
用于信息检索的句子级深度关联匹配模型
2022-06-29 12:36郝文宁靳大尉
计算机技术与发展 2022年6期
田 媛,郝文宁,陈 刚,靳大尉,邹 傲
(陆军工程大学 指挥控制工程学院,江苏 南京 210001)
0 引 言

深度神经网络,作为一种表示学习方法,已经被广泛应用于NLP任务[3-4],并取得显著成果,鉴于此,研究者尝试将其应用于IR中,现有的神经信息检索模型可大致分为两类:语义匹配模型和关联匹配模型。语义匹配模型主要关注文本的表示,通过深度神经网络将查询和待检索文档映射到低维的向量空间,然后利用这种向量表示计算它们的相似度;关联匹配模型主要关注文本之间的交互,对查询和待检索文档之间的局部交互进行建模,使用深度神经网络学习层次交互信息以得到全局的相似度得分。现有的用于IR的深度关联匹配模型通常以词为单位进行局部相关度匹配,没有考虑词之间的顺序及语义信息,无法解决一词多义的问题。该文提出的关联匹配模型使用语义相对完整的句子作为单位实现查询与待检索文档之间的局部交互,首先计算查询中每个句子与待检索文档中各个句子的相似度得分,并将这些得分映射到固定数量的桶中,桶按相似度等级划分,从而获取固定长度的匹配直方图;然后使用一个前馈神经网络学习局部交互的层次信息获取每个查询句与整个文档的相似度得分;最后使用一个门控网络计算每个查询句的权重并聚合得到最终整个查询与文档的相似度得分。
主要贡献如下:
(1)将句子级检索与深度关联匹配模型相结合,以语义相对完整的句子为单位进行查询与待检索文档之间的局部匹配,充分考虑了词的上下文信息。
(2)查询Q的全部局部匹配直方图输入到神经网络之前将其重新排列,解决模型因对位置信息过度拟合,即可能在经常用0填充的句子处学习到较低的权重带来的整体检索性能下降的问题。
(3)使用交叉熵损失替换链损失,并通过实验验证,使用交叉熵损失可以提高模型的检索性能。
1 相关研究
IR中的核心问题就是计算文档与给定查询之间的相关性,也就是文本匹配的问题。传统BM25是一个专门用于计算查询和候选文档之间相似度的评分标准,文献[5]指出,其搜索功能在实践中往往会过度惩罚有用的长文档,Na等人[6-7]将其改进成vnBM25,有效地缓解了文章长度的冗余影响。Kusner等人[8]提出了词移距离的概念(WMD),从转换成本上度量文本之间的相似度。鉴于深度神经网络良好的表示学习能力,近年来研究者已经提出了很多深度匹配模型用于IR,旨在基于自由文本直接对查询和文档之间的交互进行建模[9],这些模型大致分为两类,语义匹配模型和关联匹配模型。如图1(a)所示,语义匹配模型中的深度网络是为查询和待检索文档学习一个好的表示,然后直接使用匹配函数去计算二者之间的相似度,例如在DSSM[10]中,深度网络使用的是一个前馈神经网络,匹配函数则是余弦相似度函数;在C-DSSM[11-12]中,使用卷积神经网络学习查询和文档的向量表示,然后使用余弦相似度函数计算二者之间的相似度得分。

(a)语义匹配模型 (b)关联匹配模型
然而,Guo等人[13]指出,IR中所要求的匹配与NLP任务中所要求的匹配是不同的,若在创建文本表示之后再进行交互,可能造成精确匹配信息的丢失。关联匹配更适用于检索任务,如图1(b)所示,首先建立查询中词与待检索文档中词之间的局部交互,然后使用深度神经网络学习层次匹配模式以获取全局相似度得分,例如ARC-II[14]和MatchPyramid[15]模型使用词向量之间的相似度得分作为两个文本的局部交互,然后使用分层的卷积神经网络来进行深度匹配;DRMM模型首先计算查询-文档对词之间的相似度得分,并将其映射成固定长度的直方图,然后将相似度直方图送入一个前馈神经网络以获取最终的得分;K-NRM[16]模型使用核池化来代替DRMM中的相似度直方图,有效解决了生成直方图时桶边界的问题。
近年来已经有学者提出句子级的检索方法,但是这些方法仅使用无监督学习将查询句与文档句之间的相似度得分简单整合以获取最终得分。文献[17]中提出三种整合方法:第一个是将文档中每个句子的相似度得分进行累加以获得整个文档的相似度得分;第二个是将文档中全部句子相似度得分的平均值作为整个文档的相似度得分;第三个是取文档中句子相似度得分的最大值作为文档的相似度得分。李宇等人[18]提出了相关片段比率的概念,取文档中句子相似度得分的最大值与相关片段比率的乘积作为整个文档的相似度得分。文中模型将句子级检索与深度神经网络相结合,使用深度神经网络学习查询句子与待检索文档句子之间的层次匹配信息,从而获得整个查询-文档对的相似度得分。
2 句子级深度关联匹配模型
该文提出了一个句子级深度关联匹配模型(sentence level deep relevance matching model,SDRMM),具体来说,在句子级别的关联匹配上使用了一个深度神经网络结构,学习查询句与文档句的层次匹配信息以获取最终的查询-文档对得分。如图2所示。

图2 句子级深度关联匹配模型
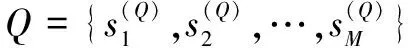
2.1 句子级关联匹配

(1)
为获取固定长度的匹配直方图,该文对查询句与文档句之间的相似度得分按等级分组,每一组看做一个桶,统计落入各个桶中的文档句个数,然后取其对数作为最终的局部匹配信息,考虑到较多桶中可能只有一个文档句子,直接取对数后值为0,会影响模型的训练效果,先对桶中的文档句子数进行加一操作再取其对数。例如,将相似度范围[-1,1]划分为4个等级{[-1,-0.5),[-0.5,0),[0,0.5),[0.5,1]},查询中的其中一个句子与待检索文档对应的局部交互得分为(0.2,-0.1,0.6,0.7,0.8,0.9),那么该查询句所对应的固定长度的匹配信号就为[0,log2,log2,log3]。
2.2 深度关联匹配
深度关联匹配模型的输入即为上述查询中各个句子与待检索文档之间的局部交互信息,首先使用前馈神经网络从不同水平的局部交互中学习层次匹配信息,针对每个查询句得到一个与待检索文档的相似度得分,前馈网络中隐藏层的输出如式(2)所示:

i=1,2,…,M;l=1,2,…,L
(2)


(3)
(4)
由于在保证深度关联匹配模型输入的固定长度时使用了零填充方法,在训练时,模型可能会在经常填充零的位置错误学习到较低的权重,也就是说,门控网络在学习权重时,可能会对不同位置的局部匹配信号区别对待。为了避免这种问题,首先将零填充后的每个查询的全部局部关联匹配直方图重新排列,然后再将其送入模型进行训练,实验结果表明该做法能够提高整体的检索性能。
2.3 模型训练
在已有的一些神经信息检索模型中,例如DRMM、PACRR[22]等,通常使用成对的排序损失最大间隔损失来训练模型,而在文中的句子级深度关联匹配模型训练时,使用一个交叉熵损失来替换最大间隔损失,对比实验表明,交叉熵损失可以提高模型的检索性能。损失函数定义为:
L(Q,D+,D-,Θ)=
(5)
其中,Q为一条查询,D+表示与查询相关的文档,D-表示与查询不相关的文档,Score(Q,D)表示查询与文档的相似度得分,Θ表示前馈神经网络和门控网络中的全部参数。
3 实 验
使用Med数据集对提出的句子级深度关联匹配模型进行评估,该数据集来自Glasgow大学收录的IR标准文本测试集,其中包含1 033篇文档,30条查询,详细情况如表1所示。对Med数据集进行预处理,去除标签等无用信息,参照标准停用词表删去停用词并提取词干,实验中使用五折交叉验证以减少过度学习,将全部查询划分为5部分,每次取4/5的查询作为训练集,剩下的作为验证集。此外,还在Med数据集上对提出的模型和一些基准信息检索模型进行比较,使用MAP、检索出的Top-10个文档的归一化折现累积增益nDCG@10和Top-10个文档的准确率P@10作为评估指标。

表1 Med数据集信息
3.1 基准模型
使用一些现存的基准模型如BM25、DRMM、无监督句子级检索模型以及笔者之前提出的无监督句子级关联匹配模型与该文的句子级深度关联匹配模型进行比较,本节将对这些基准模型进行简要介绍。
BM25:该模型代表了一种经典的概率检索模型[23],它通过词项频率和文档长度归一化来改善检索结果。
无监督句子级检索模型:左家莉等人提出一种结合句子级别检索的文档检索模型,首先计算待检索文档中每个句子与查询的相似度得分,然后通过对这些相似度得分的简单加和、求平均或取最大值来获取整个文档与查询的相似度得分,这里分别将三种不同的整合方法表示为SRIR1、SRIR2和SRIR3;李宇等人提出一种文档检索中的片段化机制,通过设定合适阈值从文档中筛选出高度相关片段并计算相关片段比率,然后将相关片段中的最高相似度得分与相关片段比率的乘积作为整个文档与查询的相似度得分,这里将该模型记为TSM_BM25;笔者在之前的工作中也提出了一种无监督句子级检索模型,先使用预训练的Sentence-Bert模型获取查询与待检索文档中各个句子的向量表示,使用余弦距离计算句子之间的相似度得分,然后再使用现有的整合方法获取整个文档的得分,模型记作MI-IR。
DRMM:该模型是一种关注文本交互的深度匹配模型,首先通过计算查询中的词与待检索文档中的词之间的相似度获取局部关联匹配直方图,然后通过前馈神经网络学习出分层的关联匹配从而获取最终查询-文档对的相似度得分。
3.2 实验设置
该文的句子级深度关联匹配模型是由三层前馈神经网络和一层门控网络构成的,在前馈神经网络中,一层输入层接收局部关联匹配信号,设有30个节点,两个隐藏层分别包含5个节点和1个节点,获取每个查询句与文档的相似度得分;门控网络设有1个节点,获取最终查询-文档对的相似度得分。在训练时,使用Adam优化器,batch-size设为20,学习率设为0.01,epoch设为3,门控网络中参数向量的维度设为768,与句向量的维度保持一致。对基准模型DRMM,使用CBOW模型获取300维的词向量用于计算查询中的词与待检索文档中的词之间的局部关联。
3.3 实验结果及分析
本节展现不同的基准模型以及该文的句子级深度关联匹配模型在Med数据集上的实验结果,如表2所示。

表2 Med数据集测试评估
可以看出,几个无监督的句子级检索模型均比传统的文档级概率检索模型BM25在性能上有所提升,这表明一些相似度计算方法可能会受到文本长度的影响。在这些无监督句子级检索模型中,SRIR模型与TSM_BM25模型的检索性能相差不大,表明在Med数据集上对用BM25公式计算出来的文档句的相似度得分使用不同的无监督整合方法差别不大,而笔者之前提出的MI-IR模型,相对于其他几种无监督句子级检索模型在准确率和nDCG上均有一定的提升,说明Sentence-Bert模型确实能更好地捕获句子的语义信息,从而提升文档检索的性能。神经检索模型DRMM相较于传统的BM25检索模型在MAP、P@10以及nDCG@10上分别有8.1%、11.9%和6.9%的提升,且优于几种无监督的句子级检索模型,比MI-IR模型在MAP上有7.3%的提升,这也表明了关注文本之间交互的深度神经网络检索方法能够提升文档检索的性能。
在这些检索模型中,该文的句子级深度关联匹配模型(SDRMM)明显表现更好,其相较于传统检索模型BM25在MAP、P@10以及nDCG@10上分别有18.6%、19.3%和15.4%的提升;较无监督句子级检索模型中表现最好的MI-IR模型分别有17.7%、11.3%和8.9%的提升;较深度关联匹配模型DRMM分别有9.6%、6.6%和7.9%的提升。证实了以语义相对完整的句子为单位的查询-文档对之间的局部关联匹配要比以词为单位的局部关联匹配表现好,能够捕获文本之间更加精确的匹配信息。
3.4 消融实验
通过消融实验对SDRMM做进一步分析,以验证打乱查询中局部匹配直方图输入顺序以及使用交叉熵损失的有效性。实验中仍然使用Med数据集,SDRMMsequence表示查询匹配直方图顺序未打乱且使用交叉熵损失的SDRMM;SDRMMhinge表示查询匹配直方图顺序打乱且使用链损失的SDRMM;SDRMMhinge×sequence表示既未将查询匹配直方图顺序打乱又未使用交叉熵损失的SDRMM,实验结果如图3所示。

图3 消融实验评估
从图中数据可以看出,在同样使用了交叉熵损失的情况下,打乱查询句的顺序比不打乱查询句的顺序在P@10和nDCG@10上均有近1%的提升;在同样打乱查询句的顺序的情况下,使用交叉熵损失比使用链损失在P@10和nDCG@10上分别有近3%和近2%的提升,在MAP上有0.3%的提升;不打乱查询句顺序且使用链损失的模型效果最差,在MAP指标上低于SDRMM 0.8%,在P@10和nDCG@10上分别低于SDRMM近4%和近3%。总的来说,选择的最优的SDRMM相比于SDRMMsequence、SDRMMhinge以及SDRMMhinge×sequence在Top-K个检索文档的MAP、准确率和nDCG上均有一定的提升,证实提出的打乱查询中句子的输入顺序以及使用交叉熵损失对于提升文档检索的性能的有效性。
4 结束语
提出了一种新的关注文本之间交互的神经信息检索模型,通过获取查询与待检索文档之间更深层的匹配信息来提高检索的性能。现存的一些深度关联匹配模型通常是以词为单位计算查询与文档之间的局部交互信息,但这往往忽略了词之间的顺序和语义信息。使用语义相对完整的句子为单位,在已有的无监督句子级检索的基础上,使用深度神经网络学习查询句与待检索文档句之间的层次交互信息从而得到整个查询-文档对的相似度得分。为了进一步提升文档检索的性能,使用交叉熵损失来替代现有一些模型中常用的链损失,此外,为了减小模型训练时对不同位置查询句区别对待的影响,在输入查询中的句子时,将其顺序打乱。在Med数据集上的实验结果表明,该文的句子级深度关联匹配模型比一些传统的信息检索模型以及先进的检索模型表现好。
当前在计算查询句与待检索文档句之间的相似度得分时,只简单使用了余弦相似度函数,在下一步的工作中,将对句子之间的相似度计算方法进行改进,考虑结合文档中句子的位置信息,因为句子的位置也会影响其重要程度;还可以将多种相似度算法相结合,以综合不同算法的优势。还希望能在更多的数据集上训练该句子级深度关联匹配模型,以进一步查看模型在不同数据集上的表现。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
影像视觉(2018年12期)2018-11-29
科学与财富(2017年28期)2017-10-14
电脑爱好者(2017年7期)2017-05-06
中学生数理化·高一版(2017年2期)2017-04-25
