
基于Feature-RNet的三维大场景点云分类框架
2022-06-29 12:32雷根华张志勇
计算机技术与发展 2022年6期
雷根华,王 蕾,2,张志勇
(1.东华理工大学 信息工程学院,江西 南昌 330013;2.江西省核地学数据科学与系统工程技术研究中心,江西 南昌 330013)
0 引 言
点云是海量点的集合,在同一空间参考系下表达目标空间分布和目标表面特性,具有不规则且无序等特点。三维点云数据的获取方式主要是通过三维激光扫描仪进行数据采集得到。激光雷达测量(light detection and ranging,LiDAR),是一种光学遥感技术,由激光发射部分、接收部分、信号处理部分三部分组成,能够获取坐标(X,Y,Z)、强度、颜色等物体信息,通过LiDAR采集到的点云数据格式多种多样。LiDAR可以单独工作获取小场景的三维点云数据,而对于获取复杂大场景下或者大尺寸物体的点云数据,单独的LiDAR往往不能满足要求,需与GNSS、camera等其他仪器联合使用,从而获取更丰富、完善的物体信息。
点云分类一般包含从局部和全局两个不同的方面提取点特征和通过学习到的特征将每个点划分为预定义的语义类别两个步骤[1]。早期的点云分类方法研究主要通过手工设计[2-3]的规则来提取点特征,然后使用基于机器学习的分类器预测每个点的语义标签[1]。如高斯混合模型[4-5]、支持向量机(SVM)[6-7]、AdaBoost[8-9]等。由于手工设计规则提取的特征表达能力较弱,使得模型在处理复杂场景时往往无法达到令人满意的效果,与此同时,有关分类器的选择和组合十分复杂,严重依赖研究人员的专业,极大地降低了此类方法应用的灵活性。
在点云分类的深度学习方法中,2006年,卷积神经网络(CNN)的提出引起了广泛关注。2015年,Su等人提出了多视图卷积神经网络(MVCNN)[10],通过设置不同位置、不同角度的视点获取多个视角的二维视图,以此作为MVCNN的输入。MVCNN在分类任务中取得了不错的成绩,但是由于无法动态选择视图等因素,导致分类精度受到影响。Maturana等人提出的VoxNet[11]是一种最早将非结构化的点云数据体素化为网格数据并应用于3D卷积神经网络的模型,在一定程度上解决了点云非结构化的问题,但是计算所需内存过大。Barnea和Filin[12]等提出将输入的点云数据构造成深度图的模式,利用深度图的特点使用均值平移算法对点云数据进行分类分割,最后将划分出的特征子集进行联合以达到良好的分类效果。Barnea[13]改进了Filin[12]的分类算法,通过使用迭代的思想对其网络框架进行改进,能更好地得到分割边界和分割区域,但不能准确得到分割目标对象。
基于深度学习的点云分类方法大多都是基于二维图像设计的。pointNet[14]及其变体的提出给研究人员提供了新的思路。文献[15]提出了一种基于多维特征矩阵和PointNet(Feature-pointNet框架)的深度神经网络模型,以特征图像代替三维点云数据作为PointNet的输入,由于上述改变,文献[15]在后面的pointNet框架中并没有使用T-Net矩阵。该方法取得了不错的分类效果,但是在参数和运行时间效率上还有待提高。
基于文献[15]中的Feature-pointNet网络框架,该文设计出一种基于Feature-RNet的网络框架。在该方法中,通过借鉴点云特征图像的获取方法(特征图像的生成方法与文献[15]中的方法一致)作为RNet框架的输入;其次,设计RNet网络框架模型,以达到提升分类精度的目的;最后使用公开的Oakland 3D数据集进行RNet的分类模型训练。
1 研究基础
现今许多领域的发展都离不开三维大场景点云分类,例如自动驾驶等,为此许多研究人员对点云做了大量的研究工作。R.B.Rusu[16]提出FPFH的方法,通过寻找点云内部或者不同点云之间的关联关系进而采取有效措施来加快FPFH的计算速度,但是其中点云法线的选取好坏对最终结果影响较大。孙杰[17]提出一种能够有效运行在大场景点云数据集上的面向对象的方法,该方法能够获取LIDAR点云数据的多种特征,最终达到一个准确的分类效果。Riegler[18]提出OCNet,由于输入数据中的稀疏性的这一特性从而构建不平衡八叉树模型来划分网络空间,是一种高分辨率的3D卷积神经网络。Hu[19]提出了一个点到图的框架,通过提取窗口内的相邻点并将其转换为图像,将点的分类问题转换成图像的分类问题,该方法在DTM生成任务(二值分类)中取得了不错的成绩,但是该方法在其他类型的点云分类任务中仍然存在一些问题。文献[15]改进Hu的方法,提出了一种基于点的特征图像生成方法,通过提取每个点的二维和三维特征从而构建特征图像,再训练pointNet网络框架模型并且使用该模型得到最终分类结果。
文献[15]中采用的框架流程如图1所示。

图1 Feature-pointNet网络框架流程
首先将三维点云数据集分别在二维和三维两个层面上进行特征提取。在三维层面上,采用KNN方法在每个点周围选取100个点计算17个特征值,得到的三维特征矩阵为[Lλ,Nx,Ny,Nz,Pλ,Sλ,Mx,My,Mz,Oλ,Aλ,Eλ,Tλ,Cλ,D,Q,V],其中的[Nx,Ny,Nz]T、[Mx,My,Mz]T分别代表点的最大分布方向、点的最小分布方向。在二维层面上,即三维点云在x,y,z三个不同方向上的二维平面投影,同三维平面上一致,通过KNN的方法在每个点周围选取100个点作为一个计算单位,获取5个特征值(三个不同平面共计15个特征值),得到的二维特征矩阵为[rk,D2D,Rλ,2D,S2D,EVratio2D],从左到右分别代表最优邻域半径、局部点密度、特征值比率、特征值和、高度方差。将得到的二维特征和三维特征进行融合构建点云的特征矩阵,作为pointNet框架的输入。需要注意的是,不同于传统的pointNet,文献[15]采用的是pointNet中的vanilla版本,由两个网络层MLP(64,64),MLP(64,128,1 024)以及一个全连接网络层MLP(512,256,C)构成。与传统的pointNet框架相比,vanilla舍弃了旨在保持点云不变性的T-Net矩阵。
在文献[15]的Feature-pointNet网络框架模型中,提出的点云特征提取方法能够有效地提取点云数据特征,并融合为点云特征图像作为框架输入,为以后的研究提供了新的方式且分类效率更高。正是由于对点云特征转换为点云特征图像的这一转变,使得应用在图像分类的网络框架能够适用于大场景三维点云分类任务中。该文正是借鉴其方法,将处理得到的点云特征图像作为框架输入进行分类训练。另外,在分析比较文献[15]及其他典型的分类框架后,设计出一种RNet网络框架,该框架与pointNet(vanilla版本)相似,采用的都是1*1的卷积核,不同之处在于RNet由网络层MLP(64,64)、MLP(64,64,1 024)以及全连接网络层(521,256,C)组成,同时在框架中多次添加⊕操作,将不同层次的经过卷积提取的三维点云特征相加形成新的特征,作为下一个层次的输入,使得特征多样化,从一定程度上避免了点云有效信息丢失,提升了分类精度。
2 网络框架
工作流程如图2所示。
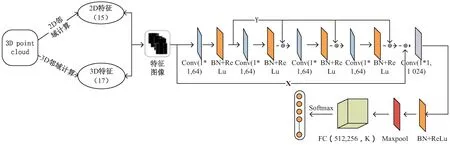
图2 Feature_RNet网络框架
首先,完成特征图像的生成,即对三维点云数据集进行特征提取,所用方法与文献[15]一致(在上一章节已经详细介绍了,这里就不进行赘述)。然后将特征值进行融合得到特征图像,再将特征图像作为RNet网络框架的输入。对于提出的RNet网络框架的设计,灵感来源于pointNet论文里的vanilla版本(即没有使用T-Net矩阵)的框架模型,主要区别在于:(1)没有卷积核大小为1*1,通道数为128的卷积层;(2)多次添加⊕操作,实现特征相加,从而得到新的特征矩阵作为下一层次的输入,能够更有效地获取特征信息,进而提升分类精度。
2.1 RNet网络框架
RNet框架如图3所示。
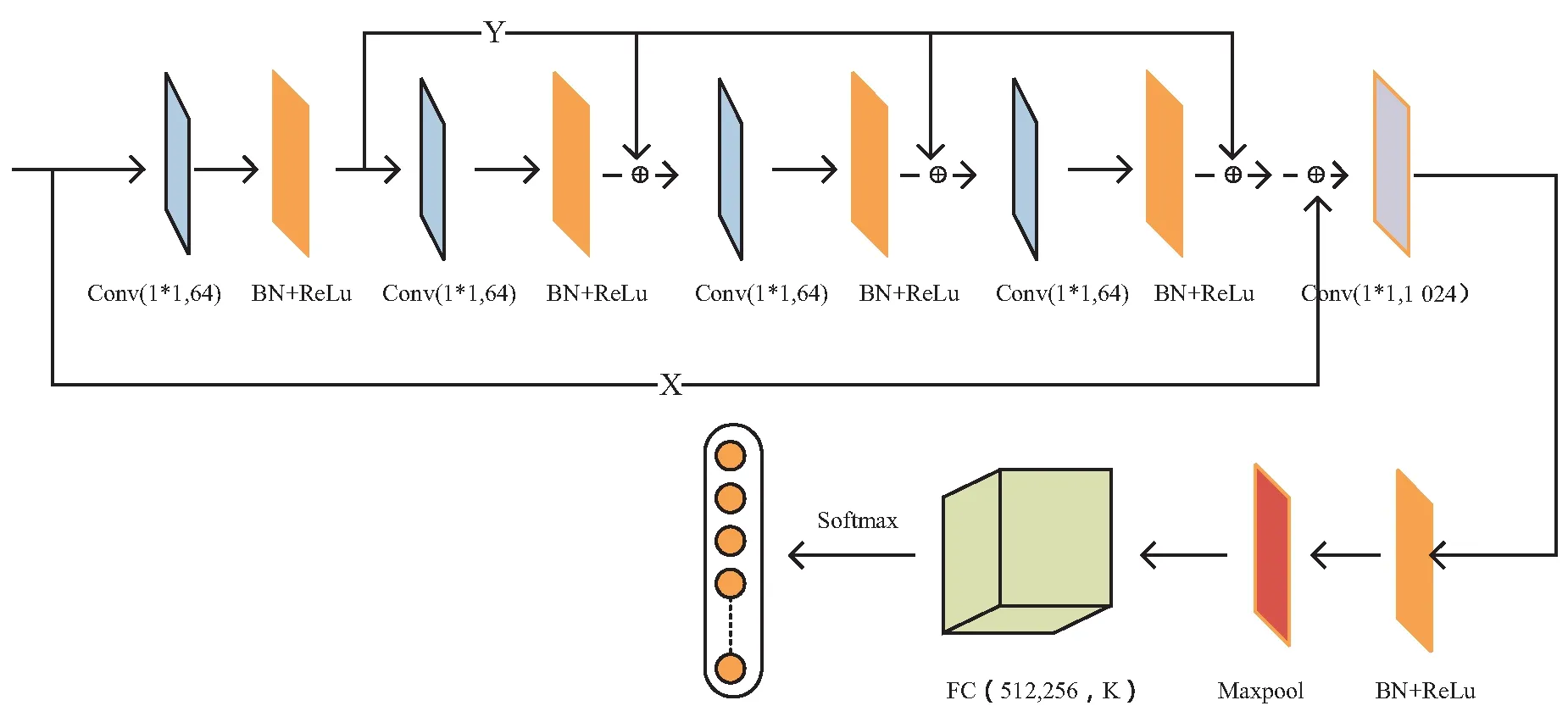
图3 RNet网络框架
将特征图像输入到RNet网络框架中,通过RNet框架中的网络层对输入的特征图像进行特征提取操作,最终完成点云分类任务。由于深度学习网络框架会随着卷积层数的增加而出现过度拟合的情况,为了防止这一情况的出现,RNet网络模型中加入了BN和ReLu,从而能更有效地获取点云的特征信息,同时,类似残差块的设计能够在一定程度上解决梯度爆炸以及梯度消失等问题。
RNet网络框架包含4个1*1卷积核,通道数为64的conv,1个1*1卷积核,通道数为1 024的conv。卷积核部分都采用了1*1的卷积核,在卷积神经网络中,相比于大的卷积核而言,在相同情况下,使用小的卷积核使得卷积层计算过程中参数量减少很多。由于在卷积神经网络层对点云特征图像提取特征的过程中部分有效特征信息并未提取到,从而导致最终分类结果精度下降,因此,为了改进这一问题,在RNet网络框架中(如图3所示),⊕实现张量相加,通过叠加输入的方法,使得网络框架将深层特征与浅层特征结合起来,能够获得更为全面的特征信息,从而提高分类精度。
接下来介绍点云特征图像进入到RNet框架之后的工作流程。首先通过文献[15]中的特征图像的获取方法,得到了形如[BatchSize,Channel,Width,Height]格式的[BatchSize,1,32,32]的特征图像,记为X,其中,Channel为通道数,Width,Height分别为特征图像的宽度和高度。将上述得到的特征图像输入到RNet网络框架中,首先经过一个卷积核大小为1×1,输出通道数为64的网络层,输出为[BatchSize,64,32,32]格式的特征矩阵,将上述输出记为Y。再将Y作为下一个卷积核大小为1×1,输出通道数为64网络层的输入,最终得到[BatchSize,64,32,32]格式的特征矩阵,记为out1。值得注意的是,在第三个卷积核大小为1×1,输出通道数为64的网络层时,输入并非为out1,而是Y+out1,最终得到[BatchSize,64,32,32]格式的特征矩阵,记为out2。同样的在第四个卷积核大小为1×1,输出通道数为64的网络层,输入并非为out2,而是Y+out2,最终得到[BatchSize,64,32,32]格式的特征矩阵,记为out3。接下来是一个卷积核大小为1×1,输出通道数为1 024的网络层,以out3+X+Y作为输入,最终得到[BatchSize,64,32,32]格式的特征矩阵。再经过Flatten层之后,输出(None,230 400)的向量,最终经过全连接FC(512,256,K)得出分类结果。
2.2 残差块进一步的应用
深度残差网络ResNet[20]由许多的残差单元组成,传统的残差单元由直接映射部分和残差部分组成,每个残差块可以用以下公式表示:
yl=h(xl)+F(xl,Wl)
(1)
xl+1=f(yl)
(2)
其中,xl+1和xl分别是第l个残差单元的输出和输入,F是残差函数,在文献[20]中,h(xl)=xl是一个恒等映射,f是一个ReLU[21]函数。
残差单元包含具有“快捷连接”的前馈神经网络。快捷连接[22-24]是跳过一个或多个层的连接。快捷连接只是执行标识映射,它们的输出被添加到堆叠层的输出中。标识快捷方式连接既不增加额外的参数,也不增加计算复杂性。直接将x从浅层神经网络传送到神经网络的深层,通过这种方式能够有助于解决梯度消失和梯度爆炸问题,使得在训练更深的网络模型时,能保证良好的鲁棒性。
如图3所示,RNet框架模型在残差模块结构的基础上,做出了一些变型——构造4个⊕操作(⊕代表张量的叠加),与传统残差块不同的是addition是在ReLu之前,而在RNet模型中addition表现在激活函数ReLu之后。从提取特征的角度上来说,将浅层提取的全局特征传送到网络的更深层,与该更深层提取的全局特征进行结合,在不增加参数量的前提下,提高了最终分类结果精度。
2.3 特征图像的生成
在文献[15]的Feature-PointNet网络框架模型中,利用构造的特征图像作为框架的输入,以三维特征与二维特征相结合的方式表示整体点云特征,以达到提高分类准确率的效果。在此基础上,该文利用文献[15]的特征图像构造方法,设计出特征图像作为输入并对RNet框架进行训练。
三维特征组合为:[Lλ,Nx,Ny,Nz,Pλ,Sλ,Mx,My,Mz,Oλ,Aλ,Eλ,Tλ,Cλ,D,Q,V]
二维特征组合为:[rk,D2D,Rλ,2D,S2D,EVratio2D]
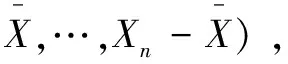
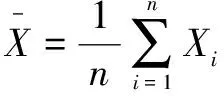
(3)
(4)

对于二维数据点Pk(xk,yk)作为点P的第k个近邻数据点,则rk(最优邻域半径)的计算公式如下:
(5)

3 实验结果
3.1 数据集
该文采用Oakland[25]数据集作为实验数据集,该数据的获取是通过配备了侧视 SICK LMS激光扫描仪的Navlab11在宾夕法尼亚州匹兹堡奥克兰的CMU校园周围收集的。该数据集包含160万个3D点云数据,共44个标签。Oakland数据集包含了训练数据集、测试数据集和验证数据集,其中训练数据集和测试数据集经过了过滤和标记,将44个标签重新映射成了5个标签,这5个标签分别为scatter_misc(植被)、utility_pole(柱状物)、load_bearing(地面)、default_wire(电线)、facade(立面),如表1所示。

表1 Oakland 3D数据集
GML数据集[26]是通过ALTM2050这一系统采集获取的三维点云数据集,该系统提供了GML_A数据集和GML_B数据集两个不同的数据集。由于GML数据集过大,总共包含约2 077万个3D数据点,而实验硬件环境远远达不到能够处理GML数据集的条件,同时,GML_A数据集相比于GML_B数据集分布更为合理,能够更好地体现网络模型分类效果,因此,采用了GML_A数据集作为实验数据集。在应用到框架之前,对GML_A数据集进行了预处理(Space采样),目的是适配现有的硬件环境以及通过减少数据集数据大小从而减少在特征提取计算上的时间耗费。经过了预处理之后的GML_A数据集每个类别数据如表2所示。

表2 经过预处理之后的GML_A数据集大小
3.2 实 验
实验是在Intel i7-4790、NVIDIA RTX 2070、8G内存,在Window10和Python3.7下搭建CUDA 10.0、CUDNN7.6.4、Pytorch 0.6的环境下进行的,学习率初始化为0.001,训练总轮数为120,使用weight_decay=1e-8,第一次估计的指数衰减率为0.9,第二次估计的指数衰减率为0.99的Adam优化方法来训练RNet网络框架。通过提取点云特征计算特征图像,而在提取特征值的过程中,是以100个点为单位计算特征值,以此为固定值,通过修改后面的RNet网络框架,与不同的神经网络框架下的准确率以及花费时间进行对比。
对比其他方法在Oakland 3D数据集上进行分类任务的精度,以及为了验证图3中⊕(张量加addition)的作用,对比了有⊕操作的RNet网络框架以及去除⊕操作的RNet框架在Oakland数据集上的分类精度,如表3所示,其中OA代表总体分类精度。

表3 不同方法分类精度对比 %
由表3可知,在scatter_misc和facade这两大类别的分类精度表现优异,在总体分类精度上,所提出的RNet网络框架达到了97.7%,要优于其他方法,并且有⊕操作可以提升框架的整体分类精度。但是在utility_pole跟default_wire这两类上表现的差强人意,造成这个结果的原因主要有:(1)这两个类别的点数据量较少;(2)在进行特征提取的过程中,存在点的覆盖问题。
图4(a)为Oakland 原始测试数据集可视化图,图4(b)为在Oakland数据集上进行分类结果可视化。从图4的可视化可知,类别utility_pole跟default_wire的分类效果不好,后续还要对框架进行优化。

(a)Oakland原始测试数据集可视化

(b)结果可视化
收集了一些应用GML_A数据集的实验研究,与文中方法进行比较,如表4所示,表现比较好的是Tree和Ground这两个类别,分别达到了91.77%、78.4%的准确率,但是在Building和Car类别上的精度差强人意,造成这种情况的原因有数据集该类别的数据少等,后续要改进参数以达到更好的分类效果。结果可视化如图5(b)所示。

(a)经过预处理(Space采样)之后的GML_A测试数据集

(b)结果可视化

表4 不同方法的对比精度 %
4 结束语
由于近些年科技的发展与进步,大场景三维点云的应用领域越来越广泛,但是大场景点云分类中还存在很多问题,如由于大场景点云数据量庞大导致相关工作所需计算量巨大,占用内存过大,训练时间也过长,以及分类精度低等问题。该文提出了一种基于Feature-RNet的大场景三维点云分类框架,在Oakland 3D数据集上取得了不错的分类精度,但是在数据量少的点云类别上效果不尽如人意。同时在GML_A数据集上取得了不错的成绩,但是依然存在很大的进步空间,后续将不断优化框架以达到更好的分类准确率。在未来的工作中,将继续研究如何提升深度学习框架本身的计算性能,在保证不错的分类精度的同时能使用更少的训练时间,同时针对数据量少的点云也能取得不错的分类效果,并且将该模型框架应用到不同的大场景点云数据集中,以便提高框架的通用性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国新通信(2017年9期)2017-05-27
电子技术与软件工程(2016年24期)2017-02-23
科技与创新(2015年19期)2015-10-14
