
基于机器学习的硬盘故障预测研究
2022-06-29 12:37乔旭坤茅智慧
计算机技术与发展 2022年6期
乔旭坤,李 顺,李 君,吴 鑫,茅智慧
(浙江万里学院,浙江 宁波 315100)
0 引 言
随着云计算和大数据时代的来临,数据量剧增,存储系统的重要性更为凸显。磁盘是云存储和数据中心等存储系统的核心,超过90%的数据存储在磁盘,磁盘故障是最频繁出现(约占80%[1]),也是最为严重的硬件故障[2]。虽然单个磁盘故障发生概率较低,但对于磁盘基数大的存储系统则带来很大影响。腾讯公司报告磁盘月故障率约为0.21%,超过5年服务期的磁盘月故障率达到0.7%;Google数据中心4~6年期的数据统计表明有20%~57%的磁盘至少有一个扇区损坏[3]。磁盘故障不仅造成其上运行的业务中断从而降低用户满意度,而且存储在磁盘上的大量数据将随着磁盘损坏而永久丢失,给企业和个人带来不可估量的损失,阻碍了大数据、云计算技术的广泛推广和应用。若能对磁盘故障和磁盘寿命进行有效及时的预测,适时做好磁盘的更换或者维护,将会在保障数据安全、防止数据丢失、挽救重大数据损失带来的负面效应以及降低数据中心等存储系统运营成本等方面起到积极的作用。因此,磁盘故障预测具有非常重要的应用价值和理论研究价值,成为存储系统的研究热点。
目前检测磁盘的健康状态主要有三种方法。一是利用加速度传感器和声发射传感器等外部传感器来监测磁盘运行中振动信号的演变[4],但把传感器安在磁盘外部无法有效得到磁盘退化信息,而安装在内部则会破坏磁盘结构并增加物理尺寸。二是利用存储系统的日志文件,由存储系统中软硬件的错误事件来判定磁盘健康状态,但由于缺乏闭环监测无法提供磁盘性能的全面信息[5]。三是利用SMART(self-monitoring,analysis and reporting technology,自检测、分析和报告技术)提供的磁盘特征参数,如磁盘加载/卸载周期数、磁盘启动平均时间、磁头寻道出错率等,通过阈值检测法实现无损的磁盘健康状态监测,并当任意一个属性值超过预设阈值时发出警报。该方法是目前磁盘厂商普遍采用的磁盘故障预测方法。但SMART阈值检测法仅能实现简单的磁盘故障评测,在达到0.1%误判率FAR(false alarm rate,好盘被误报为坏盘的比例)时,其故障检测率FDR(failure detection rate,故障磁盘中被准确检出的比例)只有3%~10%[6],无法满足用户实际需求。
1 相关工作
统计学和机器学习的方法广泛应用在磁盘SMART数据集上进行故障预测。Hughes等[7]最早提出两种统计方法以提高预测性能,在严重不均衡的数据集上取得60%的FDR和0.5%的FAR。Wang Yu等[8]基于异常检测提出了一种基于滑动窗口的广义似然比检验方法跟踪磁盘异常,在均衡的小数据集上达到68%的FDR。除了统计方法,机器学习方法也大量应用到磁盘故障预测中。Murray等[6]比较了多种机器学习方法,其中支持向量机(support vector machine,SVM)在FAR为零时获得50.6%的FDR,相对于朴素贝叶斯等算法具有较好的预测性能。树型朴素贝叶斯算法TAN[9]和隐马尔可夫模型[10]被相继提出以进一步提升FDR。早期的故障预测方法总体上预测精度不高。
随着机器学习技术的引入,磁盘故障预测准确性持续提升。Zhu Bingpeng等[11]采用反向传播神经网络与改进SVM,取得了0.03%的故障误报率和高达95%的故障检测率,并且可提前15天预测出硬盘故障。Nicolas Aussel等[12]采用梯度提升决策树算法模型,达到了94%的准确度和67%的召回率,该方法误报少,但是漏报占比大,而故障磁盘的漏报会带来严重的后果。Yang Wenjun等[13]采用逻辑回归(logistic regression,LR)算法建立硬盘故障预测模型,获得0.3%的FAR和97.82%的FDR。Shen Jing等[14]在硬盘SMART数据上建立随机森林(random forest,RF)算法模型,取得了97.67%的FDR和 0.017%的FAR。上述研究大部分都能在较低的误报率前提下达到较好的磁盘故障检测率,在检测精度上有很大的进步,极大地提高了存储系统的可靠性和可用性。国内研究人员段茹[15]和谢伟睿[16]在磁盘故障预测方面也进行了积极的探索和研究。
为了对不同算法模型预测效果有统一的比较,该文搭建了基于机器学习的硬盘预测实验平台,并采用常用算法模型进行比较,这些算法模型都是基于机器学习Scikit-learn框架,均在Anaconda上运行,使用相同的数据集和性能评估指标。
2 实验数据集
实验采用公开数据集S.M.A.R.T.dataset,是希捷(Seagate)公司制造的型号为ST31000524NS的硬盘(记为B1数据集)。B1数据集包括23 395块硬盘,其中22 962块健康盘和433块故障盘。健康盘数是故障盘的50多倍。每隔一小时采集一次,健康盘采集时长为一周,故障盘采集时长为20天,得到健康盘3 857 616条样本数,故障盘156 312条样本数。从B1中抽出一份较小的数据集(记为B2数据集)以此来对比模型在不同数量级别样本下的性能,B2数据共包含5 750块硬盘,其中包括433块故障盘和5 317块健康盘,健康盘是故障盘的12倍多。故障盘有156 312条样本,健康盘有892 264条样本。数据集在公开的时候就已经清洗、处理过,健康盘被标记为“+1”,故障盘被标记为“-1”,所有的属性值经过归一化映射到区间[-1,+1]上。该文选取了11个特征属性,加_raw标记的特征为属性的原始值,如表1所示。由于SMART技术提供的数据属性值值域范围大,采用公式(1)进行数据集归一化,以避免偏向具有较大参数值的特征而影响预测精度:
(1)
其中,X是归一化后的值,x是属性的当前值,xmax和xmin分别是数据集所对应特征属性的最大值和最小值。
把处理好的数据集按7∶3的比例随机划分为训练集和测试集。训练集和测试集是互斥的,测试集的样本在训练集上未出现过。在训练集上训练出多种预测模型,用测试集作为新样本来测试已经训练好的预测模型。

表1 数据集对应的属性值
3 硬盘故障预测模型
该硬盘故障预测模型都是基于机器学习算法,包括随机森林(random forest,RF)、逻辑回归(logistic regression,LR)、多层感知神经网络(multilayer perceptron - artificial neutral network,MLP-ANN)、决策树(decision tree,DT)、朴素贝叶斯(naive Bayes,NB)、极端梯度提升树(extreme gradient boosting,XGBoost)、梯度提升决策树(gradient boosting decision tree,GBDT)以及AdaBoost算法。其中集成学习算法XGBoost、GBDT以及AdaBoost均采用CART(classification and regression tree)作为基学习器来建立模型,CART学习器属于弱学习器,这三种集成学习算法分别对CART进行集成,集成后的模型在文中称为XGBoost模型、GBDT模型和AdaBoost模型。
4 实验结果与分析
4.1 实验环境
实验平台采用Windows7系统,12 GB的RAM内存,Intel(R)core(TM)i3-4160CPU@3.60 GHz的处理器。编程环境为Anaconda Navigator(spyder version 3.0.0)version 4.2.0,编程语言为Python语言,基于机器学习框架Scikit-learn version 0.19.0。
4.2 模型参数的设置
实验中random_state均设为12,以便于后续验证实验结果,对于其他参数是采用经验调参的方式。同一个参数在不同算法模型中设置的不一定相同,如学习率在XGBoost模型中设置为0.01,而在AdaBoost模型中设为0.1。在GBDT模型和AdaBoost模型中n_estimators都设置为了200。具体的模型调参流程如图1所示。

图1 模型调参流程
4.3 模型性能评估指标
为了进行合理的实验结果对比,该文选择统一的模型性能度量指标即查准率(precision)、查全率(recall)、故障检测率(failure detection rate,FDR)、故障误报率(false alarm rate,FAR)和ROC曲线(receiver operating characteristic curve)。
查准率(precision)也叫准确率,简称P,表示预测出的健康盘(故障盘)中实际为健康盘(故障盘)占所用测试健康盘(故障盘)的比例,具体定义见公式(2):
(2)
其中,真正例(true,positive,TP)表示真实为健康盘(故障盘)预测也为健康盘(故障盘),假正例(false,positive,FP)表示真实为健康盘(故障盘)预测为故障盘(健康盘)。
查全率(recall)也叫召回率,简称R,具体定义见公式(3):
(3)
其中,假反例(false,negative,FN)表示实际故障盘(健康盘)预测为健康盘(故障盘)。
故障检测率(FDR)为故障盘的召回率,表示成功预测的故障盘占所用测试故障盘总数的比例。
故障误报率(FAR)是把健康盘预测为故障盘的比例,如公式(4)所示:
(4)
其中,真反例(true,negative,TN)表示真实为健康盘预测仍为健康盘。
4.4 实验结果分析
在样本数较少的B2数据集上,各种算法模型的预测结果如表2所示,其中“+1”表示健康盘,“-1”表示故障盘。

表2 在B2数据下各种算法模型预测结果
P和R是precision和recall的简称,(-1)R和FDR相同,只是保留小数位不同。为了更直观地对比预测效果,把上述各算法模型的预测结果以条形图的形式呈现出来,如图2和图3所示。故障盘的查准率和召回率如图4所示。值得一提的是在P、R条形图中,随机森林算法模型的P、R指标趋于“1”,但并没有达到“1”。上述各算法模型的ROC曲线如图5所示,可见在2%的误报率情况下,所有算法模型的故障检测率都达到了80%以上。

图2 在B2数据下各种算法模型的FDR

图3 在B2数据下各种算法模型的FAR

图4 在B2数据下故障盘P和R
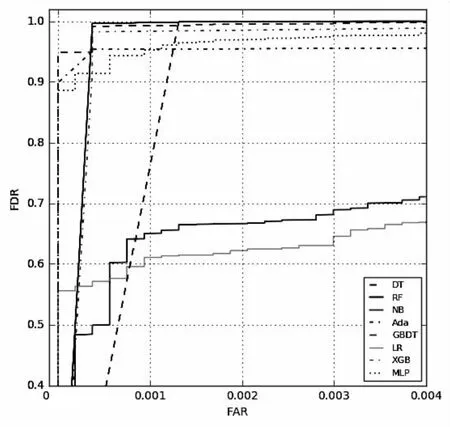
图5 在B2数据下各种算法模型的ROC曲线
从上述结果可以看出,在数据集较小的情况下,RF算法模型预测精度最高,GBDT模型次之,DT模型预测效果略好于XGBoost模型,而XGBoost模型优于AdaBoost模型,AdaBoost模型好于MLP-ANN模型。虽然MLP-ANN模型故障检测率高于AdaBoost模型,但是故障误报率也高很多,AdaBoost模型要优于LR算法模型。NB算法模型故障检测率最低,故障误报率最高,是最差的算法模型。
各模型性能差异的原因主要是:RF算法是在集成学习算法Bagging基础上的改进,Bagging算法是一种集成式并行运算算法,RF算法从所有属性中随机选择m个属性,选择最佳分割属性作为节点建立决策树,从而有很好的分类性能。GBDT和AdaBoost算法是Boosting族的代表算法,AdaBoost算法在上一个基学习器的基础上来学习优化下一个基学习器的参数,然后对这n个基学习器进行串行加权求和。GBDT算法集成了多棵CART回归树作为基学习器,随着训练的轮数更新残差并使残差减少,从而提高预测的精度。XGBoost算法是对GBDT算法的改进,具有很好的预测性能。集成算法模型GBDT的预测效果优于DT模型,而DT模型的预测结果要略好于XGBoost和Adaboost模型,这说明在某些条件下集成模型不一定比单个学习器预测效果好。DT算法利用树状结构将整个特征空间进行划分,最终判断出样本类别,虽然原理简单,但预测精度高。MLP-ANN算法是一种简单的人工神经网络,可以根据分类问题的难易程度添加隐含层数以及神经元的个数,也取得了较好的结果。LR模型是线性分类器,非线性表达能力不足,实验效果相对比较差。NB算法假设属性之间相互独立,但是该文的特征属性之间具有一定的相关性,所以NB算法模型的预测效果不佳。

表3 在B1数据下各种算法模型预测结果

图6 在B1和B2数据下的FDR

图7 在B1和B2数据下的FAR
由图6和图7可见,各种算法模型在B1数据集和B2数据集上的预测结果走势一致。特别地,RF和GBDT具有很高的FDR和很低的FAR,且几乎不受样本数据集大小影响。XGB算法的FAR虽然在B1和B2数据集的变化非常小,但是FDR变化较大。其他的算法模型预测结果FDR和FAR变化较大,说明模型对样本集规模适应性较弱。
结合RF和GBDT的特点可知以树为基学习器的集成算法对数据的抗噪能力很强,然而以树为基学习器并不是唯一决定因素,如XGBoost和Adaboost算法对数据适应能力并不强,这也与算法其他因素相关,如RF是以Bagging方式集成了决策树的算法,而GBDT是以Boosting方式集成了回归树的算法,同时从上述在B2数据集的分析结果可知每个算法的运行原理不同,这也在一定程度上影响了算法对不同数据集的泛化能力。
5 结束语
通过建立比较系统,对八种算法模型的预测效果对比可知:RF和GBDT硬盘故障预测模型相比其他算法模型具有很好的预测效果,都能在0.05%的FAR下达到93%以上的FDR,另外这两个算法模型对不同规模样本数据集的适应性也很强。由于实验只是针对同一公司的同一种型号硬盘进行测试,硬盘故障预测模型对于其他不同硬盘厂商的不同型号硬盘的预测效果尚不确定,下一步工作将会致力于研究预测精度高且具有更强泛化能力的硬盘故障预测模型。
猜你喜欢
消费电子(2022年6期)2022-08-25
电脑爱好者(2020年18期)2020-09-26
电脑爱好者(2019年2期)2019-10-30
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
电脑知识与技术(2017年14期)2017-07-10
电脑爱好者(2015年6期)2015-04-03
微型计算机(2009年13期)2009-12-11
