
基于改进决策树的道路交通事故成因耦合分析
2022-06-29 12:37郭兰英张晓静
计算机技术与发展 2022年6期
郭兰英,张晓静,程 鑫
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
近年来在中国机动车数量快速增长的情况下,交通事故及伤亡人数呈不断上升趋势,不论是造成的损失或是致死率都远大于发达国家,交通事故已成为中国交通管理所面临的严重问题。
目前国内外学者已对道路交通安全开展了广泛研究。胡骥等[1]针对翻车事故引入Ordinal Logistic 模型,结果表明是否正确使用安全带为主要影响因素,但变量独立性并未得到检验,还需进一步完善。江欣国等[2]针对危险驾驶行为建立广义有序Logit模型发现双责事故严重性更高。冯忠祥等[3-5]采用Logistic和均值异质性Logit模型进行事故预测,发现时间和天气对高速交通枢纽段影响显著,且不同形态事故影响因素具有异同性。Alireza Toran Pour等[6]利用决策树模型探究澳大利亚墨尔本地区行人交通事故影响因素,结果发现邻里社会特征对于行人撞车事故有重要影响。Zijian Zheng等[7]采用梯度提升技术,全面分析公司、驾驶员信息、卡车类型以及碰撞类型等特征,结果表明卡车公司和驾驶员特征具有显著影响。吕璞等[8]针对现有模型存在准确性低以及泛化性能较弱等问题,提出基于反残差和注意力机制的预测模型,实现对不同事故等级的分类,但并未考虑路侧交通设施的可能影响因素,且样本数据偏少。
李英帅等[9]建立随机森林模型探究自行车事故可能影响因素并进行特征重要性分析,发现道路隔离设施类型影响显著。戢晓峰等[10-11]等针对传统模型无法量化影响因素等不足,通过建立有序Logit模型筛选自变量并做出优化,最终形成两阶段模型TSM对某一平纵组合路段(CHVA)进行致因分析,但模型仅分析单一变量影响,并未说明多因素间耦合作用对事故的影响。此外,戢晓峰又引入事故规模作为指标探究交通流特征的影响机理,但模型只考虑了二级公路,并未提及在其他等级公路是否同样适用。
孟祥海等[12]采用Bow-Tie模型探究城市主干道上机动车间碰撞事故及其后果,发现驾驶员正常驾驶但无其他安全设施事故发生率最高。Tavakoli Kashani Ali[13]建立结构方程探究伊朗行人碰撞事故的有效影响因素,发现高速公路、重型车辆、老年和女性司机与事故规模增加有关。陈艳艳等[14-15]通过建立二分类Logistic模型研究山区连续长下坡路段以及城市道路交通事故影响因素,发现坡度和事故地点为山区坡路主要影响因素。
赵跃峰等[16]采用有序Logit和部分优势比建立公路隧道交通事故影响因素模型,大货车数量、车辆总数、时间、天气四个变量与事故严重程度显著相关。李贵阳等[17]针对高速公路多车事故建立SVM模型,结合敏感性分析事故影响因素变量,结果表明不良驾驶行为、天气、碰撞类型均对事故后果有显著影响。Mohammad Jalayer等[18]针对错误驾驶行为(WWD)建立random-parameters ordered probit模型评估事故伤害程度,发现驾驶员年龄、驾驶员状况、路面状况和照明条件等因素显著加剧了WWD碰撞的伤害程度。Mahdi Rezapour等[19]选择有序Logit模型研究碰撞事故严重程度的影响因素。结果表明,酒精、性别、路况、车辆类型、碰撞点、车辆操纵、安全设备使用、驾驶员行为和每车道的年平均每日交通量(AADT)是影响单车事故的重要因素。安全设备的使用、照明条件、速度限制和车道宽度是影响多车事故的重要因素。卢英志等[20]针对云南山区二级公路摩托车碰撞事故,采用Logistic模型分析其影响因素,但研究数据太过受限,无法得出更为全面的结论。
根据对以上文献的分析,得出目前存在模型准确率低、数据及特征不够全面、过多考虑单一因素的影响而忽略多因素间的耦合机理等问题。论文将结合中国交通数据,提出基于梯度提升决策树的递归特征消除法(GBDT-RFE)预测模型探究道路交通事故严重程度的主要影响因素,通过对比分析随机森林、极端随机树的模型效果,证明了GBDT-RFE特征选择的有效性,预测精度基本稳定在90%。针对筛选得到的特征使用决策树方法进行多因素耦合分析,为交管部门提供决策支持。
1 道路交通事故数据来源
中国交通数据信息采集均遵循统一标准,即公安交通管理部门制定的《道路交通事故信息采集项目表》,共包含56个单项,能够实现对人-车-路-环境的整体描述。论文研究数据来源于西安市道路交通事故数据库,每条事故记录均包括事故编号、事故地点、日期、事故类型、事故形态、天气在内共计115个字段。
选取2014年7月到2015年6月发生的16 457起道路交通事故作为研究对象,其中包括车辆间事故11 314起,行人-车辆事故3 527起以及单车事故1 616起,每类事故又包含若干类详细事故形态,具体事故数量与所占比例如表1所示。

表1 事故形态统计分布
2 基于GBDT-RFE模型的交通事故耦合机理分析
基于GBDT-RFE的道路交通事故严重程度预测模型训练流程如图1所示。对原始数据集进行删除、填充、异常值替换等数据清洗步骤,利用方差过滤、相关性分析初步筛选特征,对于类别不均衡问题作采样处理,将预处理后的数据输入模型训练并利用网格搜索进行参数寻优,得出特征重要性排序并对其可视化,将特征选择结果输入决策树模型得出IF…THEN形式的分类规则集。

图1 GBDT-RFE训练流程
2.1 数据预处理
2.1.1 数据清洗
论文使用的道路交通事故数据在采集或录入阶段可能出现丢失、错误等问题,导致原始数据存在严重缺失现象,因此需对问题数据进行清洗,如表2所示,若某列特征变量缺失超过50%,则删除该特征,缺失率低于50%,使用众数填补。
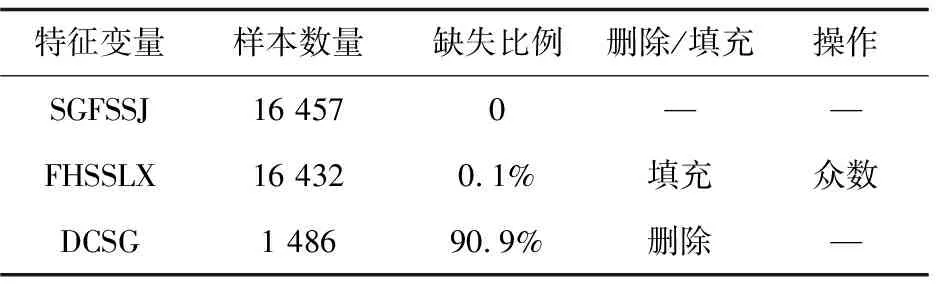
表2 数据清洗策略
2.1.2 方差过滤
论文采用方差分析方法衡量道路交通事故数据各列特征取值变化的波动性,进行初步特征筛选,如式(1)所示,若方差低于阈值,则进行过滤,方差为0,表明此列特征取值无变化。
(1)
其中,x为列样本均值,n为样本数量,xi为样本取值。
以特征列YZWXP(是否运载危险品)、SFDXSG(是否典型事故)、JTXHFS(交通信号方式)的分布及取值情况为例,特征YZWXP取值为2(否)占比约99.9%,方差为0.25,整列特征比较平稳,相较特征JTXHFS(方差为0.58)来说波动极小,而特征SFDXSG整列取值毫无变化,方差为0,表明特征并无区分度,予以删除。
2.1.3 相关性分析
道路交通事故数据样本由115维特征组成,为考察特征间相关性,论文借助协方差度量,通过计算相关系数矩阵统计多维随机变量间相关性,如式(2)所示。
X=[X1,X2,…,Xn]T
{xk.=[xk1,xk2,…,xkn]T|1≤k≤m}
(2)

由于随机变量取值范围不同,对其进行归一化处理获得相关系数,如式(3)所示,η为1表示变量完全正相关,η为-1表示完全负相关,0则认为变量无相关。
(3)
论文通过对样本数据各特征列作相关性检验可得其相关系数大小,如TQ(天气)和LBQK(路表情况)相关性达0.65,可在建模过程中考虑剔除其中之一,相关性较小变量予以保留。
2.1.4 数据重采样


(4)
(5)

由于SMOTE会随机选取少数类样本用以合成新样本,并未考虑周边样本分布,容易产生噪音,致使新合成样本与周围多数类样本重叠而难以分类。ENN(edited nearest neighbours)是一种欠采样技术,通过某种规则剔除重叠样本,达到数据清洗的目的。采样前两类事故比约为1∶7,而采样后两者比例接近1∶1,达到较为均衡状态。
2.2 GBDT-RFE模型建立
2.2.1 GBDT模型
梯度提升树GBDT将决策树与Boosting集成学习思想相结合,通过拟合损失函数的负梯度在当前模型的值改变数据的权值或概率分布,依次对新的学习器不断进行迭代,逐渐减小训练过程中产生的残差,最终使用加法模型组合一系列弱分类器从而得到效果较好的强拟合模型。如图2所示,x为样本数据,yi(i=1,2,…,n)为标签值,使用CART回归树作为基础模型,利用第n个CART拟合前n-1个CART的残差,模型输出则为各基础模型预测值的累加。

图2 GBDT训练模型
GBDT模型可表示为:

(6)
其中,x为样本数据,TM(x)为第m棵决策树,M为树的个数,FM(x)为模型最终预测值。
算法步骤如下:
(1)给定数据集{(x1,y1),(x2,y2),…,(xN,yN)}作为模型输入。
(2)初始化第一个模型为F0(x),如式(7)所示,利用对数几率初始化,∑yi是正样本个数,∑(1-yi)为负样本个数。

(7)


(8)
其中,N为样本数量。


(5)更新强学习器,如式(10)所示。

(10)
其中,J为叶子节点数量(j=1,2,…,J),Rmj为对应叶节点区域,I(x∈Rmj)为指示函数,x∈Rmj,则I(x)=1,反之I(x)=0,η为模型训练的学习率。
(6)得到加法模型,如式(11)所示。

(11)
2.2.2 GBDT-RFE模型
递归特征消除法(recursive feature elimination,RFE)是一种贪婪的优化算法,旨在找到性能最佳的特征子集。其主要思想是在不断调整的特征子集上反复构建模型进行训练评估,直到找到最佳子集或达到最大迭代次数为止。论文使用GBDT作为训练模型,迭代过程中使用穷举法筛选子集并利用模型验证,从而得到最优子集。
GBDT-RFE算法步骤如下:
(1)给定数据集{(x1,y1),(x2,y2),…,(xN,yN)}作为模型输入,N为样本数量;
(2)初始化原始特征集合S,特征排序集R=[],whiles=[];
(3)构造训练集X=X[:s];

(12)
(13)
其中,vt是和节点t相关联的特征,L为叶子节点数量,S是数据切分点,R1={x|x≤s},R2={x|x>s},c1是使R1内部平方损失误差达到最小的值,c2同理,N1、N2分别是R1、R2的样本点数。
(5)获取全部特征的样本集合训练GBDT-RFE模型,获得各个特征重要度,特征j的特征重要度通过j在单棵树中重要度的均值衡量,如式(14)所示;

(14)
其中,M是树的数量。
(6)去除重要度最低特征并更新特征集合R;
(7)基于新数据集训练模型,循环以上过程直至S=[]。
(8)计算比较各个子集获得的模型效果,选取最优变量集合并验证。
3 实验结果及分析
3.1 数据预处理结果及分析
论文经过一系列数据预处理过程,初步筛选出包括时间、道路、环境在内的17个候选特征。大量详细的编码虽可覆盖所有类别,但其描述的多是特征异常状态。例如,DLLX(道路类型)特征中单位小区自建路、公共停车场、公共广场三类仅占0.06%、0.04%、0.02%,为提升数据价值,更好利用数据,论文对部分编码进行合并,结合中国对事故严重程度等级分类标准,将仅有财产损失的定义为轻微事故,涉及人员受伤或死亡的定义为严重事故。
3.2 GBDT-RFE特征选择结果及分析
论文以历史道路交通事故数据为样本,通过将筛选出的特征作为输入,分层随机抽取80%作为训练集,20%作为测试集建立模型,并使用10折交叉验证综合评价。图3为不同特征数量下的模型精度,横坐标Number of Features为特征数目,纵坐标ACC为模型预测准确率,当特征数量为6时,模型精度达到80%,而当特征数量为11时,ACC值趋于平稳,表明之后增加的变量几乎无影响。特征相对重要性排序如图4所示,横坐标为各列特征重要性分数,纵坐标为特征列名称,可以看出,DLLX、ZHDMWZ特征重要性较高,分别达到0.2和0.155。

图3 不同特征数量下的预测结果

图4 特征相对重要性排序
为验证特征选择有效性,分别对随机森林(RF)、极端随机树(ET)和GBDT-RFE使用相同数据训练,并在相同测试集上测试,结果如表3所示,分别列举了特征选择前后各个模型的准确率(Accuracy)、召回率(Recall)、精确率(Precision)、f1分数(f1)以及耗时。
GBDT模型准确率为0.901,召回率为0.923,精确率为0.902,f1分数为0.912,均优于ET和RF模型,GBDT-RFE模型准确率为0.909,较GBDT模型有所提升,其他指标无太大差异,但耗时为1.9 s,较之前的2.3 s有所减少,表明基于GBDT-RFE的特征选择模型能较好区分两种事故。

表3 模型预测结果对比
3.3 基于决策树的事故成因耦合模式提取及分析
选取历史道路交通事故数据作为研究对象,依据图4筛选出的变量DLLX、ZHDMWZ、ZMTJ、DLXX、JTXHFS、FHSSLX作为输入建立决策树模型,由于特征属性多为多分类变量,为避免信息流失,论文构造多叉树结构,并对数据进一步转化规约,从而改进数据质量,挖掘具有实践意义的推理规则集。为控制树模型生长规模,设置树深度为6,每个子分支最小记录数至少为10,完成决策树模型构建。论文所构建的决策树自顶向下每一条路径都代表着一个推理规则,为防止选取到偶然性的事故因素组合模式,从整个规则集中筛选置信度水平大于70%的部分规则摘录如下所示。
规则1:IF 交通信号方式为有控制,照明条件为白天,道路线型为平直,道路横断面位置为机动车道,道路类型为一般城市道路,THEN 事故等级为财产损失事故,置信度为0.745。
规则2:IF 交通信号方式为有控制,照明条件为白天,道路线型为弯坡,道路横断面位置为机动车道,道路类型为一般城市道路,THEN 事故等级为伤亡事故,置信度为0.767。
规则3:IF 交通信号方式为无控制,照明条件为白天、黎明或黄昏,道路横断面位置为机动车道,道路类型为城市快速路,THEN 事故等级为财产损失事故,置信度为0.775。
规则4:IF 交通信号方式为无控制,照明条件为夜间无路灯,道路横断面位置为机动车道,道路类型为城市快速路,THEN 事故等级为伤亡事故,置信度为0.938。
(1)对比规则1、2发现,道路线型的改变对事故严重程度有较大影响,弯坡路段事故率相应提高且后果较为严重,有关部门应在此设置警告标志,提醒驾驶人注意安全。
(2)对比规则3、4发现,夜间无路灯照明条件下事故严重程度较高,更易引发伤亡事故,置信度达到0.938。若有条件,有关部门应尽可能多安装照明设施,减轻事故后果。
通过对以上规则的对比分析,发现弯坡路段、夜晚无路灯照明条件下更易导致严重事故的发生,根据控制变量法,在多个因素固定下改变另一因素得到了不同事故结果,验证了GBDT-RFE模型特征选择的有效性。利用实验得到的规则集可甄别出交通事故危害性,引起相关人员重视,有助于驾驶员提高警惕,便于交通管理人员引导交通,预防交通事件发生。
4 结束语
依据历史道路交通事故数据构建事故严重程度影响因素预测模型。模型建立前对原始数据进行清洗,根据设定阈值删除或填充缺失值、异常值,计算每列方差剔除波动较小的特征变量,引入协方差得出相关系数矩阵,分析各因素间的相互扰动,对数据进行采样使得类别均衡,将预处理后的数据输入GBDT-RFE模型对事故严重性分类并得出特征重要性排序。
通过对比RF、ET、GBDT、GBDT-RFE模型预测结果,验证了GBDT-RFE在事故严重性预测方面具有较高的精度与良好的稳定性,准确率达到了0.909,召回率达到了0.920。为对各因素间耦合作用进行分析,论文使用决策树提炼具有一定样本数量且置信度高的规则集,从微观层面掌握道路交通事故的总体特征。有关部门可在交通设施管理和基础建设等方面采取措施改善行车环境,通过驾驶员培训和安全教育工作提高行车安全。
猜你喜欢
小雪花·成长指南(2020年2期)2020-10-12
科学与信息化(2019年28期)2019-10-21
环球时报(2017-12-13)2017-12-13
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
科学与财富(2016年32期)2017-03-04
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
决策与信息·下旬刊(2013年1期)2013-03-11
幼儿智力世界(2009年2期)2009-03-10
