
利用深层语言分析改进中文作文自动评分方法
2022-06-17 09:09巩捷甫王士进宋子尧
中文信息学报 2022年4期
魏 思,巩捷甫,王士进,宋 巍,宋子尧
(1. 科大讯飞股份有限公司 AI研究院,安徽 合肥 230088;2. 首都师范大学 信息工程学院和交叉学科研究院,北京 100056; 3. 认知智能国家重点实验室,安徽 合肥 230088)
0 引言
语言将人紧密地联系在一起。人们在各个人生阶段都在经历着语言的学习和运用。写作是语言学习必不可少的关键环节,可以培养学生的语言理解、运用和表达能力。因此,不管是日常的教学考试,还是中、高考等大型考试,语文写作都是重点考查内容。然而,对学生作文进行评分却给广大教师带来了巨大的工作量。
作文自动评分(Automated Essay Scoring,AES)期望使用机器替代人工评分人员,对作文进行自动评分。机器评分根据量化过的评价标准进行评分,在保证评分科学、合理的前提下,不仅能提高评分效率,而且可以降低评分老师对于评分标准的主观波动性,保证了评分的公平性。
目前国内外已有很多作文自动评分相关的研究,但这些研究主要针对二外以及少数民族的汉语水平考试。1966年开发的(Project Essay Grader,PEG)[1]是AES的先行者。该系统主要从训练样本中抽取某些浅层文本特征,其特点是重结构而相对忽略内容。PEG使用的主要特征包括单词平均长度、作文长度(总字数)、逗号的数量、前置词的数量以及生僻字的数量等。E-rater系统全称是Essay Rater,1992年应用于GMAT考试,2005年开始应用于托福考试。不同于传统的、分析性的作文评分方式,E-rater采用的是整体评分(holistic scoring)[2]。这种评分方式依靠读者的总体印象,综合考虑作文的组织结构、词汇多样性和句法结构等。我国国内也非常重视作文自动评分。1998年和1999年教育部考试中心先后邀请了美国ETS和英国剑桥大学考试委员会的专家来华介绍他们网上评卷和软件及自动评卷系统,希望能够改进我国的自动评分现状。他们以E-rater为例,介绍了其工作原理等,讨论了在我国的大学英语四、六级考试中使用自动评分系统的可行性。
相对来说,汉语作为母语的作文自动评分的相关研究还处于初级阶段,依然停留在比较浅层的语言分析层面,比如字、词、句、浅层语病分析等,缺乏深层语言分析的过程,这与语文作文评分细则是不相符合的。另外,国内也有基于深度神经网络(Deep Neural Networks,DNN)对作文进行篇章表征的自动学习,进而对作文进行自动评分,但这无法解决深度学习模型高性能与低可解释性之间的矛盾。
基于此,本文提出利用深层语言分析改进中文作文自动评分效果的方法。主要贡献包括以下几点:
(1) 实现多层次、多维度深层语言分析功能。从语言运用、语言表达、篇章异常检测、篇章质量评估等多个方面,更加全面、丰富、深入地刻画和表示作文表现出的写作能力。
(2) 融合DNN与多层次、多维度语言分析特征的自适应混合评分方法。研究发现,深层语言分析特征的丰富表达和辨别能力可有效提高中文作文评分效果;年级与主题自适应的模型训练策略,可有效提高模型的迁移能力和预测效果。
本文的组织结构如下: 第1节介绍相关工作;第2节介绍面向中文作文评分的深层语言分析;第3节介绍作文自动评分的实现方案和模型;第4节介绍实验数据、结果及分析;第5节对文章工作进行总结。
1 相关工作
目前,作文自动评分的主流方法主要分为三类: 一类是基于浅层语言分析构建特征的作文自动评分方法;另一类是基于深度学习的端到端作文自动评分方法;第三类是融合浅层语言分析的深度学习方法。
1.1 基于浅层语言分析特征的评分方法
张晋军等提出了一个称为“汉语测试电子评分员”的研究设想,并进行了实践检验[3]。在新疆、内蒙、延边3地选取了几百份少数民族汉语水平考试三级作文预测卷,使用字数、连、介、助动、助词数、标点数、平均句长、句子数、浅层语病错误等量化指标作为评分因素,经过回归分析,选出了5项指标,构建回归模型,并编写程序对这些作文进行评分,电子评分员与人工评分的评分一致性达到了较高的程度。台湾学者林素穗等人在关于非同步式网络教学评价的研究中,设计了一个汉语作文自动评分的程序[4]。该程序基本上是从语法层面上进行作文评价,没有语意分析的成分,通过提取学生作文所采用的字词进行评价。曹亦薇和杨晨对高中生汉语作文进行了自动评分的探索。他们使用202份高中汉语作文作为研究语料,采用了三种方法,分别是: 依据语言形态学特征,使用多元回归的方法进行自动评分;使用词频向量空间模型进行自动评分;依据词频、词频-逆文档频度、信息量的加权向量,使用潜语义分析方法进行自动评分。研究结果表明,三种方法都有一定效果;自动评分和人工评分的相关系数和国外同类研究相比处于中等水平;一致率达到同等水平。按照自动评分与人工评分的相关系数从大到小进行排序,所得到的顺序为: 潜语义分析、向量空间模型、回归模型[5]。
1.2 基于DNN的评分方法
近年来,基于DNN的方法也被应用于作文自动评分。这些方法主要通过深度神经网络模型获取作文的分布式篇章表示进行评分。Dong等[6]使用分层卷积神经网络和平均池化分别对文本的句子层和篇章层表示进行建模。同年,Taghipour等[7]也使用类似的分层网络结构,句子表示是在单词序列上使用卷积网络抽取特征,然后使用循环神经网络在句子表示上进行篇章特征的抽取,最后取每一个隐含层的求和平均得到作文表示。Dong等提出注意力循环卷积网络进行篇章层次建模[8]。近年来,预训练语言模型也被引入作文评分。Yang等整合回归与排序损失微调预训练语言模型进行作文评分[9]。Song等提出多阶段预训练策略[10],模型训练分为: 通用弱监督数据预训练、跨题目监督数据继续预训练以及目标题目数据微调三个阶段。
1.3 融合浅层语言分析特征的DNN评分方法
Uto等提出将手工提取特征与神经网络特征相结合[11],但使用的特征依然基于浅层语言分析结果。
本文工作融入了更多的深层语言分析特征,包括语言运用、语言表达、篇章异常检测以及篇章质量评估等。这些深层语言分析特征显著提高了模型的辨别能力,并提供比深度神经网络模型更好的可解释性。
2 面向中文作文评分的深层语言分析
我们提出的“深层语言分析特征”是指可以明确衡量作文篇章水平的特征,这些特征如语病、优秀表达、语言流畅、结构严谨等都是有明确的与篇章水平相关含义的。“浅层语言分析特征”则是一些与篇章水平无明确联系的篇章属性相关的特征,如简单的统计特征与分布特征。这些特征在前人的工作中被广泛应用,如字词句段数及长度、词性数量及比例、主题分布等潜语义分析等。这些特征有助于区分平均水平作文与较差的作文,因此在面向第二外语的作文评分系统中起到较大作用。但这些浅层特征的区分性和表达能力不足以处理母语写作的作文。
为此,本文在深入分析各个学年段评分规则的基础上,构建面向中文作文评分的多层次、多维度的深层语言分析系统IFlyEA[12],提供深层语言分析评分特征。如图1所示,IFlyEA进行多层次、多维度的语言分析:
• 语言运用层: 该层主要用于判断学生是否能够正确使用字词进行交流,包括拼写和语法错误诊断等。

图1 深层语言分析全景图
• 语言表达层: 该层主要用于判断学生是否能够优雅、有文采地表达自己的想法。IFlyEA提供了典型修辞识别、描写手法识别以及好词好句检测等功能。
• 篇章异常检测: IFlyEA提供抄袭检测、乱写检测、非健康文章识别、流水账识别等篇章级分析。
• 篇章质量评估: IFlyEA提供基于内容、表达、结构、发展相关的11个维度对篇章质量进行评估分析。
本节主要介绍多个层次中可用于作文评分特征构建的深层语言分析模块。第3节将具体介绍如何基于深层语言分析结果构建作文自动评分特征。
2.1 语言运用层分析
正确地运用词语、标点是写作的基础,可在一定程度上有助于衡量学生正确运用语言的能力。本节主要检测作文中的语法错误、标点错误等。
对于语法错误,本文主要聚焦四类: 冗余、缺失、用词不当、乱序[13],表1给出了4类语法错误的示例和修改结果。
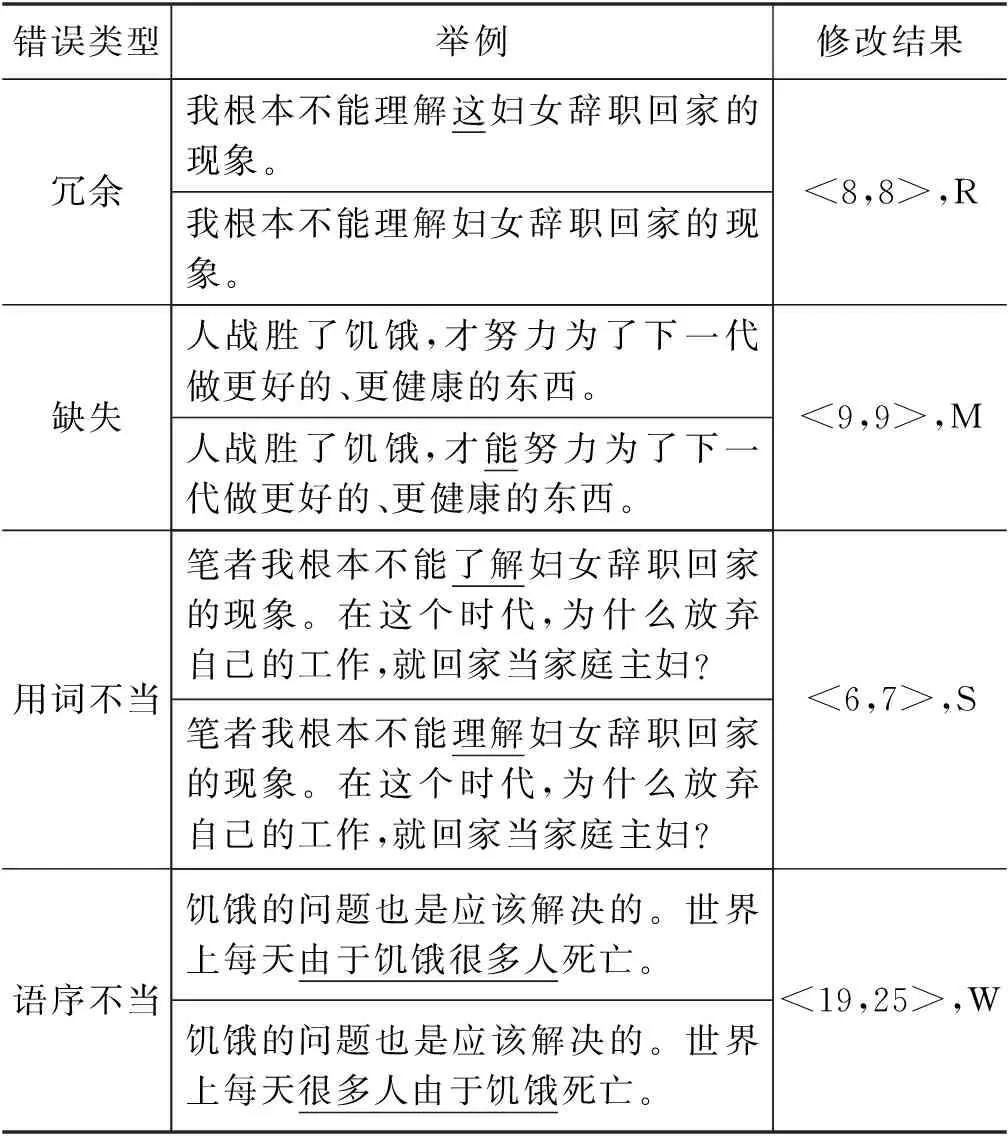
表1 语法错误类型表
系统将判断一句话是否包含语法错误,对于有错误的句子,指出语法错误的具体位置(位置检错),并给出修改意见(改错),整体实现流程如图2所示。

图2 语法纠错方案流程图
我们把语法纠错分为两个阶段,一个是错误识别阶段,另一个是错误纠正阶段。

在错误纠正阶段,我们使用BART模型[19]给出改正结果。具体地,我们将错误识别阶段得到的预测位置进行MASK操作,基于BART的自回归模式,给出候选改正结果。
另外,在用词不当错误类型中,我们将该类型进行细分,包括选词错误以及音近、形近等别字错误。对于别字错误,我们基于标注数据驱动,采用soft-masked BERT模型[20],直接给出别字的错误位置以及修改结果。受其他相关工作的启发[21-23],本文使用音近、形近字表作为辅助资源,进行别字错误后处理。在SIGHAN 2015基准测试[24]中取得了论文相当效果。
本文收集中文作文数据进行语法错误的标注,用于模型训练,相关实验结果如表2所示。

表2 语法检错实验结果表
模型在真实学生作文数据上的位置级别F1值达到70.34%,但乱序类型较低,经过分析发现,乱序的标注主观性偏高。同时,我们在NLPTEA-2020 CGED评测的句子级、位置级两个维度上都获得了排名第一的成绩。
2.2 语言表达层分析
语言表达层的分析对于判断第二语言学习者以及母语低年级写作者的写作水平具有重要作用,但是对于更高年级学生来说,基础语言运用能力不足以区分高水平与一般水平作文。为此,本文提出优秀表达分析,旨在提高识别学生写作的深层表达能力。
本文把优秀表达定义为优美句子、修辞、描写句等。进一步,修辞聚焦到比喻、拟人、排比、引用等,描写聚焦到语言、动作、神态、心理、外貌、景物描写等。按照实现方式,将语言表达层的分析方案分为三类,句内优秀表达句识别、跨句排比识别、索引类引用识别。
2.2.1 句内优秀表达句识别
一般情况下,对于优美句子、比喻、拟人、描写等的优秀表达,都是集中在一个句子内部完成的。另外,我们定义优美句子为能够引起审美感受的句子,这个定义是模糊的,标准是主观的,与其他优秀表达句在一定程度上有重叠,因此,我们以数据驱动和多任务联合的方式进行整体识别。本文设计了一种基于多任务联合学习的句内优秀表达句识别模型,如图3所示。

(5)
其中,i表示第i个任务,Li为第i个任务的损失,λi为第i个任务的损失的权重。
具体实验结果如表3所示,其中,优美句子分不同年级段进行评估,因为评估主观性等问题,指标相对修辞与描写稍低。其与评分的相关系数等,下文将做详细分析。
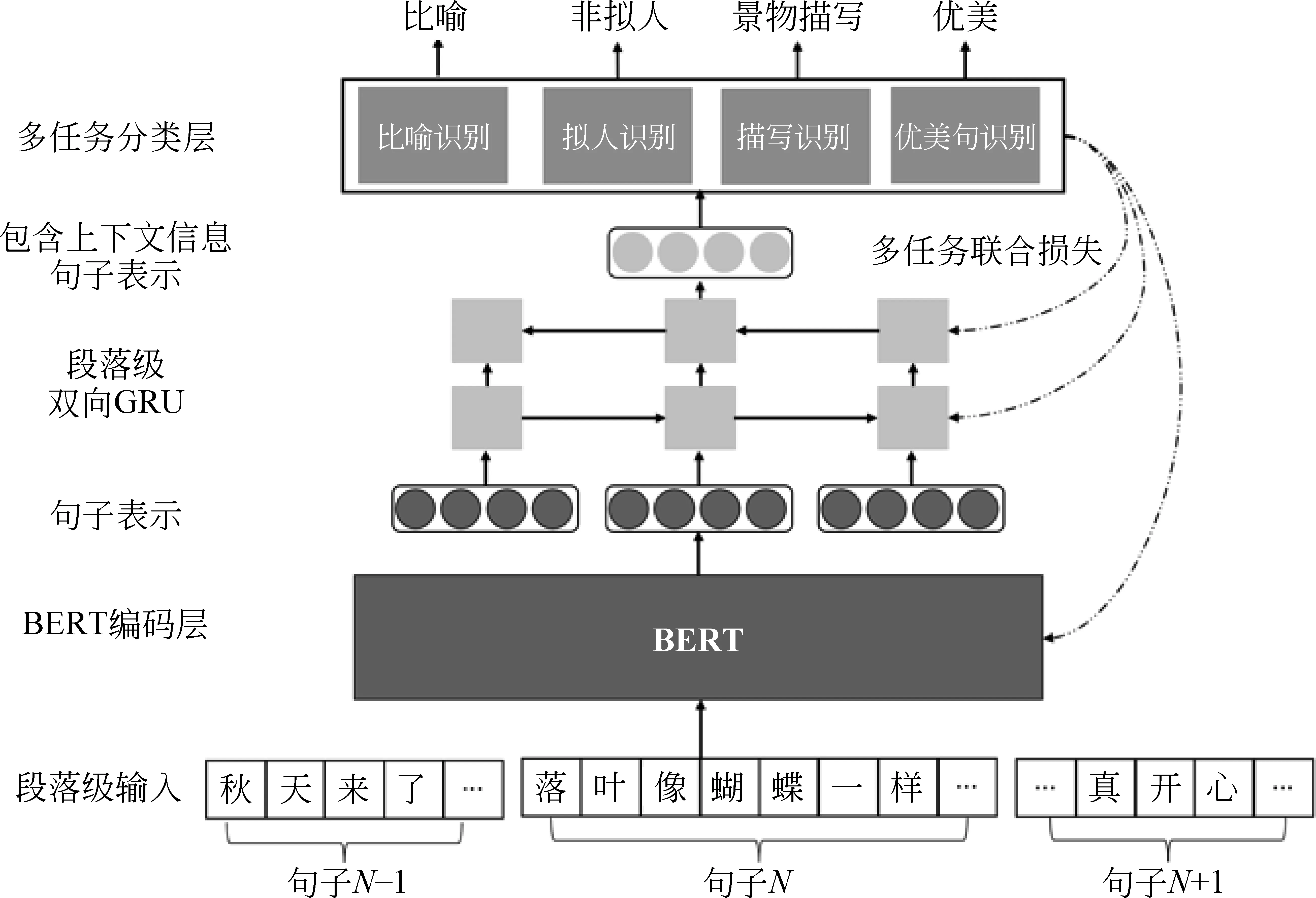
图3 优秀表达层多任务联合学习方案图
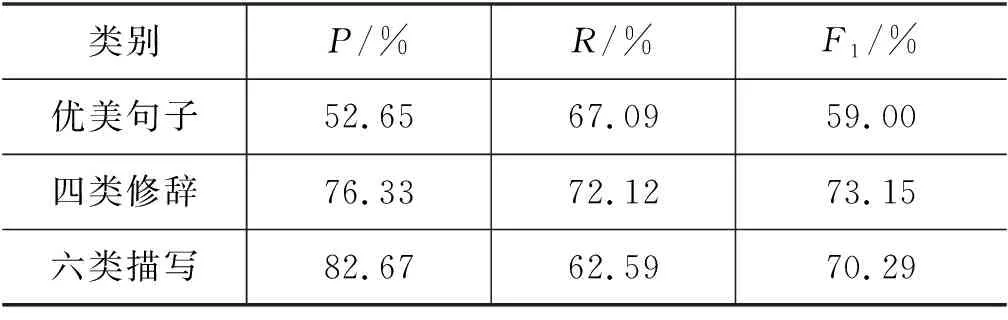
表3 优秀表达句识别实验结果表
2.2.2 跨句排比识别
排比是中文写作中常用的修辞手法。排比句,一般是这样一种结构的句式,位置上临近,语气上一致[26],能够增强气势、给人以精神上的振奋,从而达到让阅卷老师赏心悦目的效果[27]。本文主要采用特征方法来完成排比句识别。主要流程包括字词的存储结构建立、候选排比句抽取、过滤、重组与切分、回填等机制,并考察了词汇、词性、句法角色、分布式语义等多层次匹配特征完成排比句的判别[28-29]。在中文作文数据上的测试结果显示排比句判别F1值达到75%。
2.2.3 索引类引用识别
引用前人的词句,如诗歌、格言、谚语等,来阐释和支持自己的观点,是写作中采用的重要手段。我们从互联网上收集了从诗歌到谚语的大规模引用语料库,并利用信息检索(IR)技术和语义匹配进行引用句检测与识别。学生作文内提及的已入库语句的召回率可以达到96%以上。
2.3 篇章异常检测
篇章异常检测对构建稳健的评分系统很重要。例如,抄袭是一种不好的行为,应该被检测。为此,本文构建了一个范文检测库,并利用IR和语义匹配技术来完成抄袭检测。此外,本文还利用预先训练的检测器完成敏感词、辱骂性词语、乱写等的异常检测。
2.4 篇章质量评估
以上介绍了语言运用、语言表达、篇章异常检测等深层语言分析过程,但基于各分析器所抽取的用于评分的特征更多地是对于篇章相关分析维度的数量的评估,缺乏对于篇章的整体视角的质量评估。
为此,本文基于以上各分析器,从人对于作文质量评估视角出发,从内容、表达、结构、发展四个大维度,基于人工标注的篇章质量评估分档数据,构建了十一个细粒度篇章质量分析器。具体而言,在内容方面,主要包括符合题意、思想健康、内容充实、中心明确、感情真挚;在表达方面,包括规范使用字词、符合习作要求、标点正确以及语言流畅;在结构方面,主要给出结构严谨性;在发展层面,主要分析是否有文采。整体作为篇章质量评估的深层细粒度分析依据。
3 作文自动评分的实现方案和模型
本文聚焦的是小规模定标(500份以下)评分场景。所谓定标评分,一般是给定一个固定的主题或者写作方向,评分人员基本稳定,评分尺度与习惯基本一致。我们可以对当前主题的样本进行筛选,并对筛选的样本进行打分,基于打分结果去训练评分模型或者调整评分方案。
定标评分场景要特别关注两个指标,一个是考察评分之间的相对顺序的相关系数,是为了保障评分的有效性;另一个是为了考查评分与人工打分的一致率,是为了保障评分的准确性。为此,本文设计了如下的作文自动评分方案,并在后续实验中对相关指标进行重点比较。
3.1 作文自动评分方案
在定标评分场景,有多种评分方案进行自动评分。如图4方案①所示,基于当次待评分数据集进行样本筛选与人工定标后,基于语言分析结果进行评分特征抽取,训练专用评分模型进行定标评分。这样的优势是可以很好地利用当次考试的评分习惯和评分分布等,但劣势是无法引入更多的外部数据信息来提升评分效果;另一种方案是我们使用历史作文数据结合DNN模型以及语言分析结果进行通用评分模型训练。这样做的优势是可以利用更多的外部数据信息以及结合深度神经网络模型,但这样做的劣势是无法很好地拟合当次考试的评分习惯。

图4 定标评分场景评分方案图
为此,本文设计了基于通用评分模型的定标评分方案,如图4方案②所示,首先利用历史作文数据结合DNN模型以及多层次、多维度语言分析特征进行通用评分模型训练;之后使用当次数据集定标评分数据进行分数分布学习,既保证了评分效果,也符合了当次数据集的评分习惯。满足了定标评分场景两个特别关注的评分指标。
本文实现了如图4所示方案①与方案②两种评分方案,并在两种评分方案的基础上比较了加入深层语言分析后的评分效果。而实现方案①与方案②,我们要解决两个问题,一个是作文评分特征的抽取;另一个是通用评分模型的设计,后两节将详细介绍。
3.2 多层次、多维度语言分析特征选取
本文基于前面介绍的深层语言分析模块,再配合浅层的一些语言分析结果,构建了本次作文自动评分的多层次、多维度语言分析特征。我们首先分析各特征抽取器抽取的特征与训练集分数数据的相关系数,如表4所示。

表4 语言分析特征与分数相关系数分析表
浅层统计特征为最基本的作文特征,相关系数较高,普遍在0.3~0.5之间;在语言运用层和篇章异常检测层,本文分析了语法类错误、标点错误、可恢复的拼音占比、不健康句子数量、乱写句子占比等,相关系数普遍为负,基本符合预期;在语言表达层,本文分析了修辞以及描写数量与评分的相关系数,基本在0.1左右;在篇章质量评估层,大部分篇章级的质量评估与评分相关系数在0.3左右,与语言运用、语言表达和篇章异常检测层相比,篇章质量评估层相关系数较高。
后续基于语言分析特征与评分相关系数的分析结果,进行了部分特征的扩充与完善,构成了后续评分实验依赖的相关浅层特征与深层语言分析特征,如表5所示。

表5 作文特征抽取表
3.3 融合DNN与语言分析特征的自适应评分
基于语言分析的特征工程方法与基于DNN方法各有优势。为了更好地结合两者的优势,我们提出融合DNN与多层次、多维度语言分析特征的自适应混合评分方法,如图5所示。模型融入了浅层与深层等多层次、多维度语言分析特征,并提出通用预训练与定标数据微调的二阶段学习策略,以应对年级、主题变化导致的领域迁移问题。
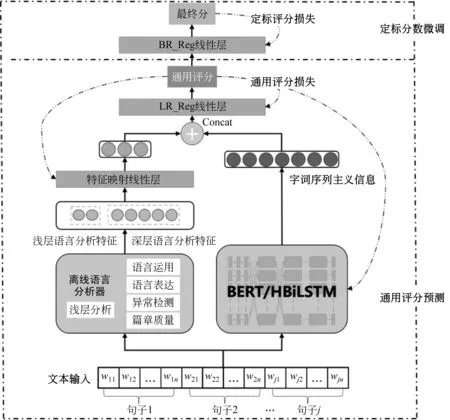
图5 融合DNN与语言分析特征的自适应评分方法
3.3.1 作文编码器
首先介绍通用评分模型,该模型可用于构建面向任何一个作文题目的评分模型。
假设作文K有j个句子,其中第i句有一个词序列si={wi1,wi2,…,win},篇章由全部句子的词序列{s1,s2,…,sj}组成。本文使用DNN模型对篇章进行编码,得到篇章表征K,这是基于字词序列的语义信息。本文分别使用了HBiLSTM模型[30]和BERT模型[25]作为篇章编码的DNN架构。
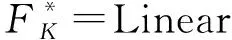
3.3.2 年级与主题自适应迁移评分
由于不同年级的评分标准有差异,我们希望提高模型的自适应能力,同时尽量避免维护多个模型。因此,我们将不同年级的评分视为多个任务。不同年级的评分任务,共享作文的篇章级别表示eK,但使用独立的全连接回归评分层。如式(6)所示,Y通用_年级i为年级i的回归评分模型的预测结果,其中,LR_Reg为线性回归评分层。
Y通用_年级i=LR_Reg年级i(eK)
(6)
我们可以利用多个年级的学生作文,联合训练该年级自适应的通用评分模型。
给定年级自适应通用评分模型,针对新的评分主题,我们希望能够进一步拟合当次作文集的打分习惯与分布。因此,我们将不同年级的通用评分模型的预测结果作为输入,使用当次作文数据集额外训练一个贝叶斯岭回归模型(BR_Reg),如式(7)所示。
Y定标=BR_Reg({Y通用_年级i})
(7)
多个年级的通用评分模型相当于从不同视角和标准下评估同一作文,提供了更为全面的描述信息。我们在实验中发现,这种策略比仅利用相对应年级的通用评分模型预测结果更为有效。
这种主题自适应策略可以基于较少的数据,快速针对当次考试的打分习惯与分布进行分数调整,得到符合当次考试的标准和分布的最终分。
4 实验
4.1 数据集
本文所用数据集主要分为两部分。一部分为通用评分数据集: 用于通用评分模型训练,使用网上开源的5万篇小学学段作文语料,包含一至六年级各约8 500篇作文,按照各年级评分要求与细则进行人工标注。另一部分为定标评分数据集: 抽取小学三至六年级四个学段共计51个主题作文数据,每个主题定标集含300~500篇作文,测试集20篇,具体如表6所示。

表6 小学三至六年级作文数据统计分析表
其中,定标评分数据集,标注人员均完成双评、仲裁等标注质检等工作。
4.2 评价指标
本文通过以下指标进行评估: 平均分差、相关系数、评分一致率。
(8)
机器得分与人工评分的相关系数计算如式(9)所示。
(9)
评分一致率如式(10)所示,主要参考计算机智能辅助评分系统[31]评估固定分差内数据占比的统计方法。
(10)
4.3 方法对比
本文挑选三组基线方法进行对比,包括基于语言分析特征的评分方法、基于DNN的评分方法以及融合浅层语言分析特征的DNN评分方法。本文提出融合DNN与多层次、多维度语言分析特征的自适应混合评分方法。
后续相关特征分析包括浅层特征与全部特征,其中,全部特征为包含浅层特征与深层特征的多层次、多维度的语言分析特征。
●基于语言分析特征的评分: 本文使用GBDT作为评分模型,分别使用浅层特征和全部特征进行实验。
●基于DNN的评分: 本文使用HBiLSTM及BERT等DNN模型对作文进行评分。
●融合浅层语言分析特征的DNN评分: 相关模型结构如图5所示。其中分别使用了两种常用的DNN模型: HBiLSTM模型和BERT模型;浅层特征共计57维。
●融合多层次、多维度语言分析特征的自适应DNN评分: 相关模型结构如图5所示。其中分别使用了两种常用的DNN模型: HBiLSTM模型和BERT模型;全部特征共计187维。
4.4 模型实现细节
为了便于模型训练,将分数归一化到0到1之间。训练时均使用均方误差作为损失函数。
●GBDT模型: 设置学习器个数为100,学习率为0.1。
●HBiLSTM模型: 实验中句子层BiLSTM和篇章层BiLSTM的隐藏层维度均为128;通用模型训练时使用AdamW[32]作为优化器,学习率为0.001。
●BERT模型: BERT模型使用BERT-base中文模型。通用模型训练时使用AdamW作为优化器,学习率为1e-5。
●特征映射线性层: 输出维度为30。
●通用评分LR_Reg层: 线性回归模型输入为outputDNN+30维,输出为1维。
●定标微调BR_Reg层: 贝叶斯岭回归模型输入为6维,输出为1维。
4.5 整体实验
本文基于小学数据集开展相关实验及分析工作。通用评分阶段,使用通用评分数据集5万篇训练通用模型。定标微调阶段,使用定标数据集中每个主题的训练集进行定标评分微调。实验时,通用评分阶段与定标微调阶段均使用定标数据集中测试集进行相关测试,每套试题单独进行测试,取宏平均用于最终实验指标分析。其中,在通用评分阶段,使用该主题对应年级的预测分数作为预测结果。具体实验结果如表7所示。

表7 评分数据实验结果表
首先对比图4方案①设置下各方法的表现,即不使用通用评分模型,仅使用当次考试数据进行定标评分。实验发现,全部特征在相关系数、评分一致率方面相比较浅层特征结果有较大幅度提升,相关系数提升0.049,评分一致率提升3.3%,证明定标评分场景深层语言分析的有效性。而使用DNN模型进行定标评分实验,在评分一致率、相关系数方面优于基于浅层特征的定标评分结果,但弱于基于全部特征的定标评分结果。可见,在小规模定标(500以下)场景,基于DNN模型只通过字词序列学到了浅层以及一部分深层的语言特征,并没有充分发挥出DNN的序列表征优势。
继续采用图4中实验方案②,该方案分为两个步骤。第一步: 使用通用评分模型进行相关实验,更加关注相关系数;第二步: 在通用评分结果基础上,使用每套试题定标数据进行分数微调,看评分一致率提升情况。
在第一步,通过实验可以发现,在相关系数方面,加入深层语言分析特征后的全部特征实验结果优于仅仅加入浅层语言分析特征结果优于不加入特征的评分结果。具体地,BERT(通用)+全部特征相比较BERT(通用)+浅层特征,在相关系数方面提升0.015;HBiLSTM(通用)+全部特征相比较HBiLSTM(通用)+浅层特征,在相关系数方面提升0.01,提升较为稳定。基于BERT模型的相关实验结果整体优于基于HBiLSTM模型的结果。同时,为了公平对比,本文也使用传统机器学习方法对全部特征进行通用评分,发现结果弱于基于DNN+特征相关方法,证明DNN相关表示对评分效果提升有积极帮助。
在第二步,如式(7)所示,我们使用线性层对结果进行定标微调,以适应当前主题作文的打分习惯与分布。微调后,评分一致率有大幅度提升。同时,在定标场景下,加入深层语言分析特征后,相对于只有浅层语言分析特征的模型,相关系数的提升结论与通用评分阶段实验结论基本一致,证明深层语言分析的有效性。
同时,本文比较了通用评分场景与定标评分场景中评分一致率与相关系数标准差。相较于通用评分场景,定标评分场景各方法的评分一致率的标准差分别从0.1左右降到了0.07左右,相关系数的标准差分别从0.2左右降到了0.15左右,各主题的评分效果比较稳定。
同时,我们与人人指标进行对比,评估机器评分效果。如表8所示,测试集中的每份试卷均采用双评标注,并给出仲裁分。为了公平起见,本文在此处实验阶段,机器分不与仲裁分进行比较,而是与人1和人2的分数进行比较,选取平均值用于与人人结果的比较。

表8 小学与人人结果对比表
从对比中可以看出,机器与人1和人2的平均相关系数为0.585,超过人人指标的0.552,且在评分一致率(<10%)方面,人机平均评分一致率(<10%)为84.3%,也超过人人指标的78.4%。可以说,机器在一定程度上可以超过人的评分效果,这为在更多场景的评分使用提供了保障。
4.6 消融实验
为了验证不同深层语言分析中不同层对评分效果提升的影响,本文在BERT(通用)+全部特征+定标的最优模型基础上做了多组消融实验,每次只移除一层,分别移除了语言运用、语言表达、篇章异常检测和篇章质量评估层相关特征来分析其作用。
消融实验结果如表9所示,移除语言运用层特征对相关系数有一定影响,表明在小学作文中语言运用是很重要的考察点。移除语言表达层特征对评分影响相对较弱,可能是因为优美句子和描写的召回率较低,导致部分语言表达未能识别。移除篇章异常检测和篇章质量评估特征后相关系数下降较明显,说明篇章级相关特征对评分效果的提升作用很大。

表9 消融实验结果
5 总结
本文针对中文作文自动评分任务,引入了更多深层语言分析能力,使用融合DNN与多层次、多维度语言分析特征的自适应混合评分方法,有效提升了语文作文评分效果。在深层语言分析基础上,还可以将多个层次、多个维度的分析进行量化展示,提供批改结果,为后续针对学生作文的个性化诊断和学习提升提供更多的诊断依据,具有非常大的潜力。
尽管本文的面向语文作文评分的深层语言分析能力已经达到国内领先水平,但其中修辞分析、篇章结构分析等研究问题还有很大的探索和提高空间。深层语言分析需要多个模块进行处理,特征获取效率较低,将多个模块整合,使用通用的底层共享模型来获取各种深层语言分析值得进一步的探索。目前,预训练语言模型处理长文本时计算负载较大,如何提高预训练语言模型在实际应用场景下的高效配置,进一步提高多层次、多维度深层语言分析的效果和效率也是未来进一步研究的内容。
猜你喜欢
水土保持学报(2022年5期)2022-10-10
纺织标准与质量(2022年2期)2022-07-12
今日农业(2021年19期)2022-01-12
建材发展导向(2021年7期)2021-07-16
建材发展导向(2021年24期)2021-02-12
矿产勘查(2020年11期)2020-12-25
马克思主义哲学研究(2020年2期)2020-07-21
水利规划与设计(2020年1期)2020-05-25
雷达学报(2018年3期)2018-07-18
吉林农业(2016年4期)2016-05-14
