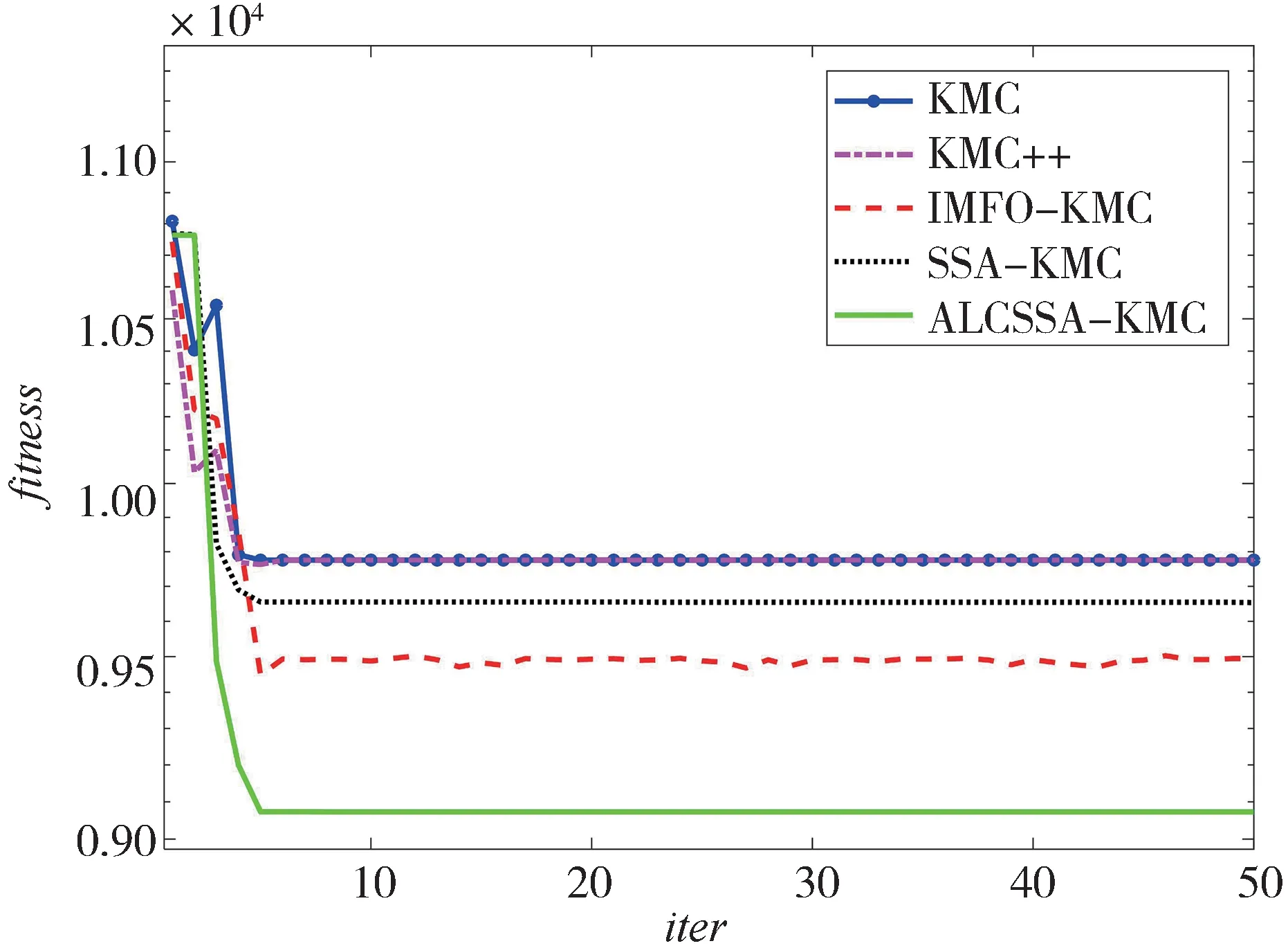
图8 不同算法在车型信息数据集上的运行结果
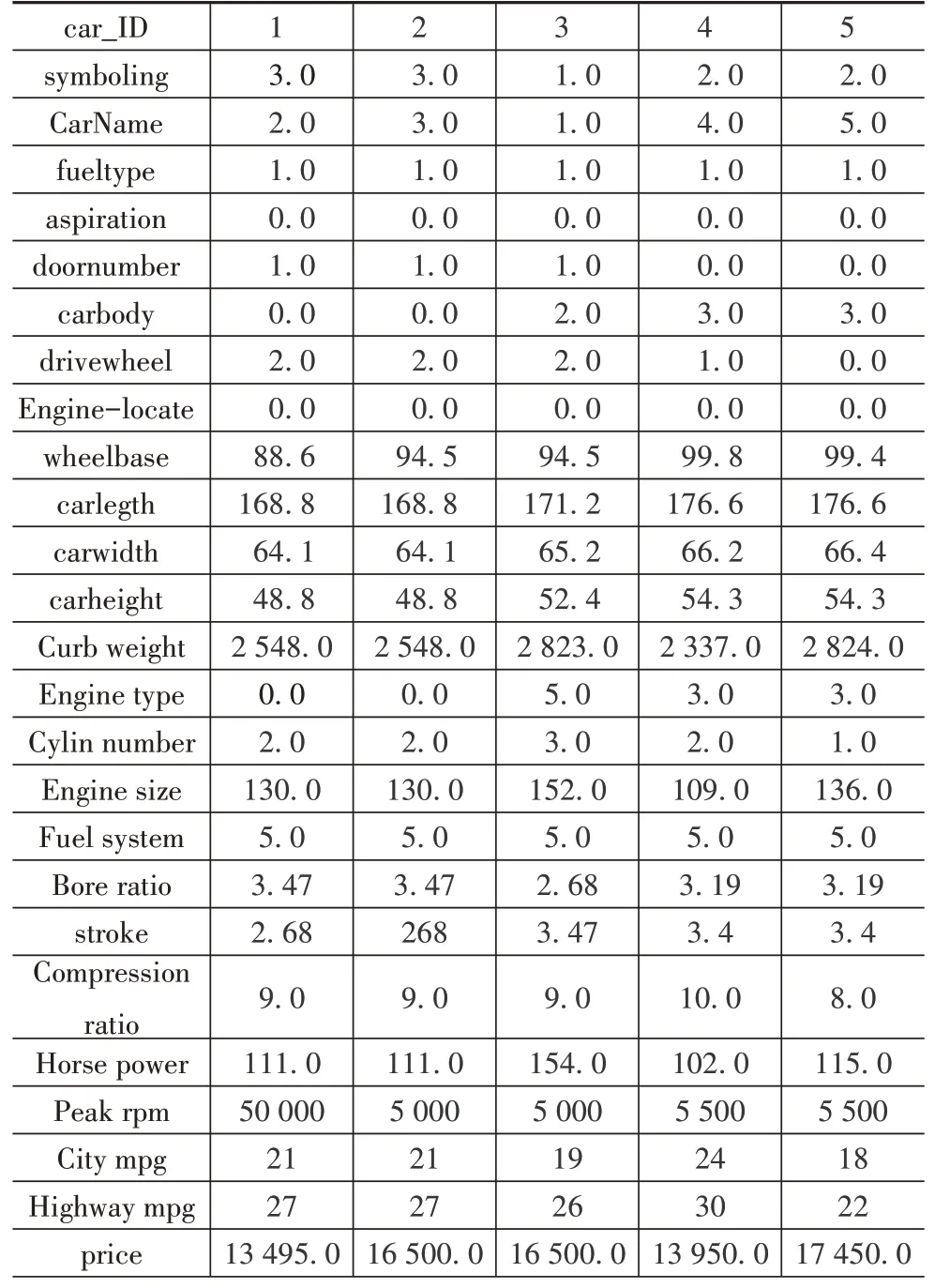
表7 编码后的汽车聚类数据集
从表8 中可以看出,在车型信息数据集上,本文算 法 的Sav 值 为0.554 1,比IMFO-KMC 提 高 了0.116 3,比KMC 提高了0.149 6,比SSA-KMC 提高了0.194 3,本文算法在聚类车型信息数据集时使得车型同类之间距离更小,类别之间距离更大,聚类效果最佳。

表8 车型信息数据集的Silhouette指标
通过聚类可以将相似的汽车属性聚为一类,然后利用聚类结果分析各个类的差别以及同类汽车属性的差异。例如:某客户中意奥迪车,可以找出audi汽车的聚类结果,如表9 所示。也可以找出audi 品牌下audi 5000 所在的类别5,并统计出类别为5 和carbody标签为wagon 的所有车辆,然后按价格排序,供消费者选择出最符合需求的汽车,如表10所示。
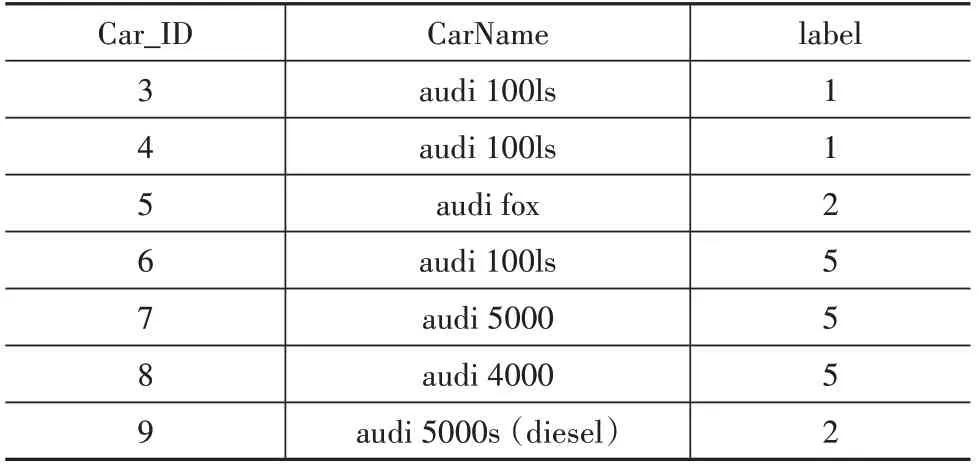
表9 audi汽车的聚类结果
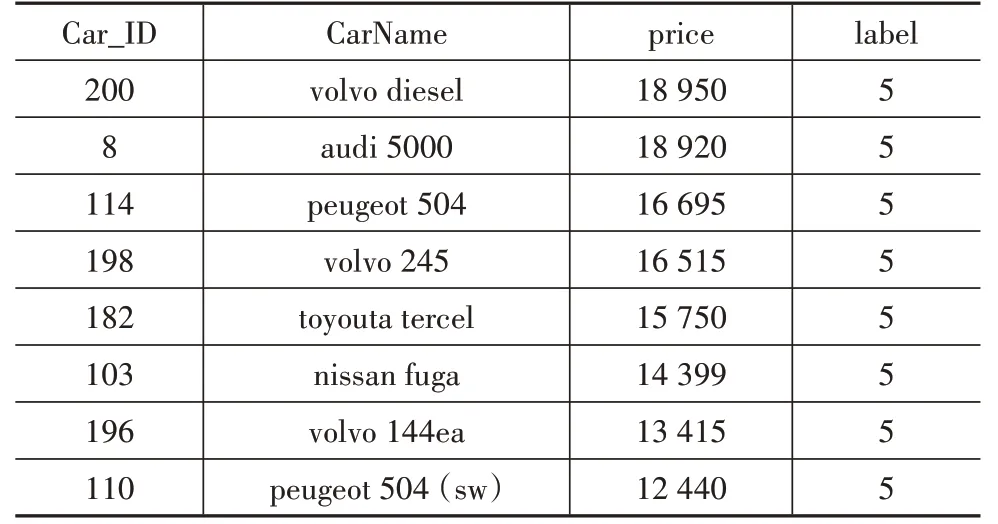
表10 按价格排序的audi 5000的竞品车型
5 结论
本文提出了一种DHSSA 优化的K 均值互补迭代车型信息数据聚类方法。首先设计了一种扰动因子-领头雀优化策略,由此提升SSA 的全局寻优能力,减小了由于SSA 易陷入局部最优造成的时间成本;然后利用筛选最大最小距离积法初始化中心,保证了各个中心最大程度地落在每个簇中;最后将DHSSA与KMC互补迭代,解决了聚类迭代过程中受离群点影响大以及路径搜索能力不足的问题,减小了迭代次数,同时提升了搜索效率,得到较好的聚类结果。最后通过车型信息数据集聚类,验证了本文算法的应用价值。
猜你喜欢
今日农业(2022年15期)2022-09-20
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学生物学(2018年8期)2018-03-01
当代旅游(2016年10期)2017-04-17
电子技术与软件工程(2016年23期)2017-03-06
物联网技术(2016年12期)2017-01-21
财经理论与实践(2015年2期)2015-04-16
中学生物学(2008年6期)2008-08-29
中学生物学(2008年2期)2008-07-07
