
线程池与消息中间件技术在疾控数据交换中的应用①
2022-06-29 07:48刘潇
计算机系统应用 2022年6期
刘 潇
(江苏省疾病预防控制中心 公共卫生信息所, 南京 210009)
随着疾控信息化工作的不断深入, 疾控的传染病、公共卫生突发事件、慢病、计划免疫以及精神卫生等业务条线的信息系统在不断地建立与完善, 疾控信息化标准体系[1,2]的建立与完善有力地推动了全民健康信息化中公共卫生的数据整合. 在当前各行业协作日益紧密、各级疾控一体化集成日渐成熟的大背景下, 疾控中心各类的数据共享与交换[3,4]需求也随之而来. 根据不同的业务需求, 各个信息系统需要调用不同来源的接口来完成数据的下载、上传或核验等操作.在数据量比较小、任务实时性要求比较低的情况下,全量数据逐条调用数据接口并记录接口反馈信息的模式可以满足业务需求, 但是当数据量比较大并且任务实时性要求比较高的情况下, 比如: 疫情期间, 全省亿级数量的常住人口库的全量数据需要周期性调用通信管理接口或核酸检测查询接口以获得个人行程记录与核酸检测的相关信息, 或是在特定的时间内, 某个月增百万级随访数据的业务系统的大量的随访信息需要全部上传至指定的平台, 逐条调用数据接口的模式效率太低, 无法在规定的时间内完成任务, 如何利用有限的硬件资源高效地完成数据交换任务成为了疾控在信息化建设中面临的一个问题.
在有限的硬件资源下, 解决这个问题的思路是让数据交换任务并发执行, 直接在服务器上为每一个数据交换任务分配一个线程并同时启动大量线程去完成数据交换的方法会导致服务器压力过大, 线程的运行缺乏有效的控制, 线程的创建与销毁都会造成系统开销, 操作系统对大量线程的频繁的切换与调度会给CPU 带来沉重的负担, 容易造成服务卡顿或服务器宕机. 本文基于线程池与消息中间件技术建立一个数据交换的并发处理模型, 使用Java 线程池去控制数据交换任务的并发处理, 并引用消息中间件Kafka 作为中间件来记录数据交换结果, 进一步提高任务完成的效率, 通过实验的对比证明该模型的可行性与高效性.
1 技术简介
1.1 线程池介绍
线程池技术是一种设计程序并发运行的技术, 其核心思想是对已有线程的复用来避免大量线程创建与销毁带来的系统开销, 在CPU 上创建和结束线程造成的开销是创建或销毁任务的18 至100 倍[5], 而且通过任务进行同步的开销也远低于同步多个线程的开销, 因此线程池技术能够更好地支持细粒度的任务并发[6]. 常见的线程池一般主要包括4 个部分: 线程管理器、工作线程、任务接口和输入输出任务队列, 在启动时线程池创建若干数量的空闲线程, 当任务到达时利用已经创建的线程执行任务, 任务处理完成后, 该线程会被线程池回收用来执行下一个任务以达到线程复用的效果, 同时线程池还要对任务队列的大小、空闲线程的销毁、新线程的创建以及对任务的拒绝策略等进行管理.
Java 从JDK 1.5 版本开始在java.util.concurrent 包中提供了对线程池功能的支持[7], 相关类的继承关系如图1 所示, 其中ThreadPoolExecutor 是最核心的一个类, Java 通过封装ThreadPoolExecutor 类提供了SingleThreadExecutor、CachedThreadPool、Fixed ThreadPool 以及ScheduledThreadPool 这4 类适合特定场景的线程池供编程人员调用, 同时Java 也支持编程人员重写ThreadPoolExecutor 的构造方法, 通过设置构造参数自定义线程池.
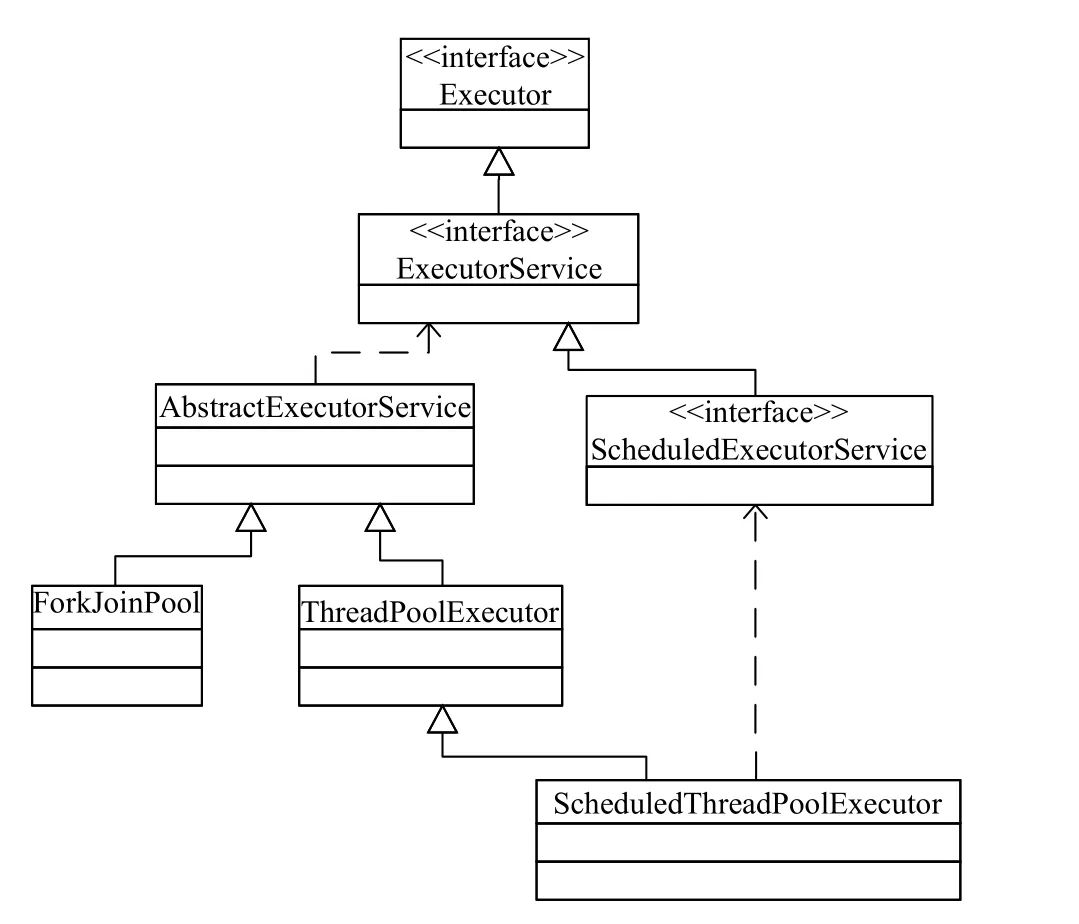
图1 Java 线程池UML 静态类图
ThreadPoolExecutor 类构造方法的主要的构造参数如下:
corePoolSize: 核心线程数, 即常驻线程池的工作线程数量.
maximumPoolSize: 最大线程数, 即某一时刻, 当任务大于线程池当前存在的工作线程数时, 线程池中的工作线程可以增加到的最大值.
keepAliveTime: 当线程数大于核心线程数时, 空闲的工作线程等待新任务的最长时间, 超过这个时间空闲线程没有接到任务就会被销毁, 线程池只保留核心线程数的工作线程数量.
workQueue: 任务队列, 即线程池中的工作线程的数量已经达到最大线程数时, 任务的等待队列.
threadFactory: 线程工厂, 可以用来自定义线程池中线程的命名方式, 优先级等属性.
Handler: 拒绝策略, 即线程池中的工作线程的数量已经达到最大线程数且任务队列已满的情况下, 线程池对超出线程池处理能力的任务所做的处理策略.
1.2 消息中间件介绍
消息中间件是可以在不同系统之间进行消息传递的一类组件, 它利用高效、可靠的消息传递机制进行平台无关的数据交流[8], 消息生产者定向发送数据, 消息消费者获取并消费数据, 基于数据通信进行分布式系统的集成. 消息中间件的消息传递主要有两种模式,分别是点对点模式和发布-订阅模式. 目前比较主流的分布式消息中间件有Kafka, RabbitMQ, ActiveMQ 等.
Kafka 是一个分布式的消息发布-订阅模式[9]的中间件系统. Kafka 在主题中保存消息的信息, 生产者向主题写入数据, 消费者从主题读取数据, 从而实现数据传输.
高性能、高吞吐、低延时是Kafka 的显著的特性,虽然Kafka 的消息保存在磁盘上, 但是由于采用了顺序写入、MMFiles (memory mapped files)、Zero Copy、批量压缩等技术优化了读写性能[10], 使其可以突破传统的数据库、消息队列等数据引擎所受限的磁盘IO瓶颈, 即使是部署在普通的单机服务器上, Kafka 也能轻松支持每秒百万级的写入请求[11], 读写速度超过大部分的消息中间件, 这种特性使得Kafka 在海量数据场景中应用广泛.
2 模型设计与实现
2.1 模型设计
疾控信息化工作中处理数据交换的基本流程是:从数据库中分批取出需要调用数据接口的数据, 为批次中的每一条数据创建一个数据交换任务, 任务主要包括调用接口获得反馈信息、将反馈信息回写数据库进行持久化两个步骤.
由于各数据交换任务相互之间的无关性, 可以在调用的数据接口可承载的并发调用范围内, 使数据交换任务并发进行以提高效率, 并在数据交换任务的反馈信息持久化阶段将反馈信息写入吞吐量更高的消息中间件进行存储, 进一步缩短数据交换任务的运行时间以提高效率.
在图2 中, 通过一个数据交换调度控制程序建立并初始化数据交换任务的线程池, 在进行数据交换任务时, 为从数据库取出的批量数据构造数据交换任务,并将任务交给线程池进行并发处理的调度, 数据接口的反馈信息写入中间件进行保存, 不同的数据消费者进程可以异步消费消息中间以获取反馈信息, 按照不同的业务需求进行日志信息持久化到数据库或者实时进行交换日志的统计与分析等操作.

图2 数据交换并发处理模型
2.2 技术实现
数据交换调度控制程序用Java 设计, 使用Java 线程池与Kafka 对模型进行实现, 模型实现主要包含数据交换任务构造、Kafka 调用以及数据交换线程池3 个部分.
2.2.1 数据交换任务构造
封装数据交换任务的类需要实现Runnable 接口以保证其可以在实例化后被线程池工作线程所调用,在该类的构造器中传递具体的Kafka 连接以及数据接口调用所需要的参数, 并实现Runnable 接口的run 方法完成具体数据接口调用与反馈信息的记录, 其核心代码如下:

?public class DSTask implements Runnable{ //数据交换任务封装类public DSTask(KafkaProducer
2.2.2 Kafka 调用
在数据交换任务封装类的sendData 方法中调用Kafka api 提供的send 方法记录反馈信息, String 类型topicName 为Kafka 的相关主题名, String 类型context 为数据交换任务最终按约定格式拼接好的反馈信息, 其核心代码如下:
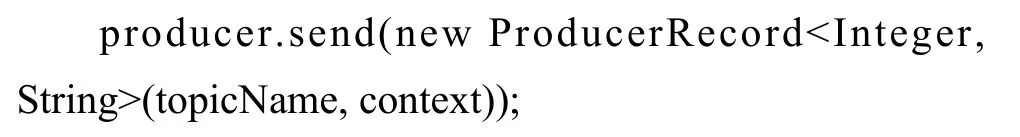
2.2.3 数据交换线程池
通过参数设置自定义ThreadPoolExecutor 类实例化线程池来控制数据交换任务并发处理. 由于数据交换任务需要连续稳定的处理, 线程池的核心线程数和最大线程数设为相同值, 即线程池中的常驻的工作线程数, 这个值的大小在运行前需要由用户综合考虑所调用数据接口能承载的并发访问量, 以及当前任务所运行的服务器的CPU 核数来设定, 在数据接口并发访问的承载范围内, 在实际工程应用中一般遵循如式(1)所示[12]:

线程池的任务队列的大小设置为每批要调用数据接口的数据的数量, 以保证所有的数据交换任务都会被任务队列容纳, 等待线程池的有效调度, 这样可以直接使用线程池默认的拒绝策略, 不需要再设计拒绝策略去处理线程池无法处理的数据交换任务.
线程池核心代码如下:

?ThreadPoolExecutor executor = new ThreadPoolExecutor(threadNum,threadNum, 10, TimeUnit.SECONDS,new LinkedBlockingQueue
3 仿真实验
为测试该模型处理数据交换任务的效率, 在疾控内部局域网部署应用进行测试, 应用部署的服务器配置: 4 核CPU, 内存8 GB, 操作系统: 64 位Linux CentOS 7.7, JDK 版本: Openjdk 1.8, 测试从疾控内网某业务库(业务库版本: MySQL 8.0.18)批量取出5 000 条个人信息数据调用在公网发布的疫苗接种记录查询接口获取个人某疫苗首次接种记录的相关信息, 在逐条处理以及使用线程池模型进行处理、接口反馈的结果回写数据库或写入Kafka 等一些不同的情况下, 分别进行如下仿真实验:
实验1. 数据接口反馈信息回写数据库, 单线程逐条处理以及使用线程池在工作线程数取不同值的情况下的运行时间对比, 运行时间皆为5 次实验的平均值,数据如表1 所示.

表1 不同工作线程数运行时间对比
很显然, 线程池处理完成数据交换任务的效率明显优于单线程逐条处理, 且在实际接口的实际条件以及4 核CPU 的硬件资源条件下, 在工作线程数设为4 时的运行效率已达到最佳.
实验2. 在线程池在工作线程数取最佳值的情况下, 数据接口反馈信息回写数据库与写入Kafka (版本:Kafka 2.5.0)的运行时间对比, 运行时间皆为5 次实验的平均值, 数据如表2 所示.

表2 反馈信息回写数据库与写入Kafka 运行时间对比
对比两者的运行时间可以看出, 将数据接口反馈信息写入Kafka 可以极大地提高了数据交换任务完成的效率.
4 模型应用
在疾控的数据交换工作中对模型进行实际应用时,工程师根据需要进行数据交换任务的数据总量, 综合考虑部署数据交换应用程序的服务器内存情况, 对数据进行批次的划分, 确定每一批完成数据交换任务的数量与线程池任务队列的容量, 并根据服务器CPU 的核数与需要调用的数据接口的实测情况确定线程池工作线程的数量, 设计数据交换调度控制程序. 如图3 所示, 数据交换调度控制程序在初始化各类连接并建立线程池后, 按照预设的批次, 分批对数据进行数据交换任务的处理, 为了判断线程池是否已完成当前批次的所有数据交换任务, 可以设置一个线程安全的全局变量, 每次数据交换任务完成时对这个变量进行累加操作, 数据交换调度控制程序通过读取这个变量值来获取线程池的当前状态, 如果当前批次的任务尚未全部完成, 调度控制程序执行自旋等待操作, 等待当前批次的任务全部完成, 线程池处于空闲状态后, 获取下一批次的数据继续进行, 直至所有批次的数据全部完成.
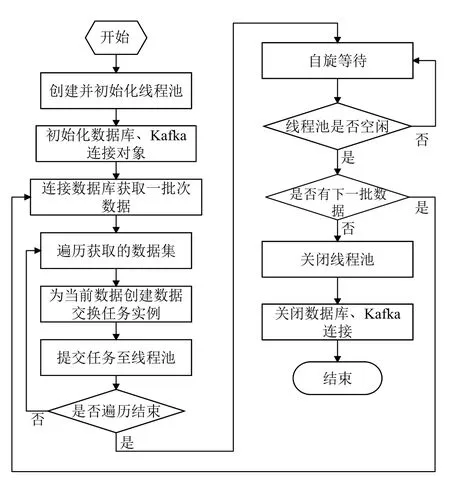
图3 数据交换调度控制程序流程设计
图4 展示的是实际工作中某重点人群库数据使用该模型调用新冠疫苗接种查询接口获取个人新冠疫苗第一针接种结果在Kafka 相关主题中的存储情况, 该项数据交换任务按约定的格式记录了个人信息在业务库的主键号, 调用接口的匹配标识, 以及调用接口所获取的接种新冠疫苗第一针的疫苗厂商、接种时间、接种单位等信息, 各数据项之间插入制表符以便在信息消费时进行解析.

图4 Kafka 记录的反馈信息展示
5 结束语
针对疾控中心在处理大规模数据交换时传统的处理模式效率不高, 难以及时完成任务的问题, 本文根据数据交换任务的特点设计了一个数据交换任务的并发处理模型, 并使用Java 线程池与消息中间件Kafka 给出了模型的具体实现. 该模型已成功应用在江苏省疾控中心的数据交换的处理中, 实践表明, 模型具有良好的数据交换任务并发控制与处理能力, 进行数据交换的数据量越大, 其优势越明显. 在不大幅度增加硬件成本的前提下, 该模型适用面广, 可用于各类型的数据换的处理与控制, 在保证服务稳定性的同时可以有效地提高数据交换的处理能力.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年12期)2022-06-14
现代电子技术(2022年8期)2022-04-13
汽车工程(2022年3期)2022-04-07
科学导报·学术(2020年26期)2020-10-21
智能计算机与应用(2016年6期)2017-05-08
青年文学家(2016年32期)2016-12-23
中国信息化·学术版(2013年1期)2013-05-28
意林(2009年12期)2009-02-11
智能计算机与应用(2007年4期)2007-08-25
