
基于TextCNN 的政策文本分类
2022-06-29 06:08李悦,汤鲲
电子设计工程 2022年12期
李 悦,汤 鲲
(1.武汉邮电科学研究院,湖北武汉 430070;2.南京烽火天地通信科技有限公司,江苏 南京 210019)
在当今的大数据时代,政府进行宏观决策时,常常需要参考各地市出台的政策文件,然而现在各地市的政策文件分布杂乱,且类别不统一,目前市面上也并没有把各地市的政策全部综合起来的政策文本类数据集,而此类数据集为政府在宏观决策时提供参考,基于此,文中构建了一个大型综合的全国各地市政策文本类数据集。其次,针对政策文本分类,目前市面上大都只进行了单标签分类,而单标签分类显然并不适用于政策文本的分类,用一个标签来概括整篇文本太笼统,因此,文中对政策文本数据集进行多标签分类。此外,在政策文本分类中,当前普遍的思路是采用TF-IDF+SVM 分类算法[1]来构建分类模型,或者使用BERT 进行分类[2],效果都不佳。文中经过实验验证了采用神经网络TextCNN 更适合进行政策类长文本的多标签分类。
1 TextCNN原理介绍
TextCNN 模型可以并行处理,且自带n-gram 属性,训练速度和预测精度都比较理想,是一种非常优秀的文本分类模型[3]。对于500 字以上长度的长文本,即使是LSTM 在这么长的序列长度上也难免梯度消失,而CNN 就不存在该问题,TextCNN 不仅适合处理短文本,同样也适合处理长文本,该文待处理的政策文本即为长文本。下面介绍了TextCNN 模型的原理。
1)Word Embedding
如图1 所示,在TextCNN 中,首先将“这个青团不错,你尝尝”分词成“这个/青团/不错/,/你/尝尝”,通过Embedding 将每个词映射成一个5 维词向量(维度可任意)[4-5]。

图1 Word Embedding
这步主要是为了将自然语言数值化,从而方便后续的处理。可以看出,映射方式不同,最后结果不同。构建完词向量后,将所有的词向量拼接成一个6×5 的二维矩阵,将其作为最初的输入。
2)Convolution 卷积
这一步骤是将输入词向量矩阵与卷积核进行卷积运算操作,将“这个”/“青团”/“不错”/“,”4 个词语构成的矩阵与卷积核分别对应相乘再相加,可得到最终的Feature Map,这个步骤即为卷积[6],具体操作如图2 所示。卷积操作后,输入的6×5 的词向量矩阵就被映射成了一个3×1 的矩阵,即Feature Map。

图2 卷积
3)Pooling 池化
在得到Feature Map=[1,1,2]后,从中选取最大值‘2’作为输出,便是max-pooling[7]。如果选择平均池化(mean-pooling)[8],就是求平均值作为输出。由此,最大池化在保持主要特征的情况下,极大地减少了参数的数目,加速了运算,并降低了Feature Map的维度,同时,也降低了过拟合的风险。

图3 max-pooling
4)使用Softmax k 分类
接下来是将max-pooling的结果合并到一起,再送入Softmax 中,可以得到各个类别[9],如label 为1 和-1的概率,如图4 所示。

图4 Softmax
在做模型预测时,使用TextCNN,此时要根据预测标签以及实际标签来计算损失函数,分别计算出卷积核、max-pooling、Softmax 函数、激活函数,这4 个函数中的各个参数需要更新的梯度,再依次更新这些参数,即可完成一轮训练。
2 数据集的构建
由于该文研究任务的特殊性,没有现成的语料可以使用,所以需要构建相应的语料库。其数据集来源于全国各个地市的政府政策公告文本信息的爬虫爬取,然后再对爬取的结果利用正则以及结合人工清洗的方式进行数据的清洗,构建数据库,将爬取并清洗后的数据入库,构建政府政策文本语料库。
2.1 爬取数据及数据处理
文中所采用的数据均为网络爬虫所得,先挑选出几个所需字段,再对各个地市政府官网公开的政策文本数据分别进行采集,经过简单清洗后整理入库。
为了丰富数据库的数据内容,文中挑选的字段涵盖了标题、文本、适用对象、原文链接等。全部字段有:title 标题、themeList 主题、styleName文体、levelName 层级、dispatchList_commonName 发文单位、targetList 适用对象、original_url 原文链接、publishTime 发文时间、industryList 适用行业、scaleList 适用规模、qx_content 内容、classify_tag_list分类标签。
共爬取数据100 000 条,经去重、去空,以及删除过短文本后数据量为96 640 条。对数据进行如下操作:
1)增加标签、筛掉无关类别的数据(和分类没关系的字段)。
2)繁简转换、清洗无意义字符。
3)人工打标,主要是对“其他”这个类别的数据进行打标。
4)构建训练集和测试集,按照6∶2∶2 进行划分。
2.2 数据集的介绍
2.2.1 类别的构建
由于爬取的数据集中,内容的类别杂乱不统一,不利于后续进一步利用该数据集,因此,对自建数据集中的“qx_content 内容”字段进行文本分类操作。
在类别的设定上,首先参考了国务院政策信息网的类别设定;另外,文中对数据集进行TF-IDF+LDA 聚类[10],通过聚类得到了一些政策重点词,针对这些政策重点词,进行类别的设定。最终,共拟定了47 种类别。全部类别为:产业发展、营商环境、政务公开、学校教育、人才引进和能力培育、创新研发、复工复产、资质认定、税收优惠、节能环保、信息化建设、转型升级、互联网+、市场拓展、工程报建、企业创办、稳企稳岗、医疗健康、金融财税、平台基地建设、知识产权、电子政务、成果转化、数字政府、不动产登记、科研课题、融资帮扶、三农发展、租金减免、孵化器及基地建设、市场监管、疫情扶持、缓缴社保、大数据、水电气减免、招商引资、法律法规、数字经济、电子商务、品牌建设、数据治理、智慧城市、改制上市、并购重组、一带一路、区块链、其他。
2.2.2 数据集示例
针对上文中的自建数据集,想要实现对每条数据进行清洗、分词后,对该条数据打上相应分类标签的目的。样本和标签的情况如下:
样本是政策的文本内容,标签是政策文本涉及到的类别,而每条政策涉及到的类别可能为多个,所以需要进行政策文本的多标签分类。所以训练模型的目的,是希望输入政策文本数据,输出该政策涉及到的类别。数据集示例如图5 所示。

图5 数据集示例图
3 TextCNN模型的构建
3.1 搭建TextCNN模型
1)定义Embedding 层
加载预训练词向量,在自定义Embedding 层时,将把词向量矩阵加入其中。采用这种方法,可使词向量矩阵在模型初始化时就加载好了。可以选择词向量在训练过程中冻结还是微调。如果选择微调,即freeze=False,能够一定程度上提升效果,尽管训练速度会变慢[11]。
2)定义卷积层和池化层
如果卷积层的层数太浅,会无法捕捉长距离的语义信息,从而不足以提取文本的特征,但是如果卷积层数太深,就会陷入梯度消失的境地[12]。为了便于提取长文本中的句子特征,文中增加了卷积层数、更改了池化方式。
采用的池化为1/2 池化,在卷积之后,每经过一个大小为3,步长为2 的池化层,序列的长度就被压缩成了原来的一半。即同样是size=3 的卷积核,每经过一个1/2 池化层后,其能感知到的文本片段就比之前长了一倍,解决了原TextCNN 模型中无法捕获长距离语义信息的问题。
3)全连接层
该文对模型在全连接层处也进行了修改,TextCNN 的原论文中,网络结构只有一个全连接层作为输出层,且无激活函数。它是把卷积池化的结果拼接,然后进行dropout 操作,再接输出层。而该文在输出层之前,又加了一个全连接层(激活函数为ReLU),将卷积池化的结果拼接,进行dropout,加全连接层,再接上输出层。这样做的原因主要是网络加深后,便于提取更丰富的特征。而且如果输出的类别较少,那么输出的维度剧烈降维的情况下,如直接从几百维降到几维,可能对分类的效果产生不好的影响。因此需要加一个全连接层来过渡。
4)输出层
输出层是线性层,不需要使用激活函数。后面的loss 函数,将sigmoid 和计算binary loss 两步同时进行,这样计算更有效率,也更稳定,故不必加sigmoid函数得到概率。
文中经改进后的TextCNN 模型与原TextCNN 模型相比,有如下优势:
基于传统的TextCNN 模型,为了解决模型中无法捕捉长距离语义信息的缺点,该文加深了卷积深度,同时提出了等长卷积和1/2 池化方式,使得卷积范围增加。
另外,增加一个全连接层作为过渡,防止在输出维度剧烈降维情况下,对分类效果产生的不利影响。
3.2 多标签分类的评估函数
该文选择采用海明损失[13](Hamming loss)和F1值[14](宏平均和微平均)作为主要指标来评估模型的性能。关于宏平均和微平均:如果每个class 的样本数量相差不大,那么宏平均和微平均差异也不大。如果每个class 的样本数量相差较大并且想更注重样本量多的class,就使用微平均;更注重样本量少的class,就使用宏平均。如果微平均远低于宏平均,则应该去检查样本量多的class。如果宏平均远低于微平均,则应该去检查样本量少的class[15]。这里可直接用sklearn 函数来计算。对于每一个预测样本,需要47 个类别的每一个类别都预测正确,才能算该样本预测正确,其难度太大,并不适合用于评价模型的效果,该文需要分类的共有47 个类别,如果部分类别可以预测正确的话,模型也是可以用的。在模型的训练过程中,如果监控到验证集上的F1 值有提升,那么会在测试集上做一次评估,同时保存模型。
多标签分类的损失函数不再是多分类的crossentropy loss,而是binary cross-entropy loss。具体实现的函数为:criterion=nn.BCEWithLogitsLoss (pos_weight=config.class_weights)[16]
该函数将模型的输出做sigmoid,然后计算损失。pos_weights 这个关键字参数,用于传入类别的权重,引入该参数缓解类别不平衡的问题,这里只在训练时传入,验证和测试时不用。
4 实验结果及对比分析
4.1 配置环境及实验参数
1)实验环境
该实验的运行环境为:tensorflow-gpu=1.12.0、keras=2.2.4、python3.6、Scikit-learn=0.21.3、Torch=1.1.0。
2)实验参数
在config 类中,配置好相关的参数,如文件路径、模型的各个参数等。其他一些需要通过计算得到的模型参数,在数据处理过程中添加,如输入的最大长度、类别数、词表的尺寸等。该文设置的部分参数如下:
①batch size=128;
②学习率=1e-3;
③百度百科词向量维度=300;
④卷积核尺寸=[2,3,4,5];
⑤卷积核数量=128;
4.2 文本预处理
首先数值化样本及标签,在配置参数初始化后,依次完成文本的清洗和分词,确定输入的最大长度,对样本进行zero pad,转化为id,对标签进行数值化,以及构建词表等操作。数值化后的标签每一位是0或1,类别数是列数,标签的类别数为47,也就是TextCNN 的输出维度为47。在数值化样本及标签后,加载百度百科词向量。针对类别不平衡问题,该文的数据集多标签类别有47 个,经过统计分析,每个类别之间数量差别巨大,存在比较严重的类别不平衡问题。通过计算各个类别的权重,来计算加权的loss。对于数量较多的类别,给予较小的权重,数量较少的类别,权重较大,以期能缓解多标签的类别不平衡问题。
4.3 对比实验结果
该节测试基本的多标签贝叶斯分类算法MLNB、多标签分类KNN 算法ML-KNN,以及RoBERTa算法与文中改进过的TextCNN 模型之间的性能对比。该选择将以上各个算法在该文的自建数据集上进行测试运行对比,结果如表1 所示。
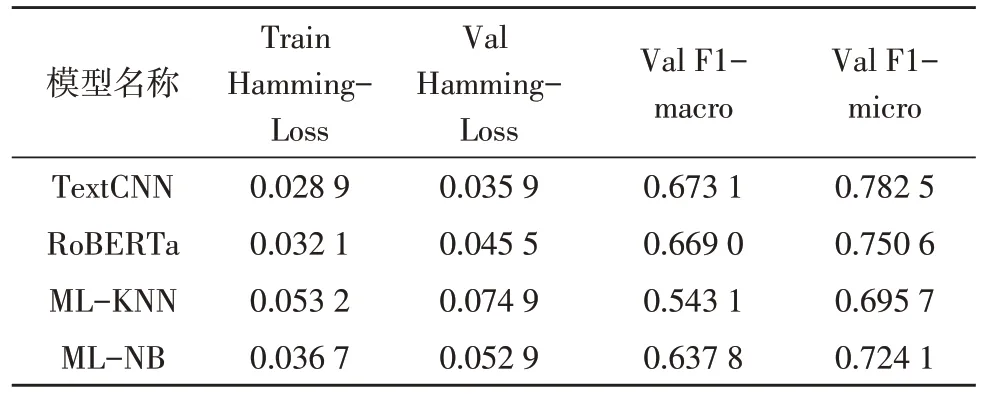
表1 实验结果对比
在该文的自建数据集上,TextCNN 模型在主要的性能指标上超过了所有其他模型,达到了较好的效果。F1-micro 的值分别比RoBERTa、ML-KNN、ML-NB 高出了3.19,8.68,5.84 个百分点。
5 结束语
该文首先介绍并构建了一个全新的全国政策文本类的数据集,通过爬虫来获取全国各个地市的政策文本数据,对数据进行预处理后,构建训练集、验证集和测试集。后在自建数据集上进行基于TextCNN 的多标签分类任务。最后通过改进过的TextCNN 神经网络来训练模型对数据进行多标签分类,经过实验对比测试,经过改进后的TextCNN 结合百度百科词向量在自建数据集上达到了较好的分类效果。
当然,该文在研究过程中仍然有不足之处,比如文中自建数据集里的政策数据是多标签文本,存在一定程度上的标签类别不平衡的问题,虽然使用权重在一定程度上缓解了类别不平衡的问题,但权重应用的效果并不是很好,这部分内容待优化。未来将在该方面继续进行研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
