
基于DRL的MEC卸载网络竞争窗口优化
2022-06-29 12:32张郭健彭麟杰
计算机技术与发展 2022年6期
詹 御,张郭健,彭麟杰,文 军
(电子科技大学 信息与软件工程学院,四川 成都 610054)
0 引 言
智能手机、平板电脑、可穿戴设备等个人智能设备和物联网设备的日新月异正在推动新服务、应用的出现,如虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)、人脸识别和移动医疗等,这些服务和应用都具有较高的计算要求。尽管现今的智能设备拥有更多的计算能力,但它们仍然无法有效地运行计算密集型的应用程序或提供稳定有效的服务。为了应对这一挑战,多接入边缘计算(multi-access edge computing,MEC)[1]被提出来,它将计算和存储资源从远程云中分出,部署在更靠近设备的一端。因此,设备的计算密集型应用任务可以被卸载到临近的MEC服务节点上,以实现高质量的服务(quality-of-service,QoS)。物联网设备主要通过接入点(access point,AP。例如Wi-Fi连接)请求MEC服务,如图1所示。AP关联到一个或多个MEC服务器,多个用户设备(user m)接入并请求MEC服务。在物联网中,智能设备主要用于数据采集和提供简单的服务,其计算资源有限,需要MEC提供算力支持以达到较好的QoS。但大量的设备接入会导致接入点的竞争冲突,尤其是在公共场所、人群聚集和大量部署物联网设备的地方,智能设备在请求MEC服务时必须要和该AP连接的其他设备竞争连接服务[2],即竞争网络资源把任务卸载到MEC服务器获取计算服务。

图1 MEC卸载网络
MEC网络的接入主要是无线网络的方式,例如Wi-Fi。针对Wi-Fi的无线访问接入协议,IEEE在2020年发布的802.11ax协议相比于之前的802.11协议较好地提高了Wi-Fi网络效率[3]。然而,802.11ax为了确保向后兼容,基本的网络接入传输数据方法保持不变[4]。这种无线网络接入方法被称为载波感应多路接入与避免碰撞(CSMA/CA)算法:每个待接入设备随机“退后(backs-off)”,即在接入网络前等待一定数量的时隙(back-off slots)。这个时隙被称为竞争窗口(contention window,CW)。为了减少多个设备相同的随机退避的概率,IEEE 802.11退避算法规定每次传输超时(碰撞)后CW会翻倍,并定义了CW的最小值和最大值。尽管这种默认的方法需要很少的计算,但是会导致低效的网络接入,特别是在有密集接入设备的MEC网络中,无法高效、稳健地应对网络的快速变化[5]。
CW的选取大小对网络性能有直接的影响,因此CW优化一直是网络优化研究分析的主题。常规的优化方法包括使用控制理论[6]和监测活跃用户的数量[7]。随着具有高计算能力的网络设备的普及,现在可以使用机器学习(machine learning,ML)方法来分析优化CW[8-10]。但ML方法的选择受到网络优化问题本身性质的很大限制。如分析模型[11],可以提供最佳的CW值,但只在某些假设和准静态设置下,所以无法依赖它们来训练模型。无导数优化算法是较合适的选择,强化学习(reinforcement learning,RL)就是无倒数优化算法,是较为适合用来改善无线网络性能的ML方法[12]。因为RL涉及到智能软件代理(网络节点,AP)在环境(MEC卸载网络)中采取行动(设置CW值),以最大化奖励(网络吞吐量)。RL的无导数、无模型的特性,比传统的、基于模型的优化方法有更好的泛化能力。近年来,已经有在计算机无线网络中使用强化学习的研究:文献[8,13]将RL应用于无线局域网的干扰对策;文献[14]提出基于RL的通用适应性介质访问控制(MAC)算法;用于水声传感器网络的MAC方法[15]、无线网络资源调度算法[16]以及用于调整可重新配置无线天线的方法[17]都使用了强化学习。文献[18]也使用了RL用于网络传输优化。但他们大部分使用的是Q-learning,是表格型的RL求解方法,这不适合应用在具有密集连接、网络拓扑动态变化的MEC卸载网络环境中。因为Q-learning存在维数灾难——查找和存储都需要消耗大量的时间和空间。文献[19]指出,通过使用深度人工神经网络(deep neural networks,DNN)构建深度强化学习(DRL),可以进一步提高RL的性能,使其具有更优越的可扩展性。
因此,该文提出将DRL改进并应用于优化物联网的MEC卸载网络中,通过合理预测、设置CW值来优化提高MEC卸载网络的吞吐量。改进两种DRL方法,深度Q网络(deep q-network,DQN)[19]和深度确定性策略梯度[20](deep deterministic policy gradient,DDPG),使其应用在Wi-Fi作为MEC的AP的环境中。仿真实验表明这两种方法都提升了MEC卸载网络的性能,特别是在密集设备接入的动态场景中,且没有破坏网络的公平性。
1 基于深度强化学习的MEC卸载网络优化方法
本节研究了强化学习、深度强化学习理论方法;然后基于WiFi物联网的MEC卸载网络模型,建立出深度强化学习优化CW算法。
1.1 强化学习和深度强化学习
RL源自于马尔可夫决策过程(Markov decision process,MDP),RL的基本理论是:使用一个可以自我学习的代理agent来替代模型分析的方式去寻找最优解。agent能够通过相应的行动action与环境environment互动(采样state,如图2),每一步行动都会使agent更接近(或更远离)其目标(奖励,reward)。通过训练,代理增强了其决策策略(执行什么action),直到代理学会(获得奖励)了在环境的每个状态下的最佳决策(动作顺序)。在DRL中,代理的决策是由一个DNN训练得到的。该文考虑了两种不同行动空间的DRL方法:DQN的离散动作策略和DDPG的连续动作策略。DQN试图预测每个动作的预期奖励,即是基于价值(奖励,reward)的方法。与基本的RL相比,DQN附加了深度神经网络,可以更有效地推断出尚未观察到的状态的奖励。与DQN不同,DDPG是基于策略(动作,action)的方法,它试图直接学习最优策略,可以产生连续的动作输出。DDPG包括两个神经网络:一个行动者(actor)网络和一个评判者(critic)网络。行动者根据环境状态做出决定动作,而评判者是一个类似DQN的神经网络,试图学习行动者行动的预期奖励收益。

图2 强化学习模型
为了将DRL应用于MEC计算卸载网络,该文做了一个映射,一个代理(部署在AP上)、环境状态(网络环境)、可用的行动(设置相应的CW值)和收到的奖励(网络吞吐量)。AP上的代理是观察网络的状态,设置CW值(动作),以使网络性能(奖励)最大化。
1.2 MEC卸载网络优化的DRL原理
作为MDP的改进版,RL是在不知道可观察到的状态以及不知道每个状态的转移概率时解决MDP问题的方法。实际上,RL是一个部分可观察的马尔可夫决策过程(partially observable Markov decision process,POMDP),它假定不可以完全观察到环境的所有状态,从部分状态和历史经验中推测新状态和预期的奖励。POMDP表示为(S,A,T,R,Ω,O,λ):
S:状态(state)集合;
A:动作(action)集合;
T:状态之间转换的概率集合;
R:奖励函数,R=f(S,A);
Ω:观测结果集合;
O:观测概率集合;
λ:折扣系数。
因为AP能观察到网络的全部接入,并可以通过信标数据帧(beacon frames)以集中的方式控制接入的设备,还具有处理DRL优化的计算要求,所以把代理agent部署在接入点AP上。此外,AP能够与其他AP交换信息,可以成为基于软件定义网络(SDN)的多代理MEC架构的一部分[5]。
环境状态s∈S是当前连接到网络的所有设备的确切状态。由于网络的接入设备是动态变化的,不可能收集到确切的信息。因此,该问题被表述为POMDP而不是MDP。
代理的行动a∈A直接对应于设置新的CW值。在基于Wi-Fi AP的MEC中,CW有默认的最大值和最小值(CWmin=25-1=31,CWmax=210-1=1 023)[21],在最大值和最小值的区间,如果设置一个较小的CW值,当许多设备试图在同一时间传输数据,很有可能其中一些设备有相同的退避间隔。这意味着将不断出现碰撞,对网络性能产生严重影响。另一方面,如果设置较大的CW,当很少有设备传输数据时,它们可能会有很长的退避延迟,导致网络性能下降。该文提出的两方法的动作策略分别为离散的和连续的。离散的动作会输出正整数a∈{0,1,2,3,4,5},即agent根据环境状态在0到5取一个整数;连续的动作会输出一个0到5之间的实数a∈[0,5]。动作的输出a值将被用来更新网络的CW值,根据以下公式:
CW=⎣25+a」-1
(1)
即可能的动作集合A=[0,5],每个动作执行后会更新网络的CW值,并伴随着网络环境状态s∈S的改变,产生新的环境s'∈S,环境s→s'会有一个概率转移T(s'|s,a)。
该文对于奖励r∈R,设置为与网络性能——网络吞吐量(network throughput,NT,每秒成功传输的比特数bits/s),相关的变量。因为在部署了agent的AP上,可以较为容易、及时地获取到当前时间的网络吞吐量。其次,对于标准的DRL的奖励是在0到1之间的一个实数,因此对奖励r做归一化处理,用观察到的每秒比特数除以预期的最大吞吐量:
(2)
每次观察环境状态为ω∈Ω,它表示为agent根据观察信息所得的网络当前最大可能的状态。对每个观察到的环境有一个观测概率o∈O,表示在网络中观察到的当前碰撞概率pcollision(传输失效概率),该概率根据传输的数据帧的数量Nt和正确接收的数据帧的数量Nr来计算:
(3)
pcollision的值直接反映了动作action选取的CW值的优劣性。一般的,AP上的agent不能直接获取,但是AP作为总的接入点,作为发送方或接收方参与了所有数据帧的传输,通过数据帧的数据位绑定Nt,AP能够获取到设备的Nt,对于Nr可以直接在AP端统计得到。
1.3 DRL优化MEC卸载网络
对于该文的两种DRL(DQN和DDPG)的理论推导和性质,就不做展开,读者可以参考文献[20-21]来辅助理解两种DRL的性质和异同。使用Wi-Fi作为AP,默认的CW设置按照标准的802.11协议规则,即指数退避算法(exponential back-off algorithm,EBA)[21],在[0-CW]中选择随机退避时隙,当冲突发生时,CW在限制大小内以2的指数递增(CW∈[CWmin,CWmax]) 。参考标准EBA,该文改进两个DRL方法——DQN和DDPG,用于优化MEC计算卸载网络。通过DRL优化网络的CW值,最大化全局网络吞吐量为奖励——优化目标,以提升网络的效率。如图3所示,agent部署在AP上,获取网络环境状态,设置相应的CW值来获取最大化全局网络吞吐量。

图3 DRL优化MEC卸载网络模型。
agent分别基于DQN和DDPG,它们的区别在于:DDPG实质上是DQN的一种在连续动作上的扩展算法,DDPG在DQN的基础上多了一些决策(policy)系列的操作。因此对于DQN和DDPG,该文设计了同样的CW优化算法:
DRL-CW优化算法:
1.初始化观测Bobs,长度为h
2.获取agent的动作函数参数θ
3.获取agent的动作函数Aθ
4.定义变量收、发帧数Nr,Nt
5.设置交互时间周期Δt
6.获取训练标志位isTrain
7.设置重放缓存B
8.最新更新时间设置为当前时间:
lastupdate←currenttime
9.初始化CW←31
10.初始化状态向量s
11.fort=1,2,…,∞ do:
12.获取Nt,Nr
13.把Nt,Nr放入Bobs中
14.if (lastupdate+Δt)≤currenttime:
15.obs←getObs(Bobs)#生成观察值
16.a←Aθ(obs)#生成执行动作值
17.CW←(⎣25+a」-1)#更新CW
18.if isTrain :
19.NT←(Nr/Δt)#计算有效网络吞吐量
20.r←normailization(NT)#奖励
21.把(obs,a,r,s)放入B中
22.s←obs
23.b←从B中小批量取样
24.用b训练优化Aθ的参数θ
getObs()根据当前网络的收发状态生成相应的状态值。
normailization()的功能是归一化奖励值,参考公式(2)。
模块getObs()用于计算最近观察到的碰撞概率H(pcollision)历史的平均值和标准偏差,由一个固定大小(h/2)和步长(h/4)滑动窗口决定。滑动窗口的采样将Bobs数据从一维变为二维(滑动窗口的每一步产生两个数据点)。这样产生的数据可以被看作是一个时间序列(窗口的每一步对应一组数据,每组数据具有前后的时间顺序,且状态的观测值也在不断更新),意味着可以用循环神经网络(RNN)分析它。因为,与使用全连接神经网络进行训练分析优化相比,RNN的设计[22]可以更深入地学习到agent的行为与网络性能之间的直接和间接关系。
2 仿真实验设置
实验是基于ns3-gym[23]网络仿真平台实现的,ns3-gym融合了强化学习RL的开发分析工具OpenAI Gym。另外,基于ns3-gym,使用Python开发实现了DQN和DDPG的神经网络。实验在Ubuntu 18.04.5 LTS下进行,软件版本:Python (3.6.5);TensorFlow (1.14.0);Torch (0.4.1)。
2.1 仿真平台的网络模型设置
在ns3-gym网络仿真平台,搭建如图3所示的MEC计算卸载网络模型,其相关参数如下:Radio Channels:error-free, 20 MHz;Protocol:IEEE 802.11ax;Modulation:1024-QAM;Coding Rate:5/6;Transmissions:single-user;Frame-Aggregation:Disabled;Transport Layer:UDP, 1500 byte packets。
为了方便DRL的训练和应用,做了如下的实验条件假设:(1)连接到AP的设备能完整、快速地把自身网络状态信息传递给AP,即AP可以立即得到Nt,Nr;(2)agent可以立即更新设置各个连接设备的CW值。这样的假设是合理的,因为基于Wi-Fi作为AP的MEC计算卸载网络类似小范围的局域网,传输延迟可以忽略不计。如果考虑了传输延迟,会导致DRL的学习周期较长,收敛较慢。因此,在该实验中,不考虑延迟的因素,但这不影响实际的应用。总的来说就是忽略延迟影响,但这样的假设不会导致在实际的网络中的应用与实验偏差较大。
2.2 DRL的训练过程优化
该文优化应用DQN和DDPG与MEC计算卸载网络主要分为三个阶段:(1)预训练学习;(2)训练学习;(3)应用阶段。预学习阶段先使用标准的EBA,让整个MEC网络环境运行起来,作为DRL训练前的热身阶段;训练学习阶段,DQN和DDPG分别利用提出的CW优化算法来优化CW的设置;在训练完成后是应用阶段,即将训练好的agent部署到MEC网络中替代标准的EBA算法。
为了让DQN和DDPG训练稳定,学习到有效的参数,该文对这两种方法的参数更新均采用局部(local)和目标(target)神经网络的训练学习方法。action的参数学习用两个神经网络同时学习的办法,但CW优化算法使用在目标神经网络的结果,目标神经网络定期获取局部神经网络的参数wlocal来更新自己的网络参数wtarget:
wtarget=τ×wlocal+(1-τ)×wtarget
(4)
通过这样的训练方式,在一个时间段内固定目标网络中的参数,定期按公式(4)来更新参数,达到稳定学习目标的效果,τ是软更新系数,确保目标网络参数的稳定更新。
对于DQN和DDPG方法的训练参数,设置的参数如表1所示。
这些超参数设定是根据多次实验,采用随机网格搜索和贝叶斯优化得出的训练、测试效果较好的参数,具备一定的参考价值。两种算法的神经网络使用相同的结构:一个循环的长短期记忆层(long short-term memory,LSTM),然后是两个密集层,形成8×128×64的网络结构用于action的生成,即a=Aθ(st|θμ),在t时刻状态st决定了action的值a;μ是上述的网络(确定性策略网络),θμ是它的参数,用于生成在st下的action。

表1 DRL训练参数设置
使用LTM这类RNN可以让agent把之前的观察训练经验考虑进去。在agent的动作和网络仿真中都加入了随机性。每个实验进行15轮(epoch),前14轮为训练学习阶段,最后一轮为应用测试阶段,每轮60秒(60/0.01=6 000个episodes)。每个agent与环境交互周期为0.01 s(即10 ms),在交互周期之间执行CW优化算法。
为了让agent尽可能的探索(exploration),在执行每个action前都会加入一个噪声因子(noise factor),该噪声因子在学习阶段中逐渐衰减。对于DQN,噪声是指用随机的action替代agent行为的概率。对于DDPG,噪声从高斯分布采样并加入到代理的决策中。这样做的目的是为了缓解DRL的本身的exploration-exploitation的问题——寻找新经验(exploration)和通过已知策略获得最大化奖励(exploitation)是矛盾的,不能兼得。具体实现如下:

噪声帮助DRL进行explorationDQN:A'θ(st)=random(Aθ(st|θμ),random(A))DDPG:A'θ(st)=Aθ(st|θμ)+noise#A'θ(st)是由确定性策略(DPG)加噪音得到的
在DQN执行动作a之前,加入一个随机噪音,即有较小的概率选择从动作库A中随机选择一个动作来执行,保证了算法的exploration。在DDPG中也是类似的,不过因为DDPG是连续动作,不适合随机选取,就在其后加上一个较小的noise来实现。同样保证了agent的exploration性,以适应新的环境状态。
2.3 实验基线与训练周期
该文使用802.11默认的退避算法作为实验基线对照:标准的EBA。实验的MEC卸载网络拓扑环境分两种,固定设备数量的(静态网络拓扑)和设备数量动态变化的(动态网络拓扑)。接入设备数量为5到50个。上一节中,之所以设置15个epoch的训练周期是实验分析得到的,参考图4:
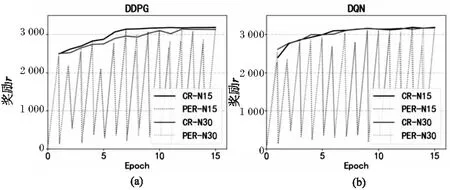
图4 DRL训练奖励变化
图4中CR为cumulative-reward(最大化累积奖励),PER为per-episode-reward(是每个episode中的步进奖励)。NX的意思是多少个设备(N15即15个设备接入)。图中展示了DQN和DDPG在15、30个设备接入的静态网络拓扑结构下,经过12个epoch左右的训练便可获得基本趋于稳定的奖励,即在12个epoch的训练学习后可以使模型收敛。后续实验统一使用15个epoch的实验周期,即保障在12个以上使模型收敛,且无需更多的epoch。
3 实验结果与分析
3.1 静态网络拓扑实验结果
在静态网络拓扑结构中,整个实验过程中都有固定数量的站点连接到AP。从理论上讲,恒定的某个CW值是可以达到最佳的网络性能[5]。静态场景的实验是为了测试DRL算法经过训练学习是否能够实现最佳的CW设定,以及与标准802.11的EBA基线相比有什么差异。图5(a)是在不同数量{5,15,30,50}连接设备下多次实验的统计平均结果,置信区间为95%。

图5 静态(a)和动态(b)网络拓扑中各 方法网络性能的对比
从图中的结果可见,标准的EBA的性能在较多的设备接入MEC计算卸载网络时,网络的整体性能有明显的下降,但DDPG和DQN可以在静态网络条件下优化CW值以应对网络拓扑的变化。与标准的EBA相比,在较少的设备连接时(5个),DRL能提升约6%的性能;在较多设备连接时(50个),约有46%的提升。
3.2 动态网络拓扑实验结果
在动态网络拓扑的环境下,每次实验过程中,接入设备的数量从5个以每次5个的速度递增,这样做的目的是为了增加MEC计算卸载网络中的碰撞率,测试算法是否能够对网络变化,做出合适的反应来稳定网络性能。
在图6(a)中,左边的纵坐标展示的是网络性能,右边的纵坐标展示的是接入设备的数量,横坐标是实验时间。接入设备数量从5增加到50,各个方法的性能变化如图中各线所示,各方法对CW的设定效果反映在网络的瞬时吞吐量上;两种DRL方法与EBA对比可见,有较好的稳定性,在设备数量增加到50时,DQN和DDPG都可以保持网络性能的稳定,网络吞吐量没有明显的下降。再参考动态网络拓扑的多次实验均值结果图5(b)(类似于图5(a)),可见DRL优化CW值的方法可以较好地优化MEC卸载网络多接入情景下的网络性能,且具有优于标准EBA方法的效果(50个接入设备时DRL约有36%的相对提升)。

图6 动态网络拓扑中各方法的瞬时 性能对比(a)与CW设置(b)
对于DRL如何设置相应的CW,该文给出动态网络拓扑中一个接入设备的CW值变化情况,如图6(b)所示。不同的DRL方法所展现的CW不一样,因为DQN是离散动作类型的RL方法,而DDPG是连续动作型的,其本质原理可参考公式(1)及其说明。DDPG的连续动作机制可以比DQN优化的CW值更快速变化,可以更好地适应网络的动态变化;标准的指数退避EBA作为参考,但其被DQN的画线所覆盖。
3.3 DRL是否有失公平
因为设备都是相互竞争地接入AP请求MEC计算卸载服务,针对CW值的优化算法是否会导致接入设备的不公平竞争也是需要考虑的问题。该文使用Jain’s fairness index[24]来评价网络的公平性,计算公式如下(0 (5) 其中,Ti为第i个设备的平均网络吞吐量,n为设备的总个数。 实验计算结果如图7所示。 从图7的实验结果来看,DRL方法并没有让网络失去公平性,几乎与标准的BEA保持一致。 图7 动态网络拓扑下各方法的公平性 该文提出两种DRL:DQN和DDPG方法,用于解决IoT的MEC卸载网络场景下面对大量接入设备时使用标准EBA导致网络性能下降的问题。提出针对Wi-Fi作为MEC卸载网络AP的CW值优化算法,应用DRL方法训练CW优化算法后在不同网络拓扑下可以有效地设置合理的CW值以稳定网络的吞吐量。实验结果表明,DRL可以解决CW优化问题:即使在快速变化的网络拓扑结构下,两种算法都具有稳定网络性能的能力,DDPG连续动作的方法略优于离散动作的DQN。最后,实验在静态和动态网络拓扑环境下的结果都表明了DRL方法优于默认的退避算法,且没有破坏网络的公平性。
4 结束语
猜你喜欢
动漫界·幼教365(大班)(2021年4期)2021-05-23
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
电子技术与软件工程(2016年23期)2017-03-06
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年12期)2016-06-14
少儿科学周刊·少年版(2015年4期)2015-07-07
