
应用竹类叶片性状特征和支持向量机算法的竹种识别1)
2022-06-24 08:13周必铙卞丽丽徐薪璐姚文静
东北林业大学学报 2022年5期
周必铙 卞丽丽 徐薪璐 姚文静
(南京林业大学,南京,210037)
竹类植物为多年生非木质常绿植物,属于禾本科(Poaceae)竹亚科(Bambusoideae)。竹类植物生长快、可再生性强、用途广泛,在发展绿色经济、保护生态环境、应对气候变化、促进生态文明建设等方面都发挥着独特作用[1-5]。国内竹亚科传统分类方法主要建立在耿氏系统上,以花序和地下茎性状为主要分类特征,再结合营养体特点划分属及以下类群。由于竹子开花结果不常见,以花果为分类依据应用困难,实际种类识别多是根据营养体展开[6-7]。竹类营养体多变,在同一种群中往往存在多种表型且季节性变化明显,传统分类由此引入模式种概念[8-10]。但模式种往往仅代表种群中某一个体在某一时期的性状,当遇到同一性状有多种表现型时,根据模式种进行分类容易导致分类混乱[11]。
竹类植物叶片四季常绿,同一种竹子叶片性状特征相对较稳定。曾有学者对竹类植物叶片进行解剖研究,并将解剖结构作为竹种分类的参考[12-13]。竹类植物的叶片结构为二维平面,颜色、形状和纹理信息都包含在内,更便于采用计算机进行图像收集及数据化处理。基于叶片特征的竹种分类法与传统的模式种法相比,通过计算机系统建立不同竹种相应的数据库,每类竹种的特征数据均从种群水平获得,减少了种群中特殊个体的影响。通过计算机视觉技术获取的数据由该竹种本身特性决定,会在一定范围内波动,更能代表该竹种的实际情况。
支持向量机算法(SVM)最早于1963年由Vladimir N. Vapnik和Alexey Ya. Chervonenkis提出。此后Corinna Cortes与Vladimir Vapnik对原算法进行了改进,将原来的“硬分隔面”变为“软分隔面”,形成了现在所用的支持向量机算法的雏形[14]。支持向量机算法不涉及统计学的相关概念,其原理是将样本放在一个空间中,在同一空间中寻找能最好划分类别的超平面。当前维度没有合适的平面时,就将样本映射到更高维度的空间,直至找到最合适的超平面[15]。历经多年的发展,支持向量机算法的理论逐渐完善,演变为一类常用的小样本分类算法[16]。实际应用中,通过选取合适的核函数,并对参数进行调整,使得机器学习中损失函数的值达到较低,保证通过有限的训练样本得到较小误差[17]。
支持向量机分类器在观赏植物和农业上已经有了广泛的应用。魏蕾等[18]以木瓜、三角枫、女贞和五角枫的叶片为材料,对叶片图像进行预处理后,提取并优化出10个叶片形状参数作为分类特征,输入支持向量机模型后取得了较好的识别准确率;陈淑君等[19]选取了9种室内常见盆栽各28个样本,对植物对象结合色彩信息进行分割,提取信息并使用支持向量机分类器进行分类,识别率达90%左右;秦丰等[20]以采集的苜蓿叶片为材料,进行人工裁剪并结合图像分割,建立病害识别支持向量机模型,在测试集上识别准确度达到80%以上;李婵等[21]提取了农业区域8种植物叶片的光谱数据,利用一阶微分光谱结合支持向量机的方法能够较好地对不同植被区域进行识别。
目前,支持向量机算法模型在竹子分类中的应用还较少。本研究通过计算机编程提取了70个竹种叶片的相关性状特征,初步实现了数据化,建立了竹类植物的叶片数据库。此外,通过调节支持向量机模型参数提高模型的分类准确度,为基于计算机辅助竹类植物的分类识别提供智能方法。
1 材料与方法
1.1 材料来源
试验共采集了70个竹种(包含变种、变型和品种)的7 000片竹叶,其中58种采自江苏省南京市南京林业大学校园(118°48′51″E,32°4′59″N)和南京林业大学白马基地竹种园(119°7′42″E,31°37′55″N);4种采自云南省昆明市西南林业大学校园(102°45′26″E,25°3′44″N);3种采自贵州省遵义市楚米镇高山村(106°42′49″E,28°16′35″N);2种采自贵州省遵义市马鬃乡(106°58′39″E,28°13′51″N);3种采自贵州省遵义市羊蹬镇(106°57′52″E,28°43′20″N)。
1.2 叶片的采集和测量
试验采集的70个竹种(包含变种、变型和品种)的学名和属名根据《中国植物志》[22]和《The bamboos of the world》[23]列表(见表1)。每个竹种选择3株以上进行随机采样,采样时选择竹子中部功能成熟叶片。每个竹种采集100片竹叶,将采集的叶片放入装有湿报纸的密封聚乙烯袋中以保持水分。对于较远地区,为防叶片腐烂,使用冰盒将采集的叶片带回实验室进行图像扫描。

表1 竹种学名及收集信息

续(表1)
使用HP Scanjet 4850扫描仪(Hewlett-Packard Company,Palo Alto,CA)获取叶片图像,以300 dpi分辨率保存为位图图像。扫描后使用python语言(版本python 3.7)结合第三方库OpenCV(版本opencv-python 4.4.0.44)识别图像并测算叶片的长度、宽度、面积、周长和最小外接圆面积,同时计算出叶片外接矩形面积、叶片周长与面积的比值、叶片面积与外接矩形面积的比值和与叶片面积相等圆的直径,共9个指标作为分类特征。利用scikit-learn(版本0.21.3)建立支持向量机算法分类模型,输入分类特征对70个竹种进行分类。
1.3 叶片形态指标
叶片长(L)、宽(W)、周长(PM)、面积(S)和最小外接圆面积(MCA)由python语言结合第三方库自动识别图像获得,其中叶长为叶片长轴方向最大距离;叶宽为叶片短轴方向最大距离;叶周长为叶片外轮廓的长度;叶面积为叶片外轮廓的面积;最小外接圆面积由程序根据叶片形状自动计算。
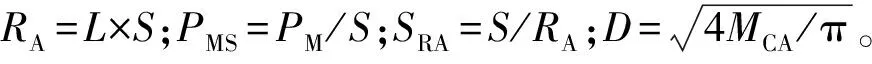
使用准确率(A)指标评价模型的总体分类能力,使用精确率(P)指标评价模型对单一竹种的分类能力,计算方式如下:A=(TN+TP)/(TN+FN+TP+FP);P=TP/(TP+FP)。式中,TN为预测负样本(预测正确);FP为预测正样本(预测错误);FN为预测负样本(预测错误);TP为预测正样本(预测正确)。
1.4 支持向量机分类模型的建立
模型建立最主要的任务是核函数的选择与参数的确定。SVM的核函数主要有Sigmoid核函数、多项式核函数(Polynomial)、线性核函数(Linear kernel)与RBF核函数(Radial Basis Function)。其中,RBF是分类研究中普遍使用的一类核函数。
使用支持向量机算法建立分类模型,首先将原始数据集划分为训练集和测试集,使用训练集的数据进行模型训练;然后在模型训练的过程中,选择RBF核函数,优化模型参数;最后利用测试集进行模型测试,验证其分类准确率,以评估模型的可行性和有效性(见图1)。

图1 模型建立流程
本研究引入RBF函数作为核函数,其公式如下:κ(x1,x2)=exp(((-‖x1-x2‖2)/σ2)),γ=1/2σ2。式中,κ(x1,x2)为核函数,x1、x2分别为不同的样本,γ为参数,σ为参数。
支持向量机算法的惩罚系数(C)和核函数的参数(γ)是可调节参数,用于调节分类错误的容忍度。对于惩罚系数(C)和参数(γ)确定,大多采用网格法在一定范围内进行穷举或直接采用算法设定的默认参数值。本研究在一定范围内通过程序进行参数优化:确定C值时,以γ=0.1为定值,C∈[1,1200];确定γ值时,以C=1 000为定值,γ∈(0,1.6]。
由图2可知,经支持向量机分类器训练得到的模型更适于训练集的分类。测试集的准确率较训练样本低,并随着参数的增加,识别准确率呈现先上升后保持平稳的趋势。随着C与γ的增大,训练集和测试集的准确率都有一定程度的增加,但到达一定值后准确率不再明显提升。当C=1 000、γ=0.1时,测试集准确率的提高能力趋于平稳,随着C值的增大,支持向量机模型对分类错误的容忍度下降。当C趋向于无穷大时,支持向量机模型不允许出现分类误差,此时可能发生拟合;当C趋向于无穷小时,支持向量机模型不再关注分类的正确性,无法得到有意义的解,模型在训练集和测试集中的分类准确度都极低,即发生了欠拟合。因此,综合考虑确定支持向量机模型参数为C=1000、γ=0.1。

A.惩罚系数(C)固定,参数γ变化;B.参数γ固定,惩罚系数(C)变化。
2 结果与分析
2.1 分类性状特征的选择
分类性状特征的选择对于分类器的训练很重要,直接影响最终的分类效果。过多的性状特征进行组合会降低各特征的贡献率,出现冗余现象,同时还会导致分类器训练的时间成本增加。
由表2可知,本试验最初选取了9个叶片性状作为分类特征。为了测试不同性状特征的区分能力,先是利用单个性状特征进行分类,竹种识别准确率为10%~20%。根据叶面积与最小外接矩形面积的比为特征识别准确率最低,准确率仅为9.7%,根据叶宽特征识别准确率最高,准确率为17.7%。由此可知,根据单个叶片特征分类的准确率较低,若想获得高准确率的分类模型,必须考虑使用多个分类特征进行组合。
为了比较不同特征组合的效果并简化输出,将不同分类特征进行排序,依次累加进行分类器的训练。不论是从上往下还是从下往上,当增加第2个分类特征时,分类器的准确率可以得到大幅提升,累加5个叶片特征后,增加分类特征数量对提高分类器准确率的效果不明显,而且每次累加后模型准确率提高的幅度不尽相同,甚至出现识别准确率下降。
由于叶片“外接矩形面积”为叶长和叶宽计算所得,且对分类准确率有负贡献,“最小外接圆面积”由叶面积计算所得,所以将其舍去。通过特征累加可知,使用5个分类特征可以得到较好的分类准确度。对“叶面积与外接矩形面积的比”和“叶周长与叶面积的比”分别与叶长、叶宽、叶面积和叶周长4个特征组合建立模型后,发现由“叶周长与叶面积的比”所建立模型的准确率较高。因此,确定使用的5个分类特征为叶长、叶宽、叶面积、叶周长、叶周长与叶面积的比。
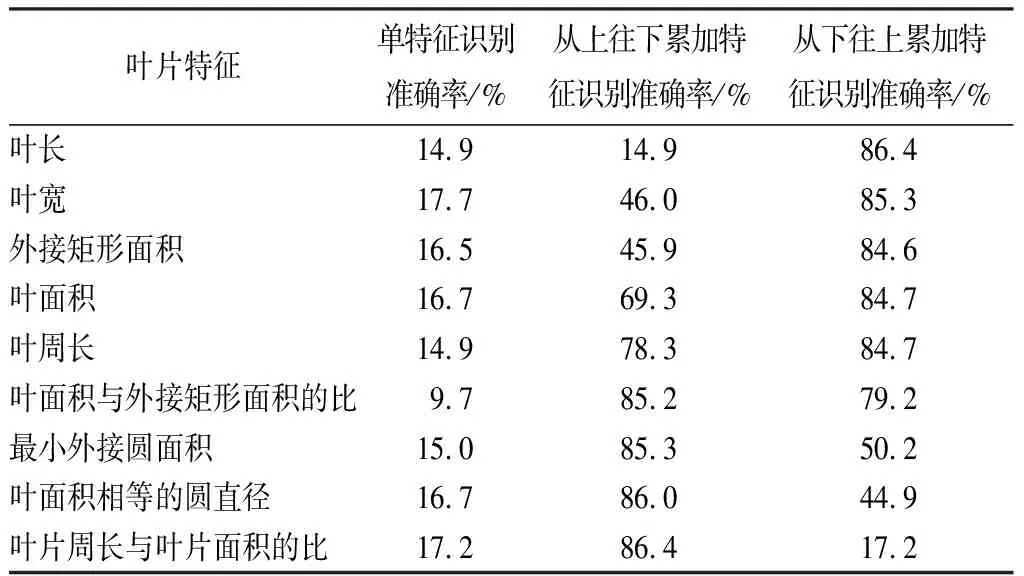
表2 叶片单特征及特征累加识别准确率
2.2 分类精度
由表3可知,使用训练得到的SVM模型(C=1 000,γ=0.1)对70个竹种进行识别分类,总体平均准确率为81%;62个竹种准确率达70%以上,其中23个竹种的准确率达到90%以上,鹅毛竹和两年生毛竹实生苗的识别准确率达到100%。

表3 不同竹种的预测精确度

续(表3)
由图3可知,输入样本与预测结果对应关系的对角线颜色总体为黑色,说明竹种总体识别精确率较高;输出样本集中最大的4个属竹种的范围标识后,刚竹属(5-30)、寒竹属(31-39)、苦竹属(43-51)和簕竹属(52-57)的部分竹种错分到同一个属中,并且预测错误的竹种所对应的点颜色均较浅,说明模型错误率低,且具有随机性。

图3 输入—输出预测精确率热力图
由表4可知,16个属中有14个属的识别准确率达到80%以上,其中5个属达到90%以上,倭竹属的准确率达到100%。其中,巴山木竹属、东笆竹属、牡竹属、倭竹属、业平竹属、玉山竹属和少穗竹属7个属为单竹属。业平竹属和玉山竹属识别准确率为70%~80%,由于属内竹种数少,属内没有可比对的竹种,影响了属水平上的识别准确率。

表4 竹种属别识别准确率
3 结论与讨论
本研究数据集包含16个属、70个种,最终选取了5个叶片性状作为分类特征,证实了SVM分类器基于叶片性状组合对多个竹种进行分类的可行性,且在属种水平上均达到了较好的分类效果,为竹子分类研究提供了一种多维度定量分析方法。段慧茹[24]根据自然环境下采集的竹种图像数据,选用VGG16、Inception V3、Res Net50和Dense Net121等4种不同的卷积神经网络模型,对12种竹子进行分类测试,最终选用了识别率最高的Dense Net121模型建立竹子分类系统,但在卷积神经网络训练中使用的竹种数有限,导致算法的性能受到一定的影响;李欣等[25]曾利用SVM对46种竹子进行分类,进行参数选择和优化后,最终选定地下茎、竹杆、竹箨、竹叶、花等56个性状特征作为分类依据,取得了较好的分类效果,但研究用于分类的样本仅246个,且实例数据来源于竹子种质资源库,库中数据为某种竹子的特征值,缺乏数据的动态性,在实际应用中,识别率可能与理论值差异较大。本研究根据9个竹叶性状特征,利用计算机技术建立SVM模型对竹子进行辅助识别分类。与建立在耿氏系统上的经典竹亚科分类法相比,本研究中使用的试验材料可以大量获得的叶片;与种质数据库中的数据相比,本研究对实地采集后的竹子叶片进行特征提取,测试数据更接近野外的真实情况。并且9个叶片性状特征经过数据化处理后,能够建立竹子叶片数据库,后期获得同类竹子数据也可及时更新数据库,提高识别准确率。在实际应用中,可实地拍摄竹叶图片,从而实现无损的竹种鉴定,突破试验材料和时间空间上的限制。此外,利用SVM分类器基于竹子叶片性状特征进行识别分类,先以分类器进行样本初筛,再进行分类细化,还可节省大量人力和物力。但受竹子地理分布广和变种多的客观原因,本研究模型测试还存在一定的不足,在后续研究中将会增加更多竹种和每一个竹种的样品数量,不断扩充竹子叶片数据库,以期识别更多竹种,探究更优化的分类识别模型,降低识别复杂度,加快识别效率。
猜你喜欢
作物学报(2022年1期)2022-11-05
水产养殖(2022年8期)2022-09-21
广东农业科学(2022年7期)2022-09-14
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
