
基于融合模型的名词隐喻识别
2022-06-29 12:37苏魁麟吕学强
计算机技术与发展 2022年6期
苏魁麟,张 凯,吕学强,张 乐
(1.北京信息科技大学 网络文化与数字传播重点实验室,北京 100101;2.首都师范大学文学院 中国语言智能研究中心,北京 100048)
0 引 言
隐喻是用来描述和理解抽象概念的主要手段,它不但是一种语言现象,也是一种认知方式[1]。认知是指人们获得知识或应用知识的过程,是人类信息加工的基本过程[2],隐喻对人们的交流和认知有莫大的帮助,在人们日常用语或行为中都存在隐喻的特性,因此隐喻研究近年来越来越受关注。
隐喻的理解是隐喻理论的一个重要部分,因为隐喻的工作机制和认知功能是在理解过程中达成和体现出来的。隐喻的理解过程包括:隐喻识别和隐喻意义的推断。其作用是在人们用语言思考所感知的物质世界和精神时,能从原先互不相干的不同事物、概念和语言表达中发现如同互联网中的链接点,建立想象丰富的联系。这不是一个量的变化,而是认识上质的飞跃,难以用规则描述[3]。因此如何有效地识别隐喻是当下面临的问题,而这个问题对自然语言的下游任务如机器翻译、问答系统、情感分析、阅读理解、人机对话、文本摘要等有着制约的影响。根据句法结构,隐喻一般分为:名词性隐喻、动词性隐喻、形容词性隐喻、副词性隐喻等。名词性隐喻在自然语言中占的比重较大,因此该文围绕名词性隐喻识别开展研究。
名词隐喻指自然语言表达中通过连接词表征的隐喻类型,其源域与目标域词汇通常以名词的形式出现在句子中也称本体和喻体,如“爱情就像棉花糖,柔软而又甜蜜”为名词隐喻,本体是爱情,喻体是棉花糖,是不同领域之间的映射。如何定位源域和目标域以及实体间的映射关系是隐喻识别的一项重要因素。
名词隐喻识别研究常用的方法是基于规则,利用语法特征,传统的机器学习,再到神经网络,但是目前对名词隐喻的语义表示不够充分,特征的抽取不精确,信息丢失造成识别的准确率不高。因此如何充分地从上下文识别学习语义信息和潜在特征的抽取是隐喻识别的问题关键。
该文提出一种融合表征模型,抽取隐喻句中的潜在特征,结合上下文的语义信息和位置信息进行编码,构建针对名词隐喻识别的模型。具体而言使用BERT进行字嵌入表示,其Transformer结构中的注意力机制能够有效获得上下文的语义信息,同时对位置信息也进行向量化表征,提高喻体和本体的定位准确率,利用CNN进行局部特征的提取,融合两者特征再通过线性层得到隐喻结果。经实验表明该模型优于现有的深度学习模型。
1 相关研究
隐喻的识别起于Wilks[4]提出的语义中断理论和优先选择模型,是基于符号规则的识别方法。Fass[5]提出基于语义优先理论,由于语料库有限,不能很好地获取语义信息,因此效果不好。许雅缘[6]基于WordNet根据语义知识和语义关系识别隐喻,其原理是基于词语间的相似度计算,通过与WordNet词典中的词语计算相似度再使用加权算法得出隐喻值,但在中文方面暂时没有成熟的知识库。上述方法均需要构建大量规则和特征,耗费人力。
随着深度学习技术在自然语言处理中的广泛应用,Kim.Y等[7]提出CNN用于文本分类,它只需要很少的超参数调整和静态向量,就可以在多个基准上获得很好的结果。Luo.L等[8]应用LSTM+Attention在实体识别上的效果有了大幅提升,利用通过Attention获得的文档级全局信息在文档中实施同一Token的多个实例之间标记一致性。王子牛等[9]提出一种语言强化融合模型CNN+LSTM证明在文本分类上的提升。Yang等[10]提出将BERT与Anserini相结合,构建了一个通过外部知识库从而辅助阅读理解的方法,在问答领域有了较大提升。Peng[11]提出变体BERT模型,其主要是在解码器Transformer上进行微调改造,在多种生物医学和临床自然语言处理任务都有大幅提升。Zhang等[12]提出CMedBERT,是一种异构特征的动态融合机制和多任务学习策略,将医学知识融合到预先训练的语言模型,在基线实验上表现最优。但将深度学习应用于隐喻研究领域还是较少,Do Dinh等[13]提出基于词向量的神经网络模型识别隐喻,在效果上相较于传统机器学习等方法有了较大的提升,但网络本身比较简单且相较于现有的LSTM略逊色。王治敏[14]提出基于机器学习算法的隐喻识别,主要针对上下文和词性两种特征进行建模,但忽视了语义层的重要信息。李晗雨[15]提出基于深度学习的隐喻识别与解释方法研究,采用卷积神经网络和SVM作为模型架构,表明卷积神经网络在提取隐喻特征的表现很好。朱嘉莹等[16]提出基于Bi-LSTM的多层面隐喻识别方法,结合卷积神经网络进行建模。通过分析隐喻的多层面特征在Bi-LSTM上进行识别取得了88.8%的准确率。张冬瑜等[17]提出使用BERT+Transformer模型进行隐喻识别,能够很好地获取语义信息,但局限性是对文本的冷僻词判断较困难,无法有效提取句子的局部特征。
上述研究采用了基于规则、机器学习、深度学习的方法识别,对语义信息的挖掘不足,无法有效分辨隐喻中的动词、名词、形容词等知识。语义是隐喻中的一个重要因素,需要根据不同的上下文从不同维度去挖掘语义信息获取相应的知识,因此要满足建模的适用性和稳定性,同时如何把隐喻中隐含的潜在特征挖掘出来是提高隐喻识别的关键,二者缺一不可。
2 研究方法
2.1 基于CNN特征提取
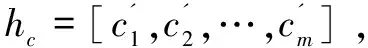
ci=f(w•xi:i+h-1)
(1)

(2)

图1 CNN模型结构
2.2 BERT预训练模型
Devlin J等[19]提出的基于Transformer结构的全新预训练模型瞬间刷新在各项自然语言处理任务GLUE的得分。从模型特点来说其输入表征不仅是词向量(token embedding),还有段表征(segment embed-ding)和位置表征(position embedding)相加产生,一定程度上丰富了特征信息。为了能够更好地学习到语言的本质增加Masked LM和Next Sentence Prediction机制,首先Masked LM随机选取少量词汇进行遮掩训练,这就迫使模型更依赖于上下文信息去预测词汇,并赋予了模型一定的纠错能力。其次Next Sentence Prediction在段落结构上进行了训练学习,与Masked LM相结合让模型能够更准确地刻画语句乃至篇章层面的语义信息。
从模型结构上Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分。其中主要涉及三个概念:Query、Key和Value,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。Attention计算公式如式(3):
(3)
其中,Q,K,V分别表示矩阵,dk表示k维序列。通过Attention构成多头机制作为编码器的一个分支,另一个分支是一个前向传播网络,在两个分支外加一个残差连接,这样就组成了一个编码器。BERT是由6个编码器组成编码层,解码层也是由6个解码器组成,其每个解码器的组成原理和编码器一致。BERT的模型结构如图2所示。

图2 BERT模型结构
实际操作中,Attention是在序列上并行,将所有序列连在一起构成Q,K,V矩阵在矩阵上进行计算,多头Attention计算公式如式(4):
MultiHead(Q,K,V)=Concat(head1,head2,…,
headn)
(4)
Concat用于连接多个头,把多个不同的注意力体连接在一起,每个head的表示如式(5):

(5)
BERT的前馈神经网络公式如式(6):
FFN(x)=max(0,xW1+b1)W2+b2
(6)
其中,W1,W2,b1,b2分别代表权重,根据反向传播自动优化。
2.3 CB模型
CNN有效提取局部特征,有效识别句子中冷僻词汇、成语古语以及干扰词汇,BERT对语义信息的理解和词与词之间位置信息的特征提取,通过融合两个模型提取到的特征,最后通过线性分类器,从而提升隐喻的识别效果。特征融合计算公式如式(7),线性层计算公式如式(8):
H=concat(hc,hb)
(7)
Y=HAT+b
(8)
其中,hc代表CNN隐藏层输出,hb代表BERT隐藏层输出,H代表融合隐藏层矩阵,AT代表权重矩阵,b代表偏置矩阵,Y代表预测值。
特征融合模型CB结构如图3所示。

图3 CB模型结构
2.4 思路框架
整体的隐喻识别思路是首先对语料进行清洗,由于语料本身为结构化,只需要去掉标点符号,然后对句子进行编码,在每个句子开头和结尾分别添加CLS和SEP标识符分别代表开始和中断,其作用是处理成BERT的输入格式;其次是对网络层的编码组合包括对BERT预训练模型的选取和CNN卷积层和池化层的维度定义,通过两者输出进行隐藏层维度的融合,再通过线性分类器,这样网络层就定义好了;最后经过多次训练得出最优结果。整体的识别流程如图4所示。

图4 隐喻识别流程
3 实 验
3.1 数据集
(1)数据来源。
采用CCL2018评测的中文动词隐喻识别任务中的数据集,由2 040条动词隐喻、2 035条名词隐喻、319条非隐喻句组成,共计4 394个中文句子。同时针对数据集进行了进一步归并,把名词性隐喻句归为一类,动词隐喻和非隐喻句子归为一类。
(2)数据标注情况。
数据分为正文部分和类别部分,而类别标注情况主要有三种,如表1所示。

表1 数据标注情况
“爱情就像棉花糖,柔软而又甜蜜”是名词隐喻,将“爱情”(本体)比喻为“棉花糖”(喻体),”爱情”本身是一个抽象的名词,但“棉花糖”是人们熟知的东西,说到“棉花糖”不禁想到“甜美”,“纯洁”等词汇,这是一种意识聚集。将抽象事物“爱情”比喻为具体事物“棉花糖”能够更好地去理解爱情的本质。
3.2 对比实验
将该文提出的模型与基线模型和同数据集实验下的最优模型进行对比实验,如表2所示。

表2 对比实验分析
3.3 评价指标
实验结果评价指标采用准确率(A)、精确率(P)、召回率(R)和F1值,分别见公式(9)~公式(12)。

(9)
(10)
(11)

(12)
其中,TP:样本为正,预测结果为正;FP:样本为负,预测结果为正;TN:样本为负,预测结果为负;FN:样本为正,预测结果为负。
3.4 实验过程和参数设置
经过多次实验,实验结果较好的参数情况如下:优化器采用AdamW,其中学习率2×10-5,eps=1×10-8,损失函数采用CrossEntropyLoss,Epoch初始化设置为100,通过设置判断条件即连续10个Epoch下验证集的准确率没有提升结束训练,并保存最优的Epoch值为4,Batch设置为32,采用BERT生成的字向量,维度100。卷积核长度设置为[3,4,5],通道设置为[100,100,100],输出维度为300。防止过拟合采用dropout,dropout=0.5,融合后的隐藏特征通过线性层进行分类。
数据集按照7∶2∶1比例分为训练集、验证集、测试集,使用pytorch框架进行预处理和模型训练等编码,使用由谷歌提供的中文预训练模型BERT,结构为12层,隐藏层大小768。
4 结果分析
根据4个评价指标在所提出的模型上的实验结果如表3所示。

表3 名词隐喻识别结果
从结果可以看出,提出的CB模型方法在各项指标上表现最优,说明能够有效地提取语义信息和潜在特征。CNN和LSTM的指标结果说明语义理解对隐喻的识别会有大幅度提高,但是也不能忽视其中的潜在的特征。CB模型的精确率和召回率较于BT模型的提升可以说明在加入CNN提取局部特征确实能够提高对于中文文本中的冷僻词汇、成语古语以及干扰词汇等特征信息的判断,从而提高名词隐喻的识别率,而CLA也是基于特征融合的思想,尽管LSTM能够获得上下文信息,但其门控制相较于BERT中MLM和NSP学习机制对语义信息的提取还是略显不足,且对长依赖问题处理效果不好。
从预测结果来说CB模型学习到名词隐喻中具有代表性的词如“像”,“好像”,”似乎”等句子预测结果都正确,同时对于没有代表性的词特征的句子如“太阳是我们心中的明灯,引领我们前行”预测正确说明对本体“太阳”和喻体“明灯”正确定位,说明对语义信息的理解很好。“广告路牌是地面上的肉疣”中“肉疣”是生僻词,但预测结果正确,说明CNN对局部潜在特征的提取能够提高识别效果。
5 结束语
隐喻是自然语言认知上的一个重要因素,因此如何有效地识别隐喻是当前需要攻克的难题。该文针对目前隐喻识别上对语义信息的理解不足和隐喻中蕴含的特征提取不够等问题,提出了一种特征融合神经网络模型,利用BERT提取文本中语义信息和表征位置信息,CNN提取隐喻中潜在的局部特征,最后在隐藏特征维度上对两者进行融合。从局部和全局两个方向上识别隐喻,从提出的评价指标来看优于现有的主流深度学习和方法。名词隐喻中不仅只有本体和喻体的映射关系。还有其他如隐喻触发词、隐喻链等特征无法针对性的去挖掘,模型还存在局限。
针对这些局限性问题可以联想到两种解决办法:
(1)对数据集进行知识性的扩充标注和扩大数据集的量,从本质上丰富数据集的特征信息。
(2)挖掘隐喻中更重要的特性并针对性地进行建模识别,理论上来说可以通过模型挖掘隐喻中所有的特性,根据每个特性在隐喻中的重要性去分散研究最后通过加权算法识别隐喻,而这其中涉及到各个特性在隐喻中比重是需要通过大量研究得出结论,隐喻识别仍是当今自然语言研究上所面临的难题。
猜你喜欢
VOGUE服饰与美容(2021年2期)2021-02-04
红楼梦学刊(2020年2期)2020-02-06
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
西南交通大学学报(社会科学版)(2018年3期)2018-08-11
环球市场信息导报(2017年1期)2017-04-08
长江学术(2015年1期)2015-02-27
小学生作文辅导·看图读写(2009年5期)2009-06-11
阅读(中年级)(2009年11期)2009-04-14
