
基于多标签零样本学习的滚动轴承故障诊断
2022-06-17 03:03张永宏赵晓平王丽华吕凯扬张中洋
振动与冲击 2022年11期
张永宏, 邵 凡, 赵晓平, 王丽华, 吕凯扬, 张中洋
(1.南京信息工程大学 自动化学院,南京 210044;2.南京信息工程大学 计算机与软件学院,南京 210044;3.南京信息工程大学 江苏省网络监控中心,南京 210044)
滚动轴承是旋转机械中的重要部件,随着现代机械仪器、设备向高速和精密方向发展,对滚动轴承的可靠性要求愈来愈高。但实际工业场景中,滚动轴承因载荷大、冲击强等恶劣工况,极易产生故障。相较于实验室流程操作所产生的固定故障类型,工业场景下滚动轴承的故障类型复杂多样[1]。利用已有的状态监控数据,如何识别无历史记录的故障类型(即未见类故障)、提高未见类故障识别的准确性成为研究难点,具有显著的工程应用价值和需求。
本文重点关注在不停机检查的情况下,依靠现有类型固定的故障数据,完成工业场景中未见类轴承故障的识别。这种故障诊断方式在没有目标故障类型样本的条件下完成,摆脱了对共享故障类型的依赖,因此零样本故障诊断更接近工程应用场景的实际情况。由于实际应用场景的制约,与一般的故障识别相比,零样本故障识别具有以下特点:①参与测试的目标故障(未见类故障)和参与模型训练的故障(可见类故障)在故障类型上没有交集;②识别结果具有较好的泛化性,能够真正扩展到实际工业场景中;③识别模型适用场景广泛,且无需反复进行模型参数重设和模型优化。
此外,本文还关注高效的模型设计,在减少模型参数的同时保持其性能,即模型轻量化。卷积核分解是一种常用的轻量化方法,如GhostNet[2]使用Ghost模块替换卷积层,减少了计算成本,Xception[3]、MobileNet[4]和MBDS-CNN[5]均使用深度可分离卷积代替标准卷积以实现轻量化。模型轻量化具有以下优势:①模型对内存和处理器性能的要求低;②分布式训练中的数据交换少;③适应更广泛的嵌入式、移动端设备。
当前,数据驱动的故障诊断方法已经成功运用于机械故障诊断[6],包括自动编码器[7-8]、卷积神经网络[9-10]和深度置信网络[11]等。但是,上述方法依赖于大量训练数据以优化模型,而实际工程场景中的带标签数据难以获取。近年来,为了克服实际工程场景中故障样本采集的困难,基于深度迁移学习的方法被广泛应用,其基本流程是从易获取的故障数据(源域)中学习知识,帮助识别难以采集或采集代价高昂的故障(目标域)[12-13]。雷亚国等[14]将残差网络与最大均值差异项、伪标记学习结合,提出了一种无需目标故障样本标记信息的高精度迁移学习方法。Lu等[15]提出域自适应模型,完成了变工况下的滚动轴承诊断任务。此外,还有学者构建了基于生成对抗思想[16-17]和实例[18]的迁移学习模型。尽管深度迁移学习方法不需要来自目标域的带标签样本,但其重点解决的是源域和目标域的域偏移问题,前提是源域与目标域具有标签相同的故障。然而本文考虑的零样本问题在源域和目标域没有标签上的交集,因此,深度迁移学习不符合零样本的要求。
综合上述分析,本文引入零样本学习(zero-shot learning, ZSL)方法以解决零样本条件下未见类故障的识别问题。ZSL方法仅将可见类样本用作训练数据,实现对未见类的分类。Lampert等[19]首次提出ZSL的概念,对毫无关联的训练集和测试集完成了对象检测,提出了直接属性预测(direct attribute prediction, DAP)方法,利用非线性支持向量机来学习属性,再使用训练好的支持向量机预测未见类样本的属性。此外,Lampert等[20]还提出了间接从标签中学习属性的间接属性预测(indirect attribute prediction, IAP)方法。为了将可见类中学习到的投影函数更好地推广到未见类中,Kodirov等[21]提出了语义自编码器(semantic autoencoder, SAE),编码器将全局视觉特征向量投影到语义空间中,通过优化解码器重构原始视觉特征给网络施加约束,提升了识别精度。在故障诊断领域,GAO等[22]提出了基于压缩堆叠自编码器的零样本学习方法,使用已知工况下的数据训练模型,成功诊断出未知工作负载下的轴承故障。但该方法未能将故障信号的特征投影到高维属性空间,本质上没有突破类别边界,不符合零样本的要求。FENG等[23]针对零样本条件下的工业故障诊断任务,定义了有别于图像识别领域的辅助信息即故障属性(故障的原因、位置、影响等),其试验结果验证了零样本条件下故障诊断的可行性,但该方法未考虑各故障属性之间的相关性。
针对以上不足,为了实现零样本条件下未见类轴承故障的诊断,本文提出了MLZSL故障诊断方法。首先,对振动信号做短时傅里叶变换并划分训练集(可见类)和测试集(未见类);其次,构建轻量化特征提取模型RDSCNN,提取可见类和未见类各样本的特征;然后将可见类样本的特征用于训练多标签属性学习网络,再识别未见类样本的属性;最后计算属性向量与各属性标签的余弦距离,完成对未见类轴承故障的诊断。试验显示,MLZSL方法相较于经典的零样本方法(DAP、IAP、SAE)取得了更准确的诊断结果。
1 相关理论介绍
RDSCNN特征提取模型中结合了残差学习机制和深度可分离卷积层,相关理论介绍如下。
1.1 残差学习
在深度神经网络中,理论上网络的层数越深,其输出的特征表示能力越强。但随着深度的不断增加,网络会发生退化,准确率也随之下降。He等[24]所提出的残差卷积神经网络(residual neural network, ResNet)引入残差模块解决了网络退化问题,残差学习模块的结构如图1所示。
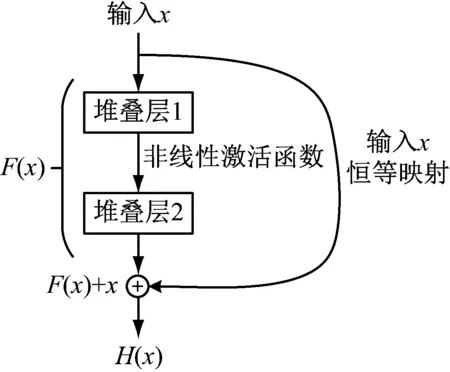
图1 残差学习模块结构Fig.1 Structure of residual learning module
残差模块在从输入到输出的单一映射基础上添加了来自输入的跳跃连接[25],将浅层的输出加到深层的输出上,最终输出如下
H(x)=F(x)+x
(1)
式中:x为上一层的输出;H(x)为残差模块的输出;F(x)为对x的线性或非线性调整。若浅层输出x已经提供足够完备的特征,以致对特征x的任意改变都会增加损失时,F(x)将不做任何学习,整个模块相当于恒等映射,由此改变网络的前向和后向传递方式,对网络加深起到优化作用。
1.2 深度可分离卷积
深度可分离卷积由深度卷积和逐点卷积两个过程组成。在深度卷积过程中,每次卷积只在单个通道上进行,输出与输入具有相同通道数量的特征图;在逐点卷积过程中,对深度卷积过程输出的特征图做1×1卷积,重复该过程n次即可增加输出通道数至n层,其具体操作如图2所示。

图2 深度可分离卷积结构Fig.2 Structure of depthwise separable convolution
假设输入图片大小为m×m×3,欲输出通道为n的特征图,使用传统卷积需要n个k×k×3的卷积核移动(m-k+1)2次,总体运算次数如下
3nk2(m-k+1)2
(2)
使用深度可分离卷积进行运算时,在深度卷积过
程中3个k×k×1的卷积核移动(m-k+1)2次;在逐点卷积过程中n个1×1×3的卷积核移动(m-k+1)2次。深度可分离卷积总体运算次数如下
3(k2+n)(m-k+1)2
(3)
2 MLZSL故障诊断方法
整体而言,本文所提出的MLZSL方法包括特征提取和属性学习两个阶段。其中,特征提取阶段的核心任务是RDSCNN模型的构建和使用;属性学习阶段通过搭建多标签属性学习网络,直接从样本特征中学习故障属性并完成未见类样本的诊断。
2.1 特征提取阶段
深度神经网络能够提取海量数据中的抽象特征,为了充分发挥深度神经网络的特征提取能力,同时加速模型收敛和避免网络退化问题,本文提出了RDSCNN模型。模型主要由深度可分离卷积层、卷积层、最大池化层、平均池化层、全连接层以及残差连接组成,如图3所示。RDSCNN模型以三通道的时频图像作为输入,通过卷积层和深度可分离卷积层不断优化特征,加入残差连接减少特征损失,设置卷积层和池化层步长以下采样方式减小空间维度,最终由全连接层输出一维特征。模型采用Relu作为非线性激活函数,加快模型训练速度。 为了防止模型出现梯度消失的问题,对每一层卷积运算的结果做批量归一化处理,使其符合标准的正态分布,消除层与层之间的量级差异。
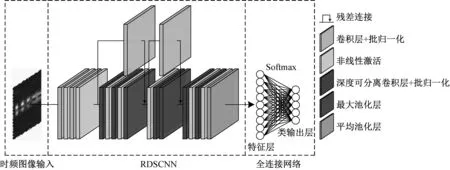
图3 特征提取网络Fig.3 Feature extraction network
RDSCNN模型在试验中分为模型训练和特征提取两个阶段。在模型训练阶段,首先将模型与Softmax函数组合,训练集数据由正向传播经过模型各层和Softmax函数运算到达类输出层,然后将输出结果代入交叉熵损失函数如式(4)所示。
(4)

在特征提取阶段,采用已经训练好的RDSCNN模型对整个数据集进行特征提取,在特征层得到数据的低维特征向量表示。
总体而言,RDSCNN模型具有轻量化的网络结构,模型结合了深度可分离卷积、非线性激活函数Relu和残差学习机制等,使得参数量大大降低、收敛速度更快、训练时间更短,在保留特征信息的同时降低了数据维度,加速了后续的属性学习过程。
2.2 属性学习阶段
本文提出的多标签属性学习网络旨在学习样本特征中的故障属性,构造可见类和未见类故障特征在高维属性空间的嵌入,最终实现故障的诊断。
本文提供了滚动轴承故障的细粒度属性描述,其主要基于滚动轴承故障的损伤程度(7 mil、14 mil、21 mil)、工作负载(0、1 hp、2 hp)和损伤位置(滚子B、内圈IR、外圈OR),如表1所示。依据故障类别yi是否拥有各个细粒度属性可以得到一个与之对应的9维二值属性矢量Ai。

表1 滚动轴承故障属性Tab.1 Rolling bearing fault attributes
每个故障特征xi对应一个9维的属性矢量Ai,即一个实例样本拥有多个标签,因此,本文将属性矢量的学习过程看作一个具有9个标签的多标签分类问题,其多标签属性空间为29。为了应对输出空间复杂度的指数性增长,本文挖掘了标签之间的相关性,将属性矢量A依据属性描述的类别作互斥属性切分,得到三个细分属性矢量a、b、c,与属性描述对应,即原属性矢量A=concat(a,b,c),将输出空间减少为3×23,大大降低了属性学习难度。
多标签属性学习网络有监督地为每个细分属性矢量构造一个属性学习器,分别记为F1,F2和F3。在测试阶段,使用这些属性学习器对每一个未见类样本预测细分属性矢量。三个属性学习器的映射关系如图4所示。
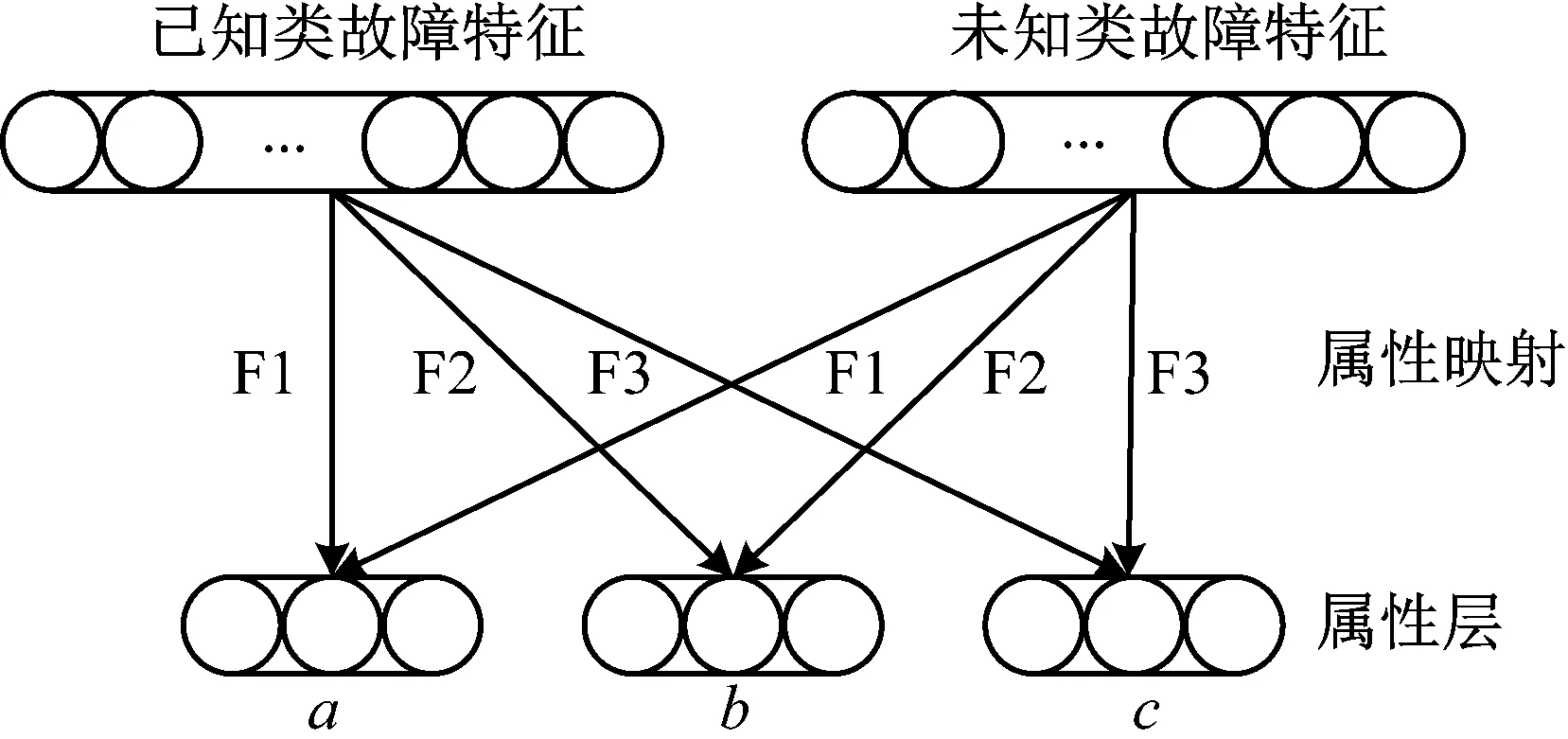
图4 属性学习器映射关系Fig.4 Mapping of attribute learners
以属性学习器F1为例,从故障特征xi到细分属性矢量ai的推理过程可表示为f:xi→ai,本文通过搭建全连接神经网络实现该推理过程,网络结构如图5所示。
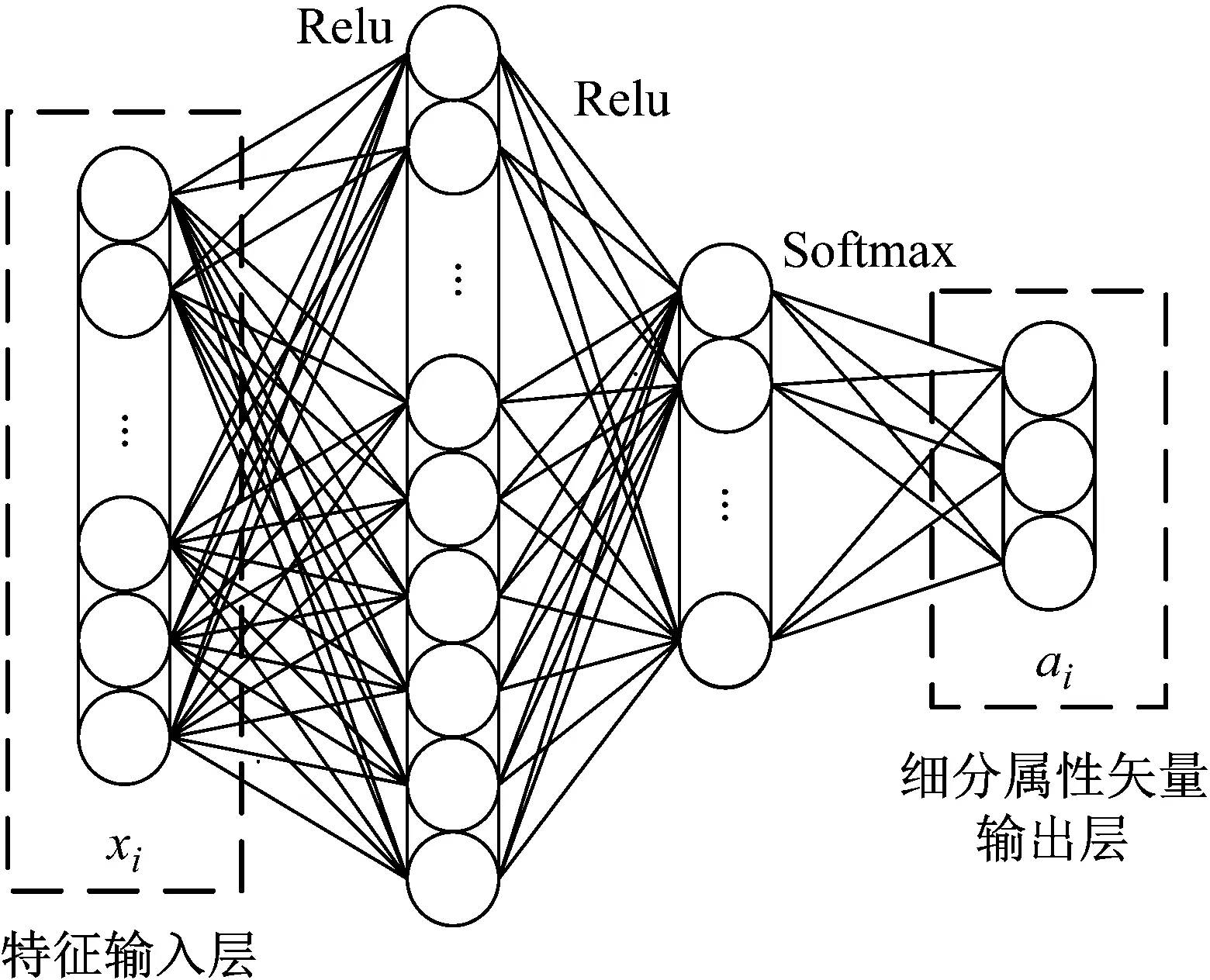
图5 属性学习器F1网络结构Fig.5 Architecture of attribute learner F1
(5)
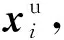
(6)
对得到的细分属性矢量完成拼接,计算其与各故障属性标签的余弦距离如式(7)所示,最终取距离最近的故障标签作为其预测标签yu。
(7)
整体上,多标签属性学习网络由三个属性学习器F1、F2和F3组成,各属性学习器分别学习一组细分属性矢量,组合得到样本的预测属性标签,最终推导得出样本的故障类别。
2.3 MLZSL故障诊断流程
基于MLZSL方法的故障诊断流程如图6所示,主要包含故障信号预处理、特征提取和属性学习三个阶段,各阶段的具体步骤如下。
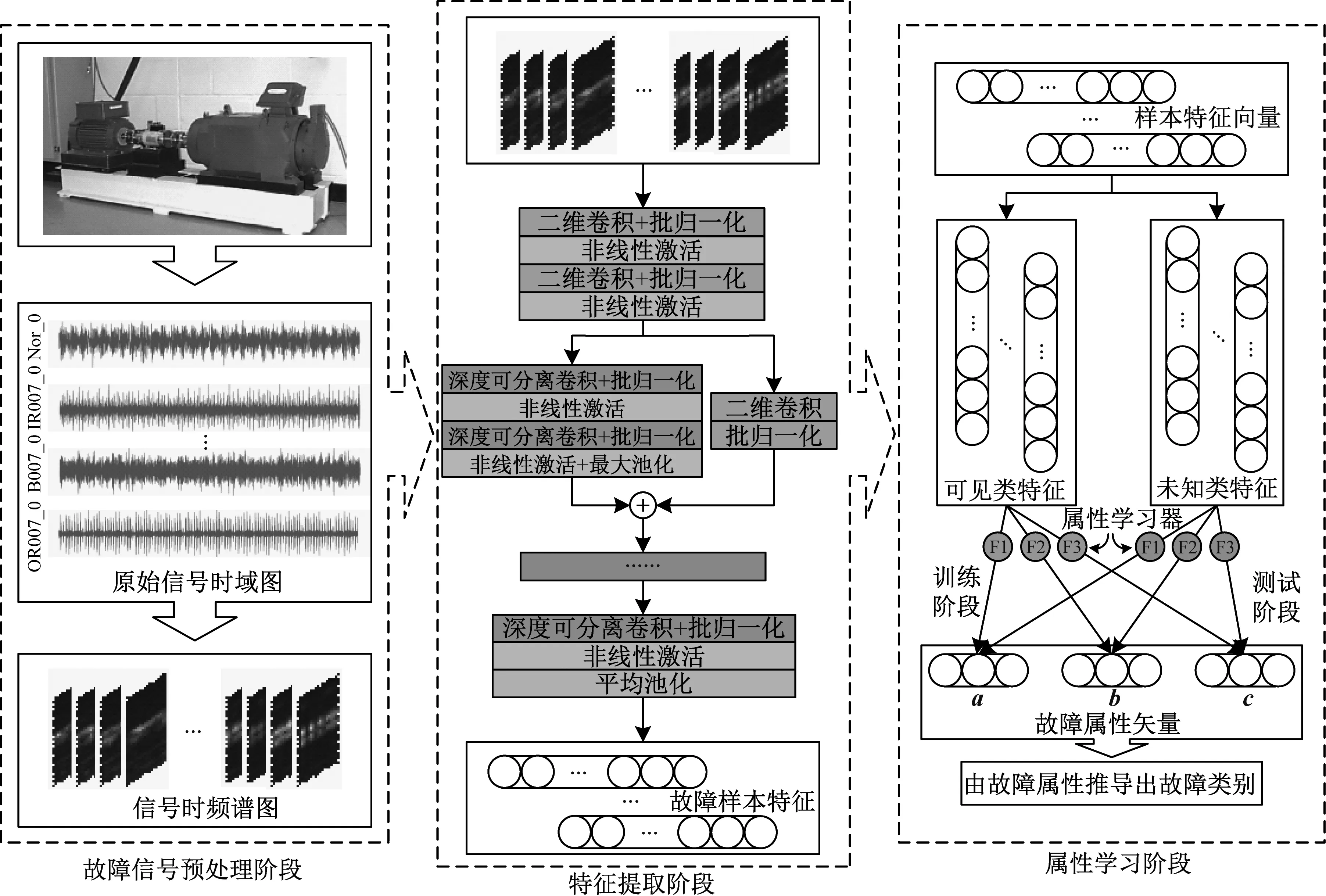
图6 MLZSL故障诊断流程Fig.6 MLZSL fault diagnosis process
故障信号预处理阶段:对采集得到的故障信号数据做预处理。首先将每一类的信号序列数据切分成一定数量的样本;然后对所有信号样本做短时傅里叶变换,得到维数为64×64×3的时频图数据集;最后按照数据的类别标签将其划分为训练集(可见类)和测试集(未见类)。
特征提取阶段:构建RDSCNN模型对所有样本完成特征提取。首先组合RDSCNN模型和Softmax层,将训练集作为输入调整模型参数;然后保存训练好的RDSCNN模型的各层参数;最后加载保存的参数,借助模型降低输入时频图数据的维度,得到可见类和未见类的故障特征向量。
属性学习阶段:使用属性学习网络预测样本属性并推导其标签。首先,以可见类样本特征作为输入,训练属性学习网络中的各属性学习器;然后使用属性学习器预测未见类样本的细分属性矢量,拼接得到完整属性向量;最终计算其与各故障属性标签的余弦距离,完成未见类故障样本的诊断。
3 试验与结果分析
3.1 试验数据
试验数据采用的是凯斯西储大学提供的轴承故障数据集[26],试验台由电动机、扭矩传感器、测力计和控制电子设备组成。本文从采样频率为12 kHz的驱动端数据中,依据不同的工作负载、损伤位置和损伤程度选取了共30类数据进行试验。其中包括健康数据3类,故障数据27类,所选取数据的类别组成如表2所示。
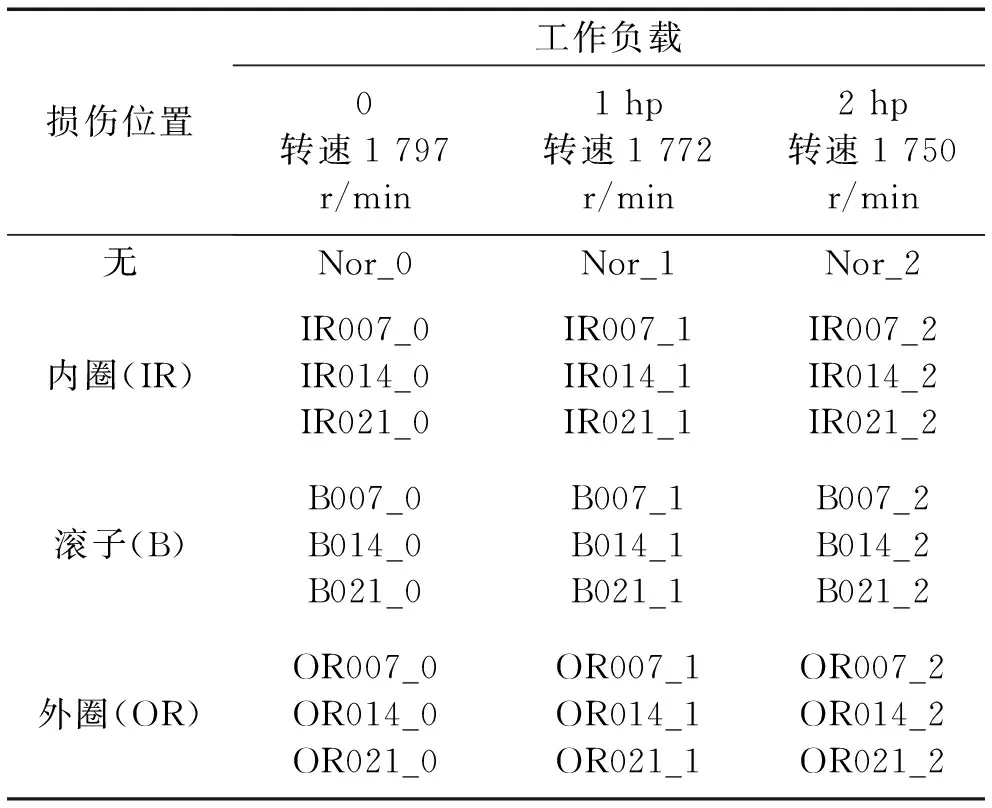
表2 试验数据种类Tab.2 Kinds of test data
滚动轴承故障信号的三种损伤位置分别为内圈(IR)、滚子(B)和外圈(OR),三种工作负载分别为0(1 hp=746 W)、1 hp和2 hp,三种损伤程度分别为7 mil(1 mil=0.025 4 mm)、14 mil和21 mil。表2中滚动轴承故障的具体类别,例如‘IR007_0’中‘IR’代表该故障的故障位置是内圈,‘007’表示该类故障的损伤程度为7 mil,‘_0’表示其工作负载为0。表中各类别试验数据的采样频率为12 kHz,每一类数据取连续102 912点,窗口滑动截取1 024个点作为样本,窗重叠50%,每一类数据得到200个样本,最终共获取6 000个样本。
试验前对原始数据进行短时傅里叶变换,以获得数据中随时间变化的频谱信息,使用Hanmming窗作为窗函数并预设了窗函数长度为120,窗重叠度为50%,最终获得30类数据的共6 000张时频图样本。
依据零样本的原则对数据集进行划分,在27类故障数据中随机选取6类故障样本作为测试集(未见类),剩余数据类别组成训练集(可见类)。总共进行四次随机选取,在四种数据集划分方式下得到数据集A、B、C、D,表3展示了各数据集下的测试类别。在每一种数据划分方式下,数据集中的训练样本数为4 800,测试样本数为1 200。

表3 试验数据集Tab.3 The test data sets
3.2 试验过程与结果分析
试验首先由RDSCNN模型从时频图样本中提取易于学习属性的特征向量,再将特征向量输入到多标签属性学习器,识别故障的属性,最后计算与标签属性之间的余弦距离得到故障类别。
(1) 特征提取试验与结果分析
根据第2.1节所述的RDSCNN模型结构搭建网络,通过反复试验最终确定RDSCNN模型的相关超参数如表4所示。按照输出特征图的大小,表4将整个网络划分为五个模块,模块一输入大小为64×64×3的时频图样本,从模块一至模块四,依次减小特征图大小,最终输出大小为1×128的特征向量。

表4 RDSCNN模型超参数设置Tab.4 Hyper-parameters of RDSCNN
RDSCNN模型在特征提取阶段为使用较大感受野,模块一中残差连接卷积核设置为3×3。为了保留局部细节,模块二和模块三中跳跃连接卷积核设置为1×1,模块四中最后池化层为降低输出维数将池化窗口设置为8×8,其余模块主干网络中卷积核和池化窗口均设置为3×3。整个网络的卷积核数量递增以充分映射特征,各卷积层中卷积核的数目与输出的第三个维度一致,在降低特征图大小的同时增加特征深度。
RDSCNN模型在训练阶段使用交叉熵损失函数,并采用指数衰减法自动调整学习率,设置初始学习率为0.02,衰减步长为40,衰减率为0.97,设置单批次样本数为100个。
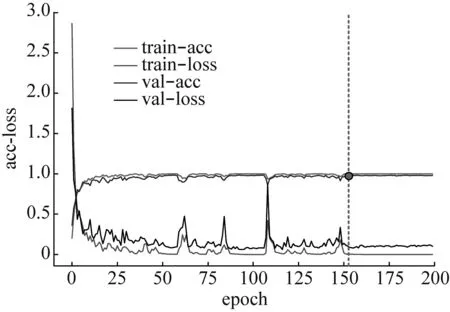
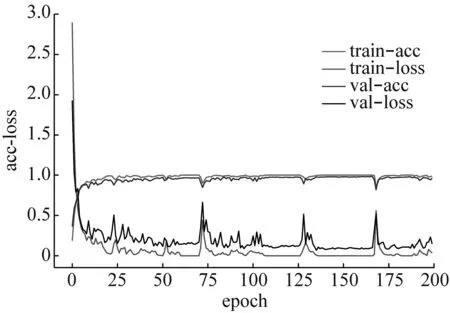
为了验证RDSCNN模型相比当前主流的特征提取模型在特征提取效率和性能上的优越性,本文将其与ResNet50、VGG16和CNN(由5层卷积层和3层全连接层组成)模型进行对比。表5显示了RDSCNN、ResNet50、VGG16和CNN四种不同模型的总参数量、收敛稳定所需要epoch(所有训练样本在模型中完成了一次正向传递和一次反向传递)的数目和训练200个epoch所用的时长。各模型在训练过程中准确率和损失的变化情况如图7所示,为提高对比效果,仅截取前200个epoch进行展示。

表5 特征提取模型训练情况对比Tab.5 Comparison of feature extraction models

(a) RDSCNN模型
(b) ResNet50模型
(c) VGG16模型

(d) CNN模型图7 不同特征提取模型的准确率和损失变化情况Fig.7 Accuracy and loss of different feature extraction models
通过表5可以知道,RDSCNN模型的参数量仅为924 064,CNN模型的参数量为其十倍左右,而ResNet50和VGG16模型的参数量均在其十倍以上;其次,RDSCNN模型训练200个epoch所用的时间仅为223.2 s,较其他三种模型更短;此外,RDSCNN模型在训练125epoch时已经收敛稳定,ResNet50模型在训练150epoch时收敛稳定,如图7中虚线处所示,而VGG16和CNN模型在训练200epoch时仍未稳定收敛。除此之外,从图7中还可以看出,借助卷积网络在自适应特征学习上的优势,各模型的训练准确率都很高,但是在VGG16和CNN模型的训练过程中存在一定的过拟合,其验证集的准确率均低于训练集的准确率。综上所述,相较于其他三种特征提取模型,RDSCNN模型在模型参数量、收敛速度和训练效果等方面具有明显优势。
为进一步验证RDSCNN模型的特征提取能力,采用t-SNE降维算法将原始输入和所提取特征按相似度投影到2维空间中进行分析。在RDSCNN、ResNet50、VGG16和CNN四种特征提取模型中,VGG16和CNN模型的训练效果较差,ResNet50模型的训练效果更接近RDSCNN模型,因此选择ResNet50模型与RDSCNN模型进行特征降维对比。以数据集C为例,将测试集样本作为RDSCNN模型和ResNet50模型的输入,学习得到样本的特征。对原始输入和两个模型输出的样本特征分别进行t-SNE降维可视化,可视化结果如图8所示。
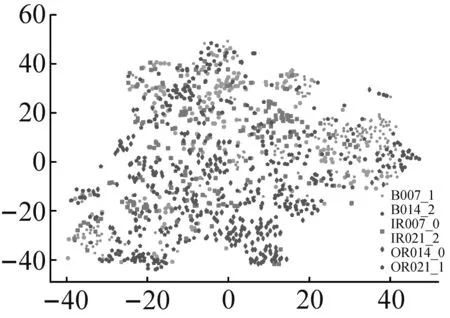
(a) 原始样本输入
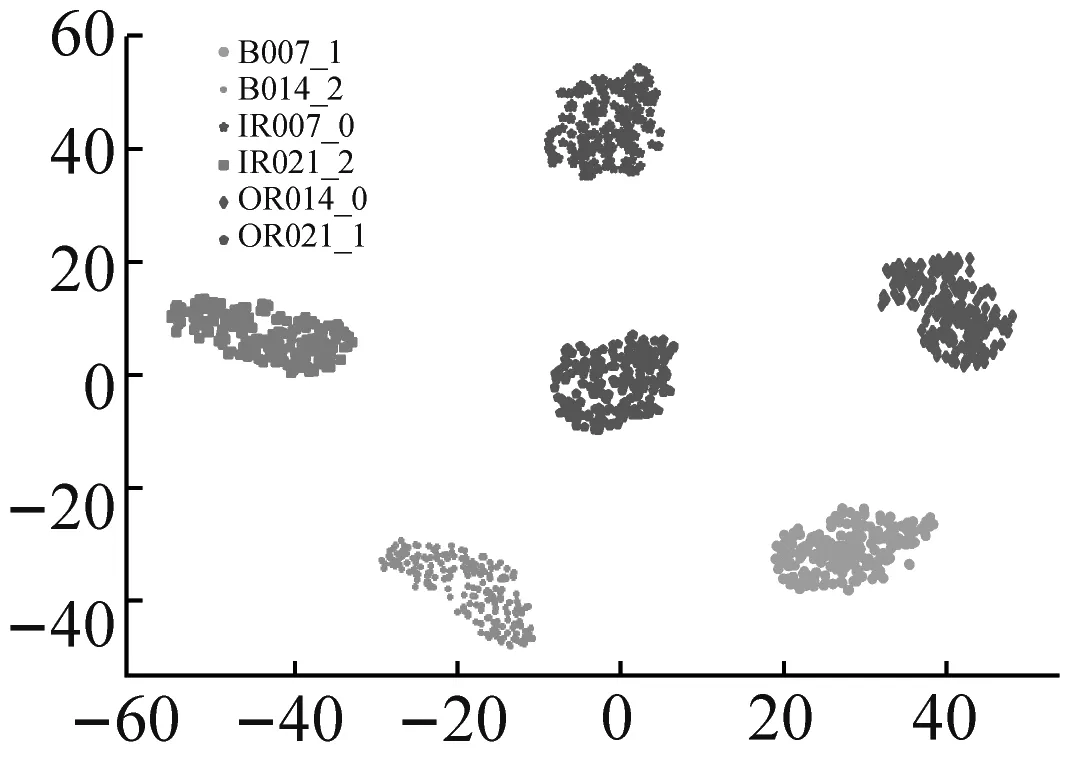
(b) RDSCNN模型输出
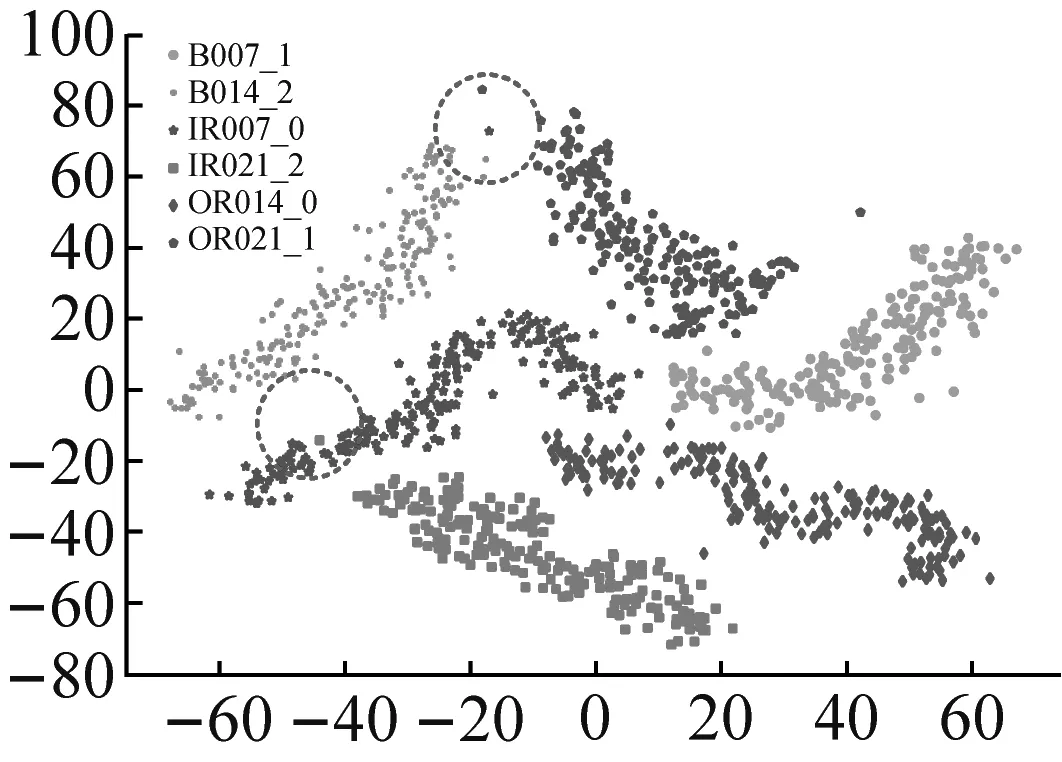
(c) ResNet50模型输出图8 原始输入和不同模型的输出特征可视化Fig.8 Visualization of original input and different models’ output characteristics
图8(a)为原始输入的可视化结果,可以看出原始输入包含很多冗余信息,难以区分各类样本。图8(b)为RDSCNN模型输出特征的可视化结果,经过RDSCNN模型提取特征后,6类故障样本之间界限清晰,完全被区分开,且不同标签的样本在2维空间中分布很集中,没有错分的异类样本。图8(c)为ResNet50模型输出特征的可视化结果,图中各类样本之间有一定的区分性,但界限不清晰,红色虚线圈中部分还存在错分现象。对比图8(b)和图8(c)可知,RDSCNN模型所提取的特征在相同标签下聚合得更集中,可分性更好。
为验证所提取特征的有效性,本文对所提取的特征进行了分类效果的对比。表6展示了基于同一数据集,使用RDSCNN、MLDAM[27]、CNN-RF[28]、1DRCAE方法进行分类试验的精度。可以看出,RDSCNN模型的分类准确率为99.93%,优于其他方法。

表6 各先进识别器的分类精度Tab.6 Classification accuracy of advanced recognizers %
总体而言,RDSCNN模型在参数量最少的情况下,模型的训练速度更快,具有更好的特征提取能力。
(2) 多标签属性学习试验与结果分析
试验按照2.2节中的属性设置原则,为每种滚动轴承故障定义了9维的属性矢量Ai∈R9,以提供故障特征在属性空间映射的对象。该属性矢量由滚动轴承故障的细粒度属性描述推理得到,属性描述基于滚动轴承故障的损伤程度、工作负载和损伤位置。基于属性之间的相关性对互斥属性进行切分,得到三个细分属性矢量a、b、c,三个细分属性矢量均属于实向量空间R3。试验采用热独编码的方式对与故障标签yi对应的细分属性矢量ai、bi、ci进行编码,编码维度为3,得到向量映射onehot(ai)、onehot(bi)、onehot(ci),则与故障标签yi对应的属性矢量编码为Ai=concat(onehot(ai,bi,ci)),例如B007_1的损伤程度为7 mil、工作负载为1 hp、损伤位置为滚子,其属性矢量编码为‘100 010 100’。依据此原则,试验为所有滚动轴承健康状况定义了对应的属性矢量。
本试验的属性学习网络由三个结构参数相同的属性学习器构成,其超参数设置如表7所示。属性学习网络将特征提取网络输出的特征映射到属性空间,单个属性学习器由三层全连接层组成,前两层使用Relu作为激活函数,提高收敛效率,最后一层使用Softmax输出分类结果,选取Adam作为优化器,学习率设置为1×10-4。为防止属性学习器过拟合,在前两层中引入dropout,并分别设置keep_prob分别为0.5和0.7。
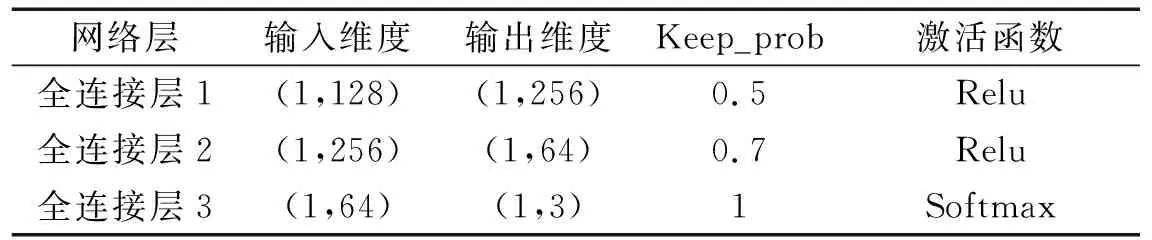
表7 属性学习器超参数设置Tab.7 Hyper-parameters of attribute learner
在表3中的四种数据集下,使用属性学习网络识别训练集(可见类)和测试集(未见类)的各个属性,试验结果中各属性的平均识别准确率如图9所示。
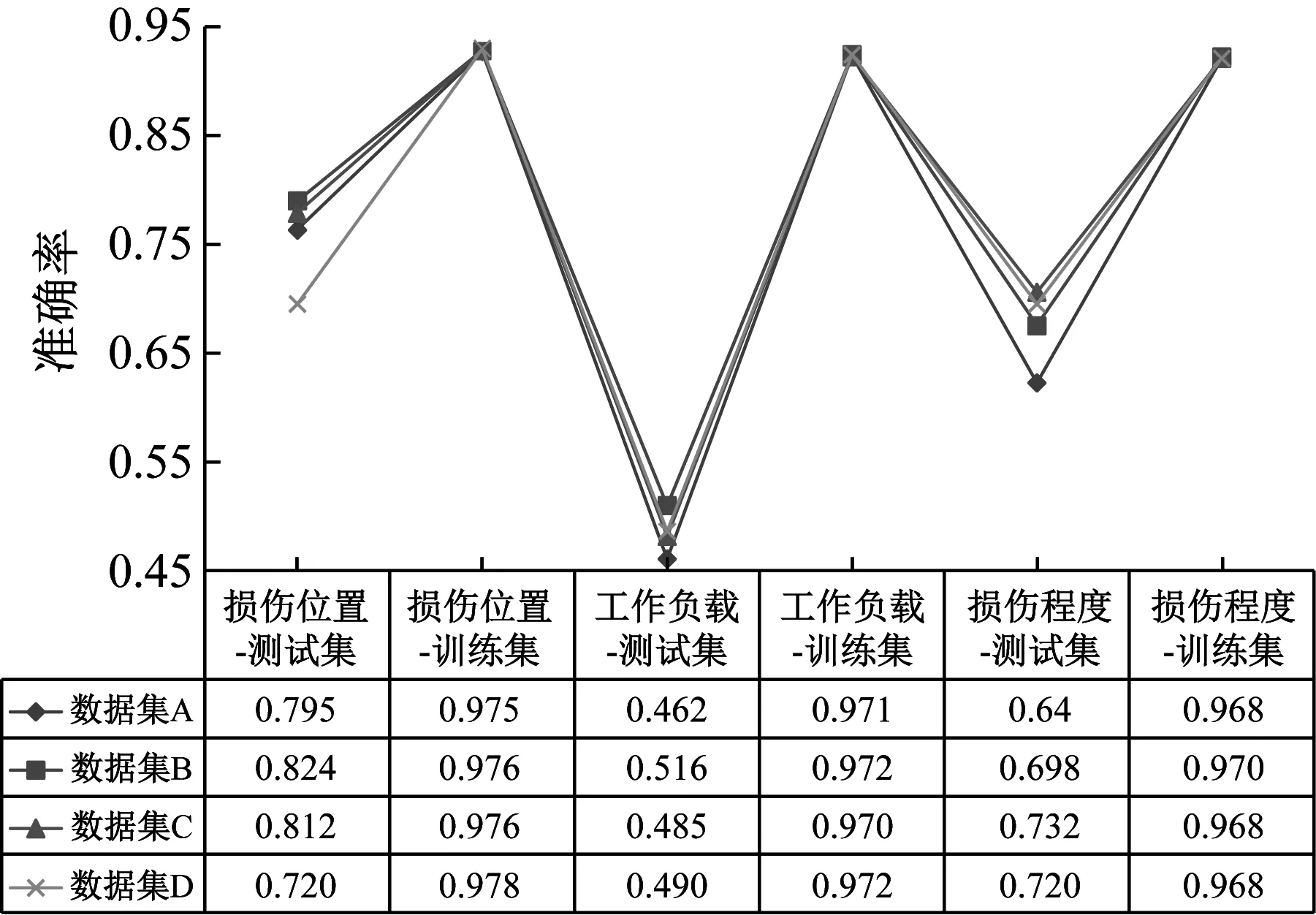
图9 不同数据集划分方式下的属性识别准确率Fig.9 Attribute recognition accuracy under different data set partition methods
横向对比图9中多标签属性学习网络对四种数据集的识别准确率,可知各类识别精度受数据集划分方式的影响不大,平均准确率波动在±4%左右,具有较强的泛化性。多标签属性学习网络对各属性的识别精度均高于33.3%的随机水平,以数据集A为例,多标签属性学习网络对测试集在损伤位置、工作负载和损伤程度上的属性识别准确率分别为79.5%、46.2%和64%,对训练集的识别准确率分别为97.5%、97.1%和96.8%,如图9中折线所示。因为试验遵循零样本设置,所有的测试集样本均未参与训练,且参与训练的测试集与训练集样本没有标签上的交集,因此测试集和训练集的识别准确率无法进行比较。试验结果证明所提出的属性学习网络可以有效学习故障属性。
由多标签属性学习网络得到测试集样本对应的属性矢量后,通过计算各样本属性矢量与各类故障属性编码之间的余弦距离,最终确定故障类别。在四种数据集下,对比MLZSL方法与其他零样本学习方法的识别准确率,如表8所示。
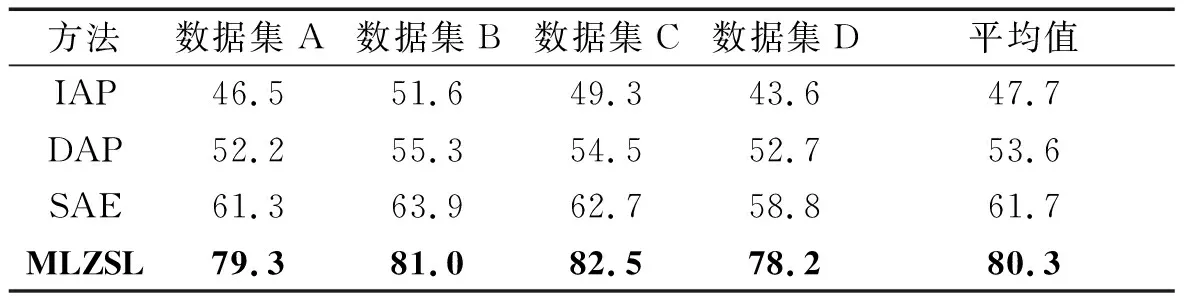
表8 轴承状态的识别准确率Tab.8 Identification accuracy of bearing states
IAP方法将属性层置于训练集标签层与测试集标签层之间,通过迁移训练集样本的标签与属性信息来预测测试集样本的标签,识别效果较差,平均识别准确率最低,仅为47.7%。DAP方法引入了中间层,从训练集样本中学习属性分类器,直接预测测试集样本的属性,但DAP没有学习到属性之间的关系,其平均识别准确率为53.6%,略高于IAP方法。SAE方法使用了自编码器的结构,要求特征输入映射到属性层后,能够重新映射回原来的特征,通过这一结构尽可能保留特征信息,拥有较高的准确率,平均识别准确率为61.7%。MLZSL方法通过有监督的神经网络学习与属性相关的特征,多标签属性学习网络从特征中预测测试集样本的属性,同时考虑了属性之间的关系,其平均诊断准确率为80.3%,高于其他三种方法,如表8所示。
为了更清晰地展示MLZSL方法对测试集故障的识别效果,将其与准确率较高的SAE方法进行对比,以数据集C为例,绘制了两种方法属性识别结果的混淆矩阵,如图10所示。
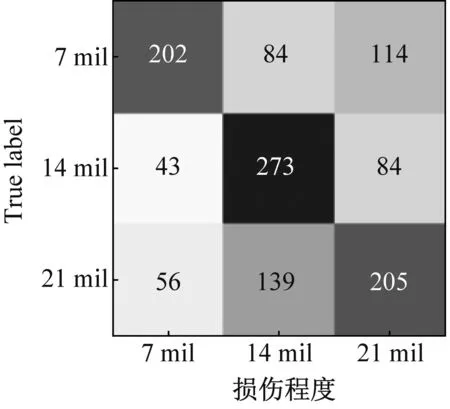
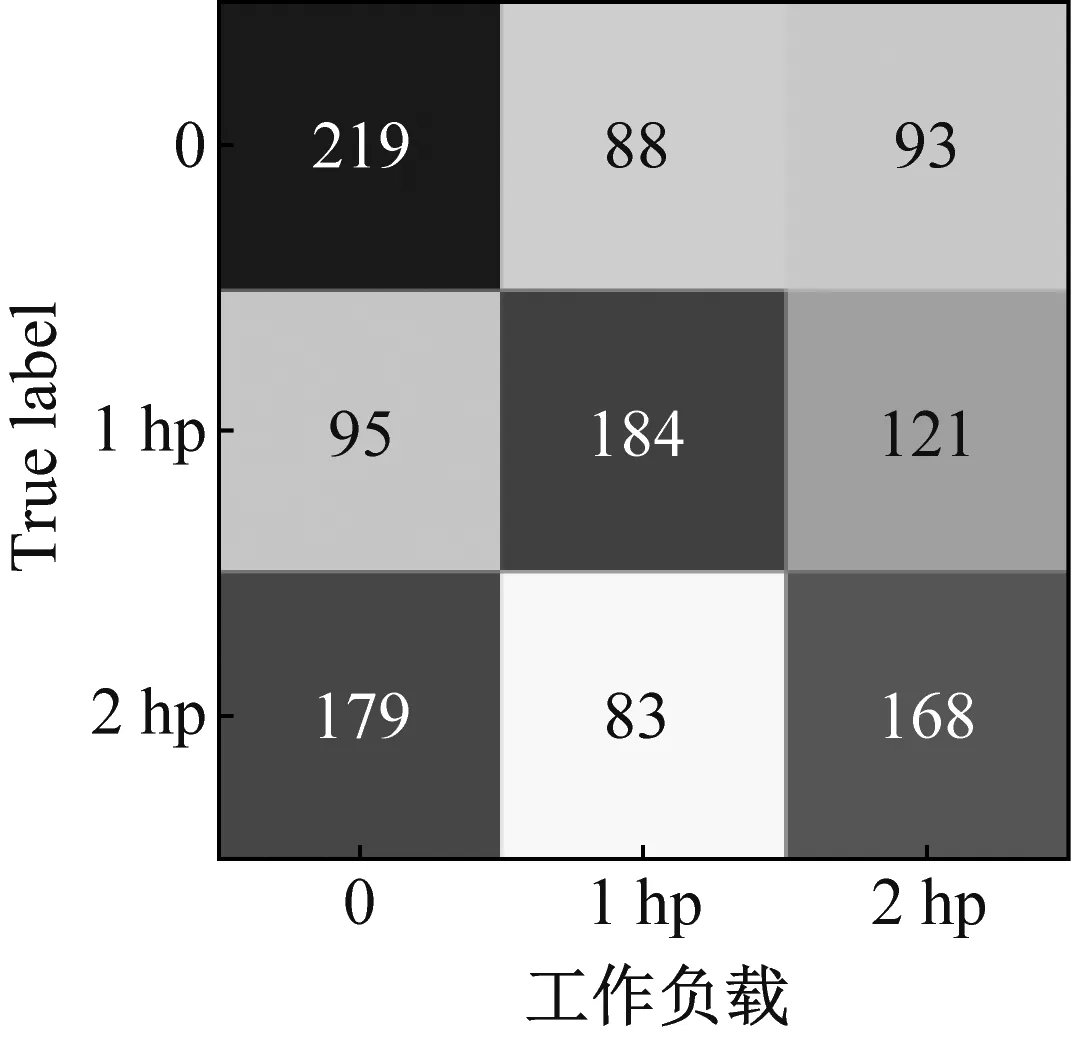
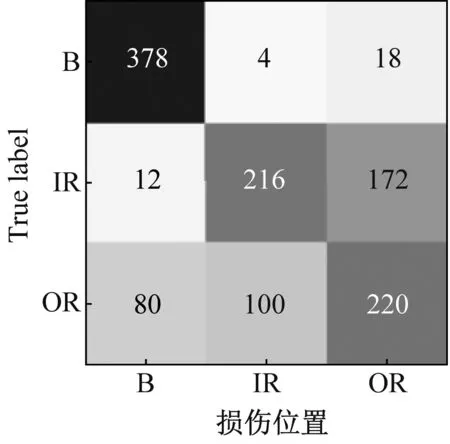
(a) SAE方法

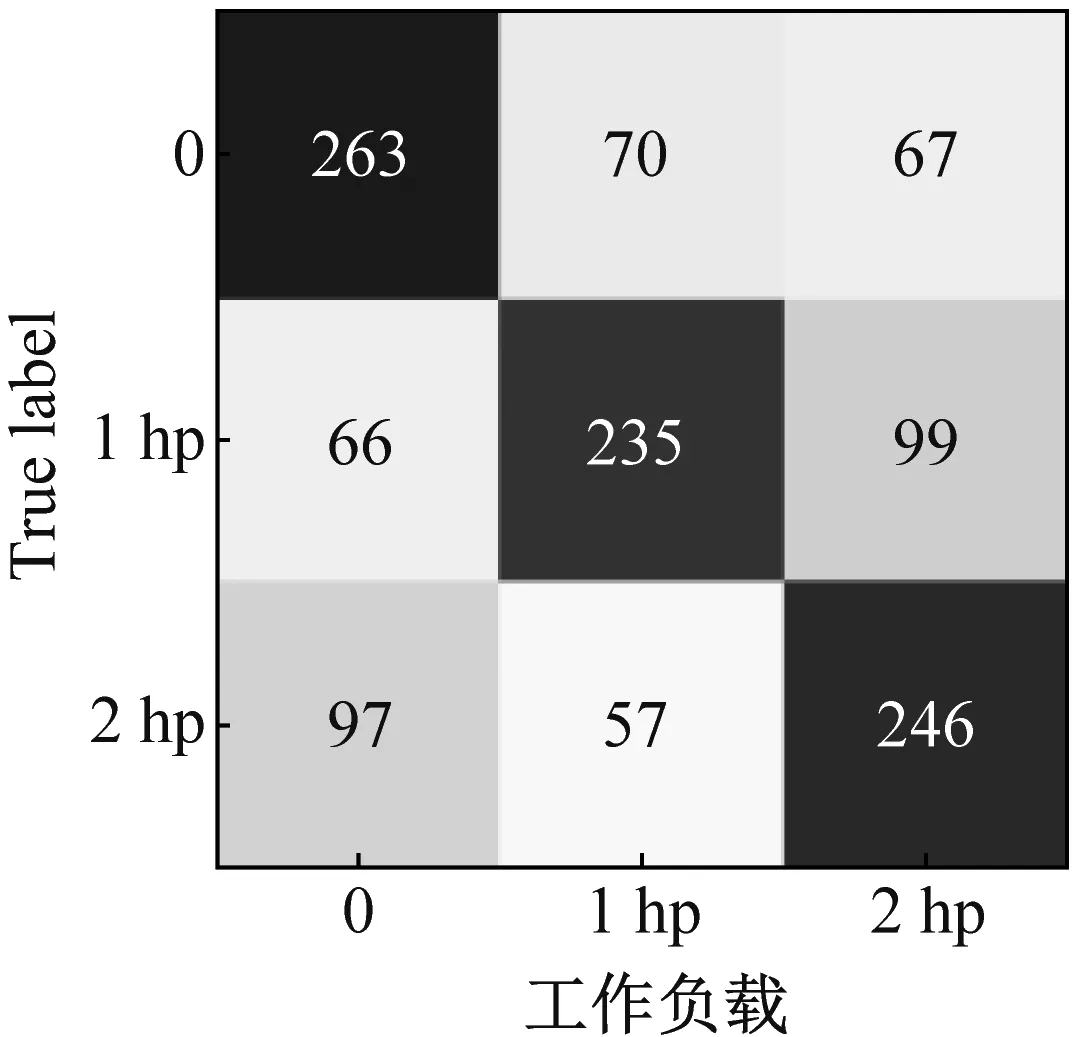

(b) MLZSL方法图10 MLZSL方法和SAE方法的属性预测混淆矩阵Fig.10 Attribute prediction confusion matrix of MLZSL and SAE
图10(a)和图10(b)中,从左至右依次是损伤程度、工作负载和损伤位置的属性识别混淆矩阵,横坐标表示属性的预测类别,纵坐标表示属性的真实类别。对比SAE方法和MLZSL方法对损伤程度、工作负载和损伤位置的属性识别混淆矩阵可知:(1)对于故障样本的损伤程度,用SAE方法识别属性时,三种损伤程度属性均有大量样本被错分,例如图10(a)中,损伤程度为7 mil的故障样本仅有202个被准确识别;而采用MLZSL方法后,对损伤程度的预测准确率大大提升,例如在图10(b)中,损伤程度为7 mil的样本有296个被准确识别,比SAE方法增加了94个。(2)使用SAE方法识别故障样本的工作负载属性时,三种工作负载的预测情况很差,例如图10(a)中,工作负载1 hp和2 hp分别只有184和168个样本被准确识别;采用MLZSL方法后,工作负载预测准确率得到很大改善,例如图10(b)中,工作负载1 hp和2 hp中被正确识别的样本数分别增加了51和78个。(3)在预测样本的损伤位置属性时,SAE方法仅对损伤位置B的预测结果较好,其余属性均存在不同程度的错分,例如图10(a)中,损伤位置IR有172个样本被错分为OR;而使用MLZSL方法识别损伤位置IR时,如图10(b)所示,总共仅有77个样本被错分,其余属性被准确识别的样本也显著增多。综上可知,MLZSL方法在各个属性上的误判数目均低于SAE方法,对各属性的识别能力更优秀,且具有较高的诊断准确率。
综合上述试验验证,MLZSL方法在零样本条件下,能够更准确的学习属性并预测故障类别,且具有较好的泛化性。
4 结 论
本文提出的MLZSL方法由RDSCNN特征提取模型和多标签属性学习网络组成。MLZSL方法实现了故障特征空间到故障属性空间的映射,将可见类的故障属性迁移到未见类,有效地诊断了未见类故障,试验结果表明:
(1) 与常用的特征提取模型相比,RDSCNN模型参数量少、收敛速度快、训练耗时短。该模型提取的特征具有更好的可分性,从所提取的特征中能够更有效的学习与属性相关的信息。
(2) 多标签属性学习网络可以同时映射多个互斥属性,降低了模型复杂度,同时提升了诊断的准确率,在不同的测试数据集中都能够诊断未见类样本,泛化性较好。
(3) 所提出的MLZSL故障诊断方法为每一类故障提供了由属性组成的故障辅助标签,这一属性层介于故障特征层和故障类别层之间。所定义的属性跨越了故障类别界限,不同类别的故障可以共享这些属性。
MLZSL故障诊断方法能够在零样本条件下识别未见类故障,适用范围更广,其轻量化的模型结构使其诊断结果具有很高的时效性,为零样本条件下的轴承故障诊断提供了解决方法。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
